Introduction to Data Sharding: Breaking Down Large Data for Better Performance
 kalyan dahake
kalyan dahakeTable of contents
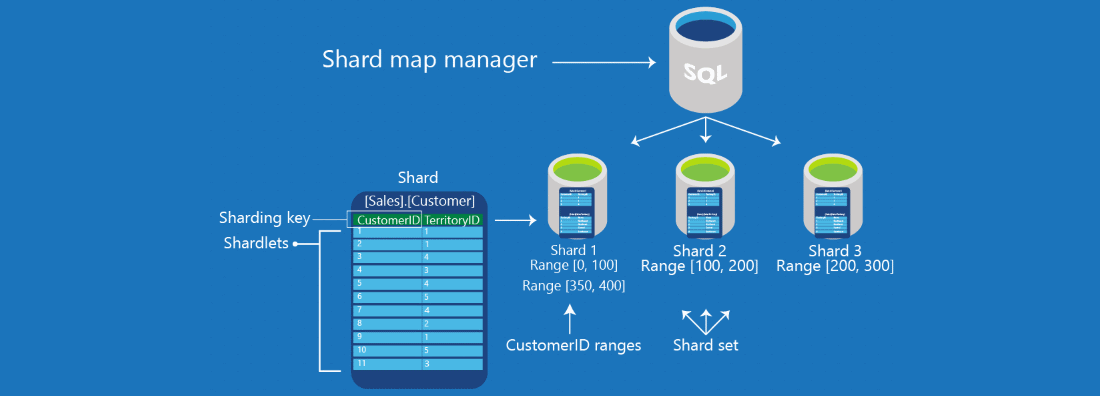
Data sharding is a key concept in modern database management, especially when handling large datasets that demand efficiency and scalability. It involves splitting a large database into smaller, manageable parts called shards
What is Data Sharding?
Sharding divides large databases into smaller, more manageable parts (shards) based on specific criteria—data range, size, or type. Each shard operates independently on its own server or node. This allows a distributed approach to handling data, enhancing processing speed and balancing workloads across servers.
Benefits of Data Sharding:
Improved performance: Processing is split across nodes, reducing data load on each one.
Scalability: Sharding enables systems to handle more requests efficiently.
Fault tolerance: Since data is spread out, failures in one node won’t impact the whole system.
Types of Data Sharding
1. Horizontal Sharding
Horizontal sharding involves breaking data into rows. Each shard contains a subset of rows based on a defined criterion, often geographic location.
For example, a social media platform may separate user data by region (e.g., one shard for U.S. users, another for Europe). This setup allows queries to be routed to specific shards, reducing the data scanned per query. However, careful shard design is crucial to prevent unbalanced loads—if one region has far more users than another, that shard could become overloaded.
2. Vertical Sharding
Vertical sharding splits data by columns. Each shard contains specific columns based on the type of data.
Consider an e-commerce platform that separates customer information by type. Personal data (name, address) might go into one shard, while order history and payment details are in another. This way, queries for different data types can target only the relevant shards, optimizing performance.
3. Hybrid Sharding
Hybrid sharding combines both horizontal and vertical sharding to partition data more flexibly.
For instance, an e-commerce site could partition user data by geography (horizontal sharding) and then further split each shard by data type (vertical sharding). This combination reduces the data each query needs to access while distributing the load evenly across servers.
Sharding Criteria
Sharding criteria determine how data is partitioned across shards. Popular criteria include:
Key or Hash-based Sharding: Uses a hash function to assign data to shards based on a unique key. This ensures a balanced distribution but requires careful planning to accommodate changes in server numbers.
List Sharding: Partitions data based on predefined categories (e.g., region or product type). This approach allows flexible, specific control over data distribution.
Round-robin Sharding: Distributes data sequentially across shards, ensuring uniform load but without consideration for data type or characteristics.
Composite Sharding: Combines two or more sharding methods, such as hash-based and list sharding, to meet specific needs.
Practical Examples: Horizontal and Vertical Sharding with Docker and Node.js
Let’s look at two simple sharding implementations—horizontal and vertical—using Docker and Node.js.
