Kubernetes Basics: Core Concepts and Components
 Manoj Shet
Manoj ShetIntroduction
In the era of microservices and containerization, Kubernetes has emerged as the go-to platform for managing containerized applications at scale. Originally created by Google and now maintained by the Cloud Native Computing Foundation (CNCF), Kubernetes provides an extensive toolkit for deploying, scaling, and managing applications efficiently across clusters. This guide will introduce Kubernetes fundamentals, dive into its core components, and explore how it streamlines application deployment in cloud-native environments.
What is Kubernetes?
Kubernetes, often abbreviated as K8s, is an open-source platform that automates deployment, scaling, and operations of application containers across clusters of hosts. It helps manage clusters of hosts running containers, making it an essential tool for applications that require resilience, portability, and scalability.
Key Components of Kubernetes
1. Control Plane Components:
A Kubernetes cluster consists of two main parts:
Control Plane (Master Node): Responsible for managing the cluster’s state, the control plane consists of several components that govern scheduling, controller management, and more.
Worker Nodes: These are machines that actually run the applications and are managed by the control plane.
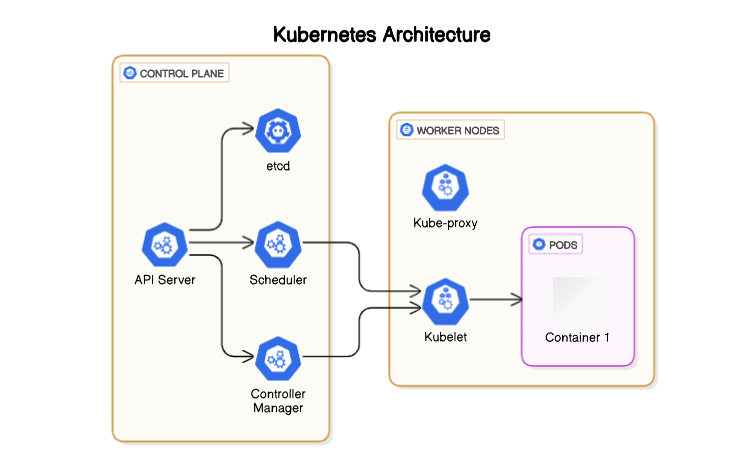
Each part has several subcomponents:
- Control Plane Components:
API Server: Acts as the entry point for all Kubernetes interactions, exposing REST APIs to allow users and components to communicate with the cluster.
etcd: A distributed key-value store that stores all cluster data and state information. It serves as Kubernetes’s primary database, ensuring data consistency across the cluster.
Scheduler: Decides which nodes should run specific pods based on resource availability, constraints, and requirements.
Controller Manager: Oversees various controllers in the cluster (e.g., node, replication, and endpoint controllers). It manages the state and ensures that the desired state is met.
Cloud Controller Manager: Interacts with the underlying cloud provider to manage cloud-specific aspects of the cluster, such as storage volumes, networking, and load balancers.
- Worker Node Components:
Kubelet: An agent that runs on each worker node, responsible for communicating with the control plane to ensure the node is running the desired set of pods.
Kube-Proxy: Manages networking and routing within the node, handling network rules for pod-to-pod and external communication.
Container Runtime: The software that runs containers on each node. This runtime provides the necessary tools to run and manage containers.
2. Pods
Pods are the most basic Kubernetes object. Each pod wraps one or more containers, allowing them to share storage and networking. Pods are typically ephemeral, meaning they’re created and destroyed as needed. If a pod fails, Kubernetes automatically replaces it to maintain application health.
Multi-Container Pods: Some pods may contain multiple containers that are tightly coupled and share resources. This design pattern is often used when a main application container requires a sidecar container, such as a logging or proxy container.
3. ReplicaSets
A ReplicaSet ensures that a specified number of pod replicas are running at any given time. If a pod goes down, the ReplicaSet will replace it, maintaining the desired number of instances.
Benefits of ReplicaSets:
High Availability: Ensures that applications remain up and running.
Auto-Scaling: ReplicaSets can be scaled up or down to meet demand.
Use Case: Imagine you have a web application that should always have three instances running. A ReplicaSet helps enforce this, so if any instance fails, Kubernetes automatically spins up another one.
