LeetCode刷题日记
 Xayla
Xayla
最后一个单词的长度
思路
题目明确了提供的字符串以空格隔开每一个单词,要获取到最后一个单词长度,首先需要先获取到最后一个单词。因此可以遍历字符串,以空格作为分隔符来定位最后一个单词串,再获取其长度即可;
具体实现上,我们可以从字符串末尾开始查找,只要查找的字符串没有达到首部,并且目标字符串不是空串的情况下,就移动指针,一直查找,直到定位到第一个非空字符串,这就是周后一个单词的末位索引.
接下来,只需要继续向前查找到下一个空格,表示查找到了最后一个单词的开始字符的前一个位置(此时索引i指向的实际是空字符);
获得了起始索引,再通过索引截取子串即可得到最后一个单词,返回其长度即可 ;
代码实现
模版模式
class Solution {
public:
int lengthOfLastWord(string s) {
int i = s.length() - 1;
while(i >=0 && s[i] == ' ')
{
i--;
}
int end = i;
while (i >= 0 && s[i] != ' ')
{
i--;
}
return s.substr(i+1,end - i).length();
}
};
ACM模式
#include<iostream>
#include<string>
int main()
{
std::string s;
std::getline(std::cin,s);
int i = s.length();
while (i >= 0 && s[i] == ' ')
{
i--;
}
int end = i;
while(i >= 0 && s[i] != ' ')
{
i--;
}
std::cout << s.substr(i+1,end - i).length();
return 0;
}
学习substr
在 C++ 中,substr是std::string类的一个成员函数,用于获取字符串的子串,其用法如下:
string substr (size_t pos = 0, size_t len = npos);
2. 参数说明
pos(起始位置):
类型为
size_t,它指定了子串在原字符串中的起始位置,索引从 0 开始。例如,如果pos为 3,那么子串将从原字符串的第 4 个字符开始(因为索引是从 0 开始计数)。如果
pos的值超过了字符串的长度,substr函数会抛出out_of_range异常。不过,如果pos等于字符串长度,将返回一个空字符串。
len(长度):
类型为
size_t,它指定了要获取的子串的长度。如果省略
len参数或者将其设置为string::npos(这是string类中定义的一个特殊值,表示最大可能的长度),则子串将从pos开始一直延伸到原字符串的末尾。
代码示例
#include <iostream>
#include <string>
int main() {
std::string str = "Hello, World!";
// 示例1:获取从索引2开始长度为5的子串
std::string sub1 = str.substr(2, 5);
std::cout << "sub1: " << sub1 << std::endl;
// 示例2:获取从索引7开始到字符串末尾的子串
std::string sub2 = str.substr(7);
std::cout << "sub2: " << sub2 << std::endl;
// 示例3:pos等于字符串长度,返回空字符串
std::string sub3 = str.substr(str.length());
std::cout << "sub3: " << sub3 << std::endl;
return 0;
}
sub1: llo,
sub2: World!
sub3:
单词规律

思路
题目提到,规则中的每一个字符和单词字符串存在着双向对应关系,这是判断S是否满足对应规律的条件。可以联想到使用哈希表来解决,将字符串s拆分为单词组,这里可以借助vector进行实现。
对于规则和目标字符串,我们可以使用两个哈希表存储他们互相的映射关系,具体后面会说,在判断是,我们只需要判断两个哈希表中的映射关系是否都满足,满足表示字符串符合给定的单词规则,返回true即可;
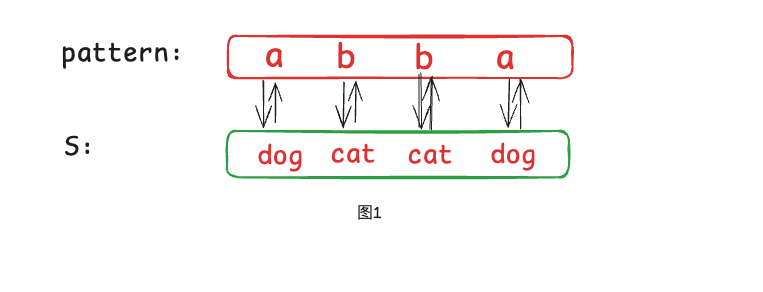
具体的,我们拿其中一个测试用例来做详细的图解:
pattern:a b b a
s:dog cat cat dog
下面是该测试用例的映射关系:
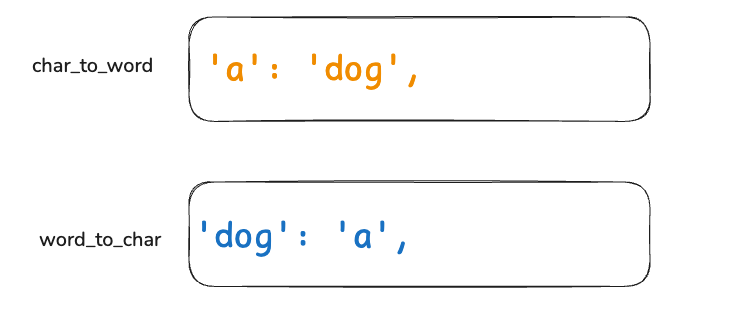
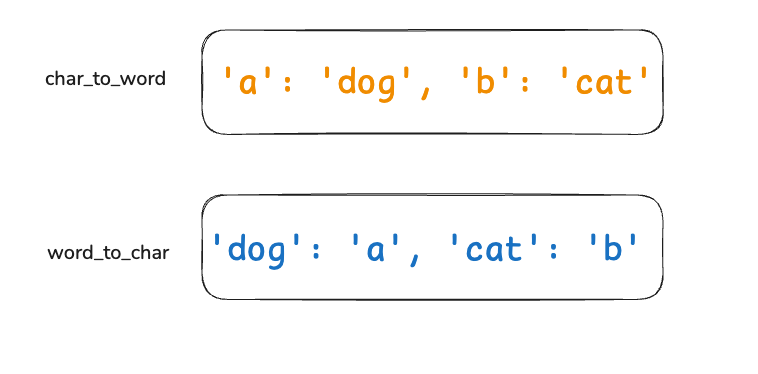
