What is a cloud asset inventory?
 Lars Kamp
Lars Kamp
Cloud-native infrastructure has brought a proliferation of cloud services—and cloud providers are adding more on an ongoing basis. Developers may have the permissions to start testing these new services without the knowledge of DevOps and security teams. That creates visibility gaps, a.k.a. “shadow IT,” which introduces new risks for security, compliance, and cost.
In this post, I’ll show how a cloud asset inventory (“cloud inventory”) addresses these new risks.
So, what exactly is a cloud inventory?
To understand what a cloud inventory is and how it works, I’ll start with definitions data collection and use cases.
Definitions
Let’s look into what defines a cloud asset and how a set of assets form a cloud inventory.
A cloud asset (or cloud resource) refers to any service that exists within a cloud computing environment. Examples of cloud assets include virtual machines, databases, storage buckets, serverless functions, container images, and lately also generative AI services.
Resource properties (or alternatively resource metadata) describe the configuration of a cloud resource. A cloud resource can come with dozens of “knobs and turns” to configure it. For example, an Amazon EC2 Instance comes with over 50 configuration options.
A cloud inventory is a catalog that tracks and manages information about all the cloud assets within an organization's cloud infrastructure.
A multi-cloud inventory is a catalog that tracks and manages cloud assets across more than one cloud service provider within a single system, regardless of the cloud where resources are hosted.
In short, a cloud inventory is a consolidated view that provides organizations an understanding of their entire cloud footprint.
In the old world of on-premises infrastructure, you may have heard the term “configuration management database” (CMDB). The purpose of a CMDB is to provide a single source of truth for a company’s IT assets. A cloud inventory is an evolution of the CMDB concept for a cloud-native world.
Data collection
The underlying resource metadata for a cloud inventory comes from cloud provider APIs. These are the same APIs that infrastructure-as-code (IaC) tools like Terraform or Pulumi use to provision, update, and destroy resources.
Polling these APIs allows us to extract a full set of configuration data for every resource. For example, Fix Security has collectors for AWS, Google Cloud, and Azure. In fact, our collectors are similar to an ETL (extract, transform, load) process which has been popularized with data integration and analytics. In cloud security, you’ll hear the term “agentless,” since legacy security tools use an agent to collect configuration data.
The downside of an agent is that it requires resource-specific instrumentation, usually with incomplete configuration data and support only for a limited number of resources. An agentless approach, on the other hand, ensures complete discovery of all resources and full coverage of configuration data.
Why do I need a cloud inventory?
Today’s cloud-native infrastructure behaves in a much different way than traditional, static on-premises infrastructure. It’s more dynamic due to three factors:
Expanding number of services. As the cloud providers launch new services, developers adopt and deploy these services. It’s not uncommon for any company to use dozens of different cloud services. The latest wave of additions by cloud providers is infrastructure to run generative AI services.
Decentralized control. Developers have lots of freedom to deploy services in their cloud accounts, without the knowledge of DevOps and security teams.
High frequency of change. Automated deployments through infrastructure-as-code means resources and their configurations change on a daily and sometimes even hourly basis.
In combination, these characteristics make it challenging to maintain visibility and control over the full scope of an organization's cloud footprint.
No inventory means you’re flying blind
Without a centralized cloud asset inventory, teams suffer from problems that affect governance, cost and security:
Shadow IT. It's difficult to know all the cloud resources in use across the organization. If you don’t know what’s running, you can’t manage it.
Unmanaged resources. Orphaned or abandoned resources aka “drift” can accumulate and drive up cloud costs.
Security risks. Unsecured or misconfigured resources expose the organization to breaches.
Compliance gaps. Losing track of regulated (data) assets can lead to compliance violations.
It’s actually remarkably hard to get a centralized view since resources tend to be distributed. It’s a good practice to separate and isolate workloads from each other for security, resilience and scalability reasons. But that also means that resources get deployed across different projects, accounts, regions and organizations. The distributed nature of cloud resources is the reason why we need to use a data integration approach.
Use cases and benefits
So assuming you now have a cloud inventory, what are some of its use cases and benefits? They are the solution to the problems of flying blind:
Security. Discover shadow IT and track the inventory for security risks and compliance violations to improve your security posture.
Compliance. Demonstrate control over regulated data assets and meet audit requirements.
Cost optimization. Identify abandoned or underutilized resources to reduce waste and cloud spend.
Infrastructure mapping. Visualizing dependencies between cloud assets for better understanding of the environment.
Change management. Tracking resource provisioning and modifications for auditing and troubleshooting.
