Overcoming Data on Kubernetes Challenges
 Kunal Kushwaha
Kunal Kushwaha
Today, many organizations are adopting Kubernetes to manage containerized applications. While Kubernetes is excellent at orchestrating stateless applications, handling data in such a dynamic and flexible environment presents unique challenges. Kubernetes wasn’t initially designed for stateful workloads or persistent storage, which brings about various data management issues. In this blog, I’ll discuss the key challenges organizations face when managing data on Kubernetes and explore potential solutions.
Key Challenges with Data on Kubernetes
As more companies rely on Kubernetes to run their applications, managing data in these dynamic environments presents distinct challenges. Kubernetes is effective at orchestrating applications, but it wasn’t originally designed for stateful applications or persistent storage. This creates several data management hurdles, including:
Stateful Applications: Running applications that need to retain data, such as databases, can be challenging on Kubernetes. Since Kubernetes was initially built for stateless tasks, managing stateful applications becomes more complex, requiring additional considerations and configurations.
Persistent Storage: Ensuring data persistence when Kubernetes Pods restart, crash, or move is essential yet challenging. Storage systems that don’t integrate seamlessly with Kubernetes make it difficult to maintain data persistence across these events.
Data Portability: Transferring data between Kubernetes clusters or across different cloud platforms is complex. Each platform handles storage differently, which adds to the difficulty of moving data across environments.
Backup and Disaster Recovery: Establishing reliable backup and disaster recovery strategies for Kubernetes data typically requires additional tools, adding complexity and workload for operations teams.
Performance and Scalability: While Kubernetes efficiently scales applications, ensuring storage scalability without performance degradation is a challenge. As applications grow, it’s crucial that storage scales just as effectively to maintain performance.
Introduction to NetApp

NetApp is a cloud-focused, data-centric software company offering solutions for data storage, management, and security across various environments. Known for integrating simplicity, performance, and flexibility into their storage systems, NetApp provides several tools to address the specific challenges of managing data in Kubernetes environments.
Some key NetApp solutions include:
NetApp Trident: Trident is NetApp’s open-source dynamic storage provisioner that integrates with Kubernetes to manage persistent storage. It automates storage provisioning and management, helping Kubernetes applications access storage when needed without requiring manual intervention.
Stateful Workload Management: NetApp supports the management of stateful applications, like databases, in Kubernetes. By integrating with NetApp, organizations can ensure data persistence and availability, even if Pods are restarted or relocated, offering stability for critical applications.
Scalable Persistent Storage: NetApp’s ONTAP technology provides scalable persistent storage, ensuring data remains accessible as Kubernetes applications grow. This solution is designed to adapt to dynamic Kubernetes environments where Pods and services change frequently.
Data Fabric for Kubernetes: NetApp’s Data Fabric helps facilitate data movement between different cloud providers or on-premises environments. This aids organizations in managing data across multiple Kubernetes clusters or cloud providers, minimizing the complexities of handling diverse storage systems.
Backup and Recovery with Cloud Volumes ONTAP: With Cloud Volumes ONTAP, NetApp includes integrated backup and recovery features to protect Kubernetes data, reducing the need for third-party solutions and supporting secure data recovery in case of unexpected events.
Performance Optimization: NetApp offers high-performance storage options with tuning capabilities to meet the demands of Kubernetes applications. This is especially important for scaling stateful workloads to handle increases in traffic or data volume.
Amazon FSx for NetApp ONTAP and Kubernetes:
By using Amazon FSx for NetApp ONTAP as a persistent storage solution for Kubernetes, businesses can integrate scalable and reliable storage seamlessly into their Kubernetes workflows. FSxN provides a fully managed ONTAP experience, allowing teams to deploy and manage storage without needing to manage the underlying infrastructure. This is particularly beneficial in containerized environments, where agility, performance, and scalability are essential.
In this section, I'll demonstrate how to create a NetApp ONTAP File System (FSxN) to serve as persistent storage in an AWS EKS cluster. For this demo, I referred to the official GitHub Repository for FSxN Sample Scripts for guidance.
