The Science Behind Large Language Models
 Chirag Joshi
Chirag Joshi
Introduction
Definition and Overview of LLMs
A large language model (LLM) is a type of artificial intelligence (AI) program that can recognize and generate text, among other tasks. LLMs are trained on huge sets of data - hence the name "large". LLMs are built on machine learning: specifically, a type of neural network called a transformer model. The quality of the samples impacts how well LLMs will learn natural language, so an LLM's programmers may use a more curated data set.

After reading this article, you will understand how long-term memory and semantic search work. You will also learn about transformer models, embeddings, and vector databases.
Fundamentals of Language Models
A language model is a type of machine learning model trained to conduct a probability distribution over words. Put it simply, a model tries to predict the next most appropriate word to fill in a blank space in a sentence or phrase, based on the context of the given text. The model doesn’t focus on grammar, but rather on how words are used in a way that is similar to how people write.
Basic Concept of Language Models
Language models are systems designed to predict the likelihood of a sequence of words or generate human-like text based on input data. At their core, they process large datasets of text to learn patterns, grammar, vocabulary, and contextual relationships between words. By analyzing vast amounts of text, language models learn to predict the next word in a sentence or generate coherent responses to prompts. This predictive capability is key to applications in machine translation, summarization, sentiment analysis, and conversational agents. While language models are highly effective at generating text, they do so based on statistical relationships in the data rather than a true understanding of language or meaning.
Introduction to Neural Network-Based Approaches
Neural network-based approaches are foundational in modern machine learning, enabling machines to recognize complex patterns and relationships in data. Neural networks, inspired by the structure and function of the human brain, consist of interconnected layers of nodes (or neurons) that process and transform data. These networks are particularly effective at handling unstructured data like images, audio, and text. In language processing, deep neural networks, such as recurrent neural networks (RNNs) and transformers, have revolutionized natural language understanding by allowing models to capture long-term dependencies and contextual nuances. These networks are trained on massive datasets, gradually adjusting weights through backward propagation to minimize prediction errors, resulting in highly sophisticated models that power applications in speech recognition, computer vision, and AI-driven decision-making.
