ML Experience: MLOps, ModelOps, DataOps & DevOps
 Amit Sides
Amit Sides
Undoubtedly, 2025 will be dedicated to disentangling the relationships between ModelOps - the way we manage the Model-Development-Life-Cycle (MDLC) and DataOps, the way we manage data pipelines, ETL/ELT. In this article, this relationship is examined while considering DevOps in mind, underlying Cloud infrastructure, and the set of tools we use in the complex process of delivering our Data Scientist and ML Engineering a Development Experience and eventually deploying and serving Model Inference to Production. Like always, my claim remains, that the challenge is in Orchestration.
ML-DataOps Pipelines and Workflow: Raw→Features→Vectors→Inferences
Creatively Orchestrate Workflows
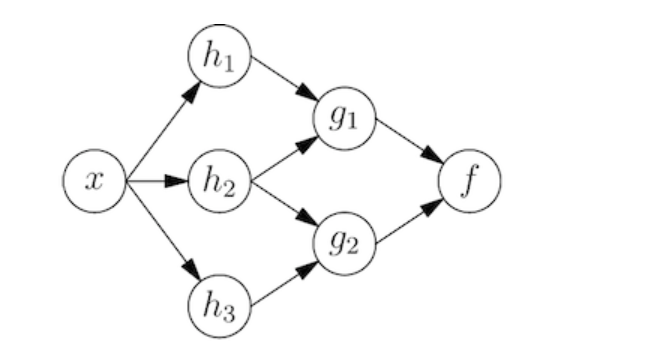
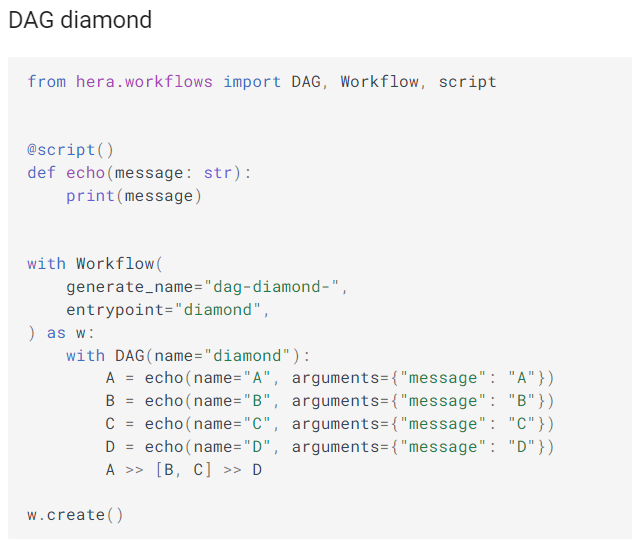

Draw a DAG Diamond in Python with Hera
Data Injection: Streaming Data & Analytics
Apache AirFlow (data lineage), AWS GLUE, Apache Beam DataProc DataFlow
Where to Start while considering future throughput? Apache Samza?
While designing our future high-scale infrastructure so we can deal with high throughput we can consider
maintaining Apache Kafka on Kubernetes (see node-termination-handler).
Managed Kafka Service
Lenses (AWS MSK)
See Schemas: Cloud Events JSON, AVRO
Our data is taking too many shapes (JSON, ONNX, HDFS), and there are even more tools we can use in our DataOps/data lineage pipelines. We want to consider DevOps best practices. Choose the right tools for the task.
Data Versioning & Preprocessing

[ picture from Tensorflow ]
[ Uber’s great article on feature while orchestrating HDFS, Spark, Samza, Cassandra, MLLib, XGBoost, and TensorFlow for real business purposes is inspiring. ]
Lineage: Data as MetaData
Ask yourself: Where do data lineage and Data-Meta-Data tools (OpenLineage Amundsen) work with data pipelines, data-warehouses?
Knitfab
Repo: https://github.com/opst/knitfab
MLOps system & tool. Release AI/ML engineers from trivial routines.
Automatic tracking of 'lineage'
Dynamic workflow based on 'tags'
Use of k8s and container to isolate ML tasks
MLOps-Data: From Features to Vectors
Feature Engineering, Feature Store
Decoupling ML from Data, Feature Storing Registries for better ML data pipelines.
[ Feast Overview | Featuretools Overview | Databricks | Feast on Kubernetes ]

Feature pipelines Feature Engineering + Data pipeline architecture offer the first stages before training our model.
