Deciding When to Normalize or Denormalize Data for Best Results
 samhita sarkar
samhita sarkar
Normalisation and denormalisation are essentially design patterns in databases that determine how data is stored and used.
Storage pattern : The key difference between normalisation and denormalisation is their storage patterns, which are essentially opposite. Normalisation spreads the data across as many tables as possible, while denormalisation combines the data into one large table or a few tables where the data is merged.
Usage pattern : A normalised table structure is typically used in transactional systems(OLTP system i.e Online Transaction Processing) like banking or e-commerce to maintain high data integrity and reduce redundancy. This setup allows high-volume transactions to be performed with maximum efficiency.
A denormalised table structure is mainly used for search or analytical queries (OLAP systems, i.e., Online Analytical Processing). Analytical queries often need to join different data sets, and having data in a single table or fewer tables reduces the number of joins, which improves performance.
Lets understand how the storage and usage differs for each with an example.
Normalisation : Order-related information is stored in entity-specific tables, such as product and category tables. By storing data this way, data integrity is maintained. For example, if a product name changes in the future, it only needs to be updated in the product table.There is no data redundancy because order, product, and category information is stored only in their specific tables.
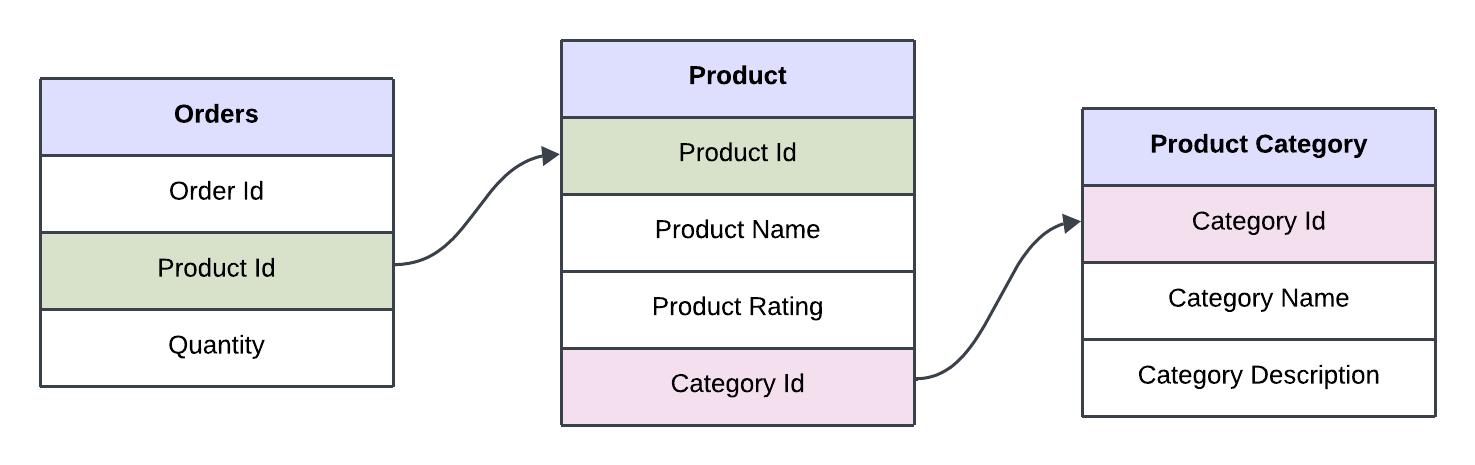
Denormalisation :
Some frequently used columns are often duplicated to make analytical queries faster and avoid joins. For example, the orders table stores both the product name and category ID, along with category details. This setup helps answer questions like "Which category sold the most?" only from the orders table without needing to join the product and category tables.
