문자 인코딩 탐구 - Part 1: 문자 집합, ASCII, 유니코드, UTF-32 등
 정승아
정승아Table of contents
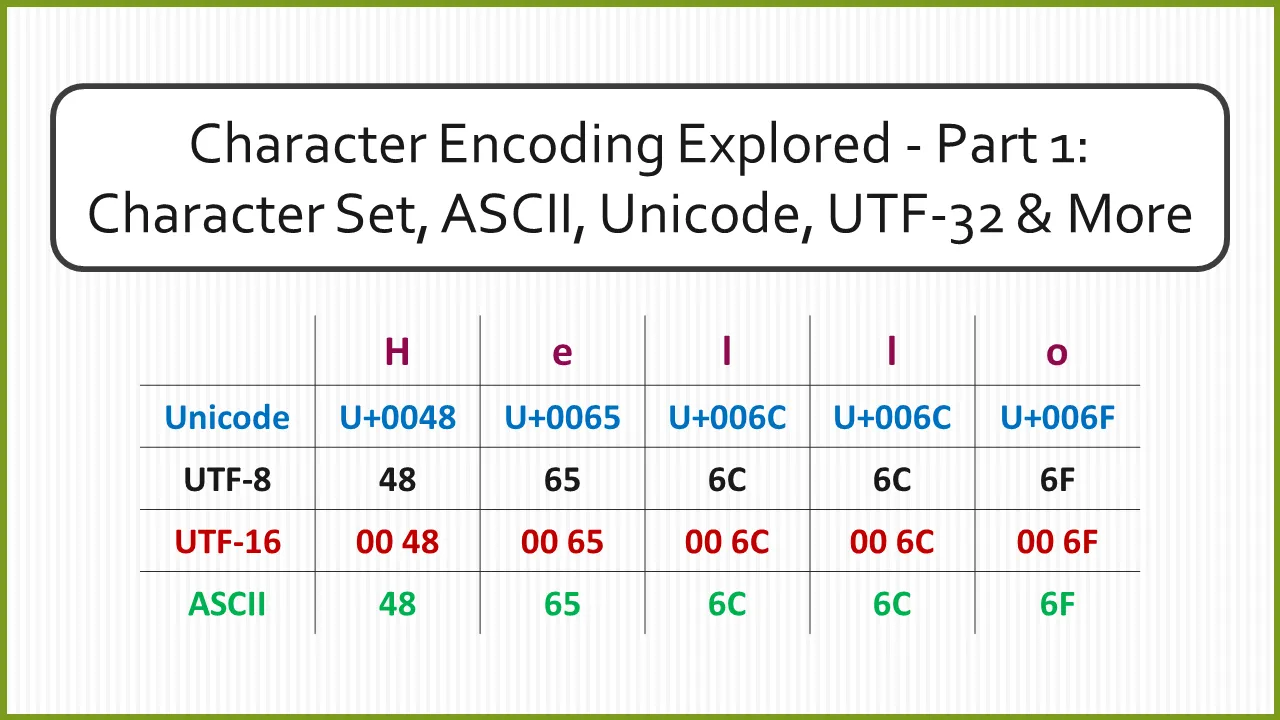
원문: David Varghese, "Character Encoding Explored - Part 1: Character Set, ASCII, Unicode, UTF-32 & More"
컴퓨터가 왜 문자를 인코딩해야 하는지 이해하려면 먼저 컴퓨터가 데이터를 처리하는 방식을 알아야 합니다. 컴퓨터는 데이터를 1과 0으로 이루어진 시스템을 통해 처리합니다. 숫자 42든 문자 d든, 컴퓨터가 이해할 수 있도록 1과 0의 스트림으로 변환되어야 합니다. 숫자의 경우, 42를 이진수 체계로 변환하면 컴퓨터가 이해할 수 있는 00101010으로 나타낼 수 있습니다. 하지만 문자인 d는 어떻게 표현할까요? 아시아 언어에서 사용되는 문자나 이모지는 어떻게 표현할 수 있을까요? 이러한 숫자가 아닌 문자를 컴퓨터에서 표현하기 위해 해결책으로 나온 것이 바로 모든 문자를 숫자 값으로 매핑하는 인코딩 표준입니다. 이 숫자 값은 이후 이진수로 변환되어 컴퓨터가 처리할 수 있게 됩니다.