接下来,我们假设存在这样两张映射表,char_to_word存储字符到单词的映射,word_to_char存储单词到字符的映射。
基于此,下面是对应的整个模拟过程:
1. pattern 中的第 1 个字符 'a' 与单词 'dog' 映射:
-
char_to_word检查: 'a' 尚未映射,将 'a' -> 'dog'。-
word_to_char检查: 'dog' 尚未映射,将 'dog' -> 'a'。
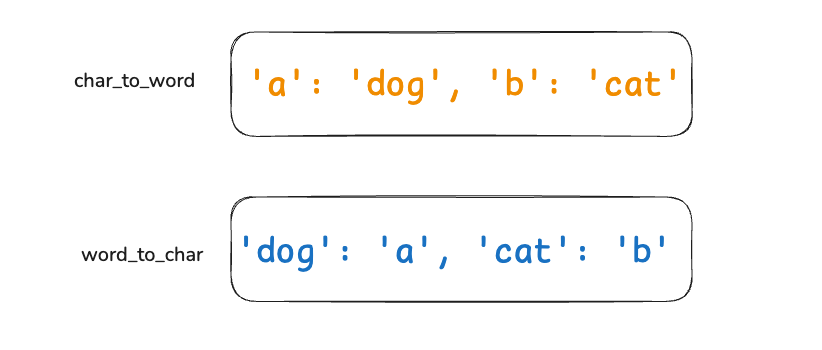
2. pattern 中的第 2 个字符 'b' 与单词 'cat' 映射:
-
char_to_word检查: 'b' 尚未映射,将 'b' -> 'cat'。-
word_to_char检查: 'cat' 尚未映射,将 'cat' -> 'b'。
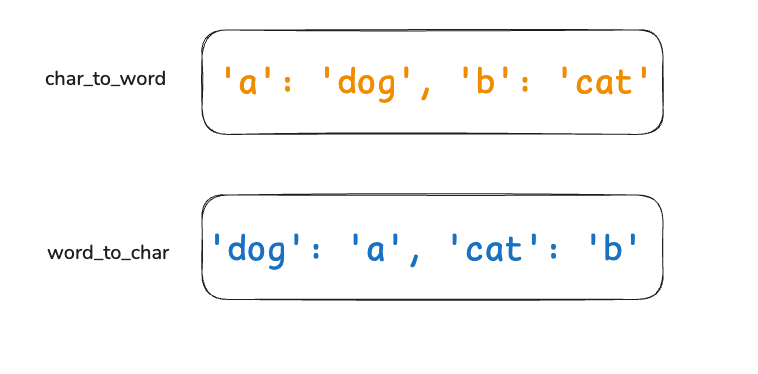
3. pattern 中的第 3 个字符 'b' 与单词 'cat' 映射:
-
char_to_word检查: 'b' 已映射到 'cat',且当前单词也是 'cat',匹配通过。-
word_to_char检查: 'cat' 已映射到 'b',且当前字符也是 'b',匹配通过。
4. pattern 中的第 4 个字符 'a' 与单词 'dog' 映射:
-
char_to_word检查: 'a' 已映射到 'dog',且当前单词也是 'dog',匹配通过。-
word_to_char检查: 'dog' 已映射到 'a',且当前字符也是 'a',匹配通过。
所以该测试用例中,字符串s符合给定的单词规则,返回true;
代码实现
class Solution {
public:
bool wordPattern(string pattern, string s) {
vector<string> words;
string word;
istringstream stream(s);
// 将字符串分割为单词数组;
while(stream >> word)
{
words.push_back(word);
}
// 长度特判
if(pattern.length() != words.size())
{
return false;
}
// 建立相互的映射关系;
unordered_map<char,string> char_to_word;
unordered_map<string,char>word_to_char;
for(int i=0;i<pattern.length();i++)
{
char c = pattern[i];
string w = words[i];
if (char_to_word.contains(c))
{
if (char_to_word[c] != w)
{
return false;
}
}else
{
char_to_word[c] = w;
}
if (word_to_char.contains(w))
{
if (word_to_char[w] != c)
{
return false;
}
}else
{
word_to_char[w] = c;
}
}
return true;
}
};
学习unordered_map
std::unordered_map 是 C++ 标准库中提供的一种哈希表数据结构,位于 <unordered_map> 头文件中。它以键值对的形式存储数据,允许我们根据键高效地查找对应的值。
1. 基本语法和初始化
#include <unordered_map>
#include <string>
#include <iostream>
int main() {
// 声明一个 unordered_map,用字符串作为键,整数作为值
std::unordered_map<std::string, int> map;
// 使用初始化列表
std::unordered_map<std::string, int> map2 = {{"apple", 2}, {"banana", 3}, {"cherry", 5}};
}
2. 常用操作
1. 插入元素
可以用 operator[] 或 insert 函数来添加元素:
map["apple"] = 2; // 插入 "apple": 2
map.insert({"banana", 3}); // 使用 insert 插入 "banana": 3
map.emplace("cherry", 5); // 使用 emplace 插入 "cherry": 5
2. 访问元素
可以用 operator[] 或 at 方法来访问元素:
std::cout << map["apple"] << std::endl; // 输出值 2