Data Science Experience or MLExp: Data Science, Notebooks, Jupyter & CUDA
The most important part of MLOps is Model Development Experience; it takes the form of allowing Data Scientists and Machine learning engineers to jump right into running powerful notebooks on NVIDIA CUDA with K8s.
Clone this Data Science Notebooks and K8S GPU NVIDIA CUDA PYTORCH JUPYER
Data Science ToolSet
K8S + ModelOps: Pods of Tensorflow
[ MLflow Overview | Kubeflow Overview | MetaFlow’s Infrastructure ]
apiVersion: kubeflow.org/v1
kind: TFJob
metadata:
generateName: tfjob
namespace: your-user-namespace


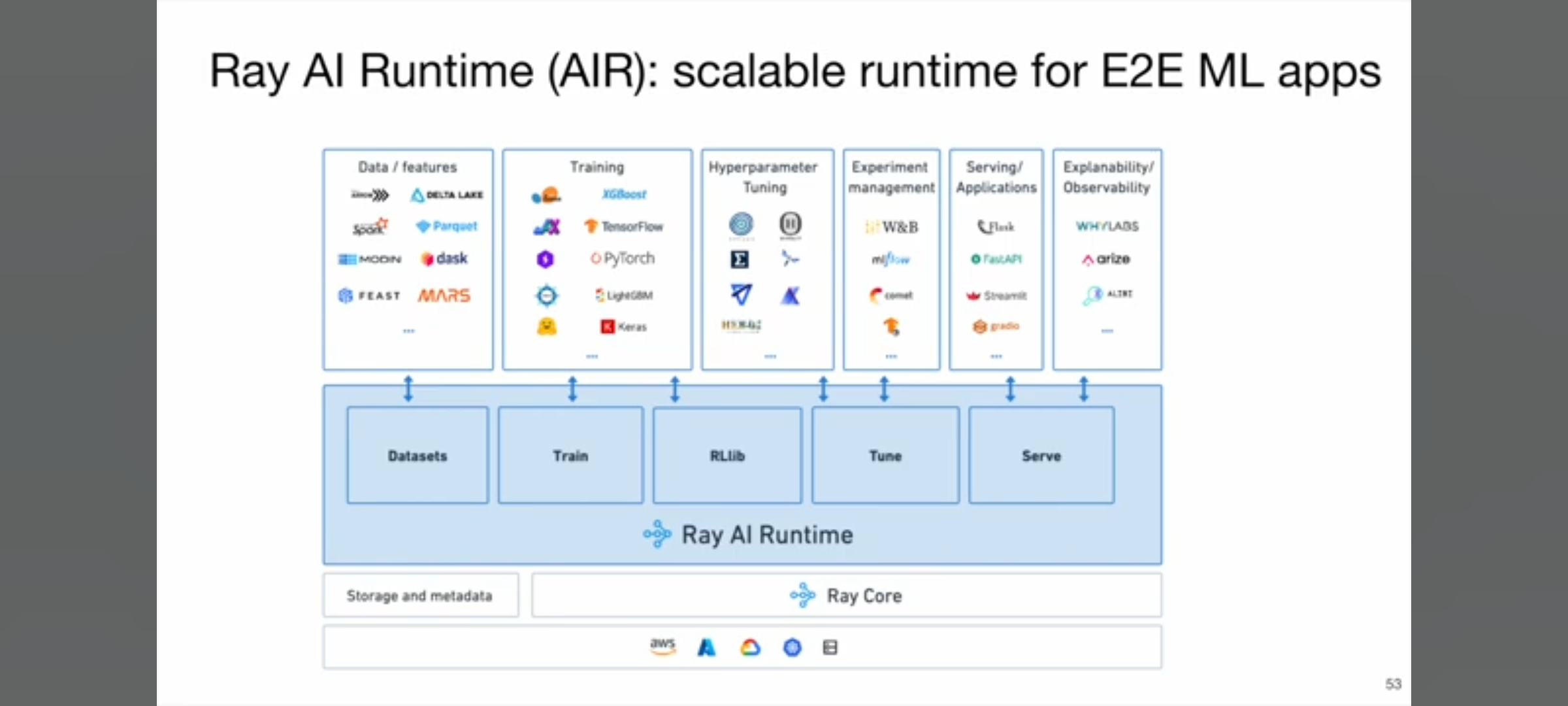

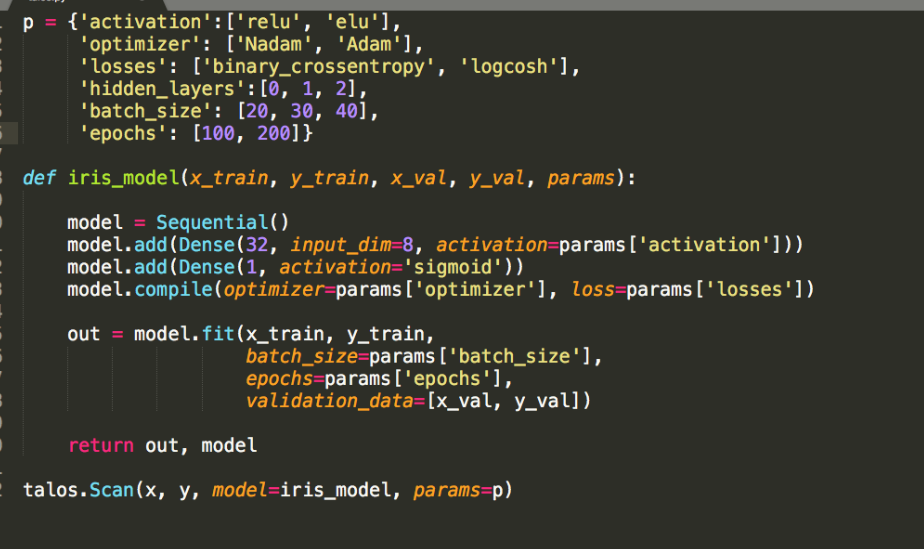
Hyperparameters Libraries
SOTA Model ZOOs