일반 용어
문자 집합
문자 집합 또는 문자 목록은 단순히 순서가 없는 문자들의 집합을 의미합니다. 라틴 알파벳이나 그리스 알파벳이 문자 집합의 예입니다.
부호화된 문자 집합
부호화된 문자 집합은 목록에 있는 각 문자를 정수 값에 매핑합니다. 즉, 각 문자는 문자 집합에서 특정한 위치에 할당됩니다. 부호화된 문자 집합에서 문자를 나타내는 정수를 "코드 포인트"라고 합니다. 부호화된 문자 집합 내 모든 문자를 매핑하는 데 필요한 숫자의 범위를 "코드 공간"이라고 합니다.
참고로, 문자 집합이라는 용어는 부호화된 문자 집합을 가리키는 데도 자주 사용됩니다. 이 글에서는 문자 집합을 부호화된 문자 집합을 의미하는 용어로 사용하겠습니다.
ASCII
ASCII는 매우 널리 사용되고 쉽게 이해할 수 있는 문자 인코딩 표준입니다. ASCII는 제어 문자, 아라비아 숫자, 라틴 문자, 그리고 구두점 문자를 0에서 127까지의 숫자에 매핑합니다.
제어 문자는 비인쇄 문자(NPC)라고도 불리며, 문자를 표시하거나 기호를 나타내지 않는 문자들입니다. 이 문자는 컴퓨터에게 특별한 동작을 수행하도록 지시하는 데 사용됩니다. 예를 들어, 벨소리 울리기, 화면 지우기, 다음 문자의 위치 제어 등이 있습니다. 제어 문자에는 탭, 줄바꿈 등이 포함됩니다.
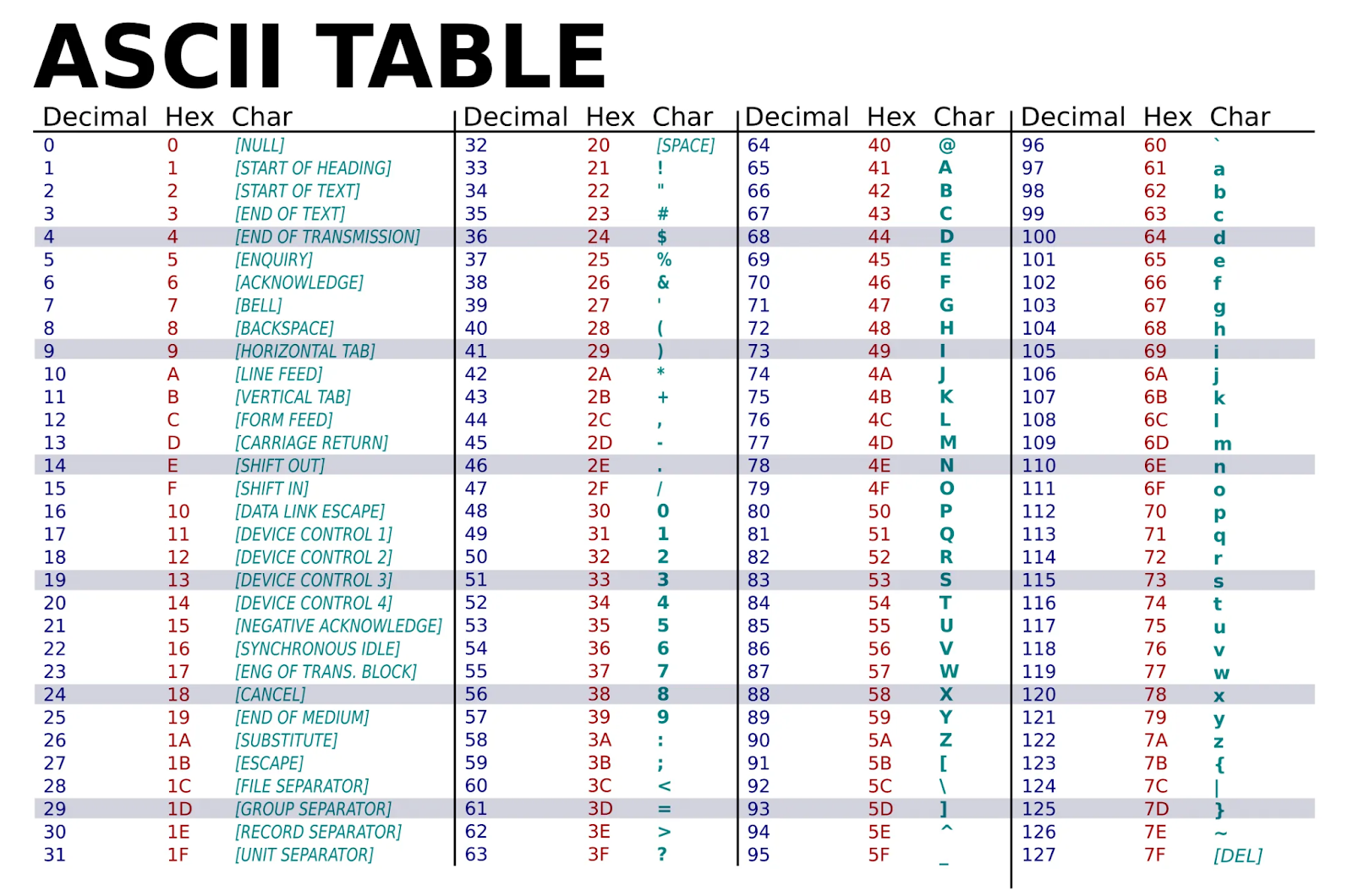
ASCII에서 사용되는 문자 집합은 ASCII라고도 불리며, 128개의 문자로 구성됩니다. 이 128개의 문자를 이진수로 표현하려면 7비트($2⁷ = 128$)가 필요합니다. 예를 들어 "Hello"라는 문자열을 ASCII로 변환하려면, ASCII 표에서 각 문자의 코드 포인트를 찾아야 합니다. 그런 다음, 이 코드 포인트들을 이진수로 변환하고, 마지막으로 모든 문자의 이진수 표현을 연결하여 컴퓨터가 사용할 수 있는 문자열 버전을 얻습니다. 문자를 문자 집합을 이용해 이진수로 표현하는 과정을 "문자 인코딩"이라고 합니다. 문자열을 다시 해독하려면, 이 과정의 반대 순서를 밟으면 됩니다.

