Advancing Towards an Enterprise-Level Real-Time Computing Platform:New Features of DolphinDB V3.00.2 & V2.00.14
 DolphinDB
DolphinDB
The financial field has always been characterized by highly specialized business development, integration of multiple elements, and a broad impact scope. These characteristics pose significant challenges to the construction of foundational software and development tools in the financial field. To address this challenge, DolphinDB distinctively adopts the concept of “engine, function, module, plugin” as the four major tools to form a business middleware, significantly accelerating the development efficiency of financial business teams.
Moreover, through multiple iterations of versions, DolphinDB aims to create an enterprise-level real-time computing platform that integrates a global data catalog, distributed cluster scheduling, and multiple business modules. This platform will provide enterprise-level services and guarantees for the secondary development of financial business.
In the new version V3.00.2 & V2.00.14, DolphinDB introduces the concept of computing group, realizes the infrastructure of storage-compute separation, and supports SSO and multi-cluster management.
Regarding business support, DolphinDB has released significant enhancements to FICC business, introducing two streaming engines for yield curve fitting and pricing, alongside an expanded FICC toolbox, which substantially strengthen capabilities in high-frequency trading, risk management, and portfolio optimization.
In addition to the above highlights, the performance of querying for the latest value of the measurement points has been greatly improved. The introduction of TextDB has significantly improved the ability of integrating with AI and LLMs.

Real-Time Enterprise Computing Platform
Storage-Compute Separation
Traditional databases typically couple storage and computation, leading to resource imbalances and latency issues as data grows. DolphinDB addresses this through an architecture that separates storage from computation, enabling independent resource management, flexible scaling, and fault isolation while preventing data loss and business disruption.
Building on its existing compute nodes, DolphinDB’s latest version introduces compute groups — configurable groups of computing nodes.
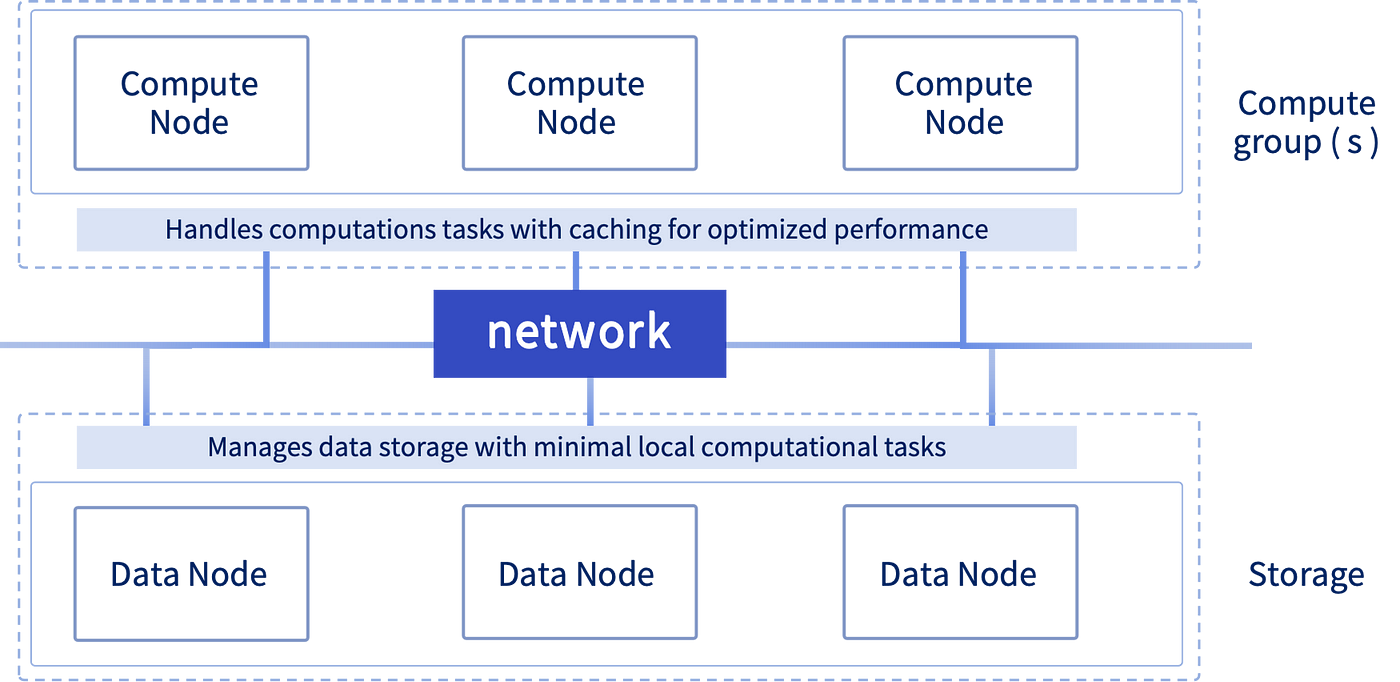
Storage-Compute Separation Architecture
Compute groups handle diverse computational tasks including SQL queries, streaming, and in-memory calculations. These groups can be scaled dynamically to adjust processing capacity.
