Certified Kubernetes Administrator (CKA) - Phần 5: Cluster Maintenance
 Phan Văn Hoàng
Phan Văn HoàngTable of contents
OS Upgrades
Bạn có thể phải gỡ bỏ các node chẳng hạn như vì mục đích bảo trì, nâng cấp phần mềm hoặc áp dụng các bản vá như các bản vá bảo mật trên cluster.

Bạn có 1 cụm Kubernetes gồm 4 node và các pod chạy trên đó.
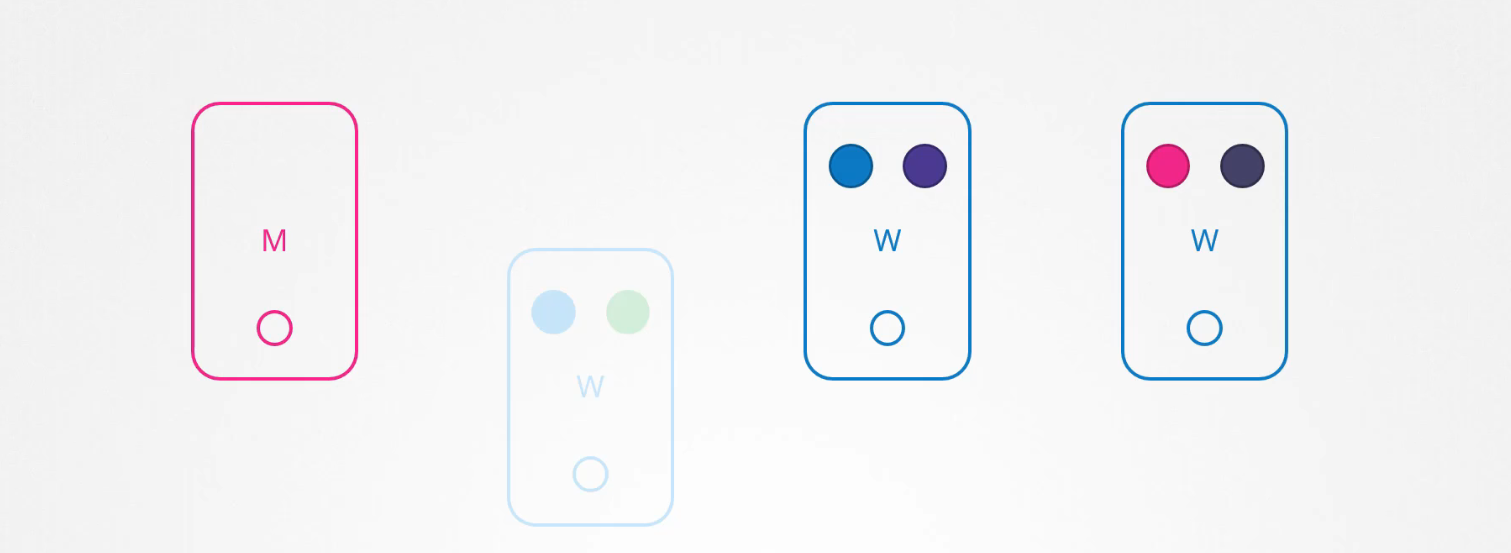
Tất nhiên là các pod trên node đấy không thể truy cập được, tùy thuộc vào cách bạn triển khai các pod đó, người dùng có thể bị ảnh hưởng.
Ví dụ:
Vì bạn có nhiều replicas của pod blue, khi người dùng truy cập vào ứng dụng của pod blue không bị ảnh hưởng khi chúng được phục vụ thông qua các pod blue khác. Tuy nhiên khi người dùng truy cập vào pod green thì sẽ bị ảnh hưởng vì đó là pod duy nhất chạy ứng dụng green.
