Amazon Simple Storage Service (Amazon S3) Steps To create Amazon S3
 Aditya Gadhave
Aditya Gadhave
What is Amazon S3 ?
S3 is one of the first services that has been produced by aws.
S3 stands for Simple Storage Service.
S3 provides developers and IT teams with secure, durable, highly scalable object storage.
It is easy to use with a simple web services interface to store and retrieve any amount of data from anywhere on the web.
S3 is a safe place to store the files.
It is Object-based storage, i.e., you can store the images, word files, pdf files, etc.
The files which are stored in S3 can be from 0 Bytes to 5 TB.
It has unlimited storage means that you can store the data as much you want.
Files are stored in Bucket. A bucket is like a folder available in S3 that stores the files.
S3 is a universal namespace, i.e., the names must be unique globally. Bucket contains a DNS address. Therefore, the bucket must contain a unique name to generate a unique DNS address.
Amazon S3 Concepts

Buckets
Objects
Keys
Regions
Data Consistency Model
Buckets
A bucket is a container used for storing the objects.
Every object is incorporated in a bucket.
For example, if the object named photos/tree.jpg is stored in the treeimage bucket, then it can be addressed by using the URL http://treeimage.s3.amazonaws.com/photos/tree.jpg.
A bucket has no limit to the amount of objects that it can store. No bucket can exist inside of other buckets.
S3 performance remains the same regardless of how many buckets have been created.
The AWS user that creates a bucket owns it, and no other AWS user cannot own it. Therefore, we can say that the ownership of a bucket is not transferrable.
The AWS account that creates a bucket can delete a bucket, but no other AWS user can delete the bucket.
Objects
Objects are the entities which are stored in an S3 bucket.
An object consists of object data and metadata where metadata is a set of name-value pair that describes the data.
An object consists of some default metadata such as date last modified, and standard HTTP metadata, such as Content type. Custom metadata can also be specified at the time of storing an object.
It is uniquely identified within a bucket by key and version ID.
Key
A key is a unique identifier for an object.
Every object in a bucket is associated with one key.
An object can be uniquely identified by using a combination of bucket name, the key, and optionally version ID.
For example, in the URL http://jtp.s3.amazonaws.com/2019-01-31/Amazons3.wsdl where "jtp" is the bucket name, and key is "2019-01-31/Amazons3.wsdl"
Regions
You can choose a geographical region in which you want to store the buckets that you have created.
A region is chosen in such a way that it optimizes the latency, minimize costs or address regulatory requirements.
Objects will not leave the region unless you explicitly transfer the objects to another region.
Data Consistency Model
Amazon S3 replicates the data to multiple servers to achieve high availability.
Two types of model:Read-after-write consistency for PUTS of new objects.
For a PUT request, S3 stores the data across multiple servers to achieve high availability.
A process stores an object to S3 and will be immediately available to read the object.
A process stores a new object to S3, it will immediately list the keys within the bucket.
It does not take time for propagation, the changes are reflected immediately.
Eventual consistency for overwrite PUTS and DELETES
For PUTS and DELETES to objects, the changes are reflected eventually, and they are not available immediately.
If the process replaces an existing object with the new object, you try to read it immediately. Until the change is fully propagated, the S3 might return prior data.
If the process deletes an existing object, immediately try to read it. Until the change is fully propagated, the S3 might return the deleted data.
If the process deletes an existing object, immediately list all the keys within the bucket. Until the change is fully propagated, the S3 might return the list of the deleted ke.
S3 contains four types of storage classes:
S3 Standard
S3 Standard IA
S3 one zone-infrequent access
S3 Glacier
S3 Standard
Standard storage class stores the data redundantly across multiple devices in multiple facilities.
It is designed to sustain the loss of 2 facilities concurrently.
Standard is a default storage class if none of the storage class is specified during upload.
It provides low latency and high throughput performance.
It designed for 99.99% availability and 99.999999999% durability
S3 Standard IA
IA stands for infrequently accessed.