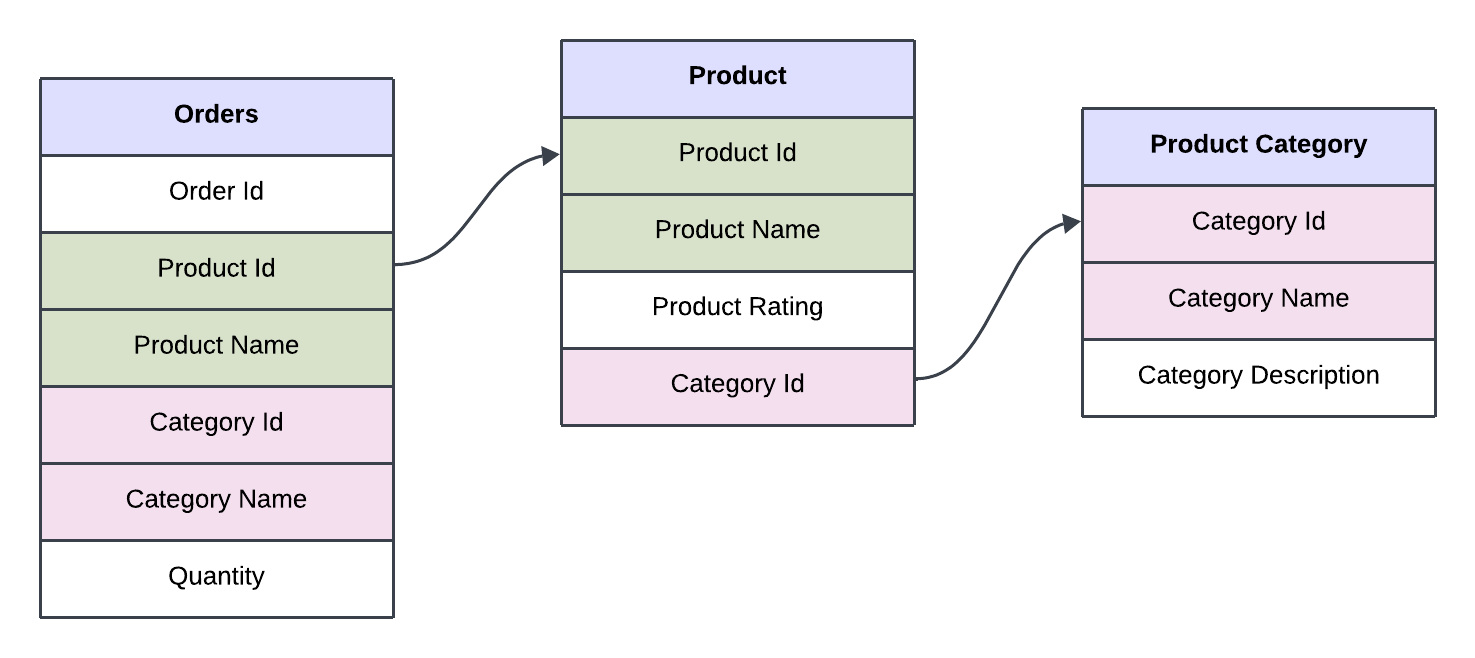
However, as shown above, this approach introduces some redundancy since the product name is stored in both the order table and the product table, and similarly, the category name is stored in both the order table and the category table. Additionally, if a product is ordered multiple times, the product name will be repeated multiple times in the orders table. If the product name changes in the future, it would need to be updated in all the rows in the orders table as well as in the product table.
Conclusion
Usually, a combination of normalisation and denormalisation approaches is used in organisations. In systems where data is generated, like OLTP systems, a normalised structure is used. In data warehouses, OLAP systems are used.
Subscribe to my newsletter
Read articles from samhita sarkar directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
samhita sarkar
samhita sarkar
Samhita is a Senior Data Engineer with a passion for extracting value from data.She has honed her skills in designing, developing, and maintaining robust data pipelines. She is proficient in a variety of data engineering tools and technologies, including Python, SQL, Snowflake,DBT, Big Data Analytics, Apache Spark, AWS, etc. Samhita has a proven track record of delivering innovative data solutions that drive business growth and improve decision-making. Samhita is skilled in data modelling, ETL processes, data warehousing, and data lake architectures having experience in working with Big data technologies and implementing data quality and security best practices. Beyond technical expertise, Samhita is a strong communicator and collaborator. She enjoys sharing knowledge and insights through her blog, where she discusses data engineering trends, challenges, and solutions.