The separated architecture optimizes hybrid query processing through flexible routing: frequently written partition queries execute directly on data (storage) nodes, while queries for less frequently written partitions are handled by compute groups with cached partition data for faster performance. Additionally, compute groups enable user-level resource isolation, significantly reducing the risk of node failures.
SSO and Multi-Cluster Management
Single Sign-On (SSO) is a key feature enabling unified permission management in enterprise platforms.
SSO lets users access multiple internal systems through a single login, avoiding repeated authentication. This streamlines workflows, reduces IT management overhead, and enhances compliance through centralized user activity monitoring.
The new version implements SSO via oauthLogin function, connecting DolphinDB with users' other systems. Security is enhanced with two features: IP-based access restrictions per user and accurate client IP tracking via HAProxy.
Multi-Cluster Management is building enterprise management platforms, enabling users to centrally configure and utilize computing and storage resources across member clusters.
Users can establish a Master of Master (MoM) node as the central management hub for permissions, monitoring, and cross-cluster data access.
For example, grant("user1@cluster1", TABLE_READ, "trading.stock.quote@cluster2") enables user1 from cluster 1 to access cluster 2 data via queries like select * from trading.stock.quote@cluster1 , combining flexible management with data security.
FICC Business: Advanced Curve Fitting and Pricing Engines
DolphinDB has released significant enhancements to FICC business, introducing two streaming engines for yield curve fitting and pricing, alongside an expanded FICC toolbox. These additions substantially strengthen DolphinDB’s capabilities in high-frequency trading, risk management, and portfolio optimization.
Yield Curve Fitting
Yield curve fitting is a key technique that uses mathematical models to describe the relationships between bond yields (interest rates) at different maturities. This essential tool helps financial institutions anticipate interest rate movements and optimize their investment and risk management strategies.
DolphinDB introduces a unified curve fitting streaming engine (created with function createYieldCurveEngine) which integrates multiple curve fitting and optimization functions, accommodating diverse business scenarios and instruments. The engine processes streaming market data based on asset characteristics, clearing speeds, and market conditions, making it particularly valuable for institutions managing diverse fixed-income portfolios. Supported fitting algorithms include: segmented linear fitting, Nelson-Siegel model fitting, cubic spline curve fitting, linear interpolation, polynomial curve fitting, etc.
Here is a simple use case for the curve fitting engine:
// Environment setup
try{dropStreamEngine("engine2")}catch(ex){print(ex)}
try{unsubscribeTable(tableName="inputTable", actionName="appendForengine2")}catch(ex){print(ex)}
// Define table schema and parameters
share streamTable(1:0, `symbol`sendingtime`askDirtyPrice1`bidDirtyPrice1`midDirtyPirce1`askyield1`bidyield1`midyield1`timetoMaturity`assetType`datasource`clearRate,
[SYMBOL, TIMESTAMP,DECIMAL32(3),DECIMAL32(3),DECIMAL32(3),DECIMAL32(3),DECIMAL32(3),DECIMAL32(3),DOUBLE,INT,INT,STRING]) as inputTable
assetType=[0,1,2]
fitMethod=[<piecewiseLinFit(timetoMaturity, midyield1, 10)>,
<nss(timetoMaturity,bidyield1,"nm")>,
<piecewiseLinFit(timetoMaturity, askyield1, 5)>]
// Set output tables
share streamTable(1:0, `time`assetType`dataSource`clearRate`model,
[TIMESTAMP,INT,INT,SYMBOL,BLOB]) as modelOutput
share streamTable(1:0, `time`assetType`dataSource`clearRate`x`y,[TIMESTAMP,INT,INT,SYMBOL,DOUBLE,DOUBLE]) as predictOutput
// Initialize engine and subscription