Standard IA storage class is used when data is accessed less frequently but requires rapid access when needed.
It has a lower fee than S3, but you will be charged for a retrieval fee.
It is designed to sustain the loss of 2 facilities concurrently.
It is mainly used for larger objects greater than 128 KB kept for atleast 30 days.
It provides low latency and high throughput performance.
It designed for 99.99% availability and 99.999999999% durability
S3 one zone-infrequent access
S3 one zone-infrequent access storage class is used when data is accessed less frequently but requires rapid access when needed.
It stores the data in a single availability zone while other storage classes store the data in a minimum of three availability zones. Due to this reason, its cost is 20% less than Standard IA storage class.
It is an optimal choice for the less frequently accessed data but does not require the availability of Standard or Standard IA storage class.
It is a good choice for storing the backup data.
It is cost-effective storage which is replicated from other AWS region using S3 Cross Region replication.
It has the same durability, high performance, and low latency, with a low storage price and low retrieval fee.
It designed for 99.5% availability and 99.999999999% durability of objects in a single availability zone.
It provides lifecycle management for the automatic migration of objects to other S3 storage classes.
The data can be lost at the time of the destruction of an availability zone as it stores the data in a single availability zone.
S3 Glacier
S3 Glacier storage class is the cheapest storage class, but it can be used for archive only.
You can store any amount of data at a lower cost than other storage classes.
S3 Glacier provides three types of models:
Expedited: In this model, data is stored for a few minutes, and it has a very higher fee.
Standard: The retrieval time of the standard model is 3 to 5 hours.
Bulk: The retrieval time of the bulk model is 5 to 12 hours.
You can upload the objects directly to the S3 Glacier.
It is designed for 99.999999999% durability of objects across multiple availability zones.
Features of Amazon S3
Durability: AWS claims Amazon S3 to have a 99.999999999% of durability (11 9’s). This means the possibility of losing your data stored on S3 is one in a billion.
Availability: AWS ensures that the up-time of AWS S3 is 99.99% for standard access.Note that availability is related to being able to access data and durability is related to losing data altogether.
Server-Side-Encryption (SSE): AWS S3 supports three types of SSE models:
SSE-S3: AWS S3 manages encryption keys.
SSE-C: The customer manages encryption keys.
SSE-KMS: The AWS Key Management Service (KMS) manages the encryption keys.
File Size support: AWS S3 can hold files of size ranging from 0 bytes to 5 terabytes. A 5TB limit on file size should not be a blocker for most of the applications in the world.
Infinite storage space: Theoretically AWS S3 is supposed to have infinite storage space. This makes S3 infinitely scalable for all kinds of use cases.
Pay as you use: The users are charged according to the S3 storage they hold.
Advantages of Amazon S3
Scalability: Amazon S3 can be scalable horizontally which makes it handle a large amount of data. It can be scaled automatically without human intervention.
High availability: AmazonS3 bucket is famous for its high availability nature you can access the data whenever you required it from any region. It offers a Service Level Agreement (SLA) guaranteeing 99.9% uptime.
Data Lifecycle Management: You can manage the data which is stored in the S3 bucket by automating the transition and expiration of objects based on predefined rules. You can automatically move the data to the Standard-IA or Glacier, after a specified period.
Integration with Other AWS Services: You can integrate the S3 bucket service with different services in the AWS like you can integrate with the AWS lambda function where the lambda will be triggered based upon the files or objects added to the S3 bucket.
Follow these steps to create a bucket in your Amazon Simple Storage Service:
Step 1: Log on to your AWS Console. If you don’t have an account, you can create it absolutely free as Amazon provides a 1-year free tier to its new users.
