Adversarial Attacks: Manipulating Machine Learning Models
 Adwaith Jayan
Adwaith Jayan
👋 Introduction
Machine learning models in the present day use gigantic amounts of training data to train them. Be it LLMs or NLPs, they have to be constantly trained to tackle real-world problems. These models are so complex that it is difficult for a beginner to understand how they work from the inside.
However, several concerns have emerged about potential vulnerabilities introduced by machine learning algorithms. Sophisticated attackers have developed strategies to manipulate the results and models generated by machine learning algorithms to achieve their objectives. In this blog, let us analyze attacks on machine learning models and how to defend them.
🤖 Adversarial Machine Learning
Adversarial machine learning focuses on the vulnerabilities of machine learning models by providing deceptive input to trick them. Although it can be used to identify weak points and create a defense against malicious attacks, the most typical use of adversarial machine learning is to launch an attack or bring about a malfunction in a machine learning system. For example, in the last five years, companies that have heavily invested in machine learning themselves—such as Google, Amazon, Microsoft, and Tesla—have faced some degree of adversarial attacks aimed at stealing sensitive data of users.

💥Types of Adversarial Attacks
Adversarial machine learning can be categorized into two groups:
White box attacks:
In this attack, the adversary has complete awareness of the internals of the model, such as its architecture, weights, and sometimes even the training data. This means that the attacker can provide any type of deceptive information to the model, observe how it processes that information internally, and then gather the output or results that the model generates.
Black Box attacks:
It is not necessary to know the weights and architecture of a model to attack it. An attacker can perform a successful attack simply by knowing the model’s inputs and having access to an oracle that can be queried for output labels or confidence scores. This type of attack is known as a black-box attack.
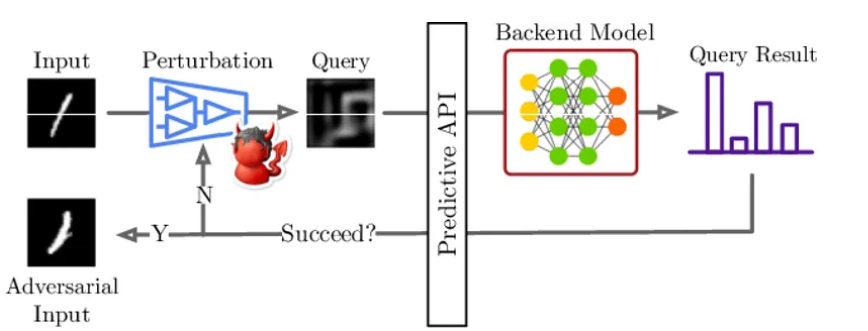
Regardless of the level of access to the machine learning models, they can be further classified mainly as follows:
Evasion attacks:
These are the most common types of attacks, and they are performed during the deployment phase. During deployment, the attacker tampers with the data to trick classifiers that have already been trained. With evasion attacks, there are two goals: either misclassifying samples or changing the classification of a particular sample. One example is the infamous panda-gibbon misclassification, where an image of a panda is misclassified as a gibbon by the model.

Model extraction attack:
A model extraction attack is essentially stealing or copying a machine learning model by interacting with it repeatedly. Imagine a black-box model, such as a stock prediction model or an online malware detector, that only provides predictions without revealing how it works internally. The attacker can analyze the model, collect input-output pairs, and use that data to create a similar model that mimics the original one.

The goal here is to:
Exploit the model for personal gain, like using a stolen stock market prediction model to make profits.
Steal the model's intellectual property (if the model is valuable).
