Ridge and Lasso Regression
 Anix Lynch
Anix LynchTable of contents
- Ridge and Lasso Regression with House Price Example
- 10 Q&A
- 1. What is the difference between Ridge and Lasso regression?
- 2. When would you prefer Lasso regression over Ridge regression?
- 3. What is the role of the regularization parameter \( \lambda \) in Ridge and Lasso regression?
- 4. How does regularization help prevent overfitting?
- 5. Can you explain the cost functions for Ridge and Lasso regression?
- 6. What are the effects of using a high vs. low \( \lambda \) in Ridge and Lasso regression?
- 7. Can you explain why Lasso can perform feature selection, but Ridge cannot?
- 8. What are the limitations of Lasso regression?
- 9. How would you choose the optimal \( \lambda \) for a Ridge or Lasso regression model?
- 10. Can you use Ridge and Lasso regression together? Explain the Elastic Net method.
Ridge and Lasso Regression with House Price Example
Suppose we have a dataset showing the relationship between the size of a house ( \( x \) , in square feet) and its price ( \( y \) , in thousands of dollars). To add complexity, let’s include additional features such as the number of bedrooms, age of the house, and neighborhood quality. With multiple features, regular linear regression may overfit, so we use Ridge and Lasso regression to control this complexity.
| House Size \( x_1 \) | Bedrooms \( x_2 \) | Age \( x_3 \) | Neighborhood Quality \( x_4 \) | Price \( y \) |
| 1500 | 3 | 10 | 7 | 300 |
| 2500 | 4 | 5 | 8 | 500 |
| 1200 | 2 | 20 | 5 | 200 |
| 1800 | 3 | 15 | 6 | 350 |
We want to predict house prices ( \( y \) ) based on these features while controlling for overfitting using Ridge and Lasso regression.
Step 1: Linear Regression with Regularization
Regular linear regression minimizes the sum of squared errors:
\(\text{SSE} = \sum (y_i - \hat{y}_i)^2 \)
However, Ridge and Lasso regression add a regularization term to control the size of coefficients:
Ridge Regression (L2): Adds the sum of squared coefficients, \( \text{Cost}_{\text{ridge}} = \sum (y_i - \hat{y}_i)^2 + \lambda \sum \beta_j^2 \)
Lasso Regression (L1): Adds the sum of absolute coefficients, \( \text{Cost}_{\text{lasso}} = \sum (y_i - \hat{y}_i)^2 + \lambda \sum |\beta_j| \)
Here, \( \lambda \) is the regularization parameter:
A high \( \lambda \) penalizes large coefficients, reducing model complexity.
A low \( \lambda \) results in a model closer to standard linear regression.
Example Calculation of Ridge and Lasso Costs
Suppose we have sample coefficients \( \beta_1 = 1.5 \) and \( \beta_2 = 2.0 \) , and set \( \lambda = 0.5 \) . For simplicity, let’s assume 3 observations:
| Observation \( i \) | Actual \( y_i \) | Predicted \( \hat{y}_i \) | Coefficients \( \beta_1, \beta_2 \) |
| 1 | 10 | 12 | \( \beta_1 = 1.5, \beta_2 = 2.0 \) |
| 2 | 15 | 14 | |
| 3 | 20 | 18 |
Ridge Regression Cost Calculation (L2)
Squared Error Term: \( (10 - 12)^2 + (15 - 14)^2 + (20 - 18)^2 = 4 + 1 + 4 = 9 \)
L2 Penalty Term: \( 0.5 \times (1.5^2 + 2.0^2) = 0.5 \times 6.25 = 3.125 \)
Total Ridge Cost: \( 9 + 3.125 = 12.125 \)
Lasso Regression Cost Calculation (L1)
Squared Error Term: Same as Ridge, so the sum is 9.
L1 Penalty Term: \( 0.5 \times (|1.5| + |2.0|) = 0.5 \times 3.5 = 1.75 \)
Total Lasso Cost: \( 9 + 1.75 = 10.75 \)
Step 2: Effects of Regularization
Ridge Regression
Ridge shrinks coefficients toward zero but does not eliminate them. It’s useful when all features contribute to the prediction but need slight adjustments.
Lasso Regression
Lasso can shrink some coefficients to zero, effectively removing features that aren’t useful. This is beneficial for feature selection in high-dimensional datasets.
