The Symphony of AI: How We Deduplicate Our Databases in the Age of AI
 Ali Yazdizadeh
Ali Yazdizadeh
First Movement: Tackling "Almost-Duplicate" Records in Our Database
- Understanding Our Mission
At Datachef, we are on a mission to build our own interconnected knowledge base on Notion, where we organize records of our Hiring Pipeline linked to our CRM, which in turn connects to Companies, which has links to the Topics related to them. This structure allows us to easily access all information related to any person or entity within our company. For example, we have a "DataChef Orientation Project" where we introduce our company to new hires. Using this knowledge base, it's easy to guide someone to find all relevant information about any topic , specialty or company.
To maintain this system, we must avoid creating duplicate pages for any identity, whether it’s a company, a person, or a specialty. We adhere to the principle of “1 Concept = 1 Notion Page.” This ensures that we can start from any page and navigate to a related person or topic we’re interested in, with each concept consistently represented by a single Notion page.
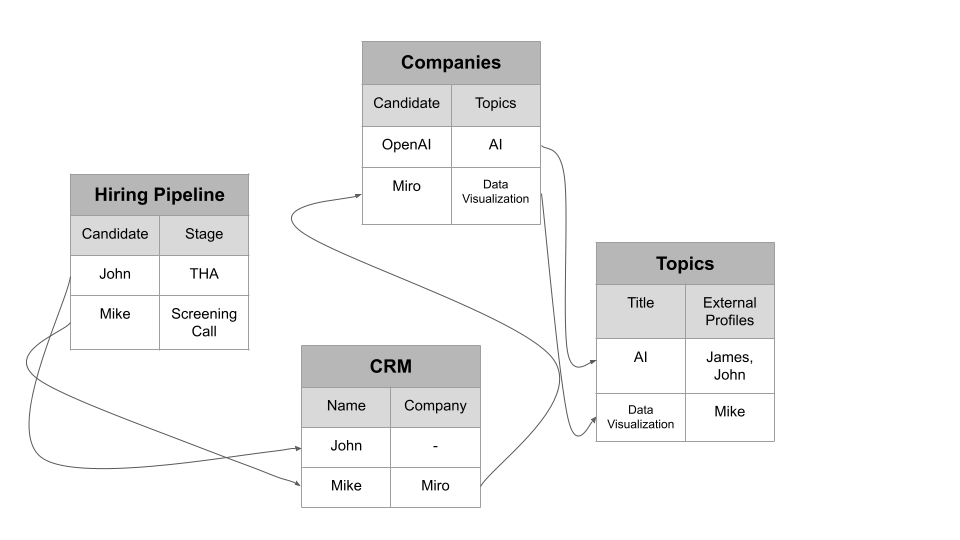
Figure 1: Our Knowledge Base Overview
- Story of Our Topics Database
The Topics Database is an extensive list of subjects that matter to us, like "Data Science”, “Community Building”, “AWS," and many more. This collection originates from LinkedIn skills and the specialties listed on the profiles of individuals and companies. However, we also allow for manual additions, which can lead to unwanted growth and “almost-duplicate” records.
Imagine someone searching for "Linux Admin" and, not finding a match, adding it as a new record, despite the presence of a "System Admin" entry that refers to the same role in our context. To solve these near-duplication challenges, we’ve implemented a multi-step machine learning solution tailored to each stage of our process.
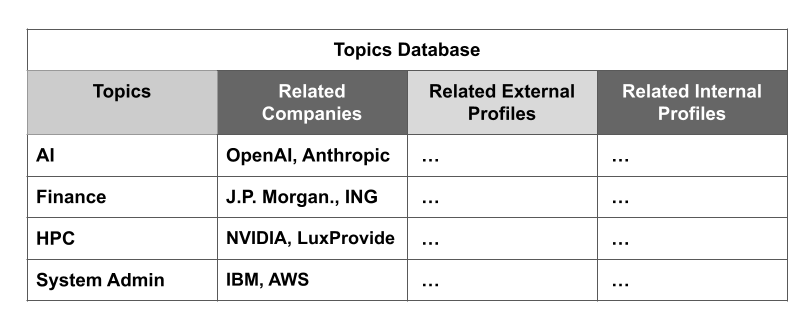
Figure 2: Topics Database Overview
Second Movement: The Challenge of Context-Dependent Deduplication
- Why Context Matters in Deduplication
One of our core challenges was recognizing that deduplication is not simply a matching exercise—it’s a context-dependent clustering problem. While clustering generally involves identifying similar data points based on a chosen distance metric, the subjectivity of deduplication requires more nuance. For example, while "Marketing" and "Advertising" may be distinct for a retail-focused team, "Data Science" and "Data Analysis" could be overlapping categories for them, while distinct topics for a tech company! Here’s how we went about solving this issue.
