how i improved FAST API response time by optimizing LLM selection, token management, and prompt design.
 Vinayak Gavariya
Vinayak Gavariya
i had the opportunity to work on building the backend for a copilot project at my previous organization, using FastAPI, openai’s large language models (llms), langchain, and postgresql. the aim was to design backend apis that not only provided accurate and reliable responses but also maintained a high level of consistency. during testing, however, i noticed that the response times were slower than anticipated. this was a challenge, as it was my first project focusing on both accuracy and performance optimization. here’s how i tackled this issue.
identifying the performance bottleneck
to improve response times, i first needed to understand what was causing the delay. i researched and identified several factors that could impact the performance of openai’s models:
model type – different models vary in terms of speed and accuracy. some models are quicker but may compromise on response quality, while others are more accurate but slower.
maximum token size – larger token inputs and outputs take more time to process. controlling token size can help speed up responses.
prompt design – the structure and wording of prompts impact response time and relevance. shorter, clearer prompts tend to perform better, resulting in faster and more accurate responses.
we were initially using gpt-4-turbo, which provided accurate results but had slower response times than we wanted. to find a balance, i tested several other models, including gpt-4o, gpt-3.5-turbo, and gpt-4o-mini. each model had unique strengths in terms of speed and accuracy, so i measured response times across a consistent set of api calls.
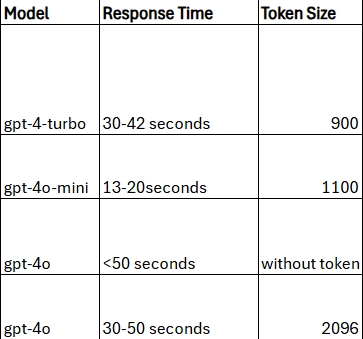
note:- the data in the above image is based on manual tests conducted on our specific use case.
in these tests, gpt-4o-mini was the fastest but came with reduced accuracy. while i considered sticking with gpt-4-turbo for its reliability, i also wanted to see if we could speed it up without compromising too much on quality.
strategies for improving api performance
to optimize the response times, i focused on two main areas:
reducing token size – after investigating token count, i realized that higher token sizes significantly slowed down responses. by experimenting with smaller token sizes, i was able to speed up responses. however, this approach required balancing token reduction carefully to prevent a loss of data and accuracy.
refining prompt structure – i worked on crafting shorter and more specific prompts. refining prompts in this way allowed the model to interpret the questions faster, which improved response time while keeping relevance high. this iterative process involved multiple prompt variations to find the optimal structure.
achieving faster results
after extensive testing and optimization, i successfully reduced the api response time from 30-42 seconds to 13-20 seconds. this substantial improvement brought us closer to our performance goals without sacrificing too much accuracy. while gpt-4o-mini offered the fastest response times, gpt-4-turbo provided a better balance between speed and quality, especially after refining token counts and prompt structures.
key takeaways for optimizing fastapi with openai llms
this project highlighted some essential strategies for building high-performance apis using llms. here are the main takeaways:
understand model strengths and trade-offs – knowing the pros and cons of each model helps in selecting the right one based on your requirements. faster models may lack in accuracy, while more complex models might require optimization for speed.
manage token limits carefully – keeping token sizes in check can significantly improve response time. balancing tokens with content quality is essential, as cutting down too much may impact the response’s relevance.
refine prompt design for efficiency – concise, targeted prompts enhance response speed without compromising on quality. testing various prompt styles and lengths can help you find the ideal structure for quick, accurate responses.
iterative testing – performance tuning is an iterative process. by testing, analyzing, and refining configurations, you can gradually improve both speed and consistency.
through careful model selection, token management, and prompt optimization, i was able to achieve a substantial boost in the copilot api’s performance. this hands-on approach allowed us to build a responsive and reliable backend, tailored to meet both speed and accuracy requirements.
if you have additional insights or suggestions on optimizing apis with llms, feel free to share – i’d love to hear your thoughts!
always eager to learn and connect with like-minded individuals. happy to connect with you all here!
Subscribe to my newsletter
Read articles from Vinayak Gavariya directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Vinayak Gavariya
Vinayak Gavariya
Machine Learning Engineer