One major additional benefit of a complete, centralized cloud inventory is that it puts engineering, platform and security teams on a common ground. By looking at the same data, it becomes easier to collaborate.
Cloud provider solutions
The cloud providers have developed their own inventory offerings. AWS has AWS Config, GCP has Google Cloud Asset Inventory, and Microsoft Azure has an asset inventory as part of Microsoft Defender, their cloud security posture management (CSPM) tool.
These products address some of the challenges, but also have their own drawbacks:
Incomplete coverage. It may seem ironic, but the cloud-native inventories don’t offer full coverage for their own product and services in all regions.
Unpredictable pricing. These inventories are not free, and can rack up significant charges based on usage and the changes in your infrastructure. In some cases, the per-resource-cost of the inventory can even be higher than the cost of the resource itself.
Limited functionality. The native inventories can be fairly monolithic in their use, with data model, search and integration constraints. Data model are fixed and can’t be customized, with restricted mapping between resources. Search is limited by the underlying query language (e.g. no full-text search), with restrictions on cross-account or cross-region queries. They don’t integrate well with external engineering tools, e.g. to integrate data back into your deployment pipelines.
No multi-cloud support. Each provider's inventory works within its own ecosystem, but not other clouds. That means you’re stuck with data silos when you’re running in a multi-cloud environment, and you’re not able to correlate and compare resources across clouds.
The native tools do get you somewhere. But the drawbacks are the reason why engineering and security teams look for third-party cloud asset inventory solutions when they need a unified, comprehensive view of their (multi-cloud) infrastructure.
A new approach for your cloud inventory
When we developed Fix, one of our goals was to build a cloud inventory that addresses the needs of DevOps and cloud security teams that work with cloud-native infrastructure.
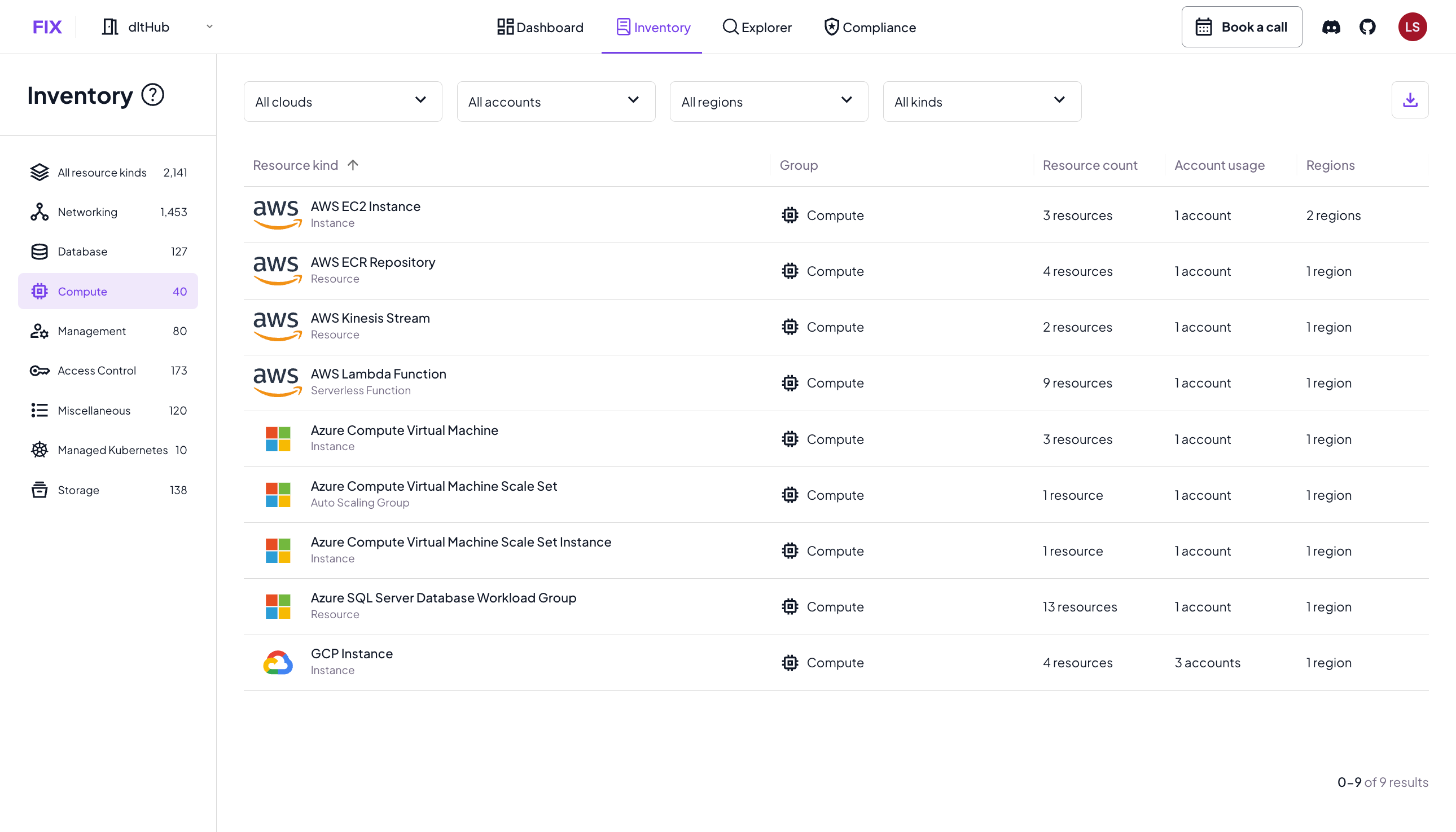
First off, we present your data in a fresh dashboard, with a single centralized view across all your cloud and resources. Our filters make it easy to narrow down your discovery by cloud, account, region and resource kind.
