Backend Patterns: Response/Request
 Onuh Chidera Theola
Onuh Chidera TheolaIntroduction
In the beginning, there was nothing. Then, like the spark of creation, the request/response pattern emerged. This pattern, one of the oldest and simplest forms of backend communication, remains fundamental to how computers interact over a network today. Despite its simplicity, the request/response pattern is still a powerful technique used to facilitate communication between services.
At its core, the process is straightforward: a client (like a web browser) sends a request, which travels across the network to a server, where a corresponding response is generated and returned. We see this in everyday actions, such as when you fill out a form and hit "submit," expecting feedback from the application—this back-and-forth is a prime example of the request/response pattern in action.
In this article, I'll dive into what I’ve learned so far about this timeless pattern, exploring its mechanics, importance, and real-world examples as well as its limits and applications, because despite how simple and easy it is to use, you might want to think twice when it comes to certain use-cases. Let’s dive in.
Request/Response Structure
The request/response pattern is often described as symmetrical because it is defined by a clear, structured exchange between two entities: the client and the server. In this interaction, the roles are distinct but complementary.
Client: The client initiates the conversation by sending a request. This could be a web browser requesting a webpage, a mobile app querying an API, or a device asking for data. The request itself contains vital information, such as the desired action (e.g., retrieving or updating data), parameters, and sometimes authentication tokens.
Server: The server, acting as the receiver, processes this request. It understands the intent, performs the necessary operations (such as querying a database or executing business logic), and formulates a response. This response is then sent back to the client, completing the cycle.
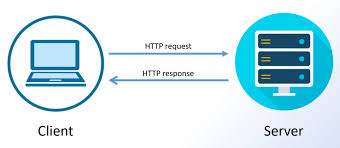
Despite this structured flow, the symmetry lies in the predictable nature of this exchange: a request leads to a response, with both the client and server playing their respective roles each time.
Layers of the Request/Response Cycle
This pattern operates across multiple layers of the network stack:
Application Layer: Where the logic of the request is handled (e.g., HTTP requests in a web application).
Transport Layer: Where data is reliably transferred between the client and server (e.g., TCP/IP). A request has a boundary and that boundary is defined by a protocol and the message format.
Network Layer: Responsible for routing the data packets through the network.
Each layer plays its part in ensuring the smooth, symmetrical flow of data from client to server and back again.
Stateless Communication
One of the key characteristics of the request/response pattern, especially in web development, is that it is typically stateless. This means that each request from the client is treated independently by the server. The server does not "remember" previous interactions—each request is a new conversation. While this improves scalability and simplicity, it also requires mechanisms like sessions or tokens to maintain context between requests.
Real-World Example
Consider a common use case: submitting a search query on a website. When you type a query into a search bar and hit "Enter," the client (your browser) sends a request to the server. The server processes the query, searches through its data, and returns a response—typically a list of results for you to browse. This entire process happens in milliseconds, yet it encapsulates the request/response cycle perfectly.
Why It Matters
The simplicity and predictability of this pattern have made it foundational for most networked applications. From REST APIs to web servers, the request/response pattern underpins much of modern computing, allowing for reliable communication in a wide variety of contexts.
How Requests are Handled
Traditionally, requests were handled using simpler, straightforward models. These include:
Sequential Request-Response Handling: The most traditional way of handling requests was through sequential or one-by-one or by blocking process means such as:
Single Request at a Time: In the early days of network communication, servers handled one request at a time. When a client sent a request to a server, the server executed that request and sent a response before it could address any other requests. This meant that, while one request was being processed, no additional requests could be handled until the current request was fully completed.
Blocking I/O: Short for Blocking input/output operations. These operations refer to situations where a server is forced to wait while a particular task such as reading or writing data or querying a database is processed and executed.
Synchronous Communication: The client would send a request and wait for the response before sending another request. This sequential model created bottlenecks, especially with multiple users.
Threaded Request Handling
As systems evolved, an early improvement to the sequential request model was the introduction of multithreading. One common method was the Thread-per-Request model, where a new thread (or process) is created for each incoming request. This allows each request to be handled by its thread, enabling multiple requests to be processed in parallel.
Concurrency: This approach introduced the ability to manage multiple requests concurrently, rather than making clients wait for their turn in a strict sequential queue.
The downside of threaded handling models is that, while they improve responsiveness and concurrency, they also introduce overhead. Threads consume system resources such as memory and CPU. If a server attempts to handle too many requests at the same time, it may encounter issues like:
Thread contention: When two or more threads attempt to access the same content/resource at the same time.
Context switching overhead: The resources and time consumed when a CPU switches between processes or threads.