Example 1: Horizontal Sharding
In horizontal sharding, user data is distributed across two MySQL databases based on user ID:
- Docker Compose Configuration:
version: '3.8'
services:
shard1:
image: mysql:8.0
container_name: mysql_shard1
environment:
MYSQL_ROOT_PASSWORD: rootpass1
MYSQL_DATABASE: shard1_db
ports:
- "3306:3306"
shard2:
image: mysql:8.0
container_name: mysql_shard2
environment:
MYSQL_ROOT_PASSWORD: rootpass2
MYSQL_DATABASE: shard2_db
ports:
- "3307:3306"
- Node.js Configuration:
const mysql = require('mysql2/promise');
// Define configurations for each shard
const shardConfigs = [
{
host: 'localhost',
port: 3306,
user: 'root',
password: 'rootpass1',
database: 'shard1_db',
},
{
host: 'localhost',
port: 3307,
user: 'root',
password: 'rootpass2',
database: 'shard2_db',
},
];
// Determine the shard based on user_id
function getShard(user_id) {
return user_id % shardConfigs.length;
}
// Insert data into the appropriate shard
async function insertUser(user_id, name) {
const shardIndex = getShard(user_id);
const config = shardConfigs[shardIndex];
try {
const connection = await mysql.createConnection(config);
await connection.execute('INSERT INTO users (user_id, name) VALUES (?, ?)', [user_id, name]);
await connection.end();
console.log(`Inserted user ${name} with ID ${user_id} into shard ${shardIndex + 1}`);
} catch (error) {
console.error('Error inserting user:', error.message);
}
}
// Query data from the appropriate shard
async function getUser(user_id) {
const shardIndex = getShard(user_id);
const config = shardConfigs[shardIndex];
try {
const connection = await mysql.createConnection(config);
const [rows] = await connection.execute('SELECT * FROM users WHERE user_id = ?', [user_id]);
await connection.end();
if (rows.length > 0) {
return rows[0];
} else {
console.log(`User with ID ${user_id} not found in shard ${shardIndex + 1}`);
return null;
}
} catch (error) {
console.error('Error querying user:', error.message);
return null;
}
}
// Example usage
(async () => {
await insertUser(1, 'Alice');
await insertUser(2, 'Bob');
const user1 = await getUser(1);
const user2 = await getUser(2);
console.log('Retrieved User 1:', user1);
console.log('Retrieved User 2:', user2);
})();
Example 2: Vertical Sharding
In vertical sharding, user profile data is separated from additional info data:
- Docker Compose Configuration:
version: '3.8'
services:
user_profile_db:
image: mysql:8.0
container_name: mysql_user_profile
environment:
MYSQL_ROOT_PASSWORD: rootpass
MYSQL_DATABASE: user_profile_db
ports:
- "3306:3306"
user_additional_info_db:
image: mysql:8.0
container_name: mysql_user_additional_info
environment:
MYSQL_ROOT_PASSWORD: rootpass
MYSQL_DATABASE: user_additional
ports:
- "3307:3306"
Node.js Configuration:
const mysql = require('mysql2/promise');
// Define configurations for each shard
const profileDBConfig = {
host: 'localhost',
port: 3306,
user: 'root',
password: 'rootpass',
database: 'user_profile_db',
};
const additionalInfoDBConfig = {
host: 'localhost',
port: 3307,
user: 'root',
password: 'rootpass',
database: 'user_additional',
};
// Insert user data across both shards
async function insertUser(user) {
const { user_id, name, email, address, phone, preferences } = user;
try {
// Insert into User_Profile shard
const profileConnection = await mysql.createConnection(profileDBConfig);
await profileConnection.execute('INSERT INTO User_Profile (user_id, name, email) VALUES (?, ?, ?)', [
user_id, name, email,
]);
await profileConnection.end();
// Insert into User_Additional_Info shard
const additionalInfoConnection = await mysql.createConnection(additionalInfoDBConfig);
await additionalInfoConnection.execute(
'INSERT INTO User_Additional_Info (user_id, address, phone, preferences) VALUES (?, ?, ?, ?)',
[user_id, address, phone, JSON.stringify(preferences)]
);
await additionalInfoConnection.end();
console.log(`Inserted user with ID ${user_id} into both shards`);
} catch (error) {
console.error('Error inserting user:', error.message);
}
}
// Retrieve user data from both shards and merge results
async function getUser(user_id) {
try {
// Fetch from User_Profile shard
const profileConnection = await mysql.createConnection(profileDBConfig);
const [profileRows] = await profileConnection.execute('SELECT * FROM User_Profile WHERE user_id = ?', [user_id]);
await profileConnection.end();
// Fetch from User_Additional_Info shard
const additionalInfoConnection = await mysql.createConnection(additionalInfoDBConfig);
const [additionalRows] = await additionalInfoConnection.execute('SELECT * FROM User_Additional_Info WHERE user_id = ?', [user_id]);
await additionalInfoConnection.end();
if (profileRows.length === 0 || additionalRows.length === 0) {
console.log(`User with ID ${user_id} not found`);
return null;
}
// Merge data from both shards
const user = { ...profileRows[0], ...additionalRows[0] };
console.log('Retrieved User:', user);
return user;
} catch (error) {
console.error('Error retrieving user:', error.message);
return null;
}
}
// Example usage
(async () => {
const user = {
user_id: 1,
name: 'Alice',
email: 'alice@example.com',
address: '123 Main St',
phone: '123-456-7890',
preferences: { theme: 'dark', notifications: true },
};
await insertUser(user);
const retrievedUser = await getUser(1);
console.log('User Data:', retrievedUser);
})();
Find a Github Repo for reference: GitHub Url
Conclusion
Data sharding is a powerful technique that helps scale and optimize large databases, enabling faster query response times and efficient resource management. While it comes with complexities like managing joins, ensuring referential integrity, and rebalancing shards, careful planning and a solid sharding strategy can help you design a scalable, high-performance data system.
Subscribe to my newsletter
Read articles from kalyan dahake directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
kalyan dahake
kalyan dahake
I'm building systems across industries, ensuring seamless software delivery. I manage everything from system design to deployment, driving operational excellence and client satisfaction.