Top 5 Vector Databases & How to choose, optimize, implement Vector Databases for AI Apps
 Anix Lynch
Anix LynchTable of contents
- Traditional vs Vector Databases
- How a vector database workflow differs from SQL specifically with images, audio, text?
- Top 5 Vector Databases Overview
- Large Language Models (LLMs) Overview
- Common Vector Similarity Measures
- Full Workflow: Vector Databases and LLM Integration
- LangChain Workflow with Vector Databases and LLMs
- Pinecone Vector Database with LangChain Integration
- Choosing the Right Vector Database: Key Criteria and Recommendations
Traditional vs Vector Databases
1. Traditional vs. Vector Databases - Key Differences
Traditional Databases: Handle structured data (rows and columns) best, like in SQL databases.
Vector Databases: Specialize in unstructured data (images, text, audio), using vectors to store data in a format that enables fast, efficient similarity searches.
2. Limitations & Challenges of Traditional Databases
Limited in handling unstructured data.
Need additional tagging/metadata for complex data (e.g., images) which isn’t practical for similarity searches.
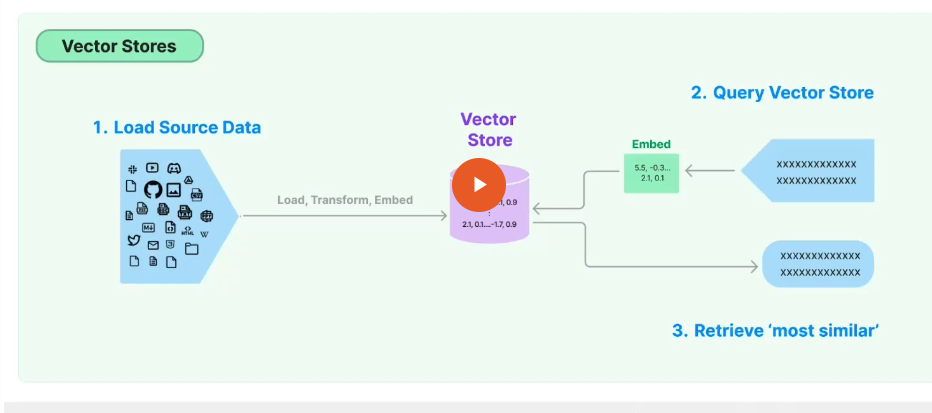
3. Vector Databases Workflow
Data Ingestion: Data (text, images) is split into smaller parts.
Embeddings Creation: Each part is converted into an embedding—a vector that encodes both content and meaning.
Indexing: Data is indexed using specialized algorithms for efficient retrieval.
Querying: Incoming queries are also vectorized, enabling the database to compare/query data based on similarity in vector space.
How a vector database workflow differs from SQL specifically with images, audio, text?
1. Data Structure
SQL: SQL databases are structured with tables, rows, and columns, making them ideal for well-defined, tabular data (like customer info, sales data).
Vector Database: Vector databases store unstructured data like text, images, or audio. This data is converted into vectors—mathematical representations in a high-dimensional space, rather than rows and columns.
Here’s what the vectors might look like:| Document ID | Content | Vector | | --- | --- | --- | | 1 | "Cats are great pets." |
[0.1, 0.25, 0.7, 0.9, 0.05, 0.3, 0.4, 0.2]| | 2 | "Dogs are loyal and friendly." |[0.2, 0.5, 0.6, 0.85, 0.1, 0.35, 0.45, 0.1]| | 3 | "I enjoy hiking in the mountains." |[0.05, 0.15, 0.2, 0.3, 0.8, 0.7, 0.65, 0.9]|
Instead of traditional tables, vector databases might use a structure optimized for vector indexing and similarity search. Here’s what that looks like:
Document ID: A unique identifier for each document.
Vector: A list of floating-point numbers that represent the semantic meaning of the content.
Metadata: Additional information about the document, such as tags, timestamps, or source information.