Architecture of LLMs
The architecture of Large Language Models (LLMs) is typically based on the Transformer model, which consists of stacked layers of attention and feedforward mechanisms. Key architectural elements, like dense layers, enable these models to process complex language patterns by learning contextual relationships and dependencies over vast datasets.
Neural Network Structures Used in LLMs (e.g., Transformers)
Transformers are the primary neural network structure behind LLMs. This architecture introduces self-attention, which allows models to evaluate relationships between words across a sentence or paragraph. Transformers also include feedforward networks, layer normalization, and residual connections, helping maintain stability across deep layers. These structural choices make Transformers highly effective for tasks that involve long-range dependencies and nuanced language understanding.
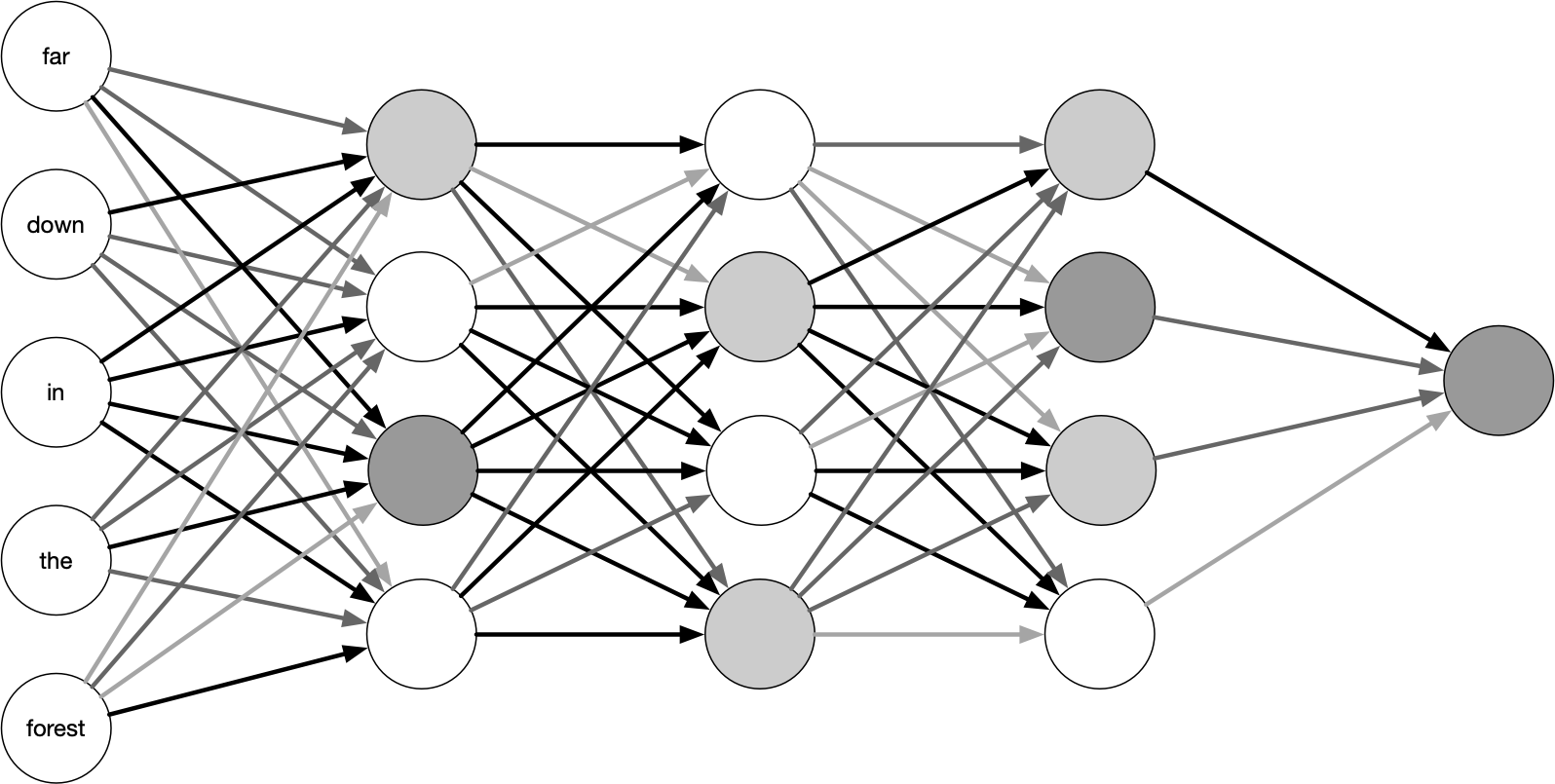
Components of LLMs (Embeddings, Attention Mechanisms, Layers)
Embeddings: The model converts words or subwords into numerical representations that capture semantic meaning, allowing it to process language mathematically.
Attention Mechanisms: Self-attention enables the model to assign weights to different words, allowing it to grasp contextual relationships.
Layers: Transformers use multiple layers of attention and feedforward networks. Each layer progressively refines the model’s understanding of language, improving its ability to generate coherent responses.
Differences Between Small and Large Language Models
Small language models are simpler and have fewer parameters, making them less resource-intensive and quicker to run. However, they may struggle with understanding context and generating high-quality responses. Large language models, with billions of parameters, can process complex language patterns and long-range dependencies, generating more contextually accurate and nuanced responses. However, their size requires significant computational power and memory, making them more challenging to deploy efficiently.
Mechanisms Behind LLM Functionality
The mechanisms of a Large Language Model depend mainly on two components that work together:
Embeddings
Vector Database
What are Embeddings?
Simply put, an embedding is data. Words are turned into a series of numbers called a vector, which shows patterns of relationships. These numbers create a multidimensional map to measure similarities.