왜 7비트일까, 왜 8비트인 바이트로 하지 않았을까 궁금할 수 있습니다. ASCII는 바이트 개념이 보편화되기 훨씬 전에 만들어졌습니다. 당시에는 8비트를 바이트라고 부르는 개념조차 확립되지 않았던 시기였습니다.
8비트가 널리 사용된 후에 출시된 ASCII 나열은 각 문자를 8비트로 인코딩했습니다. 인코딩된 각 문자에서 는 MSB는 오류 수정에 사용되었습니다. 오늘날 ASCII는 8비트로 표현되며, 최상위 비트는 0으로 설정됩니다.
MSB(최상위 비트): 비트 스트림에서 가장 큰 값을 가지는 비트로, 일반적으로 가장 왼쪽에 위치한 비트를 의미합니다.
하지만 ASCII에는 큰 단점이 있었습니다. 바로 128개의 문자만 표현할 수 있는 코드 공간이 너무 작았다는 점입니다. 이 코드 공간은 다른 언어의 문자를 표현하기에 충분하지 않았고, 이는 결국 확장 ASCII의 탄생으로 이어졌습니다.
확장 ASCII
확장 ASCII는 각 문자를 8비트($2⁸ = 256$)로 인코딩하는 문자 인코딩 표준입니다. 확장 ASCII는 기존 ASCII 문자 집합에 추가로 128개의 문자를 포함합니다. 하지만 "확장 ASCII"에 대한 공식 정의는 존재하지 않았습니다. 그 결과, 각 나라나 조직이 확장 코드 공간에 서로 다른 문자를 할당했습니다. 그 결과, 확장 ASCII를 사용하여 인코딩할 수 있는 수많은 문자 집합이 만들어졌습니다. 이로 인해 확장 ASCII를 사용해 인코딩된 데이터를 정확히 해독하려면 어떤 문자 집합이 사용되었는지 알아야 했습니다.