4.Deployments
Deployments provide declarative updates to applications, managing ReplicaSets and enabling seamless rolling updates and rollbacks.
Rolling Updates: This allows you to update applications gradually. For example, rather than stopping all instances and deploying a new version, Kubernetes replaces pods incrementally, ensuring minimal downtime.
Rollback: If an update fails or causes issues, deployments enable easy rollback to the previous stable version.
5. Services
Kubernetes Services define a logical set of pods and the policies for accessing them. Services provide stable endpoints for accessing an application even if the underlying pods change. Also provide networking within the cluster, defining how pods are accessed by other components or external clients.
Types of Services:
ClusterIP: Exposes the service only within the cluster, making it accessible only to the other pods within the same cluster. It assign the virtual IP address that routes the traffic to the service’s pods, but it cannot be accessed externally. Cluster IP is a default service type and is typically used for internal communication between services within the cluster.
NodePort: This service in Kubernetes exposes a service on a specific port on each node in a cluster. It allows external traffic to access the service by using the node’s IP address and the assigned NodePort. The service routes the traffic to the appropriate pod, with Kubernetes automatically load-balancing the requests. NodePort is useful for development or testing environments but less secure for production use.
LoadBalancer: This service in Kubernetes exposes a service externally by creating an external load balancer that routes traffic to the service's pods. It assigns a public IP address, allowing external clients to access the service. This type is typically used in cloud environments where a cloud provider can provision the load balancer automatically, offering a scalable and fault-tolerant solution.
ExternalName: This service in Kubernetes allows you to map a service to an external DNS name, rather than a cluster-internal IP. It doesn't create a proxy or load balancer but instead directs traffic to the specified external DNS name. This type is useful for integrating with external services outside the Kubernetes cluster without exposing them directly to the internal network.
6. ConfigMaps and Secrets
ConfigMap: A ConfigMap in Kubernetes stores non-sensitive configuration data as key-value pairs, allowing you to separate configuration from application code. It can be used to provide settings like database URLs or feature flags to pods. ConfigMaps can be accessed by pods as environment variables, command-line arguments, or files. They help make applications more flexible by allowing configuration changes without modifying code. Updates to ConfigMaps automatically propagate to the pods using them.
Secrets: stores sensitive data, such as passwords, API keys, and certificates, in an encoded format. It is similar to a ConfigMap but is designed for sensitive information, ensuring it is not exposed in plaintext. Secrets can be used by pods as environment variables or mounted as files. Kubernetes provides mechanisms to control access to Secrets, ensuring only authorized services can access sensitive data.
7. Namespaces
Namespace in Kubernetes is a logical partition used to organize resources within a cluster. It allows multiple teams or projects to share the same cluster while isolating their resources, such as pods, services, and deployments. Namespaces help manage resource allocation, access control, and simplify the management of resources by grouping them under unique names. By default, Kubernetes has a default namespace, but can create custom namespaces to separate different environments or applications. Resources in different namespaces are isolated from each other, but they can still communicate if needed through explicit configuration.
Use Cases: Namespaces are often used to separate environments like development, staging, and production or to provide isolation for different teams or projects.
8. Persistent Volumes and Persistent Volume Claims
Persistent Volumes: Persistent Volume (PV) in Kubernetes is a piece of storage in the cluster that has been provisioned by an administrator. PVs are independent of the lifecycle of pods and provide a reliable way to store data persistently, even if a pod is deleted or recreated. PVs can be backed by different storage backends, such as local disks, network-attached storage (NAS), or cloud storage services like AWS EBS or GCE Persistent Disks.
Persistent Volume Claims: Persistent Volume Claim (PVC) is a request by a user or application for storage resources in Kubernetes. PVCs allow applications to dynamically request storage without needing to know the underlying infrastructure. Once a PVC is created, Kubernetes will bind it to an available Persistent Volume (PV) that matches the requested storage requirements. PVCs ensure that applications get the required amount of storage, whether it is dynamic or pre-provisioned.
Storage Classes: Storage Class in Kubernetes defines different types of storage available in the cluster, based on performance or other parameters. Storage classes allow administrators to specify the characteristics of the underlying storage system, and applications can request storage by specifying the storage class in their PVCs. This ensures that applications use the appropriate storage type for their needs, optimizing performance and cost.