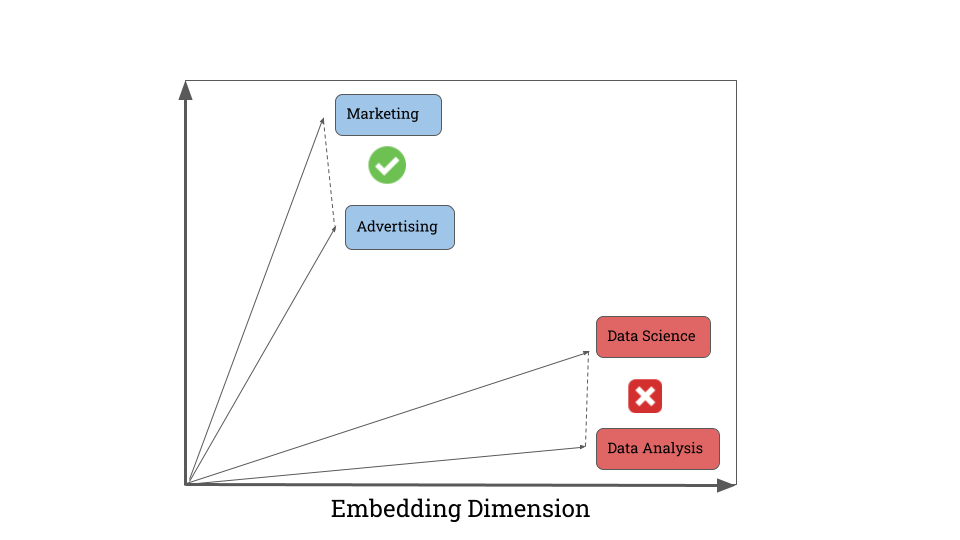
Figure 3: Topics with almost same distance have different desired outcome
Third Movement: Orchestrating AI and Machine Learning Tools to Solve Deduplication
To address these deduplication challenges, we orchestrated a combination of AI-powered and traditional ML tools, with a focus on flexibility, efficiency, and contextual accuracy. Our solution involves the following steps:
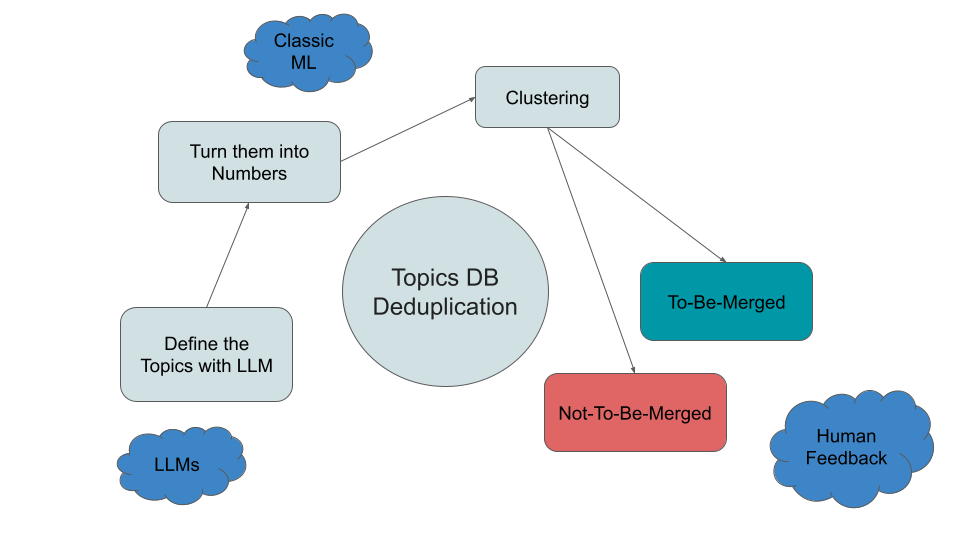
Figure 4: Deduplication Process Flow
- Step 1: Clarifying and Expanding Topics with Large Language Models (LLMs)
Since some topics involve abbreviations or require contextual clarification, we used OpenAI’s Chat API to expand topics into clearer descriptions. For instance, "CDK" becomes “Cloud Development Kit, CDK, an open-source software development framework for defining cloud infrastructure in code.” This expansion reduces ambiguity and sets the stage for accurate comparison.
