Backing Up and Restoring Etcd with etctctl and Velero in Kubernetes: Key Insights for CKA and Real-World Applications"
 Shubham Taware
Shubham Taware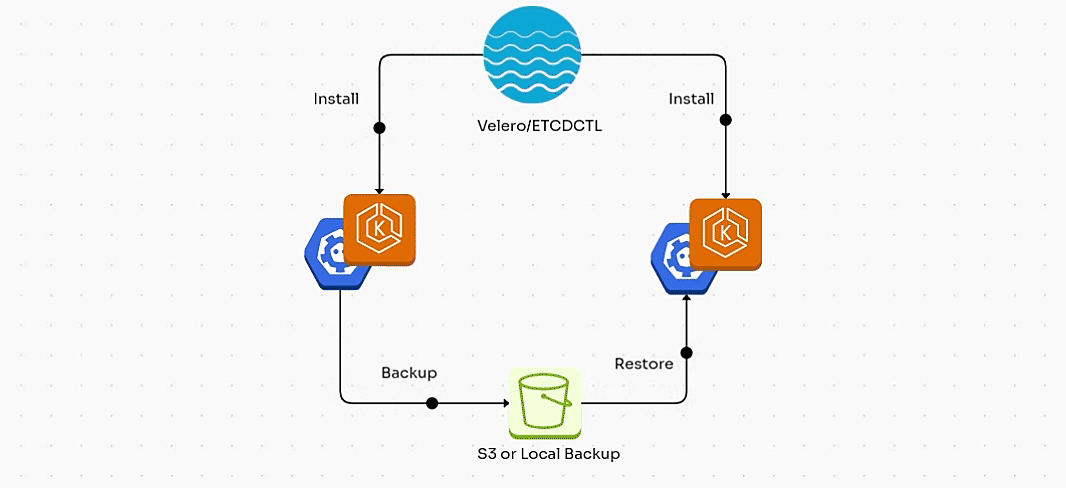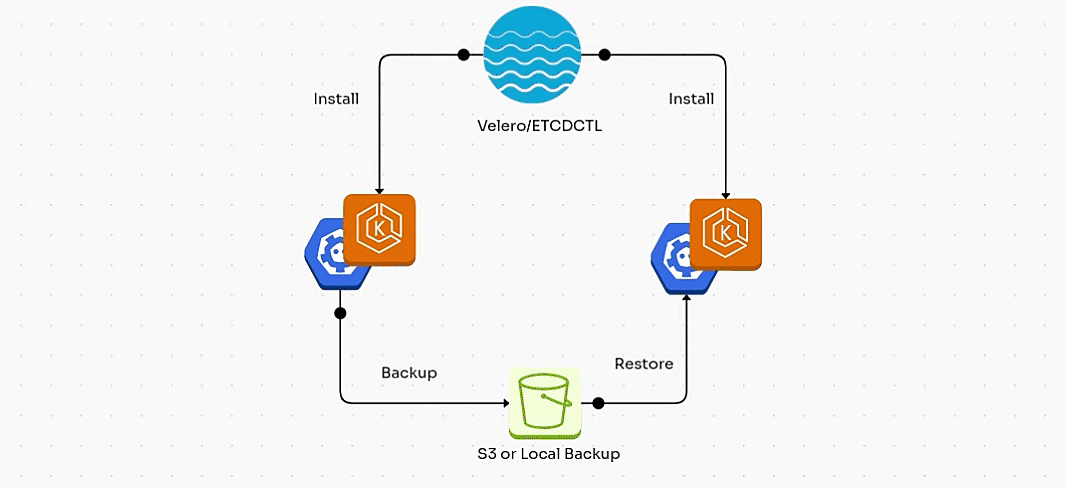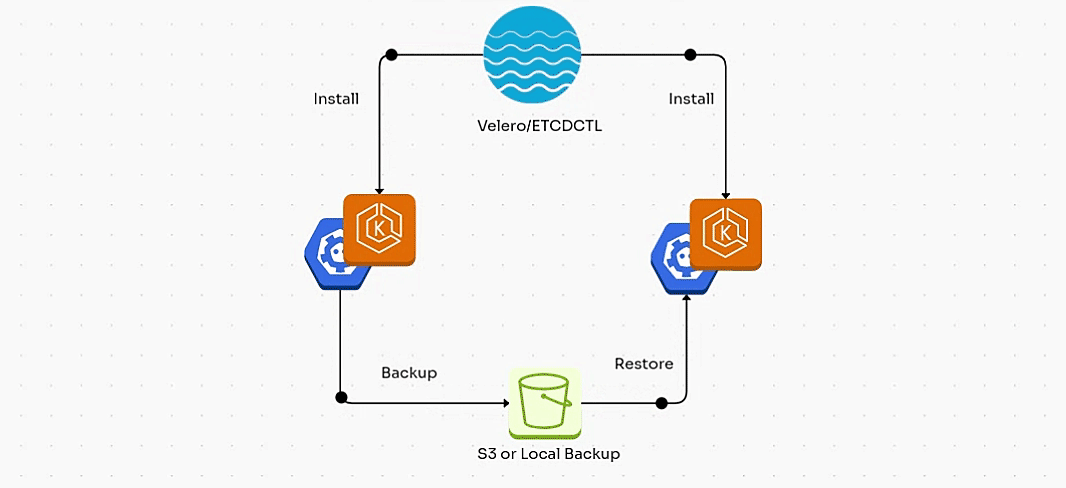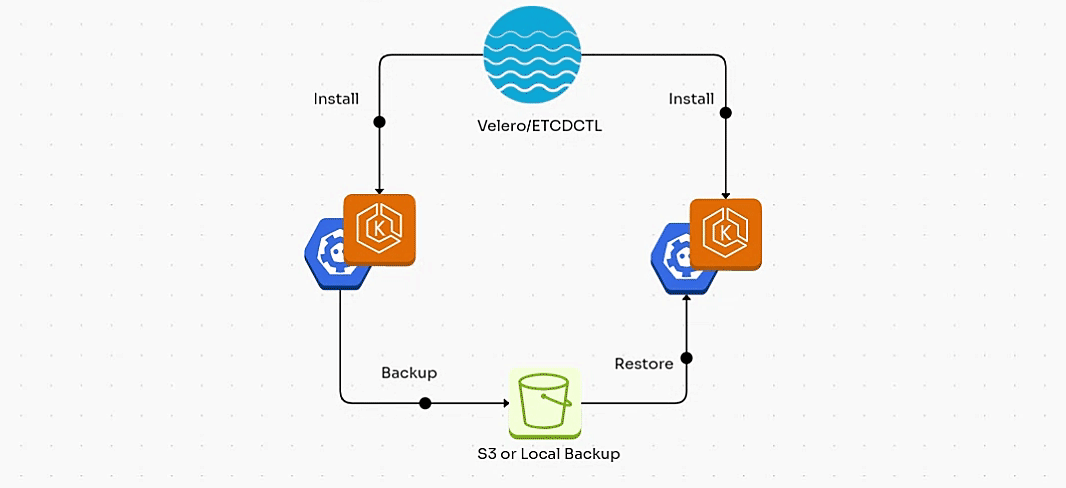
In Kubernetes, data consistency and disaster recovery are critical to ensuring the availability of applications and services. The etcd database serves as the heart of Kubernetes, storing the cluster’s state and configurations, from deployments to secrets and persistent volumes. However, like any database, it can become vulnerable to failure, accidental deletions, or even corruption.
In this blog, we will walk you through the essential steps for backing up and restoring the etcd database in a self-managed Kubernetes cluster created with kubeadm. We’ll also dive deep into Velero, a powerful tool for backing up Kubernetes resources and persistent volumes. You’ll gain a clear understanding of how Velero complements etcd backups, what makes them different, and why you need both in your disaster recovery strategy.
As one of the most important interview topics and a highly relevant question for the Certified Kubernetes Administrator (CKA) exam, mastering etcd backup and restore is crucial for any Kubernetes professional. By the end of this blog, you’ll have practical knowledge of how to perform etcd backups, restore operations, and utilize Velero for Kubernetes resource backup—equipping you with the skills needed to confidently handle these tasks in production environments.
Let’s dive into the details of backing up your Kubernetes state and ensuring you have a robust disaster recovery plan in place!
1. Backup/Restore using ETCDCTL:
In this section, we will walk through the process of backing up and restoring the etcd state in a self-managed Kubernetes cluster (for example, a cluster deployed using kubeadm) using etcdctl.