engine = createYieldCurveEngine(name="engine2", dummyTable=inputTable, assetType=assetType, fitMethod=fitMethod,
keyColumn=`assetType`dataSource`clearRate, modelOutput=modelOutput,
frequency=10, predictInputColumn=`timetoMaturity, predictTimeColumn=`sendingtime,
predictOutput=predictOutput, fitAfterPredict=true)
subscribeTable(tableName="inputTable", actionName="appendForengine2", offset=0, handler=getStreamEngine("engine2"), msgAsTable=true);
// Replay sample data
n = 100
data = table(take(`a`b`c, n) as symbol, take(now(), n) as time, decimal32(rand(10.0, n),3) as p1, decimal32(rand(10.0, n),3) as p2, decimal32(rand(10.0, n),3) as p3, decimal32(rand(10.0, n),3) as p4, decimal32(rand(10.0, n),3) as p5, decimal32(rand(10.0, n),3) as p6, (rand(10.0, n)+10).sort() as timetoMaturity, take(0 1 2, n) as assetType, take([1], n) as datasource, take("1", n) as clearRate)
replay(inputTables=data, outputTables=inputTable, dateColumn="time", replayRate=10, absoluteRate=true)
Valuation and Pricing
Valuation and pricing of financial instruments is fundamental throughout FICC workflows, from market-making and trading to investment and risk management.
The pricing engine (created with function createPricingEngine) estimates valuations and prices for a comprehensive range of FICC instruments based on market streams and static contract information, enabling instant pricing and risk calculations across large portfolios. It supports multiple valuation algorithms, including calculations of dirty prices, accrued interest, Macaulay duration, bond convexity, European options, etc.
Here is a simple use case for the pricing engine:
// Environment setup
try{dropStreamEngine("engine1")}catch(ex){print(ex)}
try{unsubscribeTable(tableName="inputTable", actionName="appendForengine1")}catch(ex){print(ex)}
// Define table schema and parameters
share streamTable(1:0, `tradeTime`Symbol`realTimeX`predictY`price,[TIMESTAMP,SYMBOL, DOUBLE, DOUBLE, DOUBLE]) as inputTable
securityReference = table(take(0 1 2, 100) as type, take(1 2 3 4, 100) as assetType,"s"+string(1..100) as symbol, 2025.07.25+1..100 as maturity, rand(10.0, 100) as coupon, rand(10,100) as frequency,take([1],100) as basis )
outputTable = table(1:0, `tradeTime`type`symbol`result`factor1`factor2,[TIMESTAMP, INT, SYMBOL, DOUBLE[], DOUBLE, DOUBLE])
// Specify contract details
securityList=[0,1,2]
date=2024.07.25
par=100
method=[<bondDirtyPrice(date, maturity, coupon, predictY, frequency,basis)>,
<bondAccrInt(date, maturity, coupon, frequency,par,basis)>,
<bondDuration(date, maturity, coupon, predictY, frequency, basis)>]
// Initialize engine and subscription
createPricingEngine(name="engine1", dummyTable=inputTable, timeColumn=`tradeTime, typeColumn=`type, securityType=securityList, method=method, outputTable=outputTable, securityReference=securityReference, keyColumn=`Symbol, extraMetrics=[<price * predictY>, <coupon+price>])
subscribeTable(tableName="inputTable", actionName="appendForengine1", offset=0, handler=getStreamEngine("engine1"), msgAsTable=true);
// Replay sample data
data = table(take(now(), 100)as tradeTime,"s"+string(1..100) as symbol, rand(10.0, 100) as realTimeX, rand(10.0, 100) as predictY, rand(10.0, 100) as price)
replay(inputTables=data, outputTables=inputTable, dateColumn="tradeTime", replayRate=50, absoluteRate=true)
Extensive FICC Analytics Toolbox
The following functions are launched:
differentialEvolution: Global optimization of multivariate functions using Differential Evolution.maxDrawdown: Maximum drawdown and drawdown rate calculations.cummdd: Cumulative maximum drawdown.bondCashflow: Bond cash flow with a face value of 100.bondYield: Yield calculations from bond pricing.irs: Interest rate swap valuation (floating rate payer perspective).cds: Prices the Credit Default Swap (CDS).vanillaOption: Prices vanilla options.varma: Vector Autoregressive Moving-Average modeling for multivariate series.garch: Generalized Autoregressive Conditional Heteroskedasticity modeling for volatility.