코드 페이지
Microsoft와 Oracle 같은 벤더의 제품을 사용할 때 "코드 페이지"라는 용어를 접할 수 있습니다. 코드 페이지는 문자 집합을 가리키는 또 다른 용어입니다. 이 용어는 IBM이 메인프레임 시스템에서 여러 문자 집합을 지원하기 위해 만든 마케팅 용어입니다. ASCII와 관련된 코드 페이지는 보통 첫 127개의 코드 포인트가 기존 ASCII 문자를 나타내며, 상위 128개의 코드 포인트(128~255값)는 각 코드 페이지마다 상당히 달랐습니다. 각 코드 페이지는 확장 ASCII의 다른 변형을 나타냈습니다.
ASCII와 확장 ASCII는 당시 가장 인기 있는 문자 인코딩 방식이었지만, 그 외에도 많은 나라에서 각자의 문자 인코딩을 개발하거나 ASCII의 변형을 사용했습니다. 예를 들어, 일본은 일본어 문자를 표현하기 위해 여러 인코딩 표준을 만들었고, 이 표준들은 서로 호환되지 않았습니다. 이로 인해 컴퓨터 간 데이터 전송 시 문자가 깨져서 나타나는 일이 빈번히 발생했으며, 일본어에서는 이를 설명하는 단어인 "모지바케(文字化け)"가 생기기도 했습니다.
인터넷이 등장하고 전 세계적으로 통신이 보편화되면서, 호환되지 않는 다양한 인코딩 표준의 사용은 큰 문제로 대두되었습니다. 이를 해결하기 위해 유니코드 컨소시엄이 설립되었습니다. 이 그룹은 전 세계 주요 문자는 물론 이모지 같은 기호를 포함한 표준을 설계하는 임무를 맡았습니다.
유니코드 용어
자소(Grapheme)
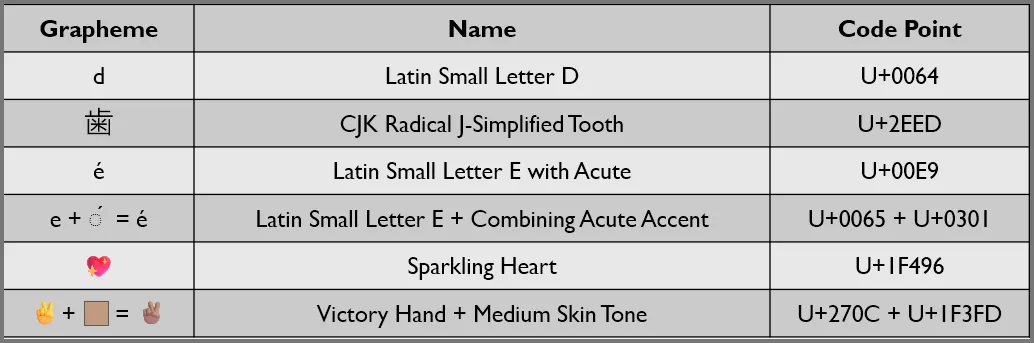
자소는 글쓰기 시스템에서 가장 작은 기능 단위입니다. 예를 들어, cat의 c나 朋友의 朋은 모두 자소의 예입니다. 유니코드에서는 일반 사용자가 하나의 문자라고 생각하는 것을 자소라는 용어로 표현합니다.
코드 포인트
코드 포인트는 문자 집합에서 자소를 고유하게 나타내는 숫자(인덱스)입니다. 유니코드에서 하나의 자소는 하나 이상의 코드 포인트로 구성될 수 있습니다.