- Step 2: Embedding Topic Descriptions
To compare topics meaningfully, we needed to convert descriptions into numerical form. Initially, we used basic text comparison techniques, but they fell short—consider how “Kubernetes” and “Container Orchestration” have little word overlap despite their similarity in meaning. By using OpenAI’s Embedding API, we transformed each description into a multidimensional vector representation, capturing the semantic essence of each topic.
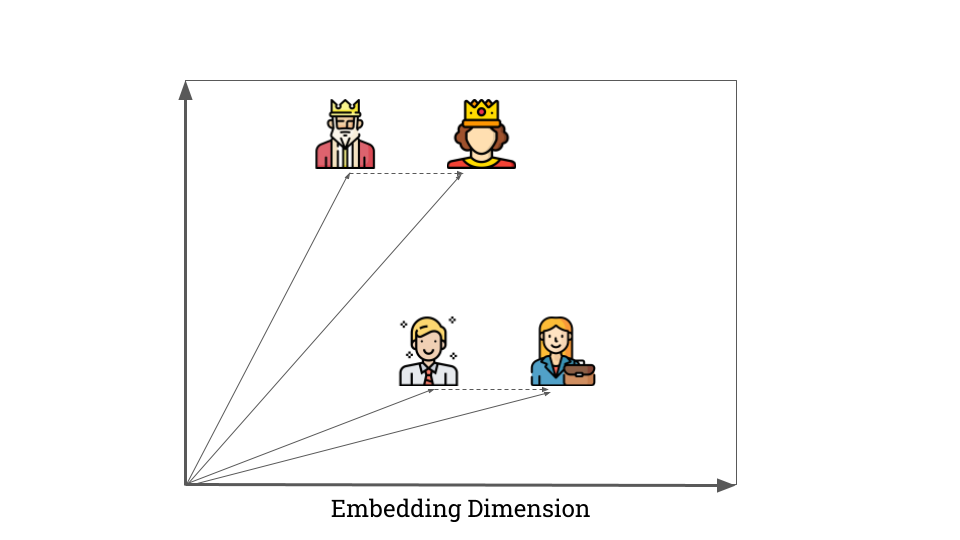
Figure 5: Example of Embedding (e.g., “king” + “woman” = “queen”)
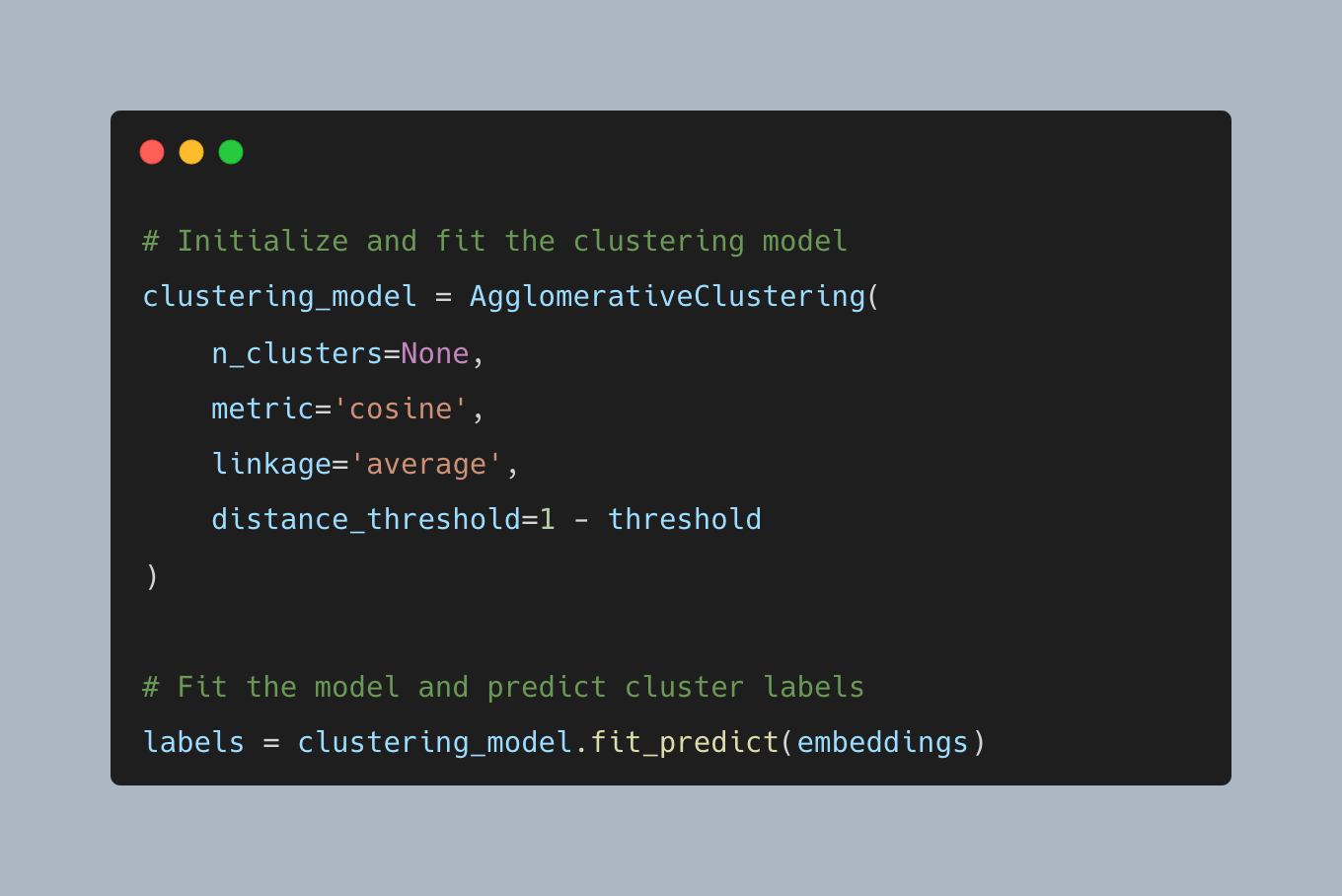
- Step 3: Clustering with Agglomerative Clustering
Once we had the embedded representations, we started by using the K-means algorithm to cluster topic vectors, however the need to decide the number of clusters before hand limits the use of this algorithm when we periodically run it and can not tell how many clusters we have beforehand. Therefore we employed Agglomerative Clustering, a flexible algorithm that lets us define strictness with a distance threshold. This approach allows us to control the granularity of clustering, ensuring we don’t unnecessarily merge distinct topics but can still find and consolidate nearly identical ones. As a bonus, this algorithm also gives you the hierarchy of the clustering which can be useful for interpretation and debugging!
- Step 4: Integrating Human Feedback
