Serverless CSV Processing with AWS SAM: Lambda, S3, and DynamoDB Guide
 Othmane Kahtal
Othmane Kahtal
As part of my AWS Certified Developer Associate (DVA-C02) exam preparation, I've built a practical project to understand core AWS services better. This project demonstrates how to process CSV files using AWS SAM, Lambda, S3, and DynamoDB – all common topics in the certification exam.
Project Repository
You can find the complete source code for this project on GitHub: Import Clients' Data via CSV
Prerequisites:
Basic understanding of AWS Lambda and S3
AWS SAM CLI installed
Node.js knowledge
AWS account with appropriate permissions
Project Overview
This application automates the process of importing clients' data via CSV files. Here's what it does:
Accepts CSV file uploads to an S3 bucket
Triggers a Lambda function to process the file
Validates and stores the data in DynamoDB
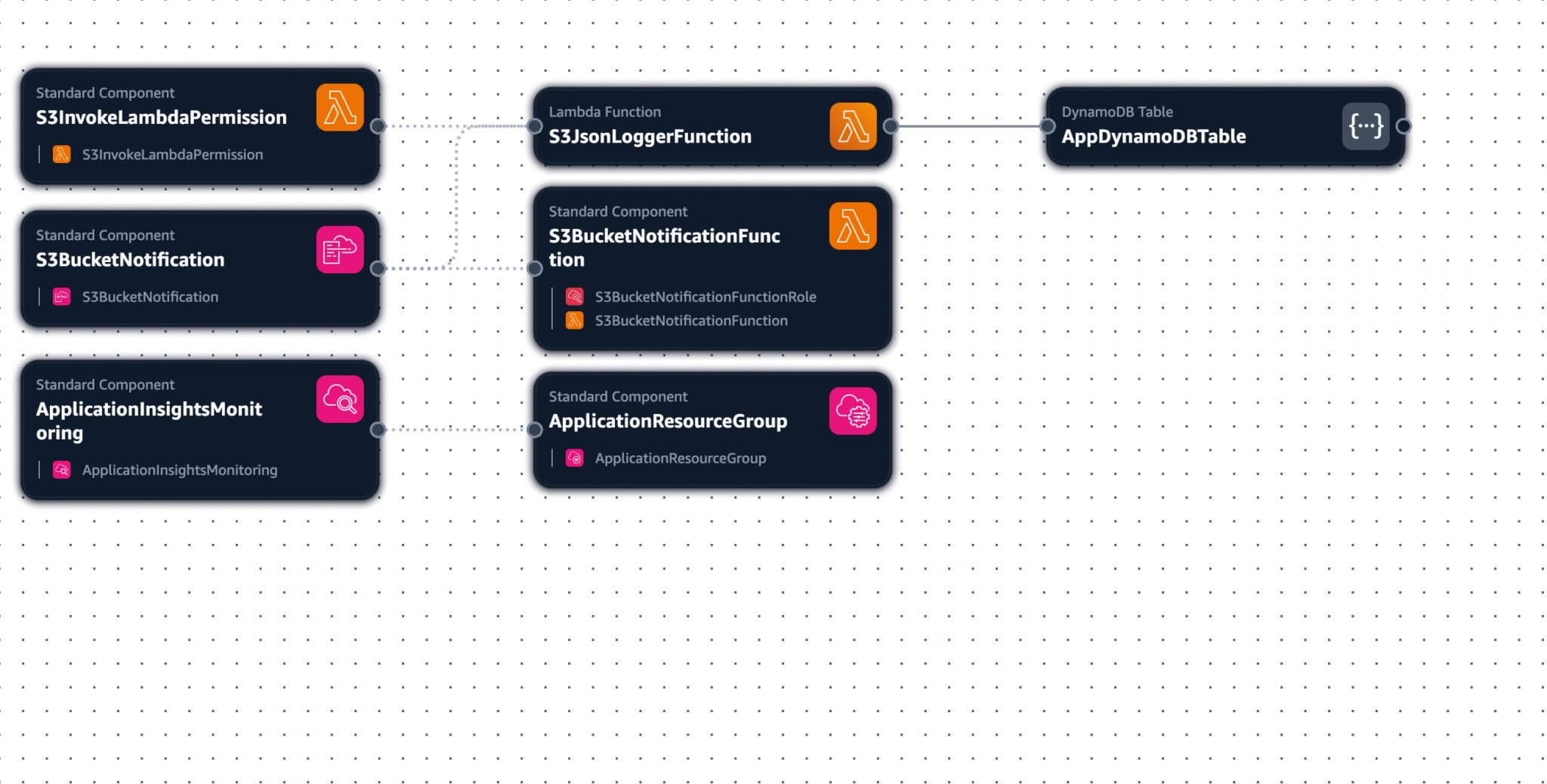
Implementation Details
SAM Template
Our infrastructure is defined using AWS SAM:
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Description: Lambda function with S3 and DynamoDB access
Parameters:
ExistingBucketName:
Type: String
Description: Name of the existing S3 bucket to use
Resources:
AppDynamoDBTable:
Type: AWS::Serverless::SimpleTable
Properties:
PrimaryKey:
Name: id
Type: String
ProvisionedThroughput:
ReadCapacityUnits: 5
WriteCapacityUnits: 5
S3JsonLoggerFunction:
Type: AWS::Serverless::Function
Properties:
Handler: src/handlers/s3-json-logger.s3JsonLoggerHandler
Runtime: nodejs18.x
Architectures:
- x86_64
MemorySize: 128
Timeout: 60
Policies:
- S3ReadPolicy:
BucketName: !Ref ExistingBucketName
- DynamoDBCrudPolicy:
TableName: !Ref AppDynamoDBTable
Environment:
Variables:
APPDYNAMODBTABLE_TABLE_NAME: !Ref AppDynamoDBTable
APPDYNAMODBTABLE_TABLE_ARN: !GetAtt AppDynamoDBTable.Arn
S3_BUCKET_NAME: !Ref ExistingBucketName
Lambda Function
The Lambda function processes CSV files and stores data in DynamoDB:
import { S3Client, GetObjectCommand } from "@aws-sdk/client-s3";
import { sdkStreamMixin } from "@aws-sdk/util-stream-node";
import { parseString } from "@fast-csv/parse";
import { DynamoDBClient } from "@aws-sdk/client-dynamodb";
import {
DynamoDBDocumentClient,
PutCommand,
} from "@aws-sdk/lib-dynamodb";
const tableName = process.env.APPDYNAMODBTABLE_TABLE_NAME;
const client = new DynamoDBClient({});
const dynamo = DynamoDBDocumentClient.from(client);
const s3 = new S3Client({});
export const s3JsonLoggerHandler = async (event, context) => {
const getObjectRequests = event.Records.map((record) => {
return processS3Object(
new GetObjectCommand({
Bucket: record.s3.bucket.name,
Key: record.s3.object.key,
})
);
});
await Promise.all(getObjectRequests);
};
// Data validation
const isValidClient = (record) => {
