How to Select the Best GPU for LLM Inference: Benchmarking Insights
 NovitaAI
NovitaAI
Key Highlights
High Inference Costs: Large-scale model inference remains expensive, limiting scalability despite decreasing overall costs.
GPU Selection Challenges: The variety of available GPUs complicates the selection process, often leading to suboptimal choices based on superficial metrics.
Objective Evaluation Framework: A standardized evaluation method helps identify cost-effective GPU solutions tailored to specific business needs.
Performance Metrics: Focus on latency (Time To First Token) and throughput (Tokens Per Second) to optimize user experience.
Cost-Effectiveness Analysis: Evaluating cost per million tokens alongside performance metrics allows for clear categorization of solutions into effective quadrants.
Real-World Testing: Testing of popular models (Llama 3.1 series) on major GPUs (H100, A100, RTX 4090) yields actionable insights.
Best Practices: Recommendations for selecting inference hardware and optimizing engines enhance efficiency and reduce costs.
Explore Novita AI: For more on large model inference services, visit Novita AI.
Introduction
The cost of large-scale model inference, while continuously decreasing, remains considerably high, with inference speed and usage costs severely limiting the scalability of operations. As a provider of large-model inference services, we persistently invest in improving inference speed and reducing inference costs.
We delve into exploring the selection of inference hardware and optimizing inference engines to deliver the most cost-effective inference solutions to our clients. This article focuses on introducing the theoretical methods and best practices for choosing inference hardware and presents our preliminary conclusions.
There is a wide variety of GPUs available for large-model inference, making it challenging to find one that suits the specific business requirements. When deploying operations, the multitude of GPUs often leaves us perplexed, leading to a mere static comparison based on metrics like GPU computing power, memory capacity, bandwidth, and price. This approach of selecting a GPU based on a subjective perception of it looking appealing can significantly mislead and negatively impact business outcomes.
We, too, encountered this issue in our early stages. However, with business growth and expansion, we have gradually developed an objective and impartial GPU evaluation standard along with corresponding evaluation methods. By employing this standardized approach through numerous evaluations, we can identify the most cost-effective solutions tailored to different business needs from a plethora of GPUs. Coupled with optimized inference engines, we ultimately provide clients with large-model inference services that are both fast and cost-effective.
Evaluation Approach
Simply put, a “best cost-effective GPU” needs to meet two criteria: lowest price and highest performance. Before starting evaluations, we accurately define these standards.
Defining Lowest Price
The lowest price isn’t the GPU hardware cost or cloud server leasing in data centers, but the inference service cost. It’s the price we see on the official website for using the Model API, defined as the cost per million tokens consumed (Dollars Per 1M tokens). A lower value means a lower price.
Understanding Highest Performance
The highest performance refers to the speed of large-model inference, where higher is better. It’s essential to distinguish this from model performance, which typically includes two sub-metrics: latency and throughput.
Latency and Throughput Metrics
Latency: Measures the Time To First Token (TTFT), the time a user waits from initiating a request to receiving the first token.
Throughput: Indicates the average number of tokens received per second (TPS) from the first token onwards.
Evaluation Methodology
To align evaluations with business needs, we treat the inference system as a black box during assessments, calculating latency and throughput based on system inputs and outputs. The diagram below illustrates how latency and throughput are calculated.
Key Considerations
Lower latency and higher throughput indicate better inference performance.
Throughput is significantly more crucial than latency in real scenarios.

Request Management
In general, lower latency and higher throughput indicate better inference performance. However, in real scenarios, throughput is significantly more crucial than latency.
As long as latency remains under 2 seconds, users are not very sensitive to it. Even waiting a few milliseconds to see the first token won’t noticeably affect the experience.
On the other hand, changes in throughput greatly impact user experience, making users prefer systems with higher throughput. Therefore, when evaluating inference solutions’ performance metrics, we focus on comparing throughput differences, while keeping latency within an acceptable range.