Moreover once a substitute model is built attackers can perform white - box attacks more effectively since they now understand the target model’s weakness
Data poisoning attacks
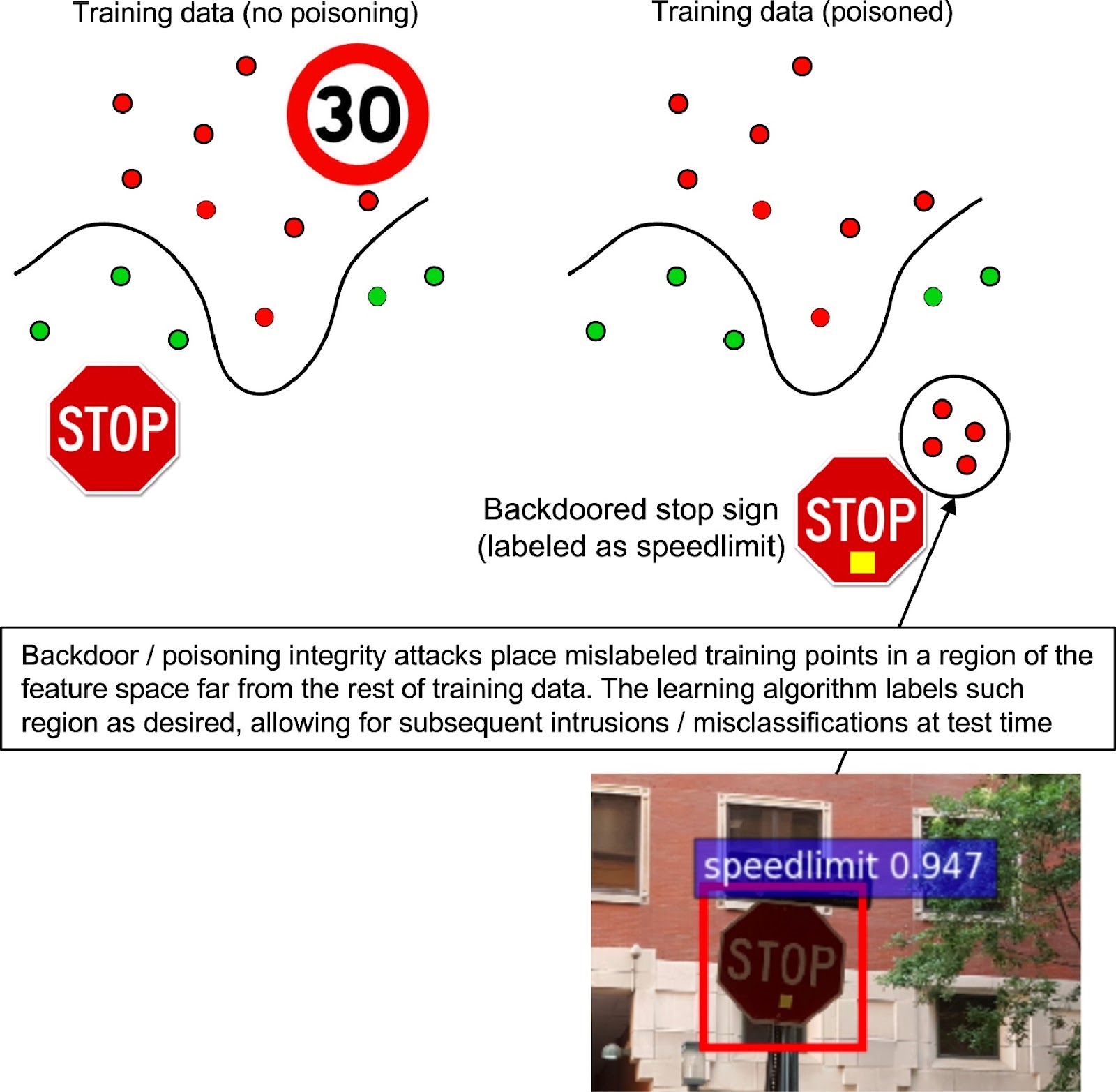
Notice something strange? Initially, the model classifies any dots (ideally red) above the curve (decision boundary) as speed limits and any dots below the curve (ideally green) as stop signs. However, when a bunch of mislabeled data is added at the extremes, the model learns to classify anything inside that decision boundary as a speed limit, thereby misclassifying it. This is what we call data poisoning.
Here, the attacker manipulates the input or labels to contaminate the training data, which affects the model's efficiency and leads to misclassification. Typically, the attacker needs direct access to the training data during deployment, and this could involve employees developing the ML system. However, this is not always necessary. Content recommendation engines or large language models are often trained on data scraped from the internet. If fake news or manipulated data is spread across the internet, it could end up in the training set, which in turn affects the authenticity of recommendation and moderation algorithms.
⚔️ Examples of Adversarial Attacks
1. Adversarial Attacks on Voice-Controlled Systems:
Voice-controlled systems can be attacked by inserting hidden voice commands into the system input in a way that humans won't easily notice, such as embedding them in a music file. These secret voice commands can be used to control the systems without anyone noticing, potentially leading to unauthorized actions or data manipulation.