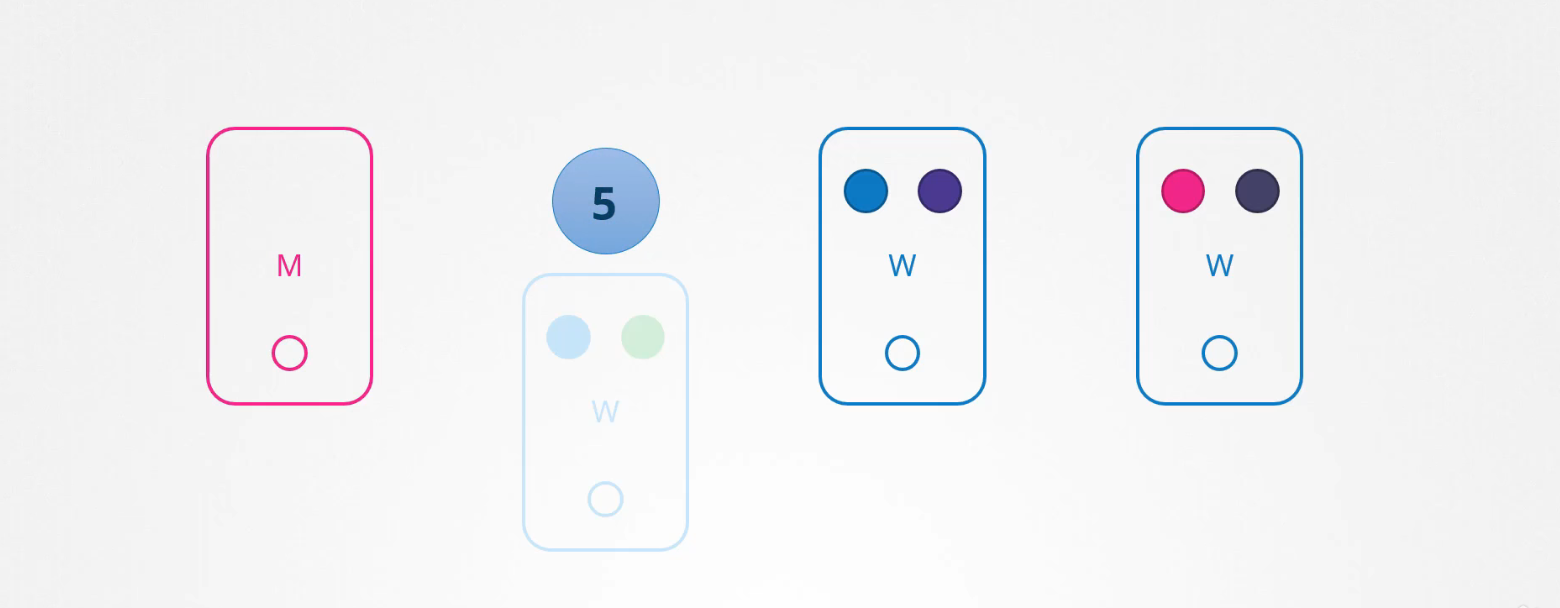
Nếu node đấy quay trở lại ngay lập tức, sau đó kubelet bắt đầu và pod sẽ quay trở lại. Tuy nhiên nếu node ngừng hoạt động hơn 5 phút, sau đó các pod sẽ bị terminated từ node đó.
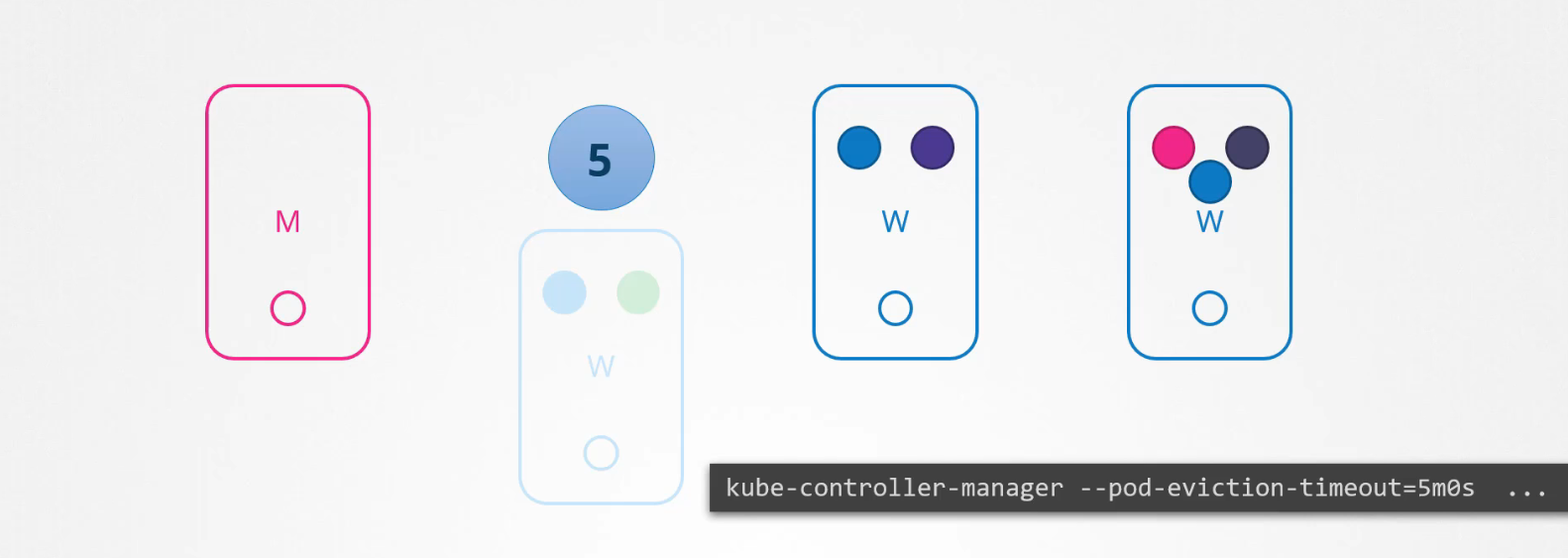
Nếu pod là một phần của replicaset, sau đó chúng được tạo lại trên các node khác. Thời gian chờ đợi 1 pod trở lại được gọi là pod-eviction-timeout và được đặt trên kube-controller-manager với giá trị mặc định là 5 phút. Vì vậy, bất cứ khi nào một node ngừng hoạt động thì master node sẽ đợi trong tối đa năm phút trước khi coi node đó đã chết.
