Unlocking the Power of Tokenization: A Deep Dive into Generative AI and NLP
 genvia
genviaIntroduction
Definition of Generative AI
Generative AI is a fascinating realm of artificial intelligence that focuses on creating new and original content, mimicking the data it was trained on. Imagine a digital artist, composer, or writer that learns from vast collections of existing works and then crafts something entirely new—this is the essence of generative AI. These systems leverage sophisticated machine learning models, often rooted in deep learning, to produce unique text, images, music, code, video, and more. They don't merely replicate what already exists; instead, they identify and learn intricate patterns, structures, and features from extensive datasets, enabling them to generate outputs that are both innovative and contextually appropriate. The market is brimming with diverse models, each specializing in different types of content generation, such as:
Image Generation Models: These models can create stunning visuals, from realistic portraits to abstract art, by understanding and replicating the nuances of visual data.
Text Generation Models: Capable of crafting anything from poetry to technical documentation, these models understand language intricacies and can produce coherent and contextually relevant text.
Video and Sound Generation Models: These models can generate dynamic video content and immersive soundscapes, pushing the boundaries of creativity in multimedia production.
Generative AI is not just about replication; it's about innovation and expanding the horizons of what machines can create. In this article, we will explore the critical role of tokenization in Natural Language Processing (NLP), a fundamental process that enables machines to understand and generate human language effectively. By delving into the intricacies of tokenization, we aim to uncover how it transforms raw text into structured data, paving the way for advanced language models to perform tasks like translation, sentiment analysis, and more. Join us as we unlock the power of tokenization and its impact on the future of AI-driven content creation.
Tokenization
In Natural Language Processing (NLP), it's important to understand some basic concepts that help organize and analyze language data:
Corpus: A large collection of text used to train language models. It includes text from various sources like books, articles, and social media.
Documents: Individual pieces of text within a corpus, such as a single article or email.
Vocabulary: The set of all unique words found in a corpus. It acts like a dictionary for the NLP model.
Words: The smallest units of meaning in text, which can be whole words or parts of words.
For example, in a news corpus:
Corpus: A collection of 10,000 news articles.
Documents: Each article is a document.
Vocabulary: All unique words in those articles.
Words: Tokens like "climate," "change," and "policy" in each document.
Tokenization is a key process in Natural Language Processing (NLP) that involves breaking down text into smaller, manageable pieces called tokens. These tokens can be words, subwords, or characters, and they help transform raw text into a structured format that models can easily understand and process.
Importance of Tokenization in NLP
Standardizes Input: Tokenization transforms continuous, unstructured text into discrete tokens, simplifying the processing for models. For example, the sentence "The cat's whiskers are long" becomes ["The", "cat", "'s", "whiskers", "are", "long"].
Facilitates Analysis: By breaking text into meaningful chunks, tokenization aids models in understanding word relationships, detecting sentiment, and analyzing context. For instance, in the sentence "I love sunny days," tokenization helps identify "love" as a positive sentiment word.
Improves Efficiency: Tokenization reduces text complexity by segmenting it, which decreases computational load and memory usage. For example, processing "Artificial Intelligence" as ["Artificial", "Intelligence"] is more efficient than handling the entire phrase as a single unit.
Handles Language Ambiguity: It manages contractions, punctuation, and special characters, which can be challenging for models to interpret directly. For example, "don't" is tokenized into ["do", "n't"], clarifying its structure.
Supports NLP Tasks: Tokenization is crucial for tasks like translation, sentiment analysis, and summarization by allowing flexible token creation at different levels. For example, in machine translation, tokenizing "running" into ["run", "ning"] can help in understanding and translating the root word.
Enables Language Modeling: It helps create word embeddings, which are vector representations capturing word meanings and relationships. For example, the word "king" might be represented in a vector space close to "queen," reflecting their semantic relationship.
Types of Tokenization
Types of Tokenization:
Word Tokenization: This process splits text into individual words, making it easier to analyze language at the word level. For example, the sentence "The quick brown fox" is tokenized into ["The", "quick", "brown", "fox"].