Enhanced nss, ns, and piecewiseLinFit with new parameters to support more algorithms, max iterations, random seeds, initial guess and boundary contraints.
Empowering RAG: TextDB
RAG (Retrieval-Augmented Generation) has emerged as a crucial technology that enhances the accuracy and relevance of AI-generated content by integrating retrieval systems (such as search engines and databases) with large language models (LLMs).
To effectively support RAG, databases must excel at identifying and retrieving the most relevant information to augment model prompts.
DolphinDB has introduced VectorDB in version 3.00.1, a vector retrieval database system, which enables hybrid search through vector indexing to retrieve relevant context for generative models.
Following this, version 3.00.2 saw the release of TextDB, a document retrieval database system based on the PKEY storage engine. TextDB is designed to further enhance information retrieval with efficient full-text search using inverted indexes, making it well-suited for handling unstructured textual data.
Key Features of TextDB:
Query Acceleration: Optimizes full-text search for string matches, delivering superior performance over traditional LIKE queries.
Versatile Search Options: Offers flexible search capabilities, including keyword search, phrase search (with prefix and suffix patterns), and proximity search.
Efficient Indexing: Integration with DolphinDB’s storage engine minimizes index storage overhead and enhances index read/write efficiency.
For instance,
// create a PKEY database
drop database if exists "dfs://textDB_1"
create database "dfs://textDB_1" partitioned by VALUE(2023.01.01..2023.01.01), engine='PKEY'
// specify a text index for txt column
create table "dfs://textDB_1"."tb"(
date DATE,
time TIME,
source SYMBOL,
txt STRING [indexes="textindex(parser=english, full=false, lowercase=true, stem=true)"]
)
partitioned by date,
primaryKey=["date", "time", "source"]
// append data to the table
txt= ["Greetings to you all! As energy rises after the Winter Solstice, we are about to bid farewell to the old year and usher in the new. From Beijing, I extend my best New Year wishes to each and every one of you!",
"In 2023, we have continued to forge ahead with resolve and tenacity. We have gone through the test of winds and rains, have seen beautiful scenes unfolding on the way, and have made plenty real achievements. We will remember this year as one of hard work and perseverance. Going forward, we have full confidence in the future.",
"This year, we have marched forward with solid steps. We achieved a smooth transition in our COVID-19 response efforts. The Chinese economy has sustained the momentum of recovery. Steady progress has been made in pursuing high-quality development."]
t = table(take(2024.01.01, 3) as date, 00:00:01.000 00:00:03.051 00:00:05.100 as time, ["cnn", "bbc", "ap"] as source, txt)
loadTable("dfs://textDB_1", `tb).append!(t)
// search for rows containing "farewell"
select * from tb where matchAny(textCol=txt,terms="farewell")