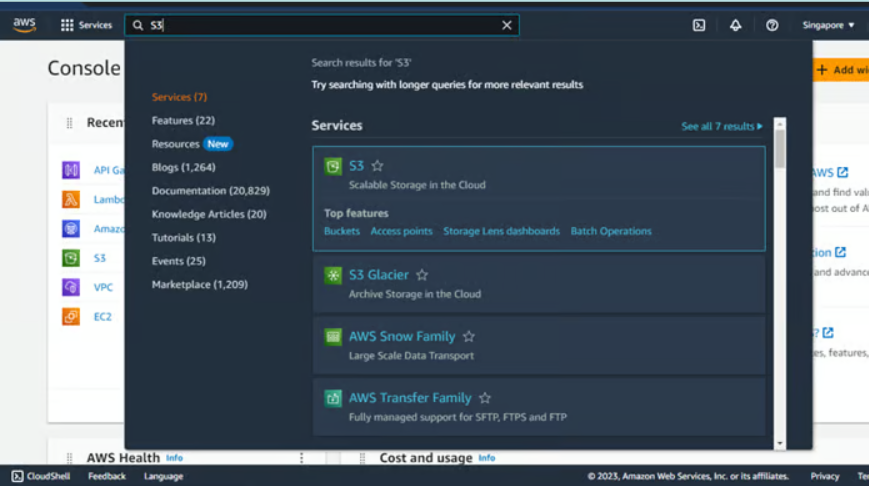
Step 2: In the search bar located at the top of your AWS Management Console, type “Amazon S3”. You will see something like this:
Step 3: Click on “S3 – Scalable Storage in the Cloud” and proceed further.
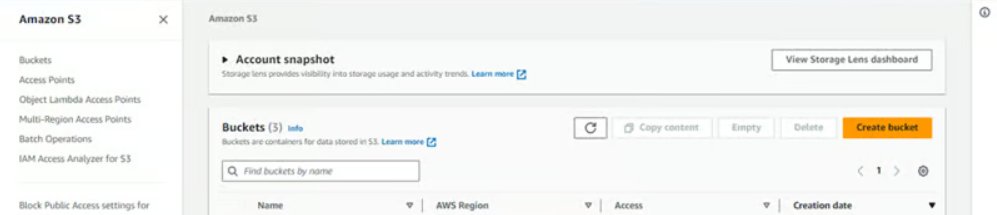
Step 4: Click on “Create Bucket”. A new pane will open up, where you have to enter the details and configure your bucket.
Step 5: Enter the name of your bucket
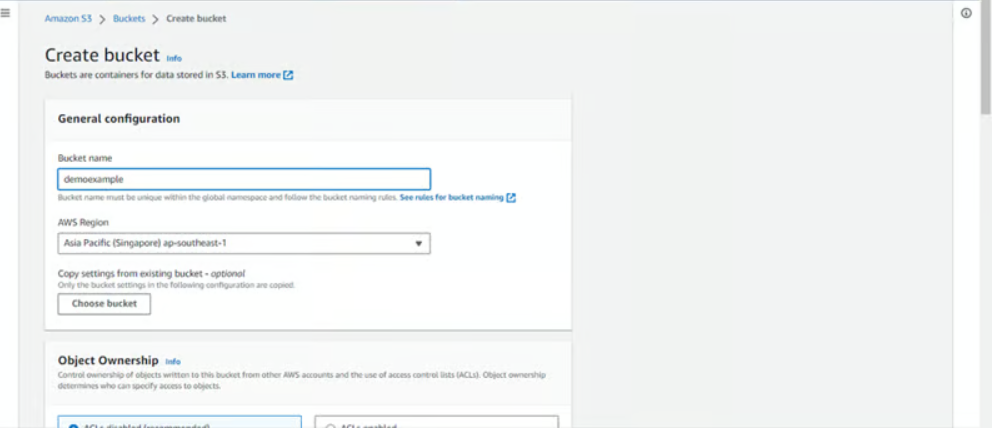
Step 6: Next, choose an AWS region nearest to your location or where you want your data to reside. In our case, it is [Asia Pacific (Mumbai) ap-south-1]. Object Ownership – Enable for making Public, Otherwise disable