Second, we introduced common resource groups, such as “Database,” “Storage,” and “Managed Kubernetes.” These categories make it easier to find resources within a single cloud and across clouds, based on their category.
For example, in the screenshot below you can see all object storage buckets in a multi-cloud environment across AWS, GCP, and Azure—including a count, the number of accounts they’re running in, and the number of regions.
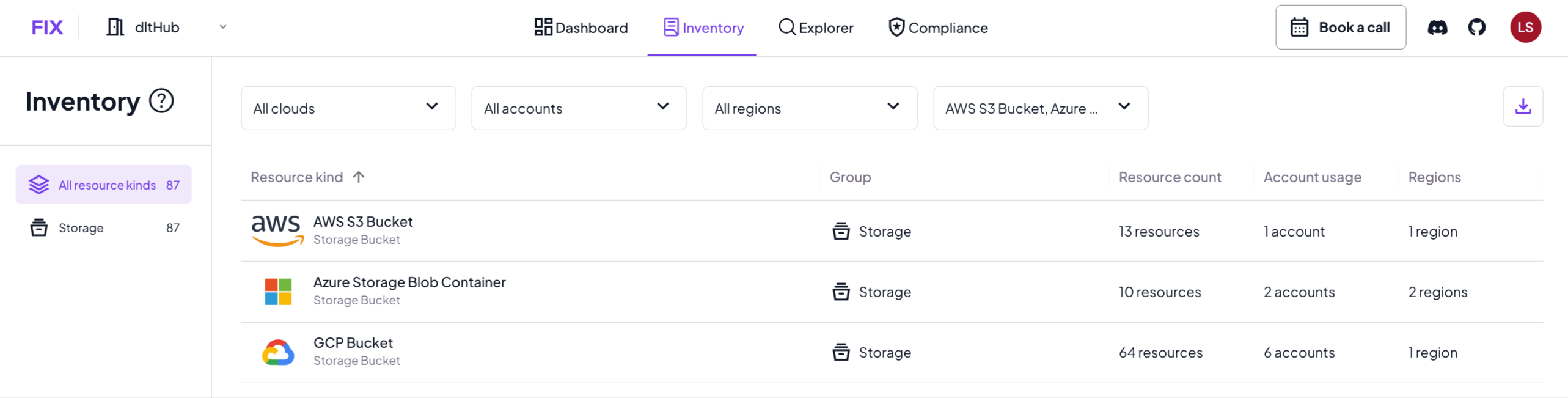
The inventory provides an aggregated view for each resource kind. If I wanted to investigate further and get a list of every individual bucket, and maybe understand their configurations, I can head over into the Explorer view to get a full list of all buckets.
Third, we’ve included short descriptors for every individual resource types across AWS, GCP and Azure, including links to their respective documentation.