AutoML [ ONNX | Modelzoo | AutoKeras | Huggingface MTeb | Trax | Model Registry | ML Metadata
“AutoEmbedding” + VectorStore + VectorDB
“AutoEmbed” if you wish not to invent wheels today. import pre-trained Models with ready-to-use state-of-the-art code snippets. Wrap it up as a Docker container to easily generate embedding at scale and ship them into VectorDB.
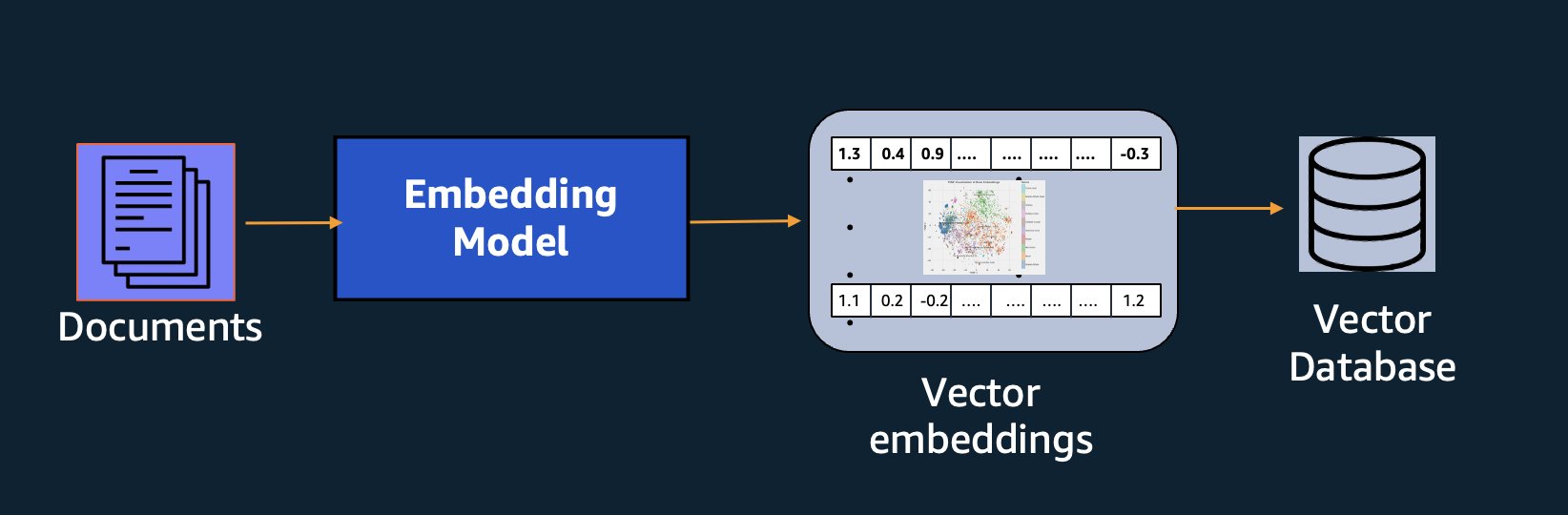

# custom selection of integrations to work with core
pip install llama-index-core
pip install llama-index-llms-openai
pip install llama-index-llms-replicate
pip install llama-index-embeddings-huggingface
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("YOUR_DATA_DIRECTORY").load_data()
index = VectorStoreIndex.from_documents(documents)
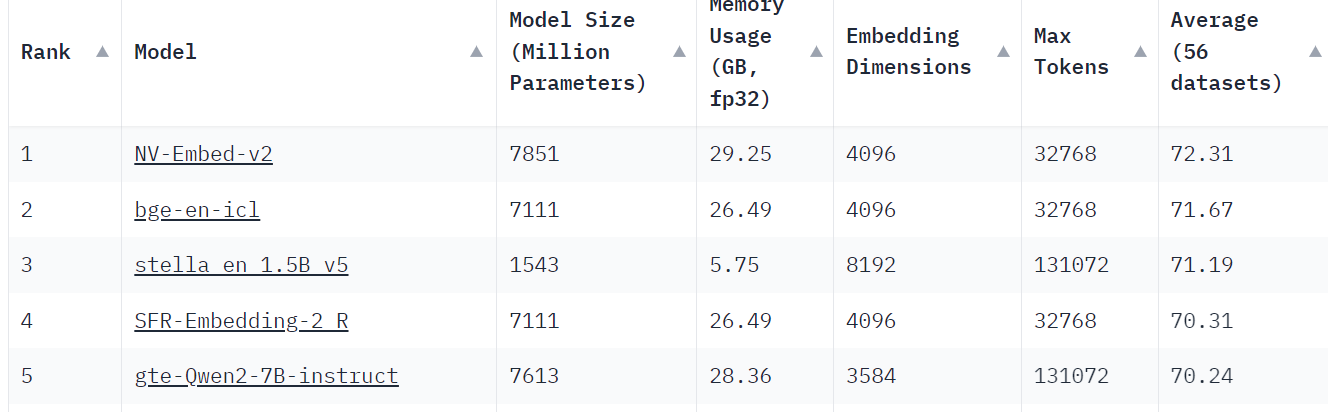