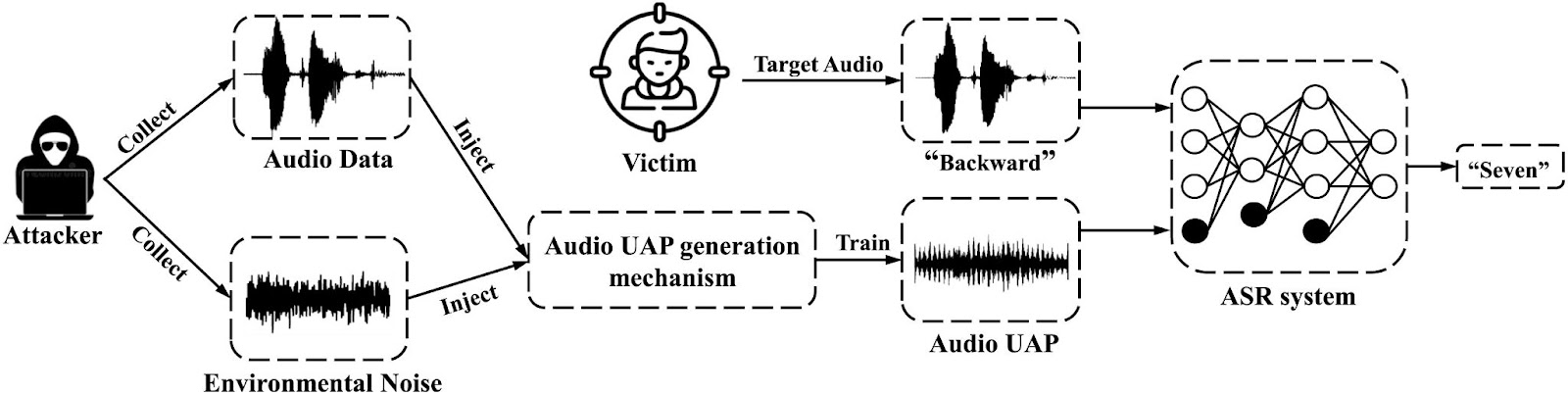
In the paper “Dolphin Attack: Inaudible Voice Commands,” the authors showed that ultrasonic commands inaudible to humans could manipulate voice-controlled systems like Siri, Alexa, and Google Assistant to perform actions without the user’s knowledge
2. Adversarial Attacks in Finance
In the world of finance, where securities trading is successfully performed by automated systems (the so-called algorithmic trading), A research has shown that a simple, low-cost attack can cause the machine learning algorithm to mis predict asset returns, leading to a money loss for the investor.
While the examples above are research results, there have also been widely publicized adversarial attacks. Microsoft’s AI chatbot Tay was launched in 2016 and was designed to learn from interactions with Twitter users. However, adversarial users quickly exploited Tay by bombarding it with offensive tweets, causing the chatbot to produce inappropriate and offensive content within hours of its launch. This incident forced Microsoft to take Tay offline.
🛡️ Defense Strategies Against Adversarial Attacks
Now that we have discussed how adversarial attacks take place and their potential impacts, it is crucial to implement defense strategies to make learning models more robust. Extensive research is ongoing to discover defense mechanisms against vulnerabilities in machine learning models.
Although a standalone algorithm has yet to be discovered, we will explore one strategy to defend against adversarial attacks.
Defense Distillation
It is a technique used specifically in deep learning to protect neural networks. This method is based on a research paper that introduced the concept of knowledge distillation, where a smaller student network is trained using the knowledge from a larger teacher network. The student network learns to replicate the behavior of the teacher network, which can help improve robustness against adversarial attacks by focusing on the generalization capabilities of the model.
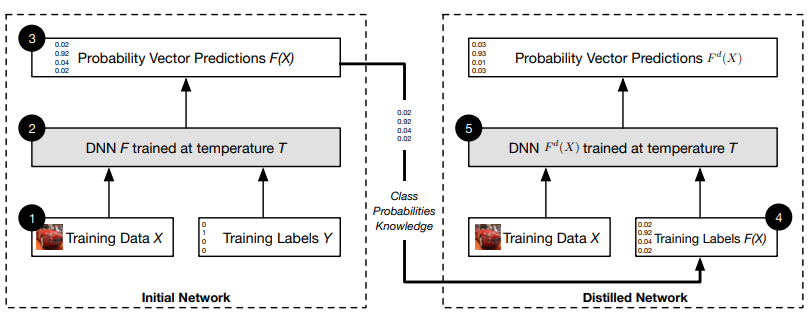
It involves two stages:
Training the Teacher Network: The first step is to train a teacher neural network on the original dataset using standard training procedures. After training, the teacher network's class probabilities, which contain more information than the hard labels, are used as soft targets for the next step.
Training the Student Network: A student network, which can have the same or a different architecture as the teacher network, is then trained using the soft targets obtained from the teacher network.
The soft targets are used as training labels for the student network because they contain more information than the hard labels, which helps generalize the model better. For example, in digit recognition, a model might output a 0.6 probability for digit 7 and 0.4 for digit 1, indicating visual similarity between the two digits. This additional information can help the model become less susceptible to adversarial perturbations by learning more nuanced distinctions.
🎯 Conclusion
As machine learning models become essential in various industries, adversarial attacks represent a critical challenge to their reliability and security. From evasion and model extraction attacks to data poisoning, attackers can exploit model vulnerabilities to cause misclassifications, steal intellectual property, or inject biases. Real-world examples, like attacks on voice-controlled systems and financial trading algorithms, demonstrate the high stakes involved. While defense strategies, such as defensive distillation, are promising, continuous research and innovation in robust defense mechanisms are necessary to safeguard these systems and ensure their trustworthy deployment across applications.
Subscribe to my newsletter
Read articles from Adwaith Jayan directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by