예를 들어, é라는 자소는 유니코드에서 하나의 코드 포인트로도, 두 개의 코드 포인트를 조합하여도 표현될 수 있습니다.
https://www.compart.com/en/unicode
유니코드 코드 포인트는 대부분 16진수로 표현됩니다. 숫자 앞에 붙는
U+표기는 선택 사항이지만, 해당 숫자가 유니코드 코드 포인트임을 명확히 하기 위해 사용됩니다.
인코딩(Encoding)
인코딩은 코드 포인트를 이진수로 변환하는 과정입니다. 예를 들어, ASCII는 코드 포인트를 이진수로 직접 변환하는 단일 인코딩 방식입니다. 유니코드에서도 다양한 인코딩 방식이 있으며, 이를 통해 코드 포인트를 컴퓨터가 이해할 수 있는 이진수로 변환합니다.
코드 유닛(Code Unit)
코드 유닛은 인코딩 방식이 문자를 표현하기 위해 사용하는 비트 수를 의미합니다. 흔히 사용되는 문자 인코딩 방식에서는 8비트, 16비트, 32비트의 코드 유닛을 사용합니다. 예를 들어, ASCII는 문자를 인코딩하는 데 7비트의 코드 유닛을 사용했으며, 확장 ASCII는 8비트의 코드 유닛을 사용하여 문자를 표현했습니다.
유니코드(Unicode)
유니코드는 ASCII와 유사하게 문자 집합을 의미합니다. 유니코드의 목표는 단일 문자 집합을 통해 우리가 필요로 하는 모든 문자를 표현할 수 있는 시스템을 개발하는 것이었습니다. 유니코드 표준은 약 110만 개의 고유한 그래프림을 표현할 수 있으며, 현재 유니코드 문자는 5.1 기준으로 약 15만 개의 코드 포인트가 사용 중입니다. 즉, 약 96만 개의 코드 포인트는 아직 할당되지 않았습니다.
유니코드에는 현재 널리 사용되는 세 가지 인코딩 방식이 있습니다. 각 인코딩 방식은 고유한 장점과 단점을 가지고 있으므로, 애플리케이션에 적합한 인코딩 방식을 선택하기 전에 이러한 특성을 신중하게 고려해야 합니다.
플레인(Planes)과 블록(Blocks)
유니코드의 코드 공간은 플레인이라 불리는 그룹으로 나누어집니다. 플레인은 연속적인 65,536개($2^{16}$)의 코드 포인트로 이루어진 그룹입니다. 유니코드는 0번부터 16번까지 총 17개의 플레인으로 구성되어 있습니다. 각 플레인은 다시 블록으로 나뉩니다. 플레인과 달리, 블록은 고정된 크기를 가지고 있지 않습니다. 플레인과 블록은 유니코드 표준을 관련된 문자들로 그룹화하는 데 사용됩니다. 플레인은 문자 빈도나 시대(현대, 고대)와 같은 일반적인 속성을 기준으로 문자를 그룹화하고, 블록은 언어 및 일반적인 응용 분야에 따라 문자를 그룹화합니다. 현재 사용 중인 대부분의 유니코드 문자(유니코드 15.1 기준)는 첫 번째 세 개의 플레인에 위치해 있습니다.
https://en.wikipedia.org/wiki/Plane_(Unicode)
플레인 0: 기본 다국어 플레인(BMP)
이 플레인에는 거의 모든 현대 언어의 문자가 포함되어 있습니다. 특히 많은 코드 포인트가 CJK 문자(중국어, 일본어, 한국어)를 나타내는 데 사용됩니다. 유니코드 15.1 기준으로, BMP에는 164개의 블록이 포함되어 있으며, 범위는 0x0000-0xFFFF입니다. UTF-16은 이 플레인의 모든 문자를 단일 16비트 코드 유닛으로 표현할 수 있습니다.
플레인 1: 보조 다국어 플레인(SMP)
이 플레인에는 주로 고대 문자와 특정 분야에서 사용되는 기호 및 표기가 포함되어 있습니다. 유니코드 15.1 기준으로, SMP에는 151개의 블록이 있으며, 범위는 0x10000-0x1FFFF입니다.
플레인 2: 보조 표의문자 플레인(SIP)
이 플레인은 BMP에 포함되지 않은 CJK 문자를 나타내는 데 사용됩니다. 이 플레인은 7개의 블록으로 구성되어 있으며, 범위는 0x20000-0x2FFFF입니다.