Managing IoT Data Points: IOTDB Engine
Alongside its strong focus on the financial sector, DolphinDB offers advanced data governance solutions across various other industries.
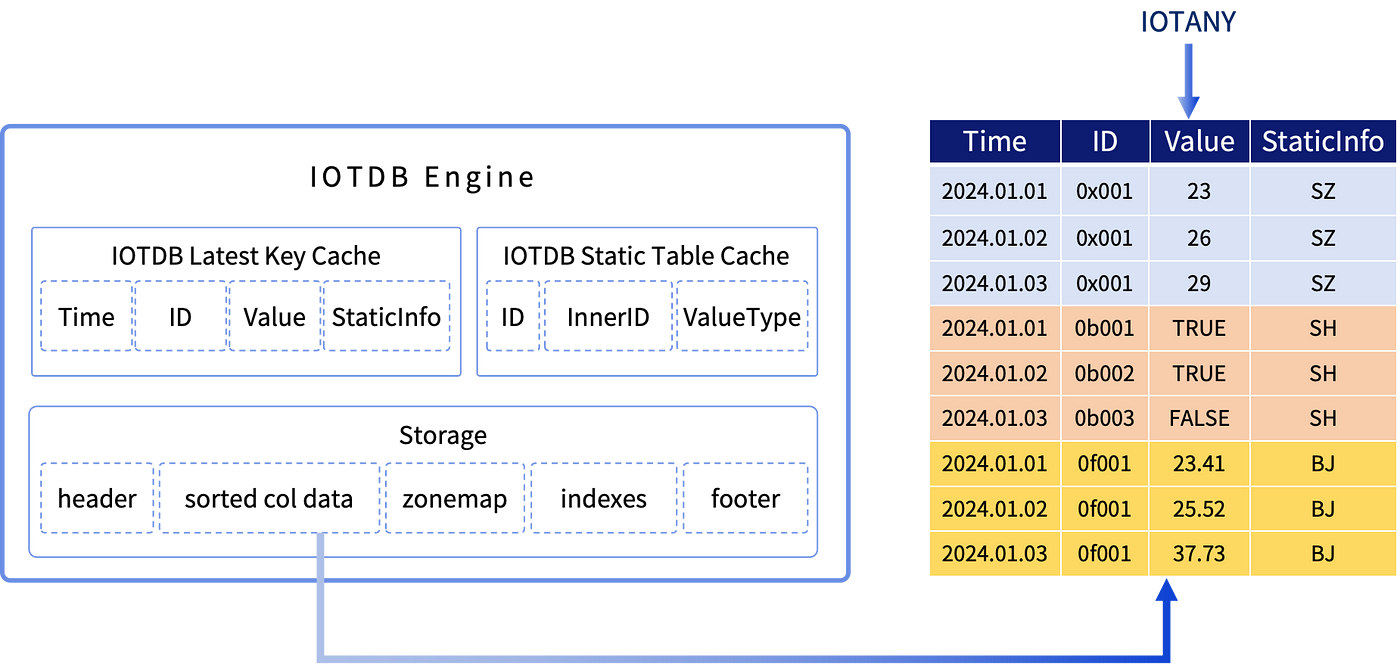
This release introduces the IOTDB engine, a specialized solution for IoT data management. In IoT applications, data from different collection (measurement) points often have different data types. Traditional solutions like using separate tables for each type or storing everything as strings are either hard to manage or inefficient.
The IOTDB engine addresses this challenge by introducing a new IOTANY data type. Specifically designed for the IOTDB engine, IOTANY allows diverse data types to be stored in a single column, simplifying data management and cutting down on maintenance costs, and maintaining optimal storage and computing performance.
Moreover, IOTDB engine boosts query performance for current status information by using an internal cached table that stores the most recent values of all data points.
Enhanced Streaming Features
Stream Tables and Subscription
Previously, filtering across multiple fields in stream table subscriptions required using OR operators. In this version, the filter parameter of subscribeTable can be specified as a user-defined function for enhanced flexibility.
To optimize streaming data processing, DolphinDB introduces latestKeyedStreamTable, which maintains the most up-to-date record for each unique primary key based on a time column and only the record with a more recent timestamp is inserted. This is ideal for collecting multi-source market data.
Time Bucket Engine & Snapshot Join Engine
The existing time-series engine supports user-defined windows, where the calculation of each window is triggered by the first record in the next window. However, there is potential for further acceleration in certain cases, such as aggregating 1-minute OHLC bars into 5-minute bars.
This version introduces createTimeBucketEngine, enabling users to define the length of each window using the timeCutPoints parameter. When a record with the last timestamp within the window boundary arrives, the system immediately triggers calculation and closes the window, thus reducing delays and enhancing efficiency.
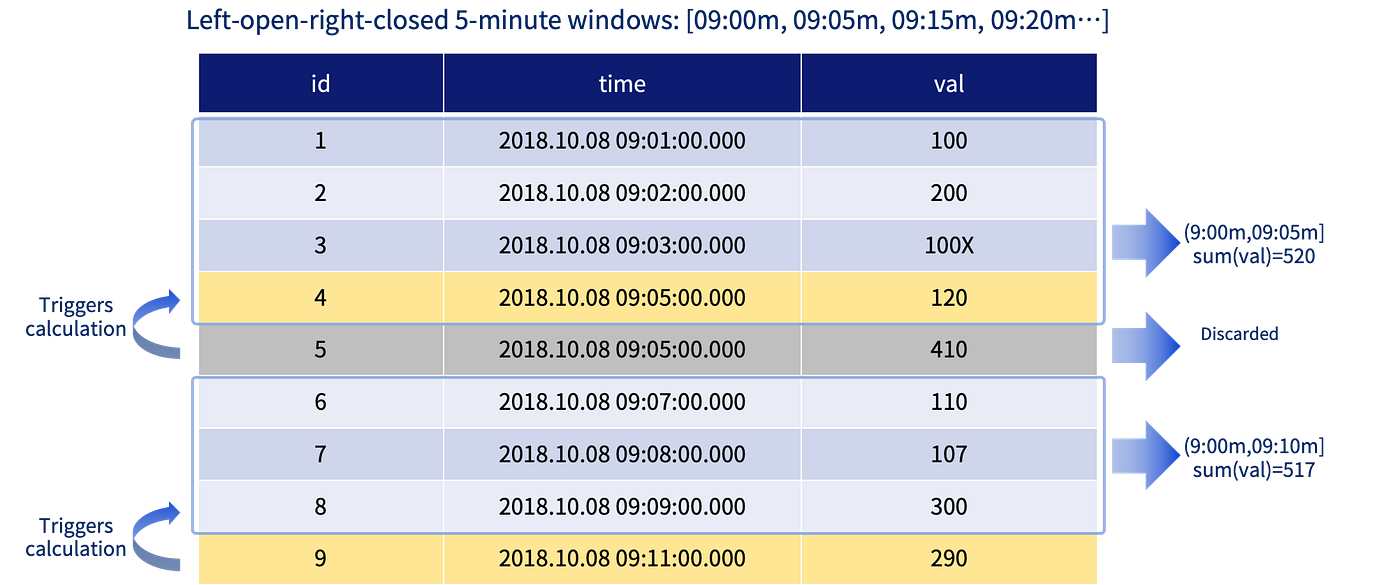
Calculation Mechanism
Additionally, this version introduces the snapshot join engine to receive streams through left and right tables, which performs inner or full outer joins triggered by the latest data from both tables. This feature is ideal for accessing risk metrics such as leverage and net worth.
Rule Engine
- Added function
getRulesto get the rules of the specified rule engine(s).
Reactive State Engine
The
cummddfunction can now be used as the state function for the reactive state engine.Added parameter n for functions
deltasandpercentChangeto enable calculations across multiple rows.When using the
movinghigher-order function in a reactive state engine, its func parameter now supports functions returning tuples.
Daily Time-Series Engine
Enhanced the