Step 1: Clone and Setup Environment
You can clone the above GitHub repository and change the variables.tf file to configure with your AWS account. Make sure to double check the region and key pair section before moving ahead in the demo.
Initilize the terraform environment using the below command:
terraform init
You can double check the terraform configuration and services that will run using the below command
terraform plan
Use the below command to create all the required services using terraform
terraform apply
It might take few minutes to create all the services, once everything is up and running you will see the below output
eks-cluster-name = "fsx-eks-z25hUXNa"
eks-jump-server = "Instance ID: i-03c76c449de131c28, Public IP: 18.218.245.19"
fsx-id = "fs-04a96bf27fb521125"
fsx-management-ip = "198.19.255.178"
fsx-password-secret-arn = "arn:aws:secretsmanager:us-east-2:892502952503:secret:fsx-eks-secret-9e43f2ed-He8KBN"
fsx-password-secret-name = "fsx-eks-secret-9e43f2ed"
fsx-svm-name = "ekssvm"
region = "us-east-2"
svm-password-secret-arn = "arn:aws:secretsmanager:us-east-2:892502952503:secret:fsx-eks-secret-f856cac5-22VRBK"
svm-password-secret-name = "fsx-eks-secret-f856cac5"
vpc-id = "vpc-00cf839179014016d"
Make note of the above output as in the later phases of the demo, you will have to refer to the values from above.
Step 2: Access the Jump Server
The above terraform configuration will create a jump server, you can SSH into the jump server using the below command to access other services.
ssh -i <path_to_key_pair> ubuntu@<jump_server_public_ip>
<jump_server_public_ip> is the IP address of the jump server that was displayed in the output of step 1.
Once you run the above command, you should get the below as output to confirm that the SSH is completed
Welcome to Ubuntu 22.04.5 LTS (GNU/Linux 6.8.0-1015-aws x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/pro
System information as of Fri Oct 11 19:09:20 UTC 2024
System load: 0.0 Processes: 110
Usage of /: 34.3% of 7.57GB Users logged in: 0
Memory usage: 4% IPv4 address for eth0: 10.0.4.222
Swap usage: 0%
* Ubuntu Pro delivers the most comprehensive open source security and
compliance features.
https://ubuntu.com/aws/pro
Expanded Security Maintenance for Applications is not enabled.
0 updates can be applied immediately.
Enable ESM Apps to receive additional future security updates.
See https://ubuntu.com/esm or run: sudo pro status
*** System restart required ***
To run a command as administrator (user "root"), use "sudo <command>".
See "man sudo_root" for details.
Configure AWS CLI using the below command in this jump server, you will be required to enter your access key and secret associated with it.
aws configure
Allow access to the EKS cluster for your user id
Add the EKS access-entry by running below commands
aws eks create-access-entry --cluster-name $cluster_name --principal-arn $user_ARN --region $aws_region
aws eks associate-access-policy --cluster-name $cluster_name --principal-arn $user_ARN --region $aws_region --policy-arn arn:aws:eks::aws:cluster-access-policy/AmazonEKSClusterAdminPolicy --access-scope type=cluster
The above command uses three environment variables, you can also configure the same using the below detials
aws_region=<AWS_REGION>
- AWS_REGION will be the region you have configured your services in.
cluster_name=<EKS_CLUSTER_NAME>
- Fetch EKS_CLUSTER_NAME cluster name from the output of step 1.