플레인 3: 제3 표의문자 플레인(TIP)
이 플레인은 2개의 블록으로 이루어져 있으며, 유니코드 15.1 기준으로 소수의 드물게 사용되는 CJK 문자가 포함됩니다. 범위는 0x30000-0x3FFFF입니다.
플레인 4–13: 미할당 플레인
이 10개의 플레인에는 아직 어떠한 문자도 할당되지 않았습니다. 범위는 0x40000-0xDFFFF입니다.
플레인 14: 보조 특수 목적 플레인(SSP)
이 플레인은 2개의 블록으로 구성되어 있으며, 범위는 0xE0000-0xEFFFF입니다.
플레인 15–16: 사용자 지정 영역 플레인(SPUA)
이 두 플레인은 사용자 지정 용도로 예약되어 있습니다. SPUA-A와 SPUA-B로 불리며, 특정 조직 내에서 특별한 의미를 가질 수 있는 문자를 나타내기 위해 사용됩니다. 유니코드 표준에서는 이 플레인에 문자를 할당하지 않을 것입니다. SPUA는 0xF0000-0x10FFFF 범위를 차지합니다.
UTF-32 인코딩
유니코드에서 지원하는 인코딩 방식 중 하나로, 각 코드 포인트를 4바이트 또는 32비트로 인코딩합니다. 32비트의 스트림은 "더블 워드"라고도 불립니다.
예를 들어, द(데바나가리 문자 Da)는 코드 포인트 U+0926을 가지고 있으며, 이는 10진수로 2342에 해당합니다. 이 문자의 이진 인코딩 형태는 00000000 00000000 00000100 100100110가 됩니다. 32비트보다 짧은 코드 포인트는 앞쪽에 0을 채워서 표현됩니다. 모든 그래프림이 4바이트(32비트)로 인코딩되므로, UTF-32는 고정 길이 인코딩 방식입니다.
아래 예시는 문자열 "Hello"를 UTF-32로 인코딩한 결과를 보여줍니다. 공간을 절약하기 위해 16진수로 인코딩 결과를 나타냈습니다.
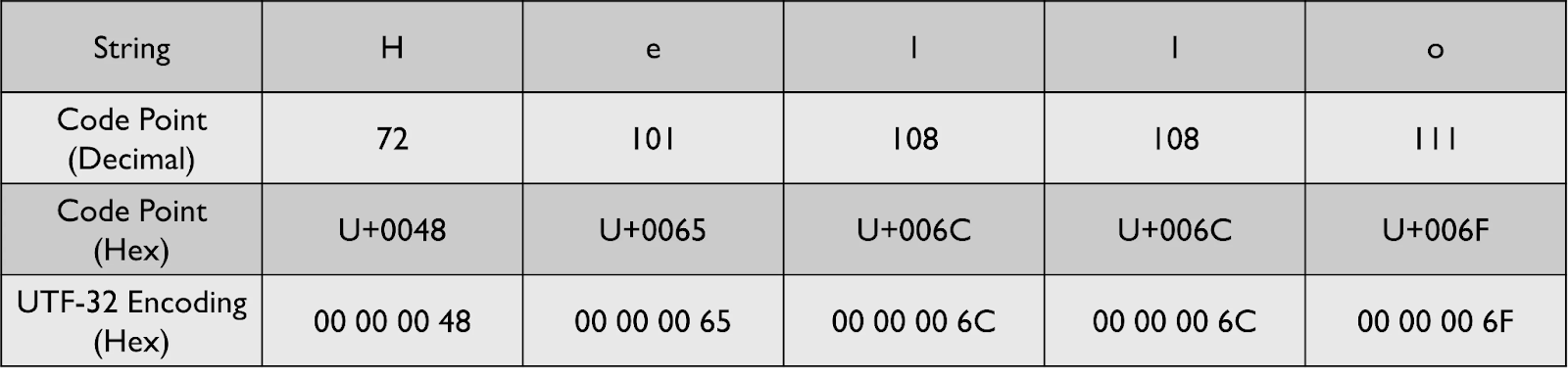
UTF-32의 주요 장점은 각 코드 포인트가 고정된 길이로 인코딩된다는 점입니다. 따라서, 만약 00 00 00 48 00 00 00 65 00 00 00 6C와 같은 스트림이 주어진다면, 새로운 코드 포인트가 어디서 시작하는지 쉽게 알 수 있습니다. 매 4번째 16진수 쌍이 새로운 코드 포인트가 되기 때문에, UTF-32 스트림에서 n번째 코드 포인트를 찾는 작업은 매우 간단해집니다.