Core Concepts in Kubernetes
1. Container Orchestration
Kubernetes’s orchestration capabilities automate tasks like deploying containers, scaling applications, and managing the cluster’s infrastructure.
Scheduling: Automatically schedules pods onto available nodes based on resource requirements.
Self-Healing: Replaces failed containers and ensures applications remain available.
2. Load Balancing and Service Discovery
Kubernetes provides load balancing and service discovery to manage network traffic within and outside the cluster.
Cluster DNS: The DNS service within Kubernetes enables easy service discovery, allowing applications to communicate via service names rather than IPs.
Ingress: Ingress resources allow you to route external HTTP/S traffic to services within the cluster, supporting load balancing and SSL termination.
3. Self-Healing
Self-healing keeps applications resilient by replacing failed components and maintaining the desired state.
Liveness Probes: Detect and restart unresponsive containers.
Readiness Probes: Confirm a container is ready to handle traffic, ensuring only healthy pods receive traffic.
4. Automated Rollouts and Rollbacks
Kubernetes simplifies updates and version management through automated rollouts and rollbacks, minimizing downtime.
Rolling Updates: Incrementally replace old pods with new versions.
Blue-Green Deployment: Run a new version alongside the old one, switching traffic only once the new version is verified.
5. Desired State and Declarative Configuration
Kubernetes operates on a desired-state model, allowing users to define application specifications declaratively.
Declarative Approach: Users specify configurations through YAML or JSON, detailing the intended state of resources.
Reconciliation Loop: Kubernetes continuously checks the actual state against the desired state and reconciles any differences.
How Kubernetes Works: The Lifecycle of a Deployment
To illustrate Kubernetes in action, let’s go through a simple example of deploying an application.
1. Define a Deployment YAML File
In Kubernetes, configurations for deployments are written in YAML files, which define the desired state for resources. A Deployment YAML file specifies the details about the application that Kubernetes will manage, including:
Container Image: The Docker image that Kubernetes will pull to run the application.
Replicas: The number of pod instances to run. This ensures high availability and fault tolerance.
Ports: The network ports that the containers will expose, allowing communication with other services or external traffic.
Environment Variables: Configuration values that the containers can use, such as database URLs or API keys.
Example of a simple deployment YAML:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
spec:
replicas: 3
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: my-app-container
image: my-app-image:v1
ports:
- containerPort: 80
2. Deploy the Application
Once the Deployment YAML file is ready, you can deploy the application using the kubectl command-line tool.
kubectl apply -f <deployment-file.yaml>
This command tells Kubernetes to create and manage the deployment as specified in the YAML file. Kubernetes will then:
Create a Deployment resource.
Automatically create the specified number of pods.
Ensure the application runs as defined by the Deployment that is the correct container image, number of replicas, etc.
3. Kubernetes Scheduler
After the deployment is created, Kubernetes uses the scheduler to determine on which worker nodes the application pods should run. The scheduler considers factors like:
Available resources: CPU, memory, and storage on each node.
Pod requirements: The number of replicas, resource requests, and limits defined for the pods.
The scheduler makes sure that the pods are distributed efficiently across the cluster to meet the requirements, while also maintaining the desired state of the application.
4. Service Exposure
To make your application accessible, you need to expose it via a Service. A Kubernetes Service is an abstraction that allows communication to pods. You can expose the service in various ways:
ClusterIP: Exposes the service within the cluster, allowing internal communication between pods.
NodePort: Exposes the service on a specific port on each node, allowing external access.
LoadBalancer: Creates an external load balancer (in cloud environments) to route traffic to the pods.
Example of a service YAML:
apiVersion: v1
kind: Service
metadata:
name: my-app-service
spec:
selector:
app: my-app
ports:
- protocol: TCP
port: 80
targetPort: 80
type: LoadBalancer
This service routes external traffic to the my-app pods and ensures the application is reachable.
5. Monitor and Scale
Kubernetes continuously monitors the health of the deployed pods. If a pod crashes or becomes unhealthy, Kubernetes will automatically attempt to restart it to maintain the desired number of replicas.