user_ARN=<ARN_VALUE>
- ARN_VALUE can be fetched using the below command
aws sts get-caller-identity --query Arn --output text
You need to also configure kubectl to use the EKS cluster which can be done using the below command
aws eks update-kubeconfig --name $cluster_name --region $aws_region
Output
Added new context arn:aws:eks:us-east-2:892502952503:cluster/fsx-eks-z25hUXNa to /home/ubuntu/.kube/config
To verify the correct working of kubectl, you can run the below command to fetch the number of nodes in your cluster
kubectl get nodes
Output
NAME STATUS ROLES AGE VERSION
ip-10-0-1-59.us-east-2.compute.internal Ready <none> 96m v1.29.8-eks-a737599
ip-10-0-2-136.us-east-2.compute.internal Ready <none> 96m v1.29.8-eks-a737599
Step 3: Creating and Checking Status of Astra Trident
Astra Trident is added in EKS Cluster using the terraform configuration in the trident namespace, you can check the same using the below command
kubectl get pods -n trident
Output
NAME READY STATUS RESTARTS AGE
trident-controller-5cb86cfcc7-pl9lr 6/6 Running 0 96m
trident-node-linux-m54wr 2/2 Running 0 96m
trident-node-linux-zbx8f 2/2 Running 1 (96m ago) 96m
trident-operator-799447549c-s5m65 1/1 Running 0 97m
In this scenario we are going to set up an NFS file system for a MySQL database and for that we are going to set up Astra Trident as a backend provider. We will have to configure the trident CSI backend to use FSx for NetApp ONTAP.
To perform the above you will have to change the directory to FSx-ONTAP-samples-scripts/EKS/FSxN-as-PVC-for-EKS and create a directory inside this path named temp. You will need to export few values as environment variables such as FSX_ID, FSX_SVM_NAME and SECRET_ARN.
with the FSxN ID.
with the name of the SVM that was created.
with the ARN of the AWS SecretsManager secret that holds the SVM password (not the FSxN password).
You can fetch all of the above values from the output of step 1.
Substitute these values in the required config file such as manifests/backend-tbc-ontap-nas.tmpl and create a new file in the temp folder named temp/backend-tbc-ontap-nas.yaml
Do the above process using the below commands
cd ~/FSx-ONTAP-samples-scripts/EKS/FSxN-as-PVC-for-EKS
mkdir temp
export FSX_ID=<fsx-id>
export FSX_SVM_NAME=<fsx-svm-name>
export SECRET_ARN=<secret-arn>
envsubst < manifests/backend-tbc-ontap-nas.tmpl > temp/backend-tbc-ontap-nas.yaml
Create and configure the trident backend using the below command
kubectl create -n trident -f temp/backend-tbc-ontap-nas.yaml
You can check the if the backend has been configured correctly using the below command
kubectl get tridentbackendconfig -n trident
If everything has configured correctly you will receive the below output else the STATUS might appear as failed
NAME BACKEND NAME BACKEND UUID PHASE STATUS
backend-fsx-ontap-nas backend-fsx-ontap-nas 3b8eac55-ed26-4071-8c15-c15094cf81b9 Bound Success
If the status is Failed, then you can add the "--output=json" option to the kubectl get tridentbackendconfig command to get more information as to why it failed. Specifically, look at the "message" field in the output. The following command will get just the status messages
kubectl get tridentbackendconfig -n trident --output=json | jq '.items[] | .status.message'
Step 4: Create Necessary Kubernetes Services and Applications
1. Create a Storage Class
Use the below command to create
kubectl create -f manifests/storageclass-fsxn-nas.yaml
Check the creation using the below command
kubectl get storageclass
Output
fsx-basic-nas csi.trident.netapp.io Delete Immediate true 7s
gp2 (default) kubernetes.io/aws-ebs Delete WaitForFirstConsumer false 131m
2. Create a Stateful Application
- Create a Persistent Volume Claim using below command
kubectl create -f manifests/pvc-fsxn-nas.yaml
Check the creation using the below command
kubectl get pvc
Output
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE
mysql-volume-nas Bound pvc-b2f521ca-6dca-412c-ba88-c8d37728dd94 50Gi RWO fsx-basic-nas <unset> 9s
- Deploy a MySQL Database using the below command
kubectl create -f manifests/mysql-nas.yaml
Check the creation using the below command
kubectl get pods
Output
NAME READY STATUS RESTARTS AGE
mysql-fsx-nas-6b9455f5f8-hrjpj 1/1 Running 0 28s
3. Check the File System
If you want to see what was created on the FSxN file system, you can log into it and take a look. Run the below command to ssh
ssh -l fsxadmin <fsx-management-ip>
This command will prompt for a password which you can easily fetch from AWS SecretsManager
You can list the volumes created in the file system using the below command and will receive a relevant output with trident pvc created eariler
volume show
Output
FsxId04a96bf27fb521125::> volume show
Vserver Volume Aggregate State Type Size Available Used%
--------- ------------ ------------ ---------- ---- ---------- ---------- -----
ekssvm ekssvm_root aggr1 online RW 1GB 972.4MB 0%
ekssvm trident_pvc_b2f521ca_6dca_412c_ba88_c8d37728dd94
aggr1 online RW 50GB 49.94GB 0%
2 entries were displayed.