In real-world operations, an inference system concurrently handles multiple user requests to enhance overall system load. However, the concurrency level should not be excessive, as overly high concurrency can actually degrade inference performance. Additionally, the length of user requests and the number of returned tokens also influence performance metrics.
Simplified Evaluation Patterns
To extract patterns from complex business scenarios, our evaluation method simplifies appropriately while closely aligning with business settings.
Fixed Ratios and Lengths
We set fixed ratios and lengths for request inputs and outputs, such as (1000,100), (3000,300), (5000,500), and precisely control input and output lengths when sending requests.
Testing Rounds and Metrics Calculation
After preparing tens of thousands of requests, we send requests to the inference server in fixed batch sizes for testing rounds, simulating numerous users continuously sending requests and maintaining a stable level of concurrency in the inference system.
Performance Metrics
Based on the data from each testing round, we calculate latency and throughput metrics for all requests and compile statistics on different percentile indicators like P50, P90, P99 to reflect more realistic performance.
Additionally, we calculate the total throughput of all input and output tokens in a testing round, combine it with hardware costs, and derive the price per million tokens for the inference system.
Cost-Effectiveness Analysis
Following this evaluation approach, we generate several sets of test data based on varying input-output lengths and batch sizes, send them to the inference service, and calculate two key metrics: the price per million tokens and the output token rate per second (TPS) per request.
We then plot these metrics on a graph with price as the x-axis and TPS as the y-axis. By evaluating more hardware specifications using the same method and plotting the results on the graph, we create an overview of cost-effectiveness.
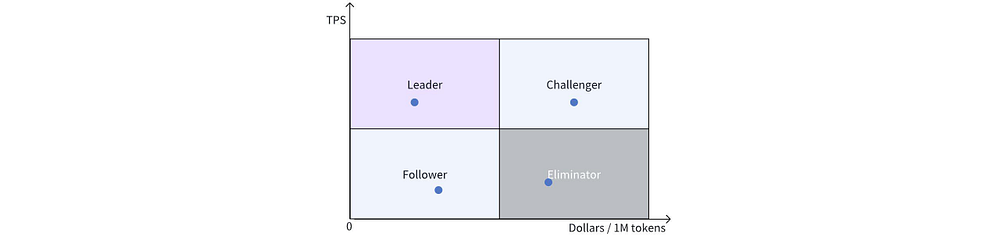
To facilitate comparison among different solutions, we divide the graph into four quadrants:
Top Left: Leader quadrant, with the highest performance and lowest price.
Bottom Left: Follower quadrant, with attractive price but needing performance improvements.
Top Right: Challenger quadrant, leading in performance but with a higher price, possibly from cutting-edge and expensive hardware solutions, which could challenge the leaders if prices decrease.
Bottom Right: Obsolete solutions lacking advantages in both price and performance.
Implementation Method
Our evaluation goal is to identify the most cost-effective GPU hardware. To ensure meaningful comparisons, we will fix the model, inference engine, and request data, only changing the GPU hardware under the same testing conditions. During the evaluation, we will select mainstream open-source models, datasets, and inference engines, primarily using NVIDIA-series GPU hardware.
Model Selection
We will use the Llama 3.1 series models, specifically the Llama 3.1–70B model (Hugging Face link). This model size typically requires multi-GPU inference, making it suitable for assessing inter-GPU communication performance.
Inference Engine
The inference engine will be vLLM v0.6.3. For the dataset, we will focus on QA pairs, choosing ShareGPT-v3-unfiltered as the most appropriate option. When constructing request data, we will iterate through the ShareGPT dataset, filtering QA pairs based on input length to retain only those that are equal to or exceed a specified value, keeping only the questions (with appropriate trimming if too long) as the request prompt.
GPU Specifications Selection
When selecting GPU specifications, we will evaluate mainstream GPUs, specifically the H100, A100, and RTX 4090, across low, mid, and high-end categories. A common approach is to rent GPU servers with an 8-card configuration on cloud platforms, such as our website, Novita AI, which offers convenient pay-as-you-go options. Additionally, we may include more GPU specifications to broaden the evaluation scope, ultimately aiming to populate the four quadrants with a variety of GPUs and inference strategies.