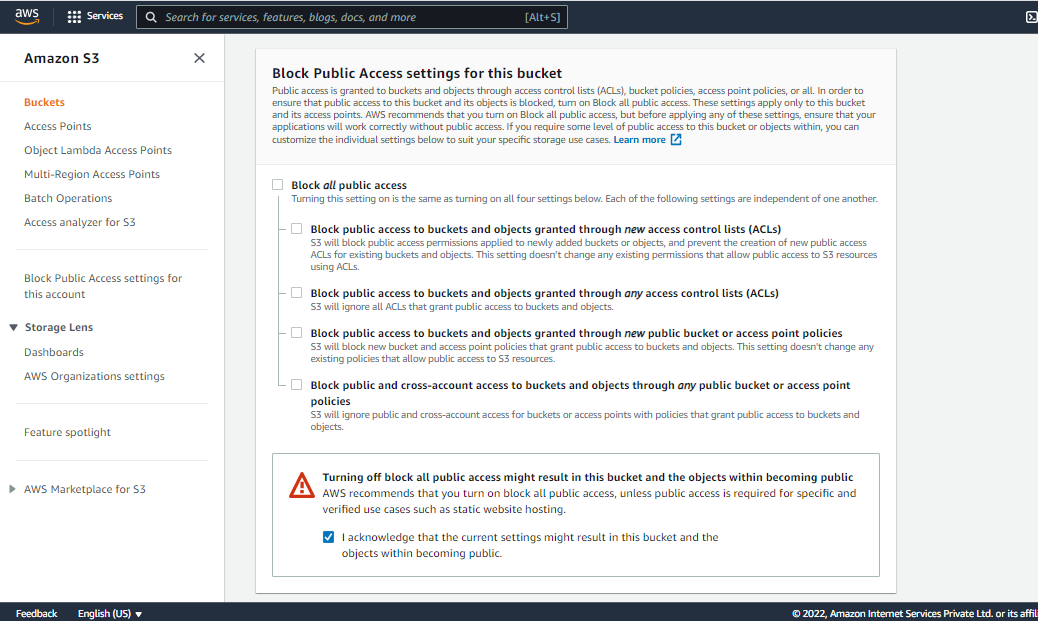
Step 7: Block Public Access settings for the bucket
- Uncheck (Block all public access) for the public, otherwise set default. If you uncheck (Block all public keys).
Bucket Versioning:- You have to do Nothing (Disable)
Tags(0) : Optional
Default encryption: Disable
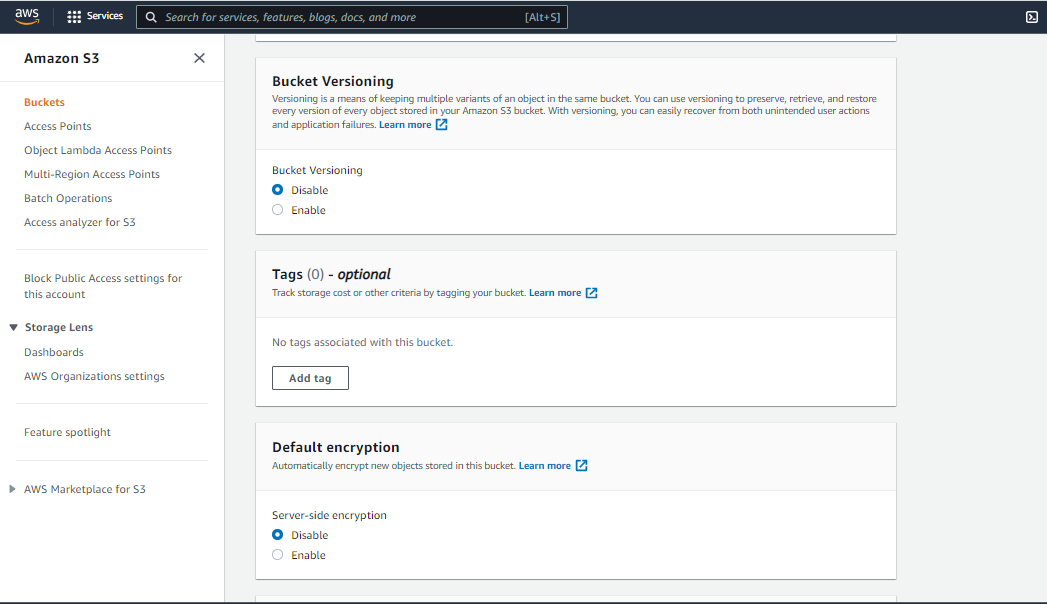
- Now, click on Create Bucket

If the bucket is created successfully, you will see a message like this on the top of the page:

Now upload code files :
Select Bucket and Click your Bucket Name.