4. Access the MySQL Database
Log into MySQL instance using the below command
kubectl exec -it $(kubectl get pod -l "app=mysql-fsx-nas" --namespace=default -o jsonpath='{.items[0].metadata.name}') -- mysql -u root -p
The above command will ask for a password, which in this scenario is Netapp1!
Now you can create databases and tables in the database and populate it with some data
mysql> create database fsxdatabase;
Query OK, 1 row affected (0.00 sec)
mysql> use fsxdatabase;
Database changed
mysql> create table fsx (filesystem varchar(20), capacity varchar(20), region varchar(20));
Query OK, 0 rows affected (0.04 sec)
mysql> insert into fsx (`filesystem`, `capacity`, `region`) values ('netapp01','1024GB', 'us-east-1'),
-> ('netapp02', '10240GB', 'us-east-2'),('eks001', '2048GB', 'us-west-1'),('eks002', '1024GB', 'us-west-2'),
-> ('netapp03', '1024GB', 'us-east-1'),('netapp04', '1024GB', 'us-west-1');
Query OK, 6 rows affected (0.01 sec)
Records: 6 Duplicates: 0 Warnings: 0
To check if the above data is stored use the below command to fetch stored data from the table create above
select * from fsx;
Output
+------------+----------+-----------+
| filesystem | capacity | region |
+------------+----------+-----------+
| netapp01 | 1024GB | us-east-1 |
| netapp02 | 10240GB | us-east-2 |
| eks001 | 2048GB | us-west-1 |
| eks002 | 1024GB | us-west-2 |
| netapp03 | 1024GB | us-east-1 |
| netapp04 | 1024GB | us-west-1 |
+------------+----------+-----------+
6 rows in set (0.00 sec)
5. Create a Snapshot of the MySQL Data
- Install the Kubernetes Snapshot CRDs and Snapshot Controller using the below command
git clone https://github.com/kubernetes-csi/external-snapshotter
cd external-snapshotter/
kubectl kustomize client/config/crd | kubectl create -f -
kubectl -n kube-system kustomize deploy/kubernetes/snapshot-controller | kubectl create -f -
kubectl kustomize deploy/kubernetes/csi-snapshotter | kubectl create -f -
cd ..
- Create a Snapshot Class based on the CRD installed using the below command
kubectl create -f manifests/volume-snapshot-class.yaml
Output
volumesnapshotclass.snapshot.storage.k8s.io/fsx-snapclass created
- Create a Snapshot of the MySQL Data
kubectl create -f manifests/volume-snapshot-nas.yaml
Check if the creation was successful using the below command
kubectl get volumesnapshot
Output
NAME READYTOUSE SOURCEPVC SOURCESNAPSHOTCONTENT RESTORESIZE SNAPSHOTCLASS SNAPSHOTCONTENT CREATIONTIME AGE
mysql-volume-nas-snap-01 true mysql-volume-nas 63788Ki fsx-snapclass snapcontent-15275f4b-fe13-413d-b6a3-cb367b7e848e 11s 11s
Step 5: Cloning MySQL Data
After creating the snapshot of the data, you can use it to create a read/write version. This can be used as a new storage volume for another mysql database.