Initiating the Evaluation
Once the preparations are complete, the evaluation can be initiated by following these steps:
Step 1: Start the Inference Engine
To start the vLLM inference engine on your target GPU server, you can quickly create a Docker container instance. For an 8-card 4090 GPU server, use the following command:
docker run -d --gpus all --net=host vllm/vllm-openai:v0.6.3 --port 8080 --model meta-llama/Llama-3.1-70B-Instruct --tensor-parallel-size 8 --swap-space 16 --gpu-memory-utilization 0.9 --dtype auto --served-model-name llama31-70b --max-num-seqs 32 --max-model-len 32768 --enable-prefix-caching --enable-chunked-prefill --disable-log-requests
Step 2: Construct and Send Requests
On the client side, construct requests based on input/output lengths and batch sizes, and send them in bulk to the server. We can also refer to the built-in test cases provided by vLLM to write test scripts that meet our evaluation requirements
Here are key points to consider when constructing requests:
- Data Filtering from ShareGPT
While iterating through all conversation entries in the ShareGPT dataset, note that the first element of each conversation is the question, and the second element is the corresponding answer. You only need the question as the prompt for your requests.
To ensure that the number of tokens in the question meets the input length requirements, you may need to trim the question appropriately. Additionally, in the parameter list for each request, set max_tokens to the specified output length and ignore_eos to true to force the inference engine to output the specified number of tokens.
- Consistent Batch Size
In each testing round, always maintain the same batch size. To achieve this, the client should send a fixed number of requests in parallel and immediately resend a request as soon as one is completed. This ensures that the testing conditions remain consistent and allows for accurate performance measurements.
Each request’s parameters can be configured as follows:
{
"model": "llama31-70b",
"prompt": prompt_content,
"temperature": 0.8,
"top_p": 1.0,
"best_of": 1,
"max_tokens": output_len,
"ignore_eos": true
}
Step 3: Collecting Metrics Data
After all requests are completed, the following key metrics should be collected:
For each request: First Token Latency (TTFT) = First_Token_Time — Send_Req_Time
For each request: Tokens Per Second (TPS) = Total_Output_Tokens / (Finish_Req_Time — First_Token_Time)
For a round of testing: Total System Throughput = Sum(Input_Tokens_Per_Req + Output_ Tokens_Per_Req) / Total_Seconds
Where TTFT and TPS refer to each request, and for convenience in calculations, you can use the P90 percentile of all requests in a testing round.
Total system throughput indicates the total number of tokens (including both input and output tokens) that the inference service can handle per second. Dividing the price of the corresponding GPU server by the total throughput allows you to derive the cost per million tokens.
In practical scenarios, server utilization and request fluctuations may also affect throughput, and a factor can be applied to account for these influences, though this generally does not impact the evaluation conclusions.
Key Findings on GPU Performance and Cost-Effectiveness
We conducted an in-depth evaluation of major GPUs (H100, A100, RTX 4090) using the aforementioned testing methods. For each GPU, we calculated performance metrics (TTFT, TPS) at various input/output lengths and batch sizes, deriving the P50, P90, and P99 percentiles. We also referenced the rental prices of mainstream GPU cloud platforms (available at Novita AI) to calculate the cost per million tokens. This data will serve as the foundation for further cost-performance evaluations and guide us to our final assessment conclusions.