const { name, email, company, phone, id, status } = record;
return (
name &&
email &&
company &&
phone &&
id &&
status &&
/^[^\s@]+@[^\s@]+\.[^\s@]+$/.test(email)
);
};
// Process S3 objects
const processS3Object = async (object) => {
try {
const data = await s3.send(object);
const objectString = await sdkStreamMixin(data.Body).transformToString();
const records = await new Promise((resolve, reject) => {
const records = [];
parseString(objectString, { headers: true })
.on("error", (error) => {
console.error("Error parsing CSV:", error);
reject(error);
})
.on("data", async (row) => {
if (isValidClient(row)) {
records.push(row);
}
})
.on("end", (rowCount) => {
resolve(records);
});
});
const insertPromises = records.map(insertIntoDynamoDB);
return await Promise.all(insertPromises);
} catch (err) {
console.error("Error in processS3Object:", err);
throw err;
}
};
// Insert into DynamoDB
const insertIntoDynamoDB = async (record) => {
try {
const command = new PutCommand({
TableName: tableName,
Item: {
id: record.id,
name: record.name,
email: record.email,
company: record.company,
phone: record.phone,
status: record.status,
},
});
await dynamo.send(command);
} catch (err) {
console.error(`Error inserting client ${record.email}:`, err);
}
};
Smart Variable Usage: This project uses SAM parameters and environment variables instead of hard-coded values for S3 bucket names and DynamoDB configurations. This makes the application easy to maintain and deploy across different environments without code changes.
Event-Driven Architecture: The application uses S3 events to trigger Lambda functions automatically. This serverless approach enables efficient processing of multiple CSV files in parallel, improving performance for large data sets.
Data Validation: Before storing in DynamoDB, each record goes through validation checks for email format and required fields. This ensures data quality while properly handling and logging any invalid records.
CSV Format
Your CSV files should follow this structure:
id,name,email,company,phone,status
1,John Doe,john@example.com,Acme Inc,+1234567890,active
2,Jane Smith,jane@example.com,Tech Corp,+0987654321,pending
DVA-C02 Exam Topics Covered
This project helps understand several key exam topics:
SAM template structure and deployment
Lambda function development
S3 event notifications
DynamoDB operations
IAM roles and policies
Error handling patterns
Deployment
Deploy the application using SAM CLI (check the repository for the guide):
sam build
sam deploy --guided
Subscribe to my newsletter
Read articles from Othmane Kahtal directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Othmane Kahtal
Othmane Kahtal
Fullstack developer crafting elegant web solutions with React.js, TypeScript, graphQL, Node.js and AWS