Create a PVC from the snapshot using the below command
kubectl create -f manifests/pvc-from-nas-snapshot.yaml
You can check the creation using the below command
kubectl get pvc
Output
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE
mysql-volume-nas Bound pvc-b2f521ca-6dca-412c-ba88-c8d37728dd94 50Gi RWO fsx-basic-nas <unset> 32m
mysql-volume-nas-clone Bound pvc-3df52819-2c6f-414f-a471-280840f8dbf1 50Gi RWO fsx-basic-nas <unset> 3s
Create a new MySQL database using the below command
kubectl create -f manifests/mysql-nas-clone.yaml
Check the creation using the below command
kubectl get pods
Output
NAME READY STATUS RESTARTS AGE
csi-snapshotter-0 3/3 Running 0 9m15s
mysql-fsx-nas-6b9455f5f8-hrjpj 1/1 Running 0 30m
mysql-fsx-nas-clone-8fd7f675d-n9v2g 1/1 Running 0 70s
Step 6: Verifing the Data
Check the status of new database by logging into it using the below command, password will be same as Netapp1!
kubectl exec -it $(kubectl get pod -l "app=mysql-fsx-nas-clone" --namespace=default -o jsonpath='{.items[0].metadata.name}') -- mysql -u root -p
Check for the data populated eariler in this newly created database
mysql> use fsxdatabase;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> select * from fsx;