Single Inference Performance Comparison
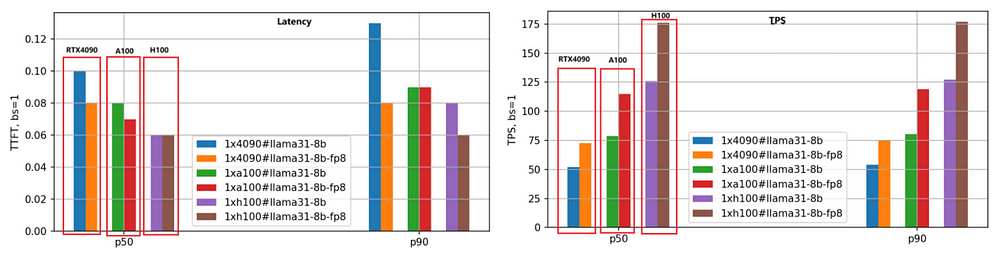
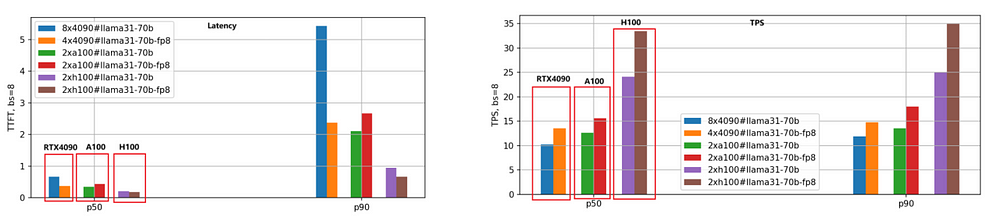
The primary focus is on latency (First Token Latency) and throughput (Tokens Per Second). A lower latency is preferable, while a higher TPS is desired. We evaluated both the BF16 and FP8 versions of the Llama-3.1–8B and Llama-3.1–70B models across the three GPUs, setting each request’s input/output length to 5000/500 and testing different batch sizes. Below are the performance comparison results for the Llama-3.1–8B model, using P50 data for analysis.
- First Token Latency:
The speed ranking from fastest to slowest is H100, A100, and RTX 4090. When the batch size is set to 1, A100’s speed is 1.25 times that of RTX 4090, and H100 is 1.66 times faster.
As the batch size increases, the gap between RTX 4090 and the other two GPUs widens significantly. When the batch size reaches 10, the latency for RTX 4090 exceeds 3.5 seconds (P90 percentile), which is unacceptable for many business applications. In contrast, A100 and H100 maintain latencies below 0.5 seconds, showing stable performance.
2. Tokens Per Second (TPS):
This metric reflects the generation speed of the engine, with the same speed ranking: H100, A100, and RTX 4090. With a batch size of 1, A100’s TPS is approximately 1.48 times that of RTX 4090, and H100’s TPS is 2.44 times that of RTX 4090, indicating H100’s highest generation efficiency.
As batch size increases, the TPS for individual requests gradually declines due to increased system load and reduced resources per request. When the batch size is 10, TPS drops to about 70% of the TPS with batch size 1.
3. FP8 Model Quantization:
The FP8 version, with weight files reduced by half compared to BF16, significantly lowers the system resource overhead, resulting in improved latency and throughput. The second set of bar graphs clearly illustrates this conclusion, particularly in the TPS metric, where the FP8 version’s performance is approximately 1.4 times that of the BF16 version for the same GPU.
4. Sensitivity of RTX 4090 to Batch Size:
Due to memory and communication limitations, RTX 4090 is highly sensitive to batch size. Excessively large batch sizes can lead to internal queuing, resulting in higher latency and lower throughput. Special attention must be paid to batch size settings when deploying workloads on RTX 4090.