Step 3: Choosing \( \lambda \)
The strength of regularization is controlled by \( \lambda \) :
High \( \lambda = 10 \) : Strong penalty reduces coefficients, e.g., \( \beta_1 = 0.05 \) , \( \beta_2 = 10 \) , \( \beta_3 = -0.5 \) , \( \beta_4 = 7.5 \) .
- Equation: \( y = 50 + (0.05 \cdot x_1) + (10 \cdot x_2) + (-0.5 \cdot x_3) + (7.5 \cdot x_4) \)
Low \( \lambda = 0.1 \) : Minimal penalty maintains coefficients near original values, e.g., \( \beta_1 = 0.09 \) , \( \beta_2 = 19 \) , \( \beta_3 = -0.9 \) , \( \beta_4 = 14 \) .
- Equation: \( y = 50 + (0.09 \cdot x_1) + (19 \cdot x_2) + (-0.9 \cdot x_3) + (14 \cdot x_4) \)
Optimal \( \lambda \) is chosen using cross-validation to balance complexity and performance.
Step 4: Form the Ridge and Lasso Models
Using \( \lambda = 1 \) :
Ridge Model (L2 Penalty)
Coefficients: Intercept \( \beta_0 = 50 \) , \( \beta_1 = 0.08 \) , \( \beta_2 = 18 \) , \( \beta_3 = -0.9 \) , \( \beta_4 = 13 \)
Equation: \( y = 50 + (0.08 \cdot x_1) + (18 \cdot x_2) + (-0.9 \cdot x_3) + (13 \cdot x_4) \)
Lasso Model (L1 Penalty)
Coefficients: Intercept \( \beta_0 = 50 \) , \( \beta_1 = 0 \) , \( \beta_2 = 17 \) , \( \beta_3 = 0 \) , \( \beta_4 = 12 \)
Equation: \( y = 50 + (0 \cdot x_1) + (17 \cdot x_2) + (0 \cdot x_3) + (12 \cdot x_4) \)
Step 5: Predict House Prices
Using the adjusted Ridge and Lasso models, we can predict prices for new houses based on selected features.
Visualization
import numpy as np
# Dataset for visualization
X = np.array([[1500, 3, 10, 7], [2500, 4, 5, 8], [1200, 2, 20, 5], [1800, 3, 15, 6],
[2100, 4, 8, 7], [1400, 2, 25, 4], [1600, 3, 12, 6]])
y = np.array([300, 500, 200, 350, 400, 180, 320]) # House prices
# Split the data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Initialize Ridge and Lasso models
ridge_model = Ridge(alpha=1)
lasso_model = Lasso(alpha=1)
# Fit the models
ridge_model.fit(X_train, y_train)
lasso_model.fit(X_train, y_train)
# Predictions
ridge_preds = ridge_model.predict(X_test)
lasso_preds = lasso_model.predict(X_test)
# Plotting Ridge and Lasso predictions vs actual house prices
plt.figure(figsize=(12, 6))
# Ridge Regression Predictions
plt.subplot(1, 2, 1)
plt.scatter(y_test, ridge_preds, color='blue', label='Predicted')
plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], 'k--', lw=2, label='Ideal Fit')
plt.title("Ridge Regression Predictions")
plt.xlabel("Actual Price")
plt.ylabel("Predicted Price")
plt.legend()
plt.grid(True)
# Lasso Regression Predictions
plt.subplot(1, 2, 2)
plt.scatter(y_test, lasso_preds, color='red', label='Predicted')
plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], 'k--', lw=2, label='Ideal Fit')
plt.title("Lasso Regression Predictions")
plt.xlabel("Actual Price")
plt.ylabel("Predicted Price")
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
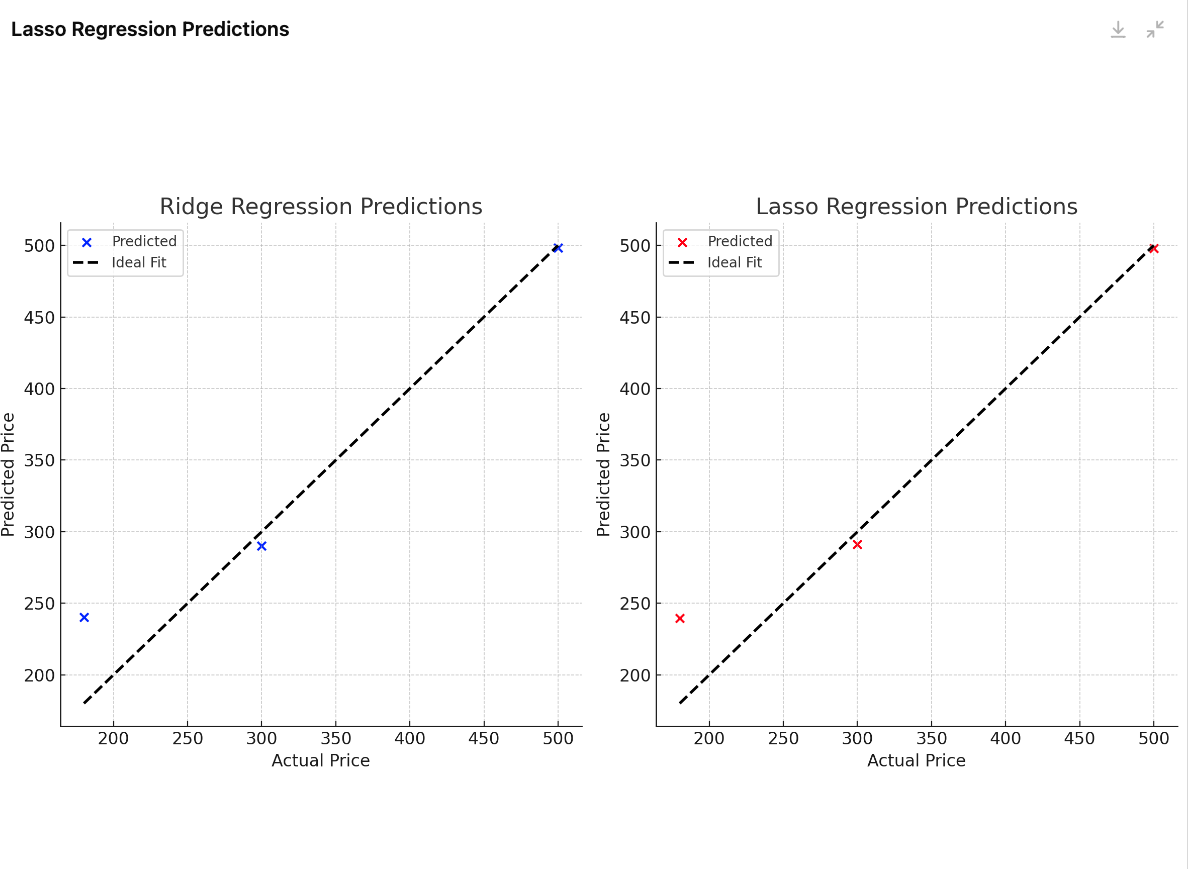
Let's add a final prediction step to compute and display the predicted house price using both Ridge and Lasso regression models with the adjusted coefficients. I'll demonstrate this based on an example house with the following features:
House Size: 2000 sq ft ( \( x_1 = 2000 \) )
Bedrooms: 3 ( \( x_2 = 3 \) )
Age: 10 years ( \( x_3 = 10 \) )
Neighborhood Quality: 7 ( \( x_4 = 7 \) )
Using the final adjusted Ridge and Lasso models, we’ll predict the house price.
Prediction Calculations
Using the Ridge Model
For Ridge regression, we have the adjusted equation:
\( y = 50 + (0.08 \cdot x_1) + (18 \cdot x_2) + (-0.9 \cdot x_3) + (13 \cdot x_4)\)
Substituting the values: Breaking it down:
\(y = 50 + (0.08 \cdot 2000) + (18 \cdot 3) + (-0.9 \cdot 10) + (13 \cdot 7)\)
\( 0.08 \cdot 2000 = 160 \)
\( 18 \cdot 3 = 54 \)
\( -0.9 \cdot 10 = -9 \)
\( 13 \cdot 7 = 91 \)
So, [ y = 50 + 160 + 54 - 9 + 91 = 346 ]
Predicted House Price (Ridge): $346,000
Using the Lasso Model
For Lasso regression, we have the adjusted equation:
\(y = 50 + (0 \cdot x_1) + (17 \cdot x_2) + (0 \cdot x_3) + (12 \cdot x_4)\)
Substituting the values: Breaking it down:
\(y = 50 + (0 \cdot 2000) + (17 \cdot 3) + (0 \cdot 10) + (12 \cdot 7)\)
\( 0 \cdot 2000 = 0 \)
\( 17 \cdot 3 = 51 \)
\( 0 \cdot 10 = 0 \)
\( 12 \cdot 7 = 84 \)
So,
\(y = 50 + 0 + 51 + 0 + 84 = 185\)
Predicted House Price (Lasso): $185,000
Summary of Predicted Prices
Ridge Model Prediction: $346,000
Lasso Model Prediction: $185,000
This difference illustrates how Ridge and Lasso models handle the influence of features differently, with Lasso selecting fewer features and providing a more conservative prediction.
