What is an Activation Function?
 Sujit Nirmal
Sujit Nirmal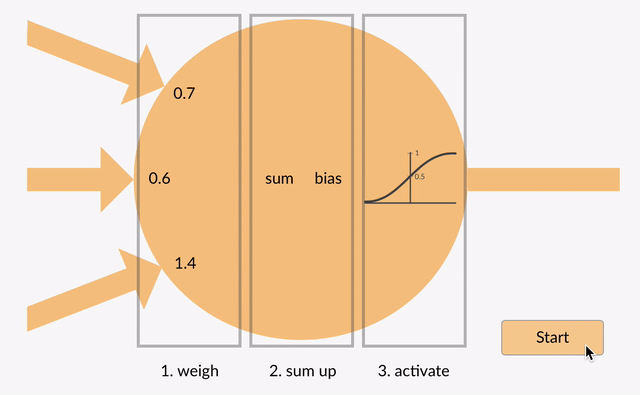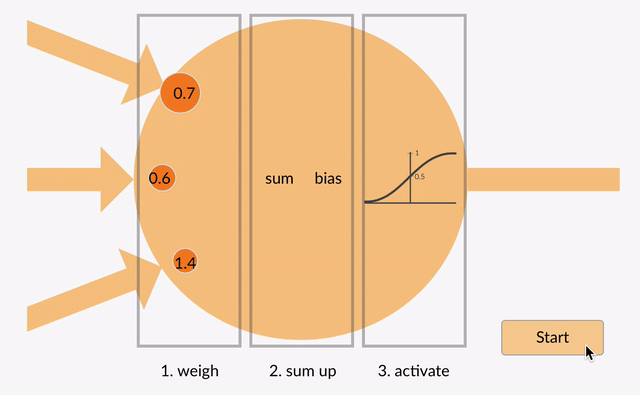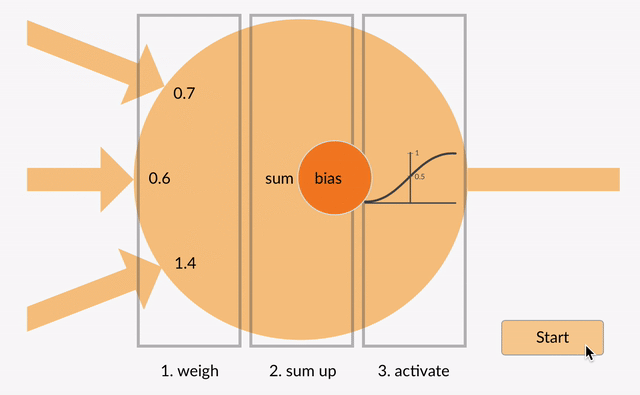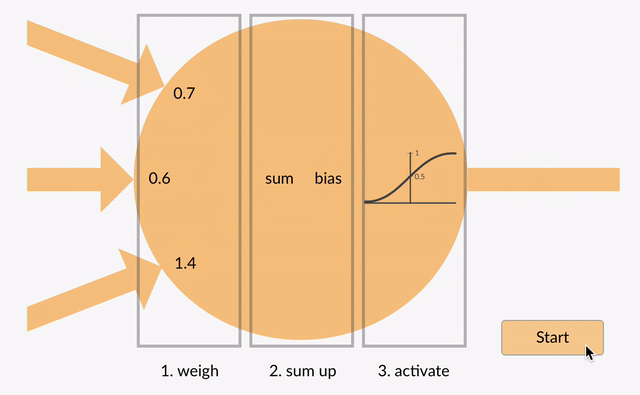
In a neural network, an activation function decides if a neuron should be activated based on the sum of its inputs and weights. This process adds non-linearity to the network, allowing it to learn from non-linear data and solve complex problems like image recognition and speech processing.
Types of Activation Functions:
Sigmoid Activation Function: Maps input values to a range between 0 and 1, making it ideal for binary classification problems. It is differentiable and non-linear, but can suffer from the vanishing gradient problem for large inputs.
import numpy as np def sigmoid(x): return 1 / (1 + np.exp(-x))Tanh (Hyperbolic Tangent) Activation Function: Similar to Sigmoid but maps input values to a range between -1 and 1, making it zero-centered. It has a steeper gradient than Sigmoid, which can lead to faster training.
def tanh(x): return np.tanh(x)ReLU (Rectified Linear Unit) Activation Function: Outputs the input directly if it is positive; otherwise, it outputs zero. It is computationally inexpensive and enables faster convergence but can suffer from the "dying ReLU" problem.
def relu(x): return np.maximum(0, x)Leaky ReLU: Designed to address the dying ReLU problem by allowing a small, non-zero gradient when the input is negative.
def leaky_relu(x, alpha=0.01): return np.where(x > 0, x, x * alpha)ELU (Exponential Linear Units): Similar to ReLU but with negative values, pushing the mean of activations closer to zero, which can speed up learning.
def elu(x, alpha=1.0): return np.where(x > 0, x, alpha * (np.exp(x) - 1))Softmax: Used for multi-class classification problems, compressing a vector of arbitrary real values into a vector of values between 0 and 1 that sum to 1.
def softmax(x): e_x = np.exp(x - np.max(x)) return e_x / e_x.sum(axis=0)Swish: A self-gated activation function that can replace ReLU in deep networks, offering smoothness and unboundedness.
def swish(x): return x * sigmoid(x)Maxout: A layer where the activation function is the max of the inputs, capable of approximating any continuous function.
def maxout(x, w): return np.max(np.dot(x, w), axis=1)Softplus: Similar to ReLU but smoother, with a wide acceptance range.
def softplus(x): return np.log(1 + np.exp(x))
Choosing the Right Activation Function
Selecting the right activation function can significantly impact model performance. For binary classification, Sigmoid is often used for the output layer, while ReLU is popular for hidden layers due to its efficiency. Tanh can be beneficial if zero-centered outputs are needed.
Resources and Interactive Content
To enhance your understanding, consider exploring the following resources:
Happy Coding !!!
Happy Coding Inferno !!!
Happy Consistency !!!
Subscribe to my newsletter
Read articles from Sujit Nirmal directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Sujit Nirmal
Sujit Nirmal
👋 Hi there! I'm Sujit Nirmal, a AI /ML Developer with a passion for creating intelligent, seamless ML applications. With a strong foundation in both machine learning and Deep Learning I thrive at the intersection of data and technology.