+------------+----------+-----------+
| filesystem | capacity | region |
+------------+----------+-----------+
| netapp01 | 1024GB | us-east-1 |
| netapp02 | 10240GB | us-east-2 |
| eks001 | 2048GB | us-west-1 |
| eks002 | 1024GB | us-west-2 |
| netapp03 | 1024GB | us-east-1 |
| netapp04 | 1024GB | us-west-1 |
+------------+----------+-----------+
6 rows in set (0.00 sec)
You can also navigate to AWS console to check the creation of File system, volumes and other services
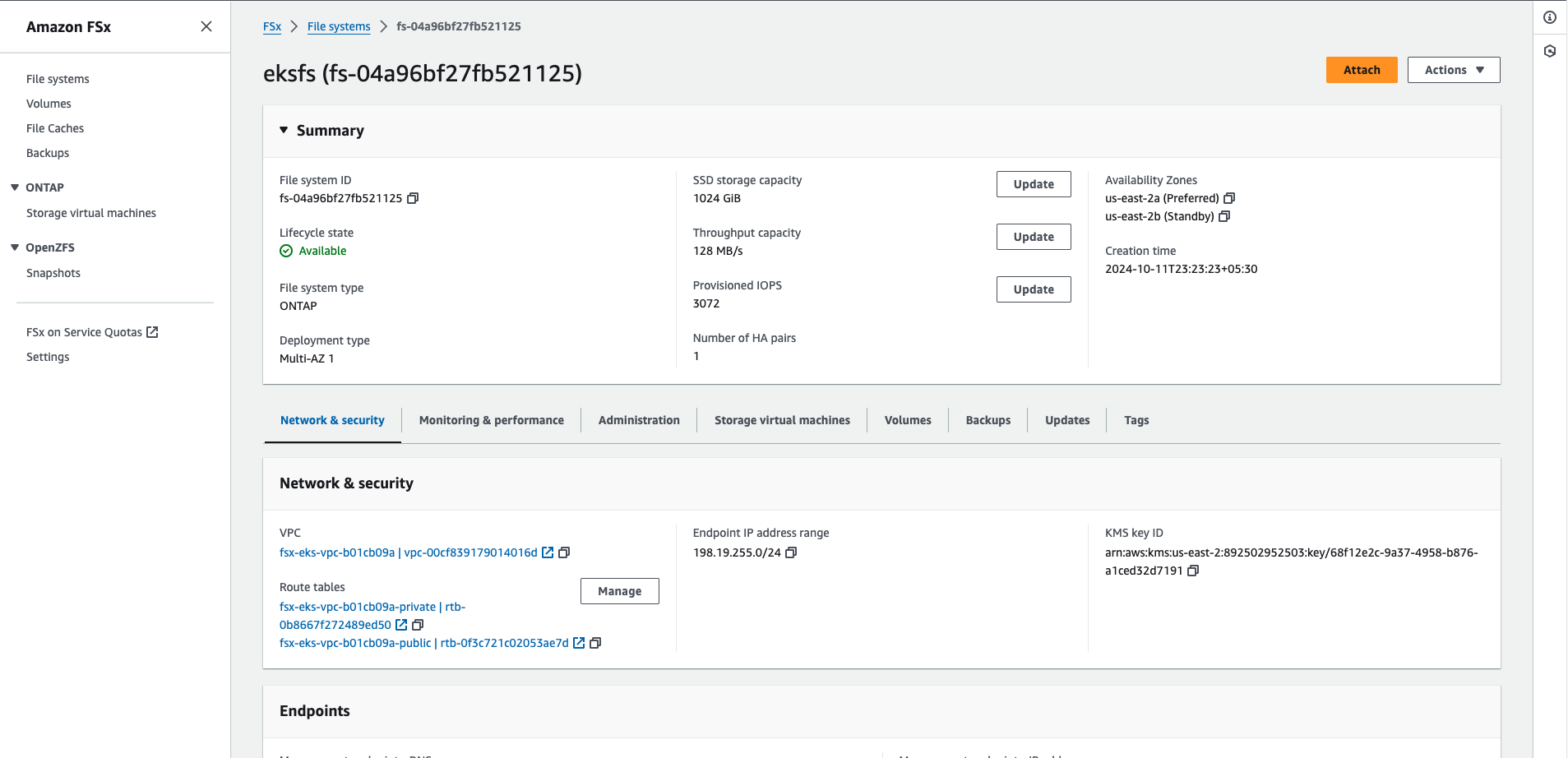
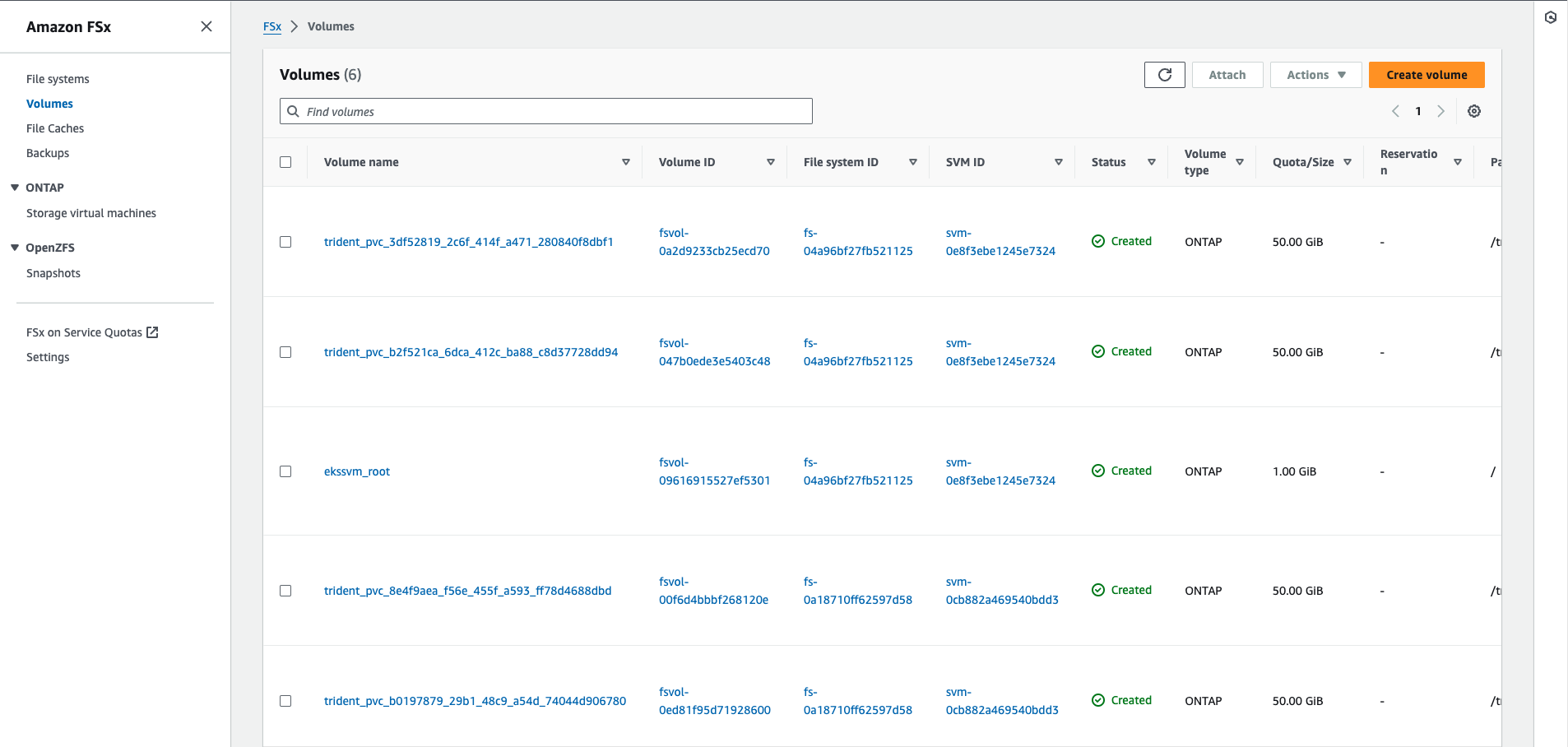
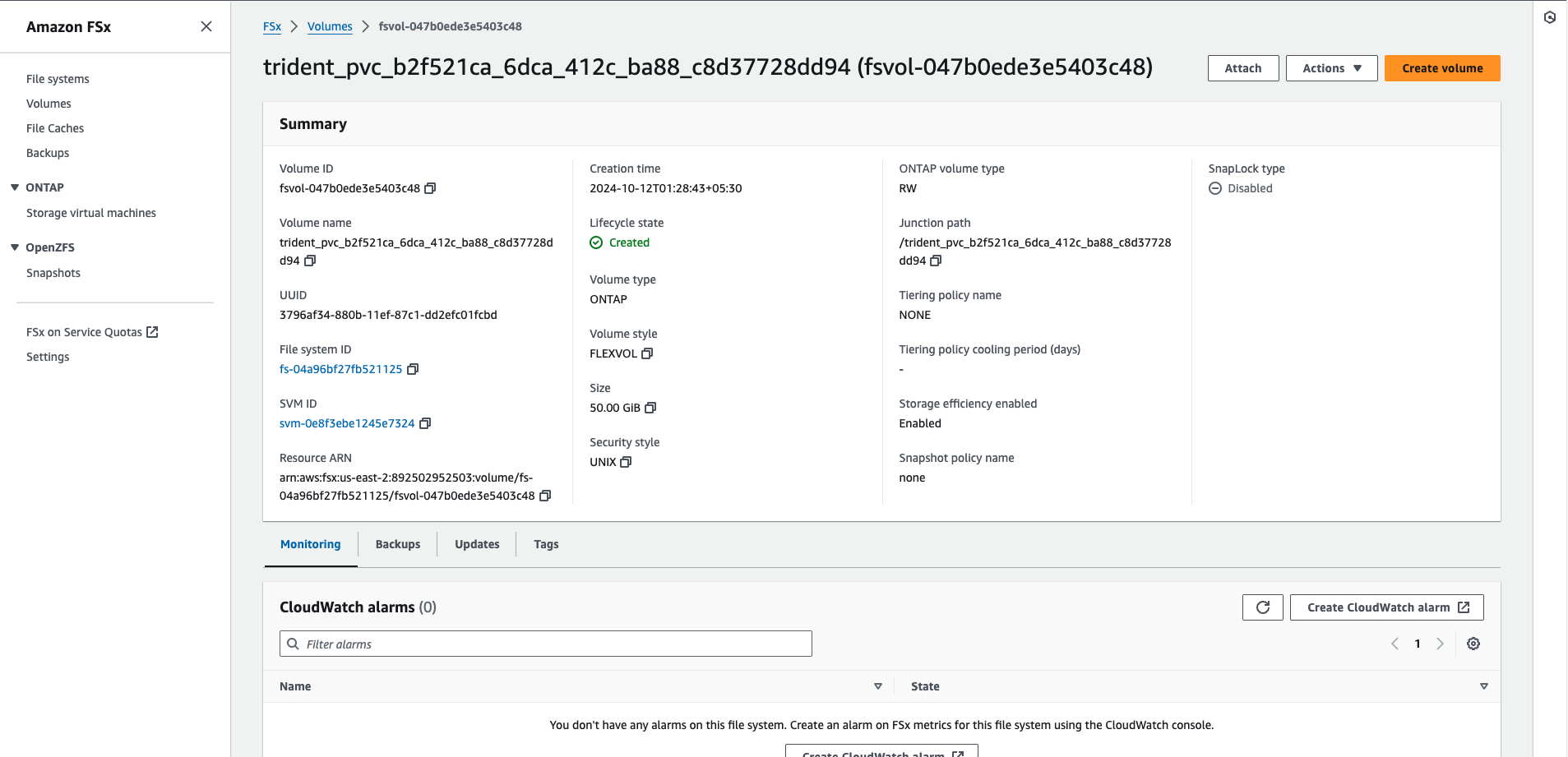
Features of NetApp
Hybrid Cloud Data Services: NetApp offers seamless data management across cloud and on-premises environments, helping organizations simplify operations and support digital transformation initiatives.
NetApp ONTAP AI: ONTAP AI combines NVIDIA DGX systems with NetApp all-flash storage to streamline data flow for AI/ML workloads, reducing design complexities and allowing for independent scaling of compute and storage.
Scalability: NetApp solutions allow businesses to start small and scale as needed, optimizing cost and performance for a wide range of workloads.