TOP 5 - Massive Text Embedding Benchmark (MTEB)
from langchain_openai import OpenAIEmbeddings
embed = OpenAIEmbeddings(
model="text-embedding-3-large"
)
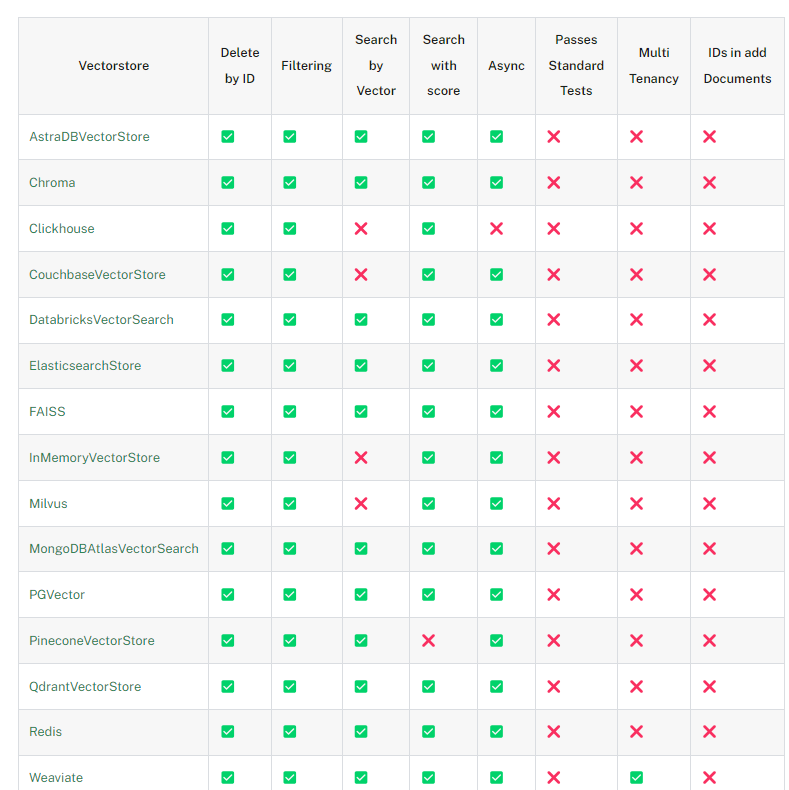
Choose your VectorDB
| Vector DB | Best For | Not Recommended For |
| Milvus 2.0 | Large-scale production deployments | Small datasets (<100k vectors) |
| Pinecone | Cloud-native applications | On-premise requirements |
| Weaviate | Semantic search applications | High-cardinality exact search |
| Qdrant | Real-time applications | Batch processing only |
| Chroma | Prototyping and small datasets | Large-scale deployments |
| pgvector | PostgreSQL integration | High-performance requirements |
DevSecOps Note: Vectors with Data Poisoning?