Sentence Tokenization: This method breaks text into sentences, which is useful for tasks that require sentence-level analysis. For instance, the text "Hello world! How are you?" is tokenized into ["Hello world!", "How are you?"].
Subword Tokenization: This approach divides words into meaningful subunits, which is particularly useful for languages with complex morphology or for handling rare words. For example, the word "unhappiness" might be tokenized into ["un", "happiness"].
Character Tokenization: This technique breaks text into individual characters, which can be useful for very fine-grained text analysis or for languages where characters carry significant meaning. For example, the word "hello" is tokenized into ["h", "e", "l", "l", "o"].
Practicals
Setup of the NLTK
import nltk
nltk.download('punkt_tab')
nltk.download('punkt')
This is use to import nltk library. The Natural Language Toolkit (NLkT) is a powerful Python library for working with human language data (text). It provides tools for text processing, analysis, and computational linguistics.
Sentence Tokenization
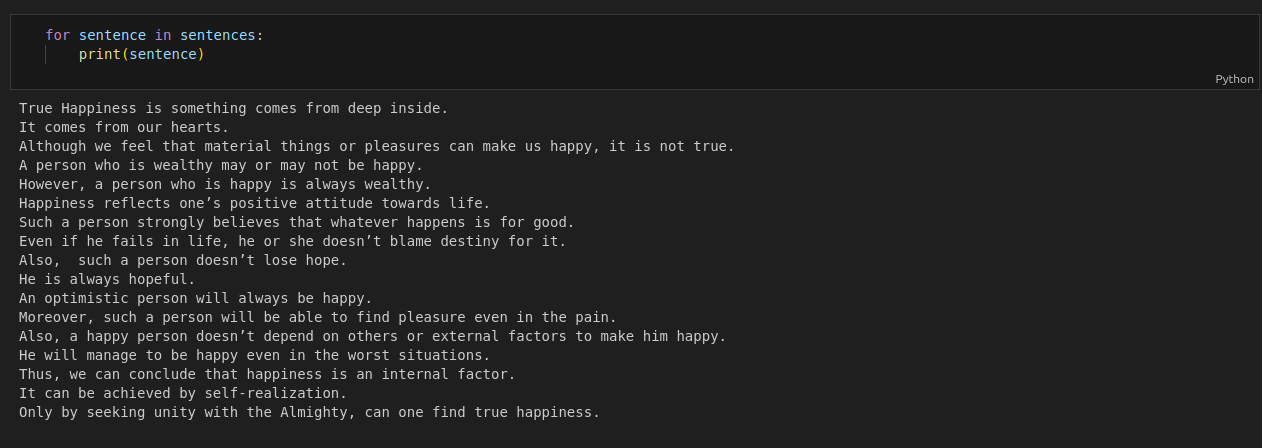
sentences=nltk.sent_tokenize(corpus)
This converts the corpus into a list of sentences
For Eg.
Word Tokenization
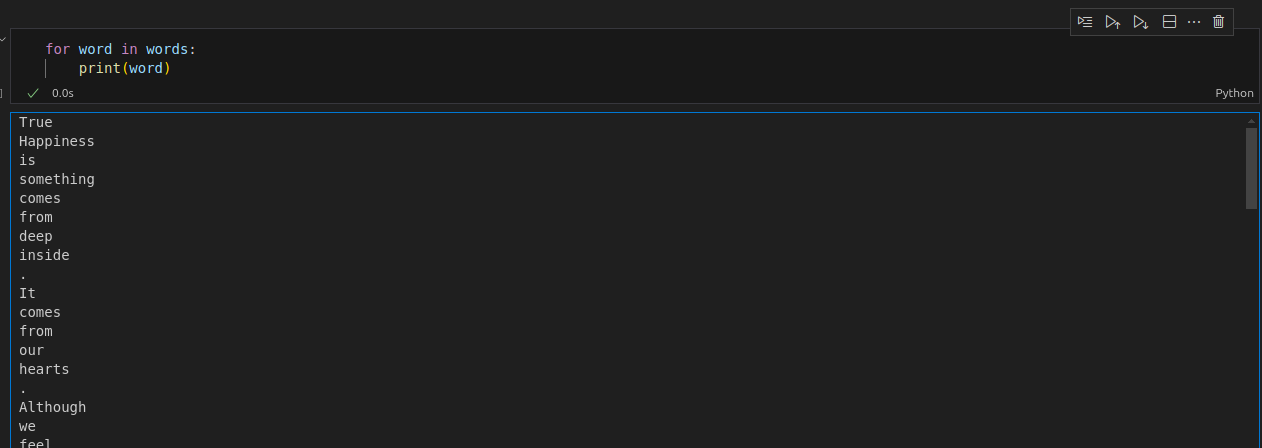
words=nltk.word_tokenize(corpus)
This will give a list of words inside of a corpus which is used as a token.