std::cout << map.at("banana") << std::endl; // 输出值 3
注意:operator[] 如果键不存在会插入一个默认值,而 at 方法在键不存在时会抛出异常。
3. 查找元素
使用 find 函数查找键值对:
auto it = map.find("apple");
if (it != map.end()) {
std::cout << "Found: " << it->first << " -> " << it->second << std::endl;
} else {
std::cout << "Not found" << std::endl;
}
4. 检查键是否存在
使用 count 方法可以查看键是否存在:
if (map.count("banana") > 0) {
std::cout << "banana exists in the map" << std::endl;
}
5. 删除元素
使用 erase 函数删除键值对:
map.erase("apple"); // 删除键为 "apple" 的元素
6. 遍历元素
使用范围 for 循环遍历 unordered_map:
for (const auto& pair : map) {
std::cout << pair.first << " -> " << pair.second << std::endl;
}
3. 常用特性和注意事项
无序:
unordered_map是无序的,因此无法保证插入的顺序。哈希表:
unordered_map使用哈希表实现,查找、插入和删除的平均时间复杂度为 O(1)。唯一键:每个键在
unordered_map中是唯一的,如果插入重复的键,后插入的会覆盖先插入的。
4. 示例代码
#include <unordered_map>
#include <iostream>
int main() {
std::unordered_map<std::string, int> fruits = {{"apple", 2}, {"banana", 3}, {"cherry", 5}};
fruits["orange"] = 4; // 插入新元素
if (fruits.count("apple")) {
std::cout << "apple count: " << fruits["apple"] << std::endl;
}
// 遍历 unordered_map
for (const auto& pair : fruits) {
std::cout << pair.first << ": " << pair.second << std::endl;
}
fruits.erase("banana"); // 删除元素
return 0;
}
在 C++20 中,std::unordered_map 新增了一个 contains 方法,可以用来简便地检查某个键是否存在,替代 count 或 find 的用法。相比 count,contains 更简洁、语义也更清晰。
#include <unordered_map>
#include <iostream>
int main() {
std::unordered_map<std::string, int> fruits = {{"apple", 2}, {"banana", 3}, {"cherry", 5}};
// 使用 contains 检查键是否存在
if (fruits.contains("apple")) {
std::cout << "apple exists in the map." << std::endl;
} else {
std::cout << "apple does not exist in the map." << std::endl;
}
if (!fruits.contains("grape")) {
std::cout << "grape does not exist in the map." << std::endl;
}
return 0;
}
contains 和 count 的区别
contains:直接返回一个布尔值,表示键是否存在,代码更简洁,语义也更明确。count:返回指定键的计数(对于unordered_map,键是唯一的,所以返回 0 或 1)。count适用于 C++11 及更早版本。
注意
contains 方法仅在 C++20 及以上版本中可用。如果您使用的是 C++17 或更早版本,仍需使用 count 或 find 方法。
Subscribe to my newsletter
Read articles from Xayla directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by