[ { "document_id": 1, "vector": [0.1, 0.25, 0.7, 0.9, 0.05, 0.3, 0.4, 0.2], "metadata": {"type": "text", "tags": ["animals", "cats"]} }, { "document_id": 2, "vector": [0.2, 0.5, 0.6, 0.85, 0.1, 0.35, 0.45, 0.1], "metadata": {"type": "text", "tags": ["animals", "dogs"]} }, { "document_id": 3, "vector": [0.05, 0.15, 0.2, 0.3, 0.8, 0.7, 0.65, 0.9], "metadata": {"type": "text", "tags": ["outdoors", "hiking"]} } ]Visualization in High-dimensional Space
If we plotted these vectors in high-dimensional space, similar vectors would be closer together. For instance:
The vectors for documents 1 and 2 (related to animals) would be closer in vector space.
Document 3, which talks about hiking, would be farther away from the others.
What This Looks Like in Practice
In a vector database like Pinecone or Chroma:
Data Ingestion: Data is uploaded and converted to vectors.
Indexing: Specialized algorithms (like Approximate Nearest Neighbors) index the vectors for efficient search.
Querying: When you search for similar content, the database compares vectors to retrieve relevant results.
2. Data Ingestion and Preparation
SQL: Data is inserted row by row, usually pre-structured (name, age, ID, etc.). The data is typically not split into parts; it’s stored as it is.
Vector Database: Data (text, images, etc.) is pre-processed and broken down into smaller segments (e.g., sentences, paragraphs). Each segment is then transformed into an embedding—a vector that captures both the content and meaning.
Here's a side-by-side comparison of data ingestion for SQL and a vector database (we'll use a basic Python example for both):
SQL Ingestion Sample
In SQL, you typically insert structured data (like rows in a table) directly:
-- SQL: Insert structured data CREATE TABLE animals ( id INT PRIMARY KEY, name VARCHAR(50), description TEXT ); -- Insert rows into SQL table INSERT INTO animals (id, name, description) VALUES (1, 'dog', 'Loyal and friendly'), (2, 'cat', 'Independent and curious');Explanation: SQL stores data in structured rows and columns. Each entry (like
nameanddescription) is a defined attribute in a table.Vector Database Ingestion Sample
In a vector database, the process usually involves:
Breaking data (e.g., sentences or images) into segments.
Converting each segment into an embedding (vector).
Storing the vectorized data in the database.
Here’s a Python example using a vector database client (like Pinecone) with embeddings:
# Import necessary libraries
from sentence_transformers import SentenceTransformer
import pinecone # Initialize your vector database client
# Initialize Pinecone and an embedding model
pinecone.init(api_key='YOUR_API_KEY', environment='YOUR_ENV')
index = pinecone.Index("animal-descriptions")
# Create an embedding model (e.g., sentence transformer)
model = SentenceTransformer('all-MiniLM-L6-v2')
# Text data to ingest
data = [
{"id": "1", "name": "dog", "description": "Loyal and friendly"},
{"id": "2", "name": "cat", "description": "Independent and curious"}
]
# Convert each description into an embedding and upsert into Pinecone
for item in data:
vector = model.encode(item['description']).tolist() # Create the vector
index.upsert([(item["id"], vector, {"name": item["name"], "description": item["description"]})])
Explanation: In vector databases:
Data like descriptions is broken into segments or directly embedded.
Each segment (e.g., "Loyal and friendly") is transformed into a vector.
The vector, along with metadata (like
name), is stored in the vector database for similarity-based querying.
Key Differences
SQL: Stores pre-structured data directly in rows and columns.
Vector Database: Breaks data down, converts it to vectors (embeddings), and stores vectors for efficient similarity-based retrieval.
3. Embeddings Creation (Vectorization)
SQL: SQL databases don’t require embeddings since data is stored as-is in text or numerical form.
-- No embedding creation needed; data is stored as plain text or numerical values INSERT INTO pets (id, type, description) VALUES (1, 'dog', 'Our dog is very friendly and playful');Output:
Data stored as: | id | type | description | |----|------|-------------------------------------| | 1 | dog | Our dog is very friendly and playful |
Vector Database: The database creates a vector (or embedding) for each data segment, which encodes the meaning of that segment in a way that can be mathematically compared. This is crucial for handling unstructured data, as the vector captures semantic content, like the context of a sentence or image.
from sentence_transformers import SentenceTransformer
# Initialize model for creating embeddings
model = SentenceTransformer('all-MiniLM-L6-v2')
# Example data
text = "Our dog is very friendly and playful"
# Generate the embedding vector
embedding_vector = model.encode(text).tolist()
# Example output vector: [0.23, -0.11, 0.75, ...] — a vector encoding the meaning of the text
Output:
Embedding vector created:
[0.23, -0.11, 0.75, ...]