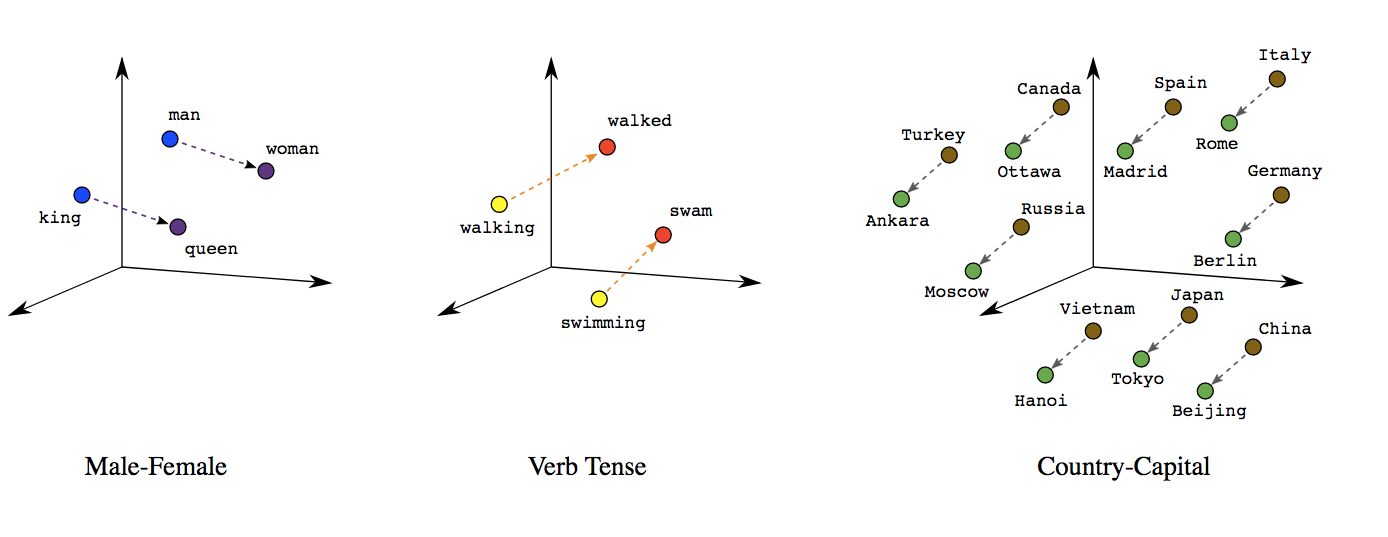
For example, imagine a 2-D Cartesian plane where words used in similar context are mapped together. The words "walked" and "walking" are used closely, so they are mapped close to each other. Likewise, "swim" and "swimming" are mapped close together. However, these two groups are not mapped near each other because they lack contextual similarity. While this is a simple example, real-life embeddings have very complex multidimensional relationships that help the large language model better understand what the user is trying to say.
What are Vector Databases?
Once an embedding is created, it can be stored in a database. A database filled with these embeddings is called a vector database. It can be used in various ways, such as searching: where results are ranked by relevance to a query, clustering: where text strings are grouped by similarity, and recommendations: where items with related text strings are suggested.
A well-known example circulating online demonstrates how several leading LLMs - such as ChatGPT, Claude, Gemini, and MetaAI, fail to correctly answer a simple question about the number of "r's" in "strawberry." This highlights the underlying reason: LLMs don't truly "understand" concepts; they rely solely on predictive algorithms to generate responses.
Doomer Talk & Conclusion
While large language models like GPT have reached impressive levels of sophistication through embeddings, vector databases, and advanced neural network architectures, they are likely approaching a plateau in their current form. These models are already highly adept at generating human-like responses by processing and predicting text based on vast datasets and intricate language patterns. However, true understanding and reasoning remain beyond their reach due to the limitations of current machine learning paradigms. As a result, while we may see incremental improvements, significant leaps in LLM capabilities may require breakthroughs in areas like reasoning-based architectures or hybrid models that integrate symbolic understanding. For now, GPTs and similar models stand as remarkable tools, but the transformative leaps of the future may come from a new generation of AI design.
Subscribe to my newsletter
Read articles from Chirag Joshi directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by