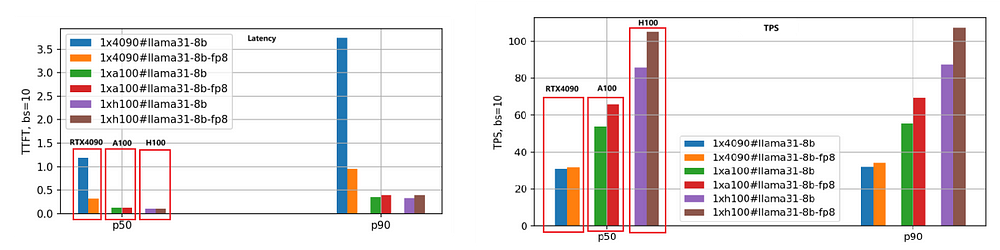
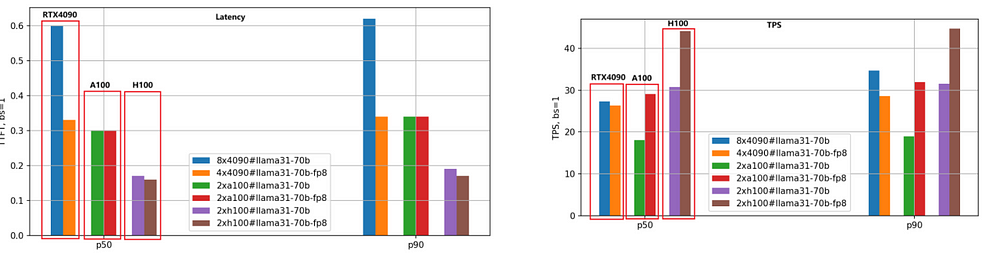
We employed the same evaluation method for the Llama-3.1–70B model, and the performance comparison is illustrated in the following figure.
Given the large size of the 70B model, we utilized 8 RTX 4090 GPUs for the BF16 version and 4 RTX 4090 GPUs for the FP8 version. In contrast, both A100 and H100 GPUs, with their 80GB of memory, required only 2 units to run effectively.
From the figure, we can draw conclusions similar to those for the Llama-3.1–8B model: the H100 remains the highest-performing GPU, and the FP8 quantization version is approximately 1.4 times faster than the BF16 version.
Comprehensive Cost-Performance Evaluation
In practical deployment, it is essential to consider not only performance metrics but also the overall cost of the solutions to identify the best cost-performance ratio.
For instance, while the RTX 4090 may be slower in terms of performance, its very low price could make its overall cost-effectiveness competitive. To achieve this, we need more scientific and professional evaluation methods to accurately determine which GPU and inference solution offer the best value.
In our “Evaluation Approach,” we propose plotting the costs and performance metrics of different inference solutions on a two-dimensional coordinate system, dividing the space into four quadrants: Leaders, Followers, Challengers, and Eliminators. Following this approach, we focused on testing the Llama-3.1–70B, Llama-3.1–8B models, and their FP8 quantization versions.
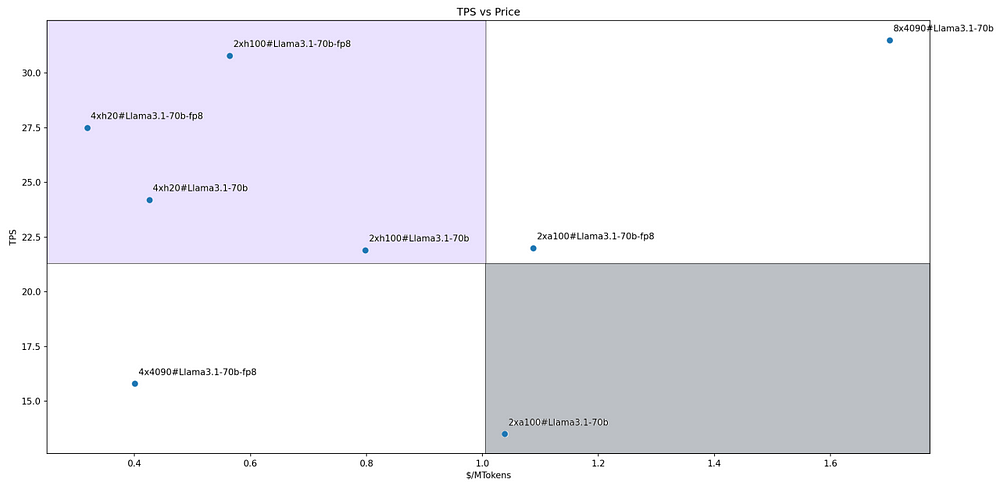
We selected four GPUs: RTX 4090, A100, H100, and H200, setting the input/output length to 5000/500 and batch sizes ranging from 1 to 10. We tested various combinations to obtain performance and pricing data, which were ultimately plotted in the two figures below.