4. Indexing for Retrieval
SQL: SQL databases use indexes (e.g., B-trees, hash indexes) to speed up data retrieval based on exact matches or range-based queries (e.g., "find all type of dog").
-- Creating an index for faster retrieval on a specific column, like `type` CREATE INDEX idx_type ON pets (type);Output:
Index created on `type` column, speeding up queries for specific types like 'dog'.Vector Database:
Vector databases use similarity-based indexing techniques, like Approximate Nearest Neighbor (ANN) algorithms, which allow for finding similar data points (embeddings) rather than exact matches. This is essential for use cases where we need to retrieve data based on similarity rather than exact equality (e.g., retrieving articles similar in theme).
import pinecone # Initialize Pinecone or another vector database pinecone.init(api_key="YOUR_API_KEY", environment="us-west1-gcp") # Create an index in the vector database index = pinecone.Index("pets") # Upsert the embedding vector with metadata index.upsert(items=[("1", embedding_vector, {"type": "dog", "description": text})])Output
Index created and embedding vector upserted: - ID: 1 - Embedding: [0.23, -0.11, 0.75, ...] - Metadata: {"type": "dog", "description": "Our dog is very friendly and playful"}
5. Querying
SQL: Queries in SQL are exact or range-based, like SELECT * FROM pets WHERE type = 'dog'. SQL uses predefined columns and rows to match specific values.
-- Retrieve exact or range-based matches, such as finding all "dog" entries SELECT * FROM pets WHERE type = 'dog';| id | type | description | |----|------|-------------------------------------| | 1 | dog | Our dog is very friendly and playful |Vector Database: Queries are converted into vectors and compared against existing embeddings using similarity measures (e.g., cosine similarity). Instead of exact matches, it retrieves data based on closeness or similarity to the query in vector space, which is particularly useful for search, recommendation, and NLP tasks.
# Query the vector database for vectors similar to the query "friendly dog" query_text = "friendly dog" query_vector = model.encode(query_text).tolist() # Find the top 3 most similar entries results = index.query(query_vector, top_k=3, include_metadata=True)Output
[ { "id": "1", "score": 0.98, "metadata": {"type": "dog", "description": "Our dog is very friendly and playful"} }, { "id": "2", "score": 0.89, "metadata": {"type": "dog", "description": "A friendly dog wagged its tail"} }, { "id": "3", "score": 0.85, "metadata": {"type": "dog", "description": "Dogs are loyal and loving"} } ]
6. Use Cases
SQL: Ideal for structured data, transactions, reporting, and relational operations (e.g., financial records, inventory).
Vector Database: Suitable for unstructured data and tasks like semantic search, recommendations, image retrieval, and NLP where understanding the "meaning" is critical.
In short, the main difference lies in the approach to data representation and retrieval. SQL databases are built around structured, relational data, whereas vector databases enable the storage and retrieval of unstructured data by relying on the relationships between meanings represented in vector form.
This ability to retrieve "similar" data, rather than exact matches, makes vector databases especially valuable for applications involving natural language, images, and other types of content where semantic relationships are key.
4. Embeddings vs. Vectors - Key Differences
Vectors: Raw numerical representations (e.g.,
[30, 60]for weight and height).# A simple vector representing a dog's weight (in kg) and height (in cm) dog_vector = [30, 60] # weight: 30kg, height: 60cmoutput
dog_vector = [30, 60]Embeddings: Not straigh forward number. Capture vague complex meaning and context, enabling similarity searches (e.g.,
[0.12, -0.45, 0.67, ...]for "friendly and playful" sentiment).from sentence_transformers import SentenceTransformer # Model for creating embeddings model = SentenceTransformer('all-MiniLM-L6-v2') # Example sentence about a dog dog_description = "Our dog is friendly and playful" # Generate the embedding dog_embedding = model.encode(dog_description).tolist()output
dog_embedding = [0.12, -0.45, 0.67, ...]