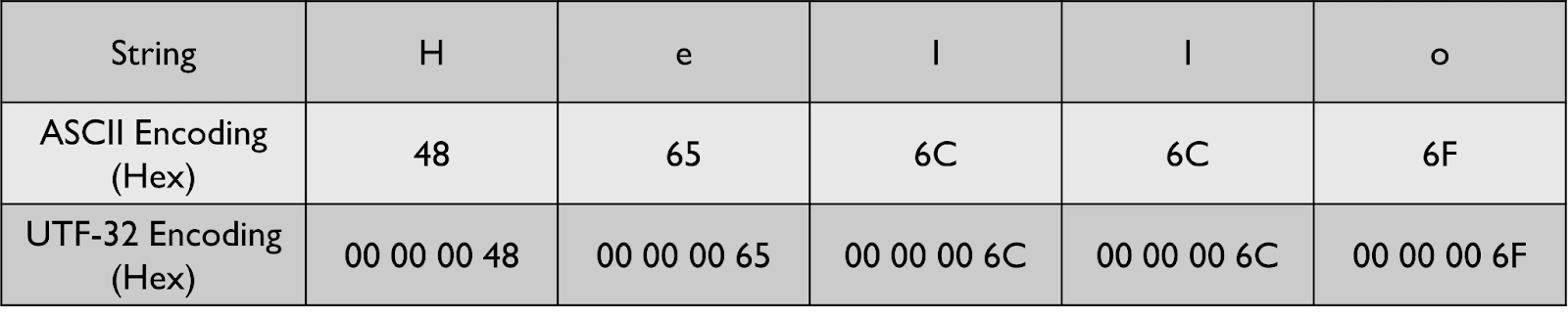
이 인코딩 방식의 가장 큰 단점은 공간 비효율성입니다. UTF-32는 각 그래프림을 인코딩하는 데 ASCII보다 4배 많은 공간을 필요로 합니다. 또한, UTF-32는 ASCII와 하위 호환되지 않기 때문에, ASCII만을 이해하는 오래된 프로그램과의 통신에 사용할 수 없습니다. 게다가, 일부 오래된 장치들은 연속된 8개의 0을 전송 종료 신호로 사용합니다. 반면, UTF-32는 연속된 0을 패딩으로 사용하므로, 이러한 장치들과 통신을 시도하면 전송이 항상 조기 종료될 위험이 있습니다.
결론
지금까지 인코딩에 대해 이야기할 때 사용되는 몇 가지 용어와 ASCII와 확장 ASCII를 살펴보았습니다. 이후 유니코드 표준을 살펴보고 유니코드의 코드 공간이 어떻게 플레인과 블록으로 나뉘는지 논의했습니다. 마지막으로, 유니코드에서 지원하는 세 가지 인코딩 방식 중 하나인 UTF-32에 대해 다뤘습니다.
다음 글에서는 남은 유니코드 문자 인코딩 방식에 대해 논의를 이어가고, 인코딩 방식이 자체적으로 동기화 된다는 것이 무엇을 의미하는지 살펴보겠습니다.
만약 방금 읽은 내용이 마음에 드셨다면 다음과 같은 방법으로 응원해 주세요.
• 이 글에 박수 보내기 (최대 50번까지 가능)
• 댓글로 응원의 메시지 남기기
• 이 글이 유용할 것 같은 사람들과 공유하기
• Medium, LinkedIn, GitHub에서 저를 팔로우하기
• Source Code에서 제 글 더 보기
Subscribe to my newsletter
Read articles from 정승아 directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by