Deployment & Serving: Production Inferences
I’ll not discuss actual “deployment(.yaml)” in this section because I have referred to it in detail in the previous article. Instead, I’ll discuss the relationships between VectorDb, GPUs, and Production Model Inferences, or Serving.
Philosophical Note: if our Embeddings are VectorStored, and we use Query to our VectorDb, isn’t our API JSON response just GenAI?
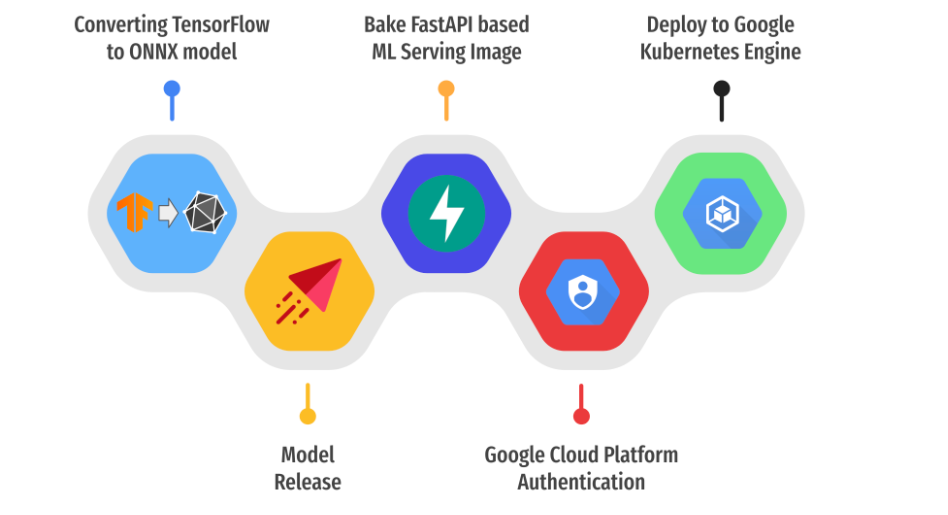
git clone https://github.com/sayakpaul/ml-deployment-k8s-fastapi/tree/main
git clone https://github.com/kserve/kserve/tree/master
git clone https://github.com/DmitryBe/onnx-serving/tree/master
5.vLLM TPU Dockerfile
https://github.com/vllm-project/vllm/blob/main/Dockerfile.tpu
Summary: Machine Learning Operation + Data Mesh
This article aimed to provide the scope for the challenges of orchestrating many tools in the different aspects of ModelOps. On the one hand, we have many tools to help Orchestrate by building Flows and Pipelines so it could give shape and “glue” everything together, but on the other hand, we have too many tools :)
Personal Tip: Recommended Books to advance your knowledge
Aim to learn more about orchestrating MLOps with Event-driven data mesh in a Cloud Native Environment.

Check out my git repository MLPlay for code examples.
Subscribe to my newsletter
Read articles from Amit Sides directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Amit Sides
Amit Sides
Amit Sides is a AI Engineer, Python Backend Developer, DevOps Expert, DevSecOps & MLOPS GITHUB https://github.com/amitsides