Prerequisites:
You are running a self-managed Kubernetes cluster (e.g., a cluster set up using
kubeadm).You have access to the master node or wherever etcd is running in your Kubernetes cluster.
You have
etcdctlinstalled. This is the command-line tool to interact with etcd.You have access to the etcd API and the necessary credentials (if any).
Getting Control Plane Data:
The Kubernetes control plane components, are defined as static Pods in YAML files located in the
/etc/kubernetes/manifests/directory. To view etcd configuration, you can check the specific manifest file for the etcd Pod i.e. etcd.yamlCopy the below details in notepad from your etcd.yaml.
--listen-client-urls=https://127.0.0.1:2379 --cert-file=/etc/kubernetes/pki/etcd/server.crt --key-file=/etc/kubernetes/pki/etcd/server.key --trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt
Set Environment Variables for
etcdctlto avoid confusionexport ETCDCTL_API=3 export ETCDCTL_CERT_FILE=/etc/kubernetes/pki/etcd/server.crt export ETCDCTL_KEY_FILE=/etc/kubernetes/pki/etcd/server.key export ETCDCTL_CA_FILE=/etc/kubernetes/pki/etcd/ca.crt export ETCDCTL_ENDPOINTS=https://127.0.0.1:2379 #OR ETCDCTL_API=3 etcdctl --endpoints=https://127.0.0.1:2379 \ --cacert=<trusted-ca-file> --cert=<cert-file> --key=<key-file> \ snapshot save <backup-file-location>Take a Backup of the Etcd Server:
etcdctl snapshot save /path/to/backup/etcd-backup.dbVerify the backup using command:
etcdctl snapshot status /path/to/backup/etcd-backup.dbRestore etcd if there is any issue in cluster:
If any API servers are running in your cluster, you should not attempt to restore instances of etcd. Instead, follow these steps to restore etcd:
stop all API server instances
just move the manifests out of the
/etc/kubernetes/manifestsdir and kubelet will stop the containers gracefully.sudo systemctl stop etcd sudo systemctl start etcdrestore state in all etcd instances
restart all API server instances
just move the manifests into the
/etc/kubernetes/manifestsdir and kubelet will start the containers gracefully.
Restoring the snapshot:
etcdutl --endpoints=https://127.0.0.1:2379 \ --cacert=<trusted-ca-file> --cert=<cert-file> --key=<key-file> \ --data-dir <data-dir-location> snapshot restore snapshot.db #OR etcdutl --data-dir <new-dir-location> snapshot restore snapshot.dbChanging the data directory in /etc/kubernetes/manifests/etcd.yaml:
After restoring the snapshot, you need to update the
etcdconfiguration to use the new data directory (/var/lib/etcd-new) where the restored data has been placed.Look for the --data-dir flag and change it to your new data directory:
--data-dir=/new/data/dir/etcd-new
You’ll need to update the
volumeMountsandvolumessections in theetcd.yamlfile to reflect the newdata-dirand volume paths.sudo systemctl daemon-reload
sudo systemctl restart kubelet
check using the command kubectl describe pod etcd-master -n=kube-system
etcdctl Advantages:
Direct Access to etcd: Provides direct access to backup and restore the Kubernetes control plane data stored in etcd.
Simple and Lightweight: Minimalistic tool focused solely on etcd, making it lightweight for control plane backup.
Fine-Grained Control: Offers granular control over the etcd backup process (manual snapshots, incremental backups).
Self-Managed Clusters: Ideal for self-managed Kubernetes clusters where you control the etcd instance.
etcdctl Disadvantages:
Limited to etcd: Only backs up etcd data; does not cover workloads, services, or persistent volumes.
Manual Operation: Requires manual snapshots and interventions, making it less automated than other solutions.
No Cloud Integration: Lacks native support for cloud storage or cross-region backups.
Not Suitable for Managed Clusters: Cannot be used in cloud-managed Kubernetes (like EKS, AKS) since you don't have direct access to etcd.
No Namespace/Resource-Level Backups: Cannot perform backups for specific namespaces or other Kubernetes resources beyond etcd.
What to use for Cloud Managed Cluster?
Velero. Here's why:
Cloud Provider Integration: Velero integrates with cloud storage services like S3 (AWS), Google Cloud Storage, and Azure Blob Storage, which are ideal for storing backup data in cloud-managed environments.