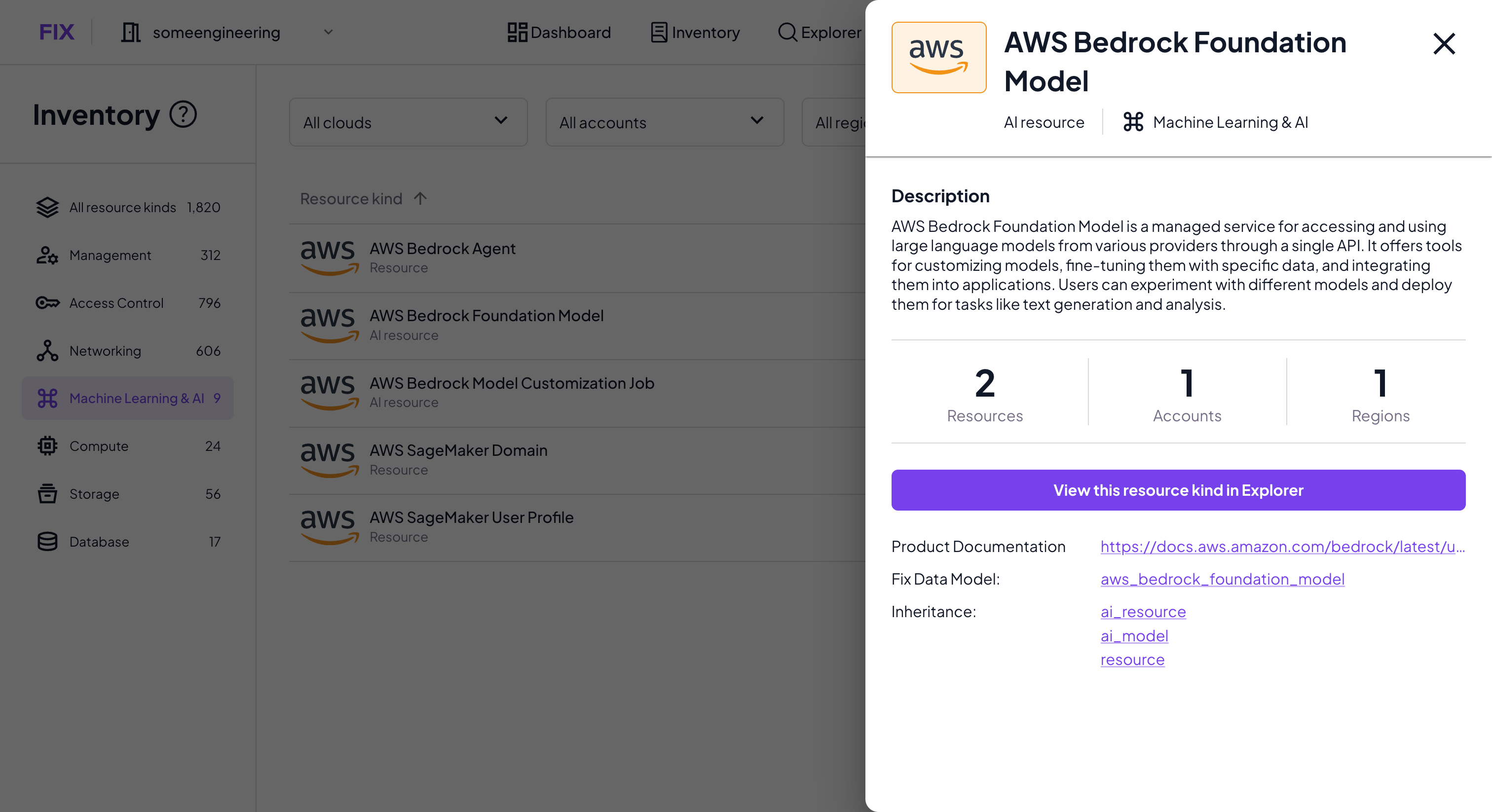
The Inventory tab groups resources by kind. If you want to see the individual resources, their configurations, context and change history, simply click “View this resource kind in Explorer” and you’ll get the full list and context of how each individual resource is connected within the context of your cloud inventory.