5. How Vector Databases Work and Their Advantages
Convert unstructured data into vector embeddings for efficient querying.
Use indexing to enable fast, scalable similarity searches.
Optimize storage and retrieval of complex, multi-dimensional data.
6. Use Cases for Vector Databases
Image Retrieval: E-commerce platforms use visual similarity for products.
Recommendation Systems: Streaming platforms recommend similar songs or movies based on user history.
NLP & Chatbots: AI support bots retrieve and respond based on semantic similarities.
Fraud Detection: Compare user behavior vectors for anomaly detection.
Bioinformatics: Compare genetic data for research or diagnostics.
Top 5 Vector Databases Overview
Pinecone
Type: Managed service
Key Features: Real-time vector indexing, high consistency, and reliability in search.
Strength: Simple API integration, making it ideal for fast development of AI applications.
Milvus
Type: Open-source
Key Features: Supports both CPU and GPU, customizable with multiple indexing options.
Strength: Suitable for high-performance similarity searches, especially in enterprise applications.
FAISS (Facebook AI Similarity Search)
Type: Open-source by Facebook
Key Features: Optimized for clustering and nearest-neighbor searches in high-dimensional spaces.
Strength: Best for AI/deep learning applications, specifically optimized for GPU-based searches.
Weaviate
Type: Open-source
Key Features: Supports GraphQL, RESTful APIs, and automatic vectorization with machine learning models.
Strength: Modular infrastructure that supports AI-driven tasks like semantic search and object recognition.
Chroma
Type: Open-source and AI-native
Key Features: Stores embeddings and metadata, integrates easily with LLMs.
Strength: High performance and scalability, simple setup ideal for developers building LLM-driven applications.
Bonus: Annoy (Approximate Nearest Neighbors Oh Yeah)
Type: Lightweight, open-source
Key Features: Focuses on speed and memory efficiency, ideal for applications with limited computational resources.
Large Language Models (LLMs) Overview
Definition: LLMs are algorithms trained on large datasets of text to generate human-like responses. They understand and respond in natural language.
Key Training Process:
Data Collection: Training on a vast range of data (text, sometimes images).
Unsupervised Learning: Initial learning of relationships between words and concepts.
Fine-Tuning: Final supervised learning, refining understanding for specific tasks.
Core Technology: Transformers - a neural network architecture using a self-attention mechanism to understand relationships and context in language.
LLMs in Action
Capabilities: Text generation, translation, sentiment analysis, content organization, summarization, and chatbot creation.
Popular LLMs: GPT (3.5, 4, etc.), LLaMA, BLOOM, FLAN-UL2, and others.
Key Takeaways
Vector Databases: Essential for handling unstructured data, enabling fast similarity searches. Suitable for applications in image retrieval, recommendation systems, NLP, fraud detection, etc.
LLMs: Offer powerful capabilities in natural language understanding and generation, supported by transformer technology.
Common Vector Similarity Measures
Vector similarity measures help in determining how close or aligned two vectors are in a vector space, which is essential for tasks like similarity search in vector databases. Here are the three main measures and their best use cases:
Cosine Similarity
Definition: Measures the angle between two vectors, focusing on direction, not magnitude.
Formula: \(\text{cosine similarity} = \frac{\text{A} \cdot \text{B}}{||\text{A}|| \times ||\text{B}||}\)
Interpretation: Value close to 1 means vectors point in similar directions; 0 means perpendicular; -1 means opposite directions.
Best Use Cases: Topic modeling, document similarity, collaborative filtering.
Euclidean Distance (L2 Norm)
Definition: Measures the straight-line distance between two points in space, accounting for magnitude.
Formula: \({Euclidean distance} = \sqrt{(x_2 - x_1)^2 + (y_2 - y_1)^2 + \ldots}\)
Interpretation: Smaller distance means vectors are closer together, larger distance means they are farther apart.
Best Use Cases: Clustering analysis, anomaly detection, fraud detection.