AI Control Plane: The NetApp AI Control Plane integrates with Kubernetes and Kubeflow, offering scalability and persistent data availability for AI and ML applications.
Persistent Storage with NetApp Trident: Trident provides seamless integration of persistent volumes with Kubernetes, simplifying data management and supporting containerized workloads effectively.
Data Fabric: NetApp’s Data Fabric supports data portability and availability across edge, core, and cloud environments, enabling businesses to move and access data flexibly.
Comprehensive Data Protection: NetApp offers robust security, backup, and disaster recovery solutions, ensuring data is secure and recoverable across different environments.
Ideal Market
The ideal market for NetApp includes:
Enterprise IT: Large organizations needing scalable, efficient storage solutions for DevOps workflows and hybrid cloud environments.
Cloud-Native Companies: Startups and technology firms managing data across multi-cloud platforms.
DevOps Teams: Teams focused on automating storage provisioning and supporting CI/CD pipelines and agile development processes.
Data-Intensive Sectors: Industries such as healthcare, finance, and retail with high demands for data storage and backup.
NetApp serves businesses that prioritize efficient, scalable, and cloud-integrated data management.
Conclusion
Managing data in Kubernetes environments presents various challenges, including handling stateful applications, ensuring persistent storage, and maintaining scalability. Although Kubernetes primarily focuses on orchestrating containerized applications, it wasn't initially designed for stateful workloads, making data management complex. Solutions like NetApp can address these challenges by providing integration, scalability, and performance optimization, enabling organizations to run stateful workloads on Kubernetes without the added data management burdens. Whether it's securing persistent storage, streamlining backup and recovery, or optimizing performance at scale, NetApp supports businesses in managing their data efficiently within today’s dynamic cloud-native landscape.
Shoutout to NetApp for collaborating with me on this blog.
Subscribe to my newsletter
Read articles from Kunal Kushwaha directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by