Out-of-memory errors(OOM): Occurs when a computer lacks sufficient memory to run applications.
Traditional HTTP/1.0
In the world of web communication, HTTP/1.0 (HyperText Transfer Protocol)/1.0 brought a fundamental change by establishing a fresh connection for every single request. The early versions of HTTP/1.0 followed a very basic request/response model. It's a simple yet powerful mechanism that laid the groundwork for how we interact with the internet today. The model is characterized by two important features:
Single Connection per Request: Once the server delivered its response, that connection would gracefully close, making way for a new one with the next request.
Statelessness: Each connection was independent of the previous one, with no knowledge of earlier requests.
This model worked great for low-traffic systems but as information grew so did the web, hence constantly opening and closing connections became a sort of bottleneck situation, significantly reducing performance, especially for applications with web assets (like images, CSS and Javascript).
HTTP/1.1 (Persistent Connections)
One of the key limitations of HTTP/1.0 was that it closed the connection after each request/response cycle. This meant that for every new request, a new connection had to be established, causing significant overhead. HTTP/1.1, introduced to address these inefficiencies, brought the concept of persistent connections.
If you inspect the network activity in your browser's developer tools, you'll notice a field in the response headers called Keep-Alive. When set to “true,” it indicates that the server is reusing the same connection for multiple requests, rather than opening and closing a connection for each one. This dramatically reduces the overhead associated with establishing new connections, leading to faster load times and more efficient resource use. This ability to keep connections open for multiple requests is one of the key features introduced by HTTP/1.1.
Currently, the latest version of HTTP used on the internet is HTTP/3, which is built on the QUIC protocol, originally developed by Google. Unlike previous versions of HTTP, which rely on TCP (Transmission Control Protocol), HTTP/3 uses UDP (User Datagram Protocol). This switch allows HTTP/3 to offer faster connection setups and improved performance on unreliable networks, such as mobile or Wi-Fi networks, where packet loss and latency can be an issue.
If you're curious to dive deeper into the different HTTP versions and the underlying protocols, there's a wealth of information available to explore.
Now, knowing how requests were handled in the past compared to today might lead you to believe that this pattern is flawless—after all, it's been the foundation of the web for decades. But as with any system, there are challenges and trade-offs. Let’s explore those next.
Why Request/Response Can’t Work Everywhere
The Request/Response pattern, while simple and foundational, isn’t always the best choice for every communication scenario between a client and server. Its simplicity, which makes it easy to use and understand, also becomes its limitation in more dynamic, real-time contexts.
Let’s look at an example: notifications in a web application. In the traditional Request/Response model, the client only receives data from the server when it explicitly makes a request. This means that if the client needs updates about new notifications, it has to keep polling the server—sending repeated requests to ask, “Do I have any new notifications?” Not only is this inefficient, but it also creates unnecessary traffic, potentially flooding the network with repetitive requests even when there’s no new information.
This is like asking for a present every day leading up to Christmas, only to be told to wait until Christmas morning. In the meantime, you’re bombarding the system with requests that go unanswered until the moment the event actually happens. This inefficiency can lead to performance issues, especially in applications that require frequent updates or real-time interaction.
A more effective approach for handling notifications would be to use WebSockets. With WebSockets, the server can maintain an open connection to the client, allowing it to push updates asynchronously as soon as new notifications are available. This eliminates the need for constant requests from the client. The connection remains open, and the server simply sends the data when necessary, leading to real-time updates without the overhead of constant polling.
The Request/Response model also struggles in other scenarios that require low-latency, real-time communication. For instance:
Chat applications: In a chat app, relying on requests for every new message would cause noticeable delays. WebSockets or other real-time protocols allow for instant message delivery.
Long-running requests: When a server takes a long time to process a request (e.g., generating reports), the client would have to keep the connection open or poll the server. Asynchronous processing or WebSockets can handle such cases more elegantly.
Unexpected client disconnections: If the client disconnects, the server might continue processing a request, which could lead to wasted resources. More dynamic systems can better handle reconnections and recover from disconnections gracefully.
While Request/Response is useful in many scenarios, particularly for short, stateless transactions, it falls short in situations requiring real-time updates, long-lived connections, or more interactive, low-latency communication.
Resources:
Subscribe to my newsletter
Read articles from Onuh Chidera Theola directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Onuh Chidera Theola
Onuh Chidera Theola
Hello 👋🏾 I’m a highly motivated software developer from Nigeria, who enjoys coming up with solutions and ideas for new projects. I also enjoy reading a lot, like books, comics/manga,manhwa. Feel free to connect with me anytime☺️