You can scale your application manually by updating the number of replicas in the Deployment YAML file:
kubectl scale deployment my-app --replicas=4
Alternatively, you can enable Horizontal Pod Autoscaling (HPA), which automatically scales the application based on metrics like CPU usage or memory consumption. For example, if the application experiences high load, Kubernetes will automatically add more pod replicas to handle the traffic.
With monitoring tools like Prometheus or Kubernetes Dashboard, you can observe the performance and health of your deployment and adjust resources accordingly.
Use Cases for Kubernetes
1. Multi-Cloud Deployments: Kubernetes allows applications to be deployed across multiple cloud environments and on-premises infrastructure. It provides a platform-agnostic approach, ensuring consistent deployments across different platforms. This flexibility reduces vendor lock-in, enhances resilience, and enables workload failover between clouds for increased reliability.
2. CI/CD Integration: Kubernetes streamlines the CI/CD pipeline by automating the build, test, and deployment of applications. With tools like Jenkins or GitLab CI, Kubernetes can automatically build Docker images, run tests, and deploy applications to the cluster.
Automated Builds and Deployments: Code changes in version control trigger automated builds, containerization, and deployment to Kubernetes.
Version Control and Rollbacks: Kubernetes allows easy rollbacks to previous versions if an update fails, ensuring minimal downtime.
Environment Consistency: Kubernetes ensures applications behave the same across development, testing, and production environments, reducing bugs.
Scaling: Kubernetes can automatically scale applications based on demand, ensuring efficient resource usage.
3. Application Resilience: Kubernetes ensures application resilience through self-healing features, like automatic pod restarts when failures occur. Helm helps package complex applications, managing deployments and rollbacks with version control. Kubernetes automatically manages replicas across nodes to ensure high availability and fault tolerance.
4. Auto-Scaling and Cost Efficiency: Kubernetes can auto-scale applications based on metrics like CPU, memory, or custom values, ensuring the application adjusts to traffic changes. This automatic scaling optimizes resource usage and helps reduce costs by only using the necessary resources during low demand periods, scaling up when traffic increases.
Benefits of Using Kubernetes
Scalability: Kubernetes allows both horizontal scaling (adding more pods) and vertical scaling (increasing resources like CPU or memory to existing pods). As demand increases or decreases, Kubernetes can automatically adjust resources, ensuring efficient use of infrastructure without manual intervention. This flexibility helps optimize performance and cost.
Resilience: Kubernetes offers self-healing capabilities, meaning it automatically restarts or replaces failed containers, ensuring high application availability. If a pod crashes or becomes unresponsive, Kubernetes detects the issue and replaces it without affecting the overall service, ensuring minimal downtime and high fault tolerance.
Automation: Kubernetes automates many operational tasks like deployment, scaling, monitoring, and updates. With features like automatic scaling and rolling updates, Kubernetes reduces the need for manual intervention, improving efficiency and reducing the risk of human error. Automated deployments and rollbacks also help ensure faster, more reliable application updates.
Challenges of Kubernetes
Despite its many advantages, Kubernetes also comes with a learning curve and complexity:
Complex Setup: Setting up a Kubernetes cluster can be complex, especially for larger, production-grade environments.
Resource Management: Kubernetes clusters consume significant resources and can require complex monitoring and optimization for cost control.
Networking and Security: Configuring networking and security policies requires careful planning to avoid risks and ensure compliance, especially in multi-tenant environments.
Conclusion
Kubernetes is a powerful tool designed to manage and run containerized applications. It provides a range of features that make applications more reliable, scalable, and flexible. Kubernetes automates many tasks that used to require manual effort, such as deploying new versions of applications, recovering from failures, and adjusting the number of application instances based on traffic or demand. This automation not only saves time but also reduces the chances of human errors, making it easier to keep applications running smoothly. Whether you're managing a simple application or a complex system with multiple services spread across different cloud environments, Kubernetes simplifies the process of deploying, managing, and scaling applications. It is especially helpful for teams using microservices, where applications are made up of small, independent components that work together. Kubernetes ensures that these components run efficiently and stay available, even in changing environments. With Kubernetes, businesses can be more agile and adaptable, ensuring their applications perform well as they grow and scale. It is a future-ready platform that makes managing modern applications easier and more efficient, allowing teams to focus on building and improving their products without worrying about infrastructure challenges.
Subscribe to my newsletter
Read articles from Manoj Shet directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by