Now, click on upload (then click add File/folder) and select your HTML code file from your PC/Laptop.
After uploading, click on Close
Step 8: Copy your Object URL
Now, click on your HTML File Object Name.
Copy the Object URL.
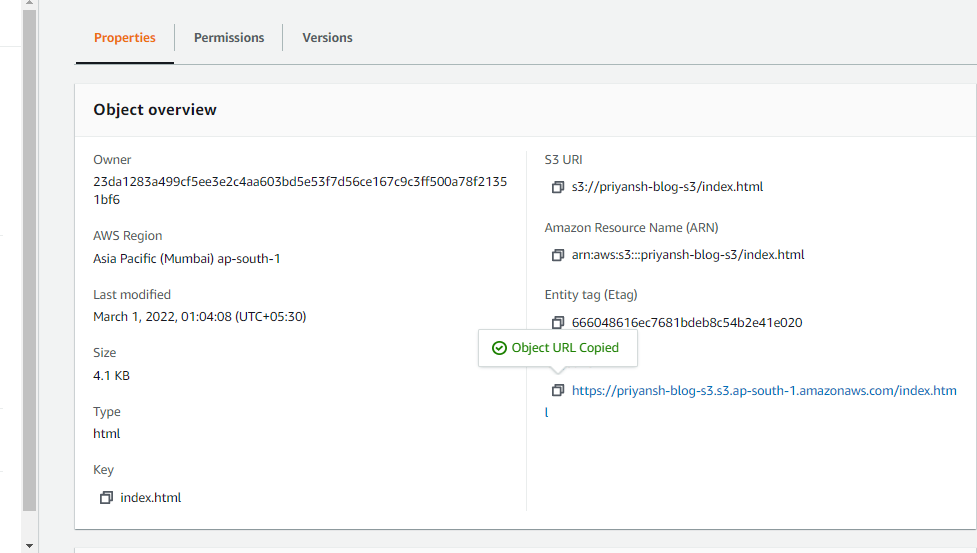
Step 9: Check out your Website!
Directly Paste this URL into the Other Tab or your other System.
Congratulation, Now Your Website is available in the Public.
You Successfully Host Your Website by AWS S3.to
Important points to remember
Buckets are a universal namespace, i.e., the bucket names must be unique.
If uploading of an object to S3 bucket is successful, we receive a HTTP 200 code.
S3, S3-IA, S3 Reduced Redundancy Storage are the storage classes.
Encryption is of two types, i.e., Client Side Encryption and Server Side Encryption
Access to the buckets can be controlled by using either ACL (Access Control List) or bucket policies.
By default buckets are private and all the objects stored in a bucket are also private.
Conclusion:
S3 provides developers and IT teams with secure, durable, highly scalable object storage.It is easy to use with a simple web services interface to store and retrieve any amount of data from anywhere on the web.S3 is a safe place to store the files.It is Object-based storage, i.e., you can store the images, word files, pdf files, etc.
If you have any questions, need clarifications, or want to discuss anything related to AWS technologies, feel free to reach out to me on LinkedIn. Connect with me at Aditya Gadhave, and I'll be more than happy to assist you. 😊
Subscribe to my newsletter
Read articles from Aditya Gadhave directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Aditya Gadhave
Aditya Gadhave
👋 Hello! I'm Aditya Gadhave, an enthusiastic Computer Engineering Undergraduate Student. My passion for technology has led me on an exciting journey where I'm honing my skills and making meaningful contributions.