createDailyTimeSeriesEnginefunction:It can now include the last window of a session in its output, even if this window contains fewer data records than the specified window size.
Added parameter keyPurgeDaily to determine if existing data groups are automatically removed when newer data from a subsequent calendar day is ingested.
The calculation of daily time series engine now can be triggered by each incoming record with updateTime = 0.
Cross Sectional Engine
- The cross sectional engine can now accept array vector inputs.
Enhanced Database Management
DolphinDB has enhanced access control, cluster management, and storage engines.
Access Control
- Added functions
getDBAccessandgetTableAccessto check the user/group access to specific databases and tables.
Cluster Management
- Added support for logging into an agent node in non-HA clusters.
Storage Engine
For TSDB databases configured to retain all data (keepDuplicated set to ALL), the
upsert!function no longer requires specifying the keyColNamesparameter for all sort columns.The PKEY engine now supports vector indexing.
Optimized Data Analysis Capabilities
In the latest release, DolphinDB’s data analysis capabilities have been further improved in Just-In-Time (JIT) compilation, SQL, and functions.
JIT
JIT now supports classes and more data types (e.g., DATE, DATETIME), significantly enhancing the performance of backtesting plugins.
SQL
- Added support for parallel processing based on hash join algorithms, improving the performance of joins and GROUP BY operations on large in-memory tables.
Function
Added function
histogram2dto calculate the two-dimensional histograms for two datasets.Added function
jsonExtractto extract and parse JSON elements into the specified data type.The prevailing parameter of the
twindowfunction now accepts 0, 1, or 2. When range's left boundary is 0, window starts at current row, excluding prior duplicates, and vise versa.Added parameter minPeriods to functions
mcountandmrankfor specifying the minimum number of observations in a window.
This release is fully backward compatible with all previous functions and scripts, and ensures compatibility with plugin and SDK code, enabling plugin scripts to function smoothly after binary updates.
Upcoming Features
Enhancements for the real-time enterprise computing platform featuring:
Optimized cross-region stream table subscriptions
Simulated calculations in streaming for risk management
Declarative APIs in streaming for usability
Better performance for SQL multi-table joins.
More functions can be accelerated by GPU in the Shark platform, including time-consuming tasks such as complex metric calculations, curve fitting, and derivative pricing.
Email us for more information or to schedule a demo: sales@dolphindb.com
Thanks for your reading! To keep up with our latest news, please follow our Twitter @DolphinDB_Inc and Linkedin. You can also join our Slack to chat with the author! 😉
Subscribe to my newsletter
Read articles from DolphinDB directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by