Full Kubernetes Backup: Velero can back up not just the etcd data (control plane), but also Kubernetes resources (pods, services, deployments, etc.), persistent volumes, and cloud-specific resources.
Automated and Scheduled Backups: Velero supports automated backups, including scheduled and incremental backups, reducing manual intervention.
Disaster Recovery: It supports cross-region and multi-cluster restores, which are essential for cloud-managed clusters with global availability.
Namespace-Level Backups: Velero allows for namespace-level backup and restore, making it more flexible for selective restores.
No Direct etcd Access: Since cloud-managed clusters abstract the etcd database, you cannot directly interact with etcd (like with
etcdctl), making Velero the ideal solution for full cluster backup and restoration.
2. Backup/Restore using Velero:
Step 1: Velero CLI Installation
To begin, you need to install the Velero CLI on your local machine or wherever you will manage the backups from.
Download the Velero CLI:
wget https://github.com/vmware-tanzu/velero/releases/download/v1.7.0/velero-v1.7.0-linux-amd64.tar.gzThis command downloads the Velero CLI release tarball.
Extract the tarball and move the Velero binary to
/usr/local/bin:tar -xvf velero-v1.7.0-linux-amd64.tar.gz -C /tmp sudo mv /tmp/velero-v1.7.0-linux-amd64/velero /usr/local/binThis extracts the tarball and moves the Velero binary to a directory in your
PATH.Verify the installation:
velero version
Step 2: AWS Credentials Setup
Velero needs AWS credentials to interact with your S3 bucket or other AWS services.
Create a file (e.g.,
credentials-velero) with your AWS credentials:[default] aws_access_key_id=YOUR_ACCESS_KEY_ID aws_secret_access_key=YOUR_SECRET_ACCESS_KEYMake sure to replace
YOUR_ACCESS_KEY_IDandYOUR_SECRET_ACCESS_KEYwith your actual AWS credentials.You can get your AWS credentials from the IAM Console in the AWS Management Console. Ensure that the IAM user has sufficient permissions (like S3 and EC2).
Step 3: Velero Installation to Kubernetes Cluster
Now, you need to install Velero into your Kubernetes cluster and configure it to back up to your AWS S3 bucket.
Set Environment Variables for your bucket and region:
export BUCKET=k8-backup export REGION=ap-south-1Install Velero on your Kubernetes Cluster: Use the following command to install Velero, specifying your AWS provider, backup bucket, and credentials file:
velero install \ --provider aws \ --plugins velero/velero-plugin-for-aws:v1.3.0 \ --bucket $BUCKET \ --backup-location-config region=$REGION \ --snapshot-location-config region=$REGION \ --secret-file ./credentials-velero
--provider aws: Specifies that you are using AWS as your cloud provider.--plugins velero/velero-plugin-for-aws:v1.3.0: The AWS plugin Velero will use.--bucket $BUCKET: The name of your S3 bucket where the backups will be stored.--backup-location-config region=$REGION: The AWS region where the S3 bucket is located.--snapshot-location-config region=$REGION: The region where the snapshots will be taken.--secret-file ./credentials-velero: Path to the credentials file you created earlier.
Verify Velero Installation: After running the above command, check that the Velero pods are running properly in the
veleronamespace:kubectl get pods -n velero
Step 4: Creating a Kubernetes Application
For demonstration purposes, you’ll create a simple application that Velero can back up.
Create a simple NGINX deployment:
kubectl create deployment testing --image=nginx --replicas=2Expose the deployment as a service:
kubectl expose deployment testing --name=test-srv --type=NodePort --port=80Port-forward to access the application (for local testing):
kubectl port-forward svc/test-srv 8000:80
Step 5: Create a Backup of the Cluster
Now, you can back up your Kubernetes cluster using Velero.
Verify Backup Locations:
velero backup-location get
This will show the configured backup location (in this case, your S3 bucket).
Create a Backup: Run the following command to create a backup of your cluster:
velero backup create cluster-backup
Velero will now take a backup of the cluster, including Kubernetes resources (deployments, services, etc.) and persistent volumes.