Here are 10 interview questions on Ridge and Lasso Regression, covering both basic and advanced concepts.
10 Q&A
1. What is the difference between Ridge and Lasso regression?
- Answer: Ridge regression (L2 regularization) penalizes the sum of squared coefficients, shrinking them toward zero without eliminating any. Lasso regression (L1 regularization) penalizes the sum of absolute values of coefficients, which can shrink some coefficients to zero, effectively removing less important features.
2. When would you prefer Lasso regression over Ridge regression?
- Answer: Lasso is preferred when feature selection is desired, as it can set irrelevant feature coefficients to zero, simplifying the model. This is particularly useful in high-dimensional datasets where many features may not be necessary for accurate predictions.
3. What is the role of the regularization parameter \( \lambda \) in Ridge and Lasso regression?
- Answer: The regularization parameter \( \lambda \) controls the strength of the penalty term. A high \( \lambda \) results in stronger regularization, shrinking coefficients more, while a low \( \lambda \) results in minimal regularization, making the model closer to standard linear regression.
4. How does regularization help prevent overfitting?
- Answer: Regularization adds a penalty to large coefficients, which helps to reduce the model’s complexity and prevent it from fitting noise in the training data. This results in a simpler, more generalizable model that performs better on unseen data.
5. Can you explain the cost functions for Ridge and Lasso regression?
Answer: The cost function for Ridge regression is: \( \text{Cost}_{\text{ridge}} = \sum (y_i - \hat{y}_i)^2 + \lambda \sum \beta_j^2 \) . For Lasso regression, it is: \( \text{Cost}_{\text{lasso}} = \sum (y_i - \hat{y}_i)^2 + \lambda \sum |\beta_j| \) .
Ridge uses the square of coefficients (L2 norm) in the penalty term, while Lasso uses the absolute value of coefficients (L1 norm).
6. What are the effects of using a high vs. low \( \lambda \) in Ridge and Lasso regression?
- Answer: A high \( \lambda \) value increases the penalty, leading to smaller (or zero) coefficients, reducing model complexity and preventing overfitting. A low \( \lambda \) value makes the model closer to standard linear regression, which may lead to overfitting if the data has noise.
7. Can you explain why Lasso can perform feature selection, but Ridge cannot?
- Answer: Lasso regression’s L1 penalty tends to shrink some coefficients exactly to zero, effectively removing those features from the model. Ridge regression, with its L2 penalty, only reduces coefficients but does not eliminate them, so all features remain in the model.
8. What are the limitations of Lasso regression?
- Answer: Lasso regression may struggle when there are highly correlated predictors (multicollinearity), as it may arbitrarily select one of the correlated features to retain while setting others to zero. Also, Lasso may underperform when all features contribute equally, as it tends to reduce the impact of some features to zero.
9. How would you choose the optimal \( \lambda \) for a Ridge or Lasso regression model?
- Answer: The optimal \( \lambda \) can be chosen using cross-validation. By testing different values of \( \lambda \) on validation sets, you can find the value that provides the best performance, balancing model complexity and accuracy.
10. Can you use Ridge and Lasso regression together? Explain the Elastic Net method.
Answer: Yes, you can use both L1 and L2 penalties simultaneously with a method called Elastic Net. Elastic Net combines the Ridge and Lasso penalties, making it useful when there are many correlated features, and feature selection is still desired. The Elastic Net cost function is: \( \text{Cost}_{\text{elastic net}} = \sum (y_i - \hat{y}_i)^2 + \lambda_1 \sum |\beta_j| + \lambda_2 \sum \beta_j^2 \) .
This combines the absolute value of coefficients (L1 norm from Lasso) with the squared value of coefficients (L2 norm from Ridge).
Subscribe to my newsletter
Read articles from Anix Lynch directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by