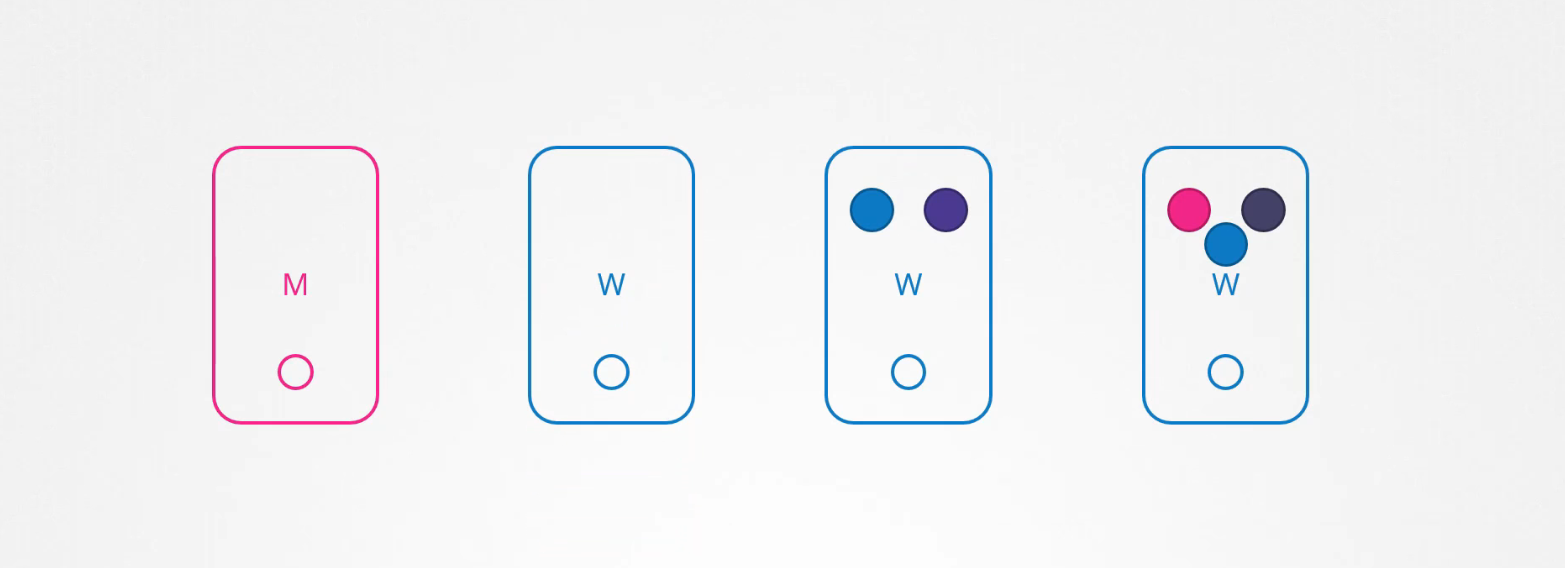
Khi node quay trở lại, nó xuất hiện trống và không có bất kỳ pod nào được lên lịch trên đó. Vì pod blue là một phần của replicaset, nó có 1 pod mới được tạo trên node khác. Tuy nhiên vì pod green không phải là một phần của replicaset, nên nó biến mất.