As we discussed in the second movement, one of the challenges in this project is that the clustering algorithm does not distinguish between different fields when setting the merging threshold. We could add a local threshold option where the model adjusts the clustering threshold based on the topic’s location in the embedding space. For example, if the topic pertains to Tech and IT fields, it could apply a stricter threshold. However, this would add complexity to an already intricate system. Instead, we opted for a simpler approach to integrate user feedback into the database. Each time two topics are merged incorrectly, they will be labeled and avoided in future clustering rounds. Over time, this will help prevent merging topics that are close but need differentiation.
Fourth Movement: A Glimpse into the Future of AI in Software
This deduplication project showcases the broader potential of AI in software: smart, adaptable, and contextually aware solutions that improve accuracy over time. By integrating a range of AI tools—from LLMs for language understanding to embedding and clustering algorithms—we’ve developed a system that handles ambiguity, respects context, and continually learns from feedback.
Our experience represents a vision for future software, where engineers will have a full repertoire of AI algorithms to tackle various problems, from small-scale deduplication to large-scale automation.
If you’re interested in exploring how AI can revolutionize business, join us in our AI for Business course, where we’ll dive into practical applications that empower businesses to harness the full potential of AI.
Subscribe to my newsletter
Read articles from Ali Yazdizadeh directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by