You can check the backup status using:
velero backup get
Step 6: Restore the Backup
If something goes wrong, or you want to restore the backup, you can do so with the following steps:
Restore from a Backup: To restore from the backup you created earlier, run the following command:
velero restore create new-backup-restore --from-backup cluster-backup
This will initiate the restoration of all resources that were backed up in the
cluster-backupbackup.Check the Restore Status: You can monitor the restore process:
velero restore get
Step 7: Verify the Restore
After the restore process completes, you can verify that the resources (like the
nginxdeployment and service) are successfully restored:Check if the pods are restored:
kubectl get podsCheck if the service is restored:
kubectl get svcPort-forward and verify the application is running:
kubectl port-forward svc/test-srv 8000:80
Now you can access the application again on http://localhost:8000
Advantages:
Comprehensive Backup: Backs up Kubernetes resources (pods, services, deployments) and persistent volumes.
Cloud Integration: Supports cloud storage providers like AWS S3, Azure Blob Storage, and Google Cloud Storage.
Multi-Cluster Support: Can back up and restore across multiple clusters or regions.
Automated Backups: Supports scheduled, incremental, and automated backups.
Namespace-Level Backups: Allows for selective backups and restores at the namespace level.
Persistent Volume Backup: Can back up persistent volumes with Restic for cloud-managed clusters.
Disaster Recovery: Enables disaster recovery with cross-region and cross-cloud restore capabilities.
Easy Setup and Use: Simple CLI interface and easy-to-understand commands for users.
Disadvantages:
Resource Overhead: Velero introduces additional overhead in terms of running backup and restore processes in the cluster.
Limited to Kubernetes: Does not back up non-Kubernetes resources (e.g., external databases, external storage).
Cloud Provider Dependency: Relies on cloud storage, so backup costs and performance may depend on the cloud provider.
Initial Setup Complexity: Setup and configuration, especially for multi-cluster or cloud integrations, can be complex.
Large Backup Sizes: Can have large backup sizes, especially with persistent volumes, increasing storage and retrieval costs.
Backup Duration: Large backups may take significant time to complete, affecting cluster performance during the process.
Conclusion:
In this blog, we've explored two essential backup solutions for Kubernetes: etcdctl for self-managed clusters and Velero for cloud-managed clusters.
etcdctl is ideal for backing up the etcd database in self-managed Kubernetes setups, but it's limited to control plane data and doesn’t handle workloads or persistent volumes.
On the other hand, Velero offers a more comprehensive solution, allowing you to back up not just the etcd data but also Kubernetes resources, persistent volumes, and cloud-specific configurations, making it the go-to choice for cloud-managed clusters like EKS, AKS, and GKE.
Both tools are critical for disaster recovery, and understanding how and when to use each is a key skill for Kubernetes professionals, especially for the Certified Kubernetes Administrator (CKA) exam. With the right backup strategies, you can ensure the availability and resilience of your Kubernetes environments.
For more insightful content on technology, AWS, and DevOps, make sure to follow me for the latest updates and tips. If you have any questions or need further assistance, feel free to reach out—I’m here to help!
Streamline, Deploy, Succeed-- Devops Made Simple!☺️
Subscribe to my newsletter
Read articles from Shubham Taware directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Shubham Taware
Shubham Taware
👨💻 Hi, I'm Shubham Taware, a Systems Engineer at Cognizant with a passion for all things DevOps. While my current role involves managing systems, I'm on an exciting journey to transition into a career in DevOps by honing my skills and expertise in this dynamic field. 🚀 I believe in the power of DevOps to streamline software development and operations, making the deployment process faster, more reliable, and efficient. Through my blog, I'm here to share my hands-on experiences, insights, and best practices in the DevOps realm as I work towards my career transition. 🔧 In my day-to-day work, I'm actively involved in implementing DevOps solutions, tackling real-world challenges, and automating processes to enhance software delivery. Whether it's CI/CD pipelines, containerization, infrastructure as code, or any other DevOps topic, I'm here to break it down, step by step. 📚 As a student, I'm continuously learning and experimenting, and I'm excited to document my progress and share the valuable lessons I gather along the way. I hope to inspire others who, like me, are looking to transition into the DevOps field and build a successful career in this exciting domain. 🌟 Join me on this journey as we explore the world of DevOps, one blog post at a time. Together, we can build a stronger foundation for successful software delivery and propel our careers forward in the exciting world of DevOps. 📧 If you have any questions, feedback, or topics you'd like me to cover, feel free to get in touch at shubhamtaware15@gmail.com. Let's learn, grow, and DevOps together!