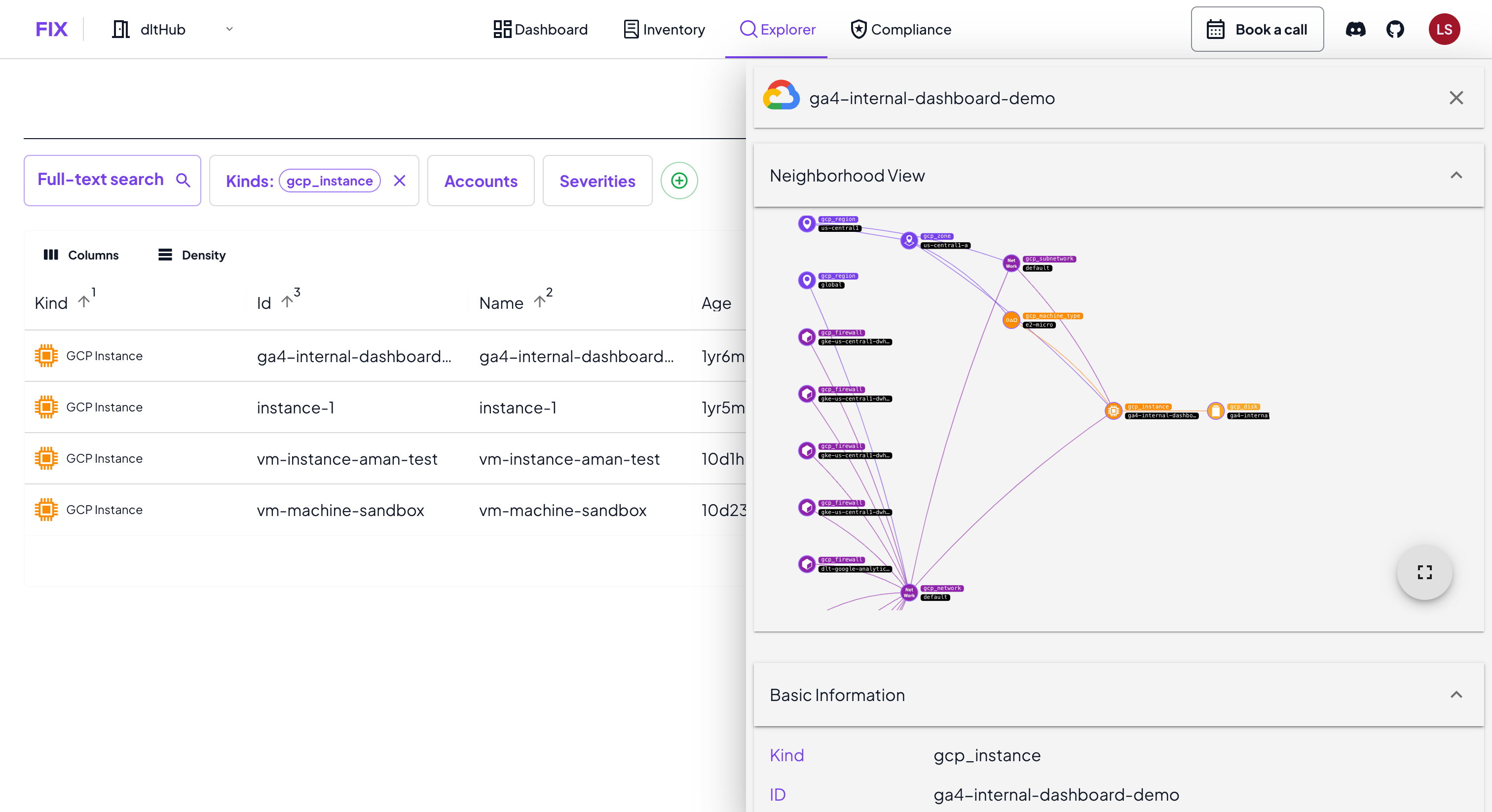
Finally, we also introduced support for machine learning & AI resources to create your AI inventory.
The magic behind our cloud inventory
We’ve done a little bit of magic behind the scenes to create this inventory and make life for cloud security and DevOps engineers easier.
Agentless data collection. With coverage for over 300 cloud services across AWS, GCP and Azure we offer broad visibility and control with a a true multi-cloud inventory. By default, Fix collects inventory every hour, so that you get 24 complete snapshots of your infrastructure every day, and scan your snapshot for misconfigurations and compliance violations.
Normalized data. With our unified data model for cloud resources, we’ve created a normalizing layer across clouds that transforms provider-specific formats into a single, standardized structure. In combination with our syntax, you can write consistent policies, queries and automations that work across AWS, GCP and Azure. In addition, we offer full-text search across all resource properties such as tags.
Relationships. With our inventory graph and its neighorbood view, you can see exactly how a resource is connected with other cloud services. Think of an AI model that sources data from an S3 bucket. Our access graph also shows you where users have overly permissive access rights.
Finally, all this data is not just available via our dashboard. With fixctl (“Fix Control”), you can integrate data directly into your workflows.
Summary
Our Inventory provides you with centralized visibility into the services that run in your cloud infrastructure, across AWS, Google Cloud, and Azure. With our unified data model, you have one consistent way to discover and catalog the resources in your cloud, and write a single set of searches and policies, regardless of cloud.
Our AI Inventory is now generally available to all users in your Fix Security dashboard. Head on over, or sign up for a free trial.
Subscribe to my newsletter
Read articles from Lars Kamp directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by