For the Llama-3.1–70B model, the cost-performance ratios of each solution are illustrated in the figure. Four solutions fall into our defined Leader quadrant:
Llama3.1–70B-FP8@2xH100
Llama3.1–70B-FP8@4xH200
Llama3.1–70B@4xH200
Llama3.1–70B@2xH100
In the figure, the slope of the line connecting each solution’s coordinate point to the origin represents the ratio of performance to price. A steeper slope indicates a higher cost-performance ratio.
Therefore, the solution Llama3.1–70B-FP8@4xH200 stands out as the most cost-effective option among all the evaluated inference solutions.
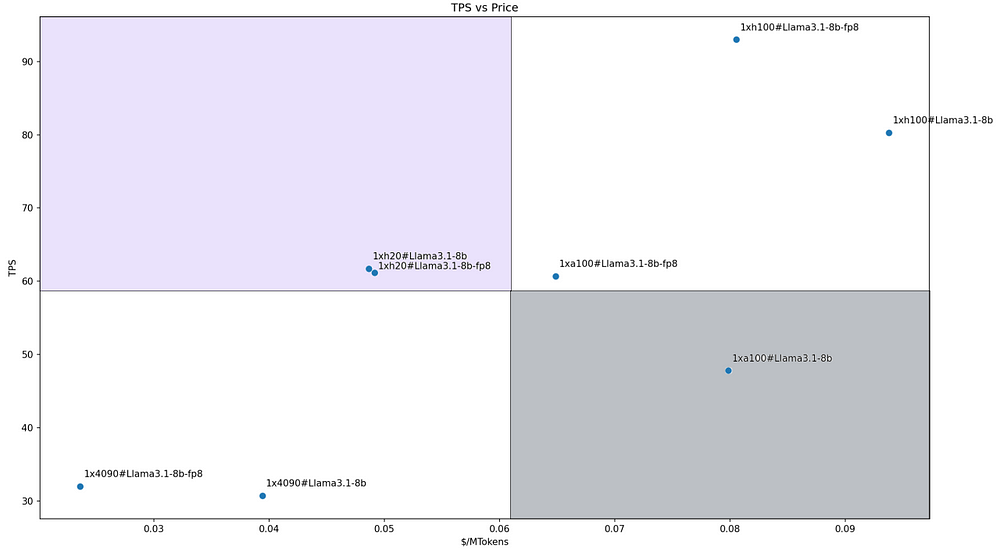
For the Llama3.1–8B model, due to its smaller size, we deployed all models using a single GPU configuration. The cost-performance ratios of the various solutions are illustrated in the figure below. Both configurations with H200 fall into our defined Leader quadrant.
This is primarily due to H200’s good performance (especially its leading memory capacity and bandwidth) and competitive pricing. The two RTX 4090 configurations are the most cost-effective, but due to their poorer performance, they fall into the Follower quadrant.
Conclusion
GPU costs represent a significant portion of large model inference services, and with the multitude of GPU hardware options available in the market, selecting the most suitable one can be challenging. Identifying the best cost-performance GPU and inference solution tailored to specific business needs is crucial, as it can determine the success or failure of the business.
Through our experience in providing large model inference services, we have accumulated substantial deployment knowledge and developed an effective GPU evaluation framework that continuously guides business development, offering clients the best cost-performance inference services.
This article distills best practices from practical applications and conducts real-world tests on mainstream large models and GPU specifications, providing performance comparisons to identify the best cost-performance inference solutions.
Our evaluation approach transcends complex hardware metrics, focusing on practical business applications, making it highly generalizable and actionable — especially suitable for comparative testing across various GPU models or inference engines.
Check out Novita AI for more info on top-notch large model inference services and solutions!
Originally published at Novita AI
Novita AI is the All-in-one cloud platform that empowers your AI ambitions. Integrated APIs, serverless, GPU Instance — the cost-effective tools you need. Eliminate infrastructure, start free, and make your AI vision a reality.
Subscribe to my newsletter
Read articles from NovitaAI directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by