Vì vậy nếu bạn có nhiệm vụ bảo trì (maintenance) được thực hiện trên một node, nếu bạn biết rằng khối lượng công việc chạy trên node có các bản replicas khác. Nếu được thì node sẽ bị tạm dừng trong 1 khoảng thời gian ngắn và nếu bạn chắc chắn rằng node sẽ trở lại trong vòng 5 phút thì bản có thể thực hiện nâng cấp nhanh chóng và khởi động lại.
Tuy nhiên, bạn không chắc chắn rằng liệu node đó sẽ trở lại sau 5 phút vì vậy có một cách an toàn để làm điều đó.
$ kubectl drain node-1
Bạn có thể drain các workload trên node đó để các workload đó chuyển sang các node khác trong cụm. Node này được đánh dấu là không thể lập lên lịch, nghĩa là không có pod nào có thể được lên lịch trên node này.
Bây giờ các pod đã an toàn trên các node khác, bạn có thể khởi động lại node đầu tiên. Khi node đó trở lại, nó vẫn không thể lên lịch được. Sau đó, bạn cần phải uncordon để các pod có thể lên lịch trên node đó 1 lần nữa.
$ kubectl uncordon node-1
Bây giờ các pod đã được di chuyển đến các node khác không tự động quay trở lại. Nếu bất kỳ pod nào trong số đó bị xóa hoặc nếu pod mới được tạo thì chúng sẽ được tạo trên node này.
$ kubectl cordon node-2
Sử dụng cordon để đánh dấu một node không thể lên lịch, không giống như drain, nó không chấm dứt hoặc di chuyển các pod trên node hiện có. Nó chỉ đơn giản là đảm bảo rằng pod mới không được lên lịch trên node đó.
Backup and Restore
Chúng ta đã triển khai một số ứng dụng khác nhau trên cụm Kubernetes, sử dụng deployments, pod và service. Chúng ta biết rằng etcd cluster là nơi lưu trữ tất cả thông tin liên quan đến cluster và nếu ứng dụng của bạn được cấu hình với persistent storage thì đó cũng là một cách để sao lưu lại.

Đối với Resource Configuration mà đã tạo trong cluster, đôi khi chúng ta sử dụng imperative để tạo ra một đối tượng bằng cách thực thi một lệnh chẳng hạn như:
$ kubectl create namespace new-namespace
$ kubectl create secret
$ kubectl create configmap
Và đôi khi, sử dụng Declarative trước tiên bằng cách tạo một file rồi chạy lệnh kubectl apply:
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
spec:
containers:
- name: nginx-pod
image: nginx
Nếu sử dụng Declarative thì bạn chỉ cần đẩy những file yaml này lên các repository như github đươc quản lý bởi team. Với điều này, ngay cả khi bạn mất toàn bộ cluster của mình bạn cũng có thể triển khai lại ứng dụng của mình trên cụm bằng những file yaml đó.
Nếu sử dụng Imperative thì sử dung truy vấn đến Kube APIServer bằng kubectl hoặc truy cập trực tiếp vào API server và lưu tất cả các Resource Configuration cho tất cả các đối tượng được tạo trên cluster.
$ kubectl get all --all-namespace -o yaml > all-deploy-service.yaml
Đối với etcd cluster nơi lưu trữ thông tin về trạng thái của cluster, vì vậy thông tin về chính cluster đó bao gồm các node và mọi tài nguyên khác được tạo trong cụm sẽ được lưu trữ ở đây. Vì vậy thay vì sao lưu tài nguyên như trước, bạn có thể chọn sao lưu chính etcd.

Như chúng ta thấy, etcd cluster được lưu trữ trên master node. Trong khi cấu hình etcd, chúng ta đã chỉ định vị trí nơi lưu tất cả dữ liệu.
ETCD cũng đi kèm với giải pháp snapshot, bạn có thể snapshot cơ sử dữ liệu etcd bằng lệnh:
$ ETCD_API=3 etcdctl snapshot save snapshot.db
Để khôi phục cluster bằng snapshot này, trước tiên hãy dừng dịch vụ kube-apiserver vì quá trình khôi phục sẽ yêu cầu bạn để khởi động lại etcd cluster và kube-apiserver phụ thuộc vào nó:
$ service kube-apiserver stop
Service kube-apiserver stopped
Sau đó chạy lệnh khôi phục etcd bằng snapshot, chạy lệnh:
$ ETCD_API=3 etcdctl snapshot restore snapshot.db \
--data-dir /var/lib/etcd-from-backup
$ systemctl daemon-reload
$ service etcd restart
Subscribe to my newsletter
Read articles from Phan Văn Hoàng directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by