For eg.
Difference Between Word Tokenize and Word Punct Tokenize
Punctuation Handling: The
word_tokenizefunction is designed to be more intuitive when dealing with punctuation. It keeps punctuation with words when appropriate, such as in contractions. For example, in the phrase "don't worry,"word_tokenizewould produce the tokens ["do", "n't", "worry"], maintaining the contraction as a single unit. In contrast,wordpunct_tokenizetreats punctuation as separate tokens, so the same phrase would be tokenized into ["do", "n", "'", "t", "worry"], splitting the contraction into individual components.Complexity: The
word_tokenizefunction employs more sophisticated logic, incorporating rules for handling abbreviations, contractions, and other language nuances. For instance, it can correctly tokenize "Dr. Smith's office" into ["Dr.", "Smith", "'s", "office"], recognizing the abbreviation and possessive form. On the other hand,wordpunct_tokenizeis a simpler, rule-based tokenizer that focuses on breaking text into words and punctuation without such nuanced understanding. It would tokenize the same phrase into ["Dr", ".", "Smith", "'", "s", "office"], treating punctuation marks as separate tokens.
GIT Link: https://github.com/genvia-tech/generative_ai/blob/main/Tokenization/tokenization_lab.ipynb
Usecases
Machine Translation: Tokenization is crucial in breaking down sentences into manageable units for translation models, allowing for accurate and contextually appropriate translations between languages.
Sentiment Analysis: By tokenizing text into words or phrases, sentiment analysis models can identify and interpret emotions or opinions expressed in reviews, social media posts, or customer feedback.
Text Summarization: Tokenization helps in extracting key information from large documents, enabling models to generate concise summaries that capture the essence of the original text.
Chatbots and Virtual Assistants: Generative AI models use tokenization to understand and generate human-like responses, improving the interaction quality of chatbots and virtual assistants in customer service.
Content Creation: Generative AI can produce creative content such as articles, poetry, or music by learning from existing datasets, aiding writers, marketers, and artists in generating new ideas and content.
Image and Video Generation: Models trained on visual data can create realistic images or videos, which can be used in entertainment, advertising, or virtual reality applications.
Code Generation: Generative AI can assist developers by generating code snippets or entire programs based on natural language descriptions, streamlining the software development process.
Conclusion
In NLP, tokenization is a crucial process that breaks down text into smaller units called tokens, which can be words, subwords, or characters. This process helps in organizing and analyzing language data, making it easier for models to process and understand text. The article highlights the importance of tokenization in standardizing input, facilitating analysis, improving efficiency, handling language ambiguity, supporting NLP tasks, and enabling language modeling.
Different types of tokenization are discussed, including word, sentence, subword, and character tokenization. Practical examples using the Natural Language Toolkit (NLTK) in Python are provided to demonstrate sentence and word tokenization. The article also explains the differences between word_tokenize and wordpunct_tokenize functions, focusing on their handling of punctuation and complexity.
Subscribe to my newsletter
Read articles from genvia directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by