Dot Product
Definition: Measures how much two vectors are pointing in the same direction, emphasizing both magnitude and direction.
Formula: \({dot product} = x_1 \cdot x_2 + y_1 \cdot y_2 + \ldots)\)
Interpretation: Positive value means vectors point in the same general direction; 0 means they are perpendicular; negative means opposite.
Best Use Cases: Image retrieval and matching, neural networks, deep learning, music recommendation.
Section Summary
Cosine Similarity is ideal when direction matters more than distance, commonly used in text similarity.
Euclidean Distance is used when both direction and magnitude are essential, effective for clustering and detecting anomalies.
Dot Product is favored in applications like recommendation systems and deep learning where direction and strength of alignment both matter.
These measures are widely used in vector databases to efficiently find and rank similar data points based on the specific needs of the application.
Here's a full workflow summary for integrating vector databases with large language models (LLMs), specifically using Chroma DB and OpenAI’s API.
Full Workflow: Vector Databases and LLM Integration
Loading Documents
- Start by loading all documents from a directory. Each document (e.g., a
.txtfile) is read and prepared for embedding.
- Start by loading all documents from a directory. Each document (e.g., a
Splitting and Preprocessing
Chunking: Large documents are split into smaller, manageable chunks.
Overlap: Each chunk includes some overlapping text to retain context across chunks.
Generating Embeddings
Embedding Function: Use a model (e.g.,
OpenAI’s text-embedding-ada-002) to generate embeddings for each chunk.Storage: These embeddings are stored in Chroma DB, each associated with the original text chunk for retrieval.
Query Processing
User Query: When a query is inputted, it is embedded similarly to the document chunks.
Indexing: Chroma DB indexes the embedded query to perform efficient similarity search.
Search and Retrieval: The database retrieves the most relevant document chunks based on the similarity of embeddings.
LLM Response Generation
Context Preparation: The retrieved chunks serve as context for the query.
Prompt Design: A custom prompt is crafted, e.g., “Use the retrieved information to answer concisely.”
Answering: The context and user question are passed to an LLM (e.g.,
GPT-3.5 Turbo), which generates a coherent response based on the content of the documents.
Deep Dive: Key Concepts
Vector Similarity Search: The vector database finds closest matches based on embedding similarity, enabling precise information retrieval.
Embedding Persistence: Storing embeddings within a vector database (e.g., Chroma) ensures efficient querying and retrieval.
LLM Augmentation: By integrating with an LLM, the workflow enhances answers by producing more comprehensive, context-aware responses than simple retrieval.
Example Workflow in Code Steps
Load and Prepare Data
documents = load_documents("data/articles/") chunks = split_text(documents, chunk_size=1000, overlap=20)Generate and Store Embeddings
embeddings = [generate_embedding(chunk) for chunk in chunks] store_embeddings_in_chroma(embeddings)Process Query and Retrieve Similar Chunks
query_embedding = generate_embedding("Your question here") relevant_chunks = query_chroma_db(query_embedding)Generate Final Response Using LLM
final_response = generate_llm_response(query="Your question here", context=relevant_chunks) print(final_response)
Section Summary
Purpose: This workflow supports advanced querying by combining vector-based retrieval with the interpretative power of LLMs.
Use Case: Ideal for document-based chatbots, research assistants, or any application requiring contextual, intelligent answers from large document collections.
This integration of vector databases and LLMs enhances the quality and relevance of responses, especially for applications dealing with extensive and unstructured data.
LangChain Workflow with Vector Databases and LLMs
LangChain is a powerful framework for building AI applications that integrates seamlessly with large language models (LLMs) and vector databases. This process streamlines embedding creation, document retrieval, and response generation, all through minimal code. Here’s a high-level breakdown:
Workflow Overview
Loading Documents
- LangChain's
DirectoryLoaderloads multiple documents (e.g.,.txtfiles) quickly without custom code.
- LangChain's
Splitting Text
- Text Splitters: LangChain’s
RecursiveCharacterTextSplitterchunks documents into smaller, manageable pieces with overlapping text for context preservation.
- Text Splitters: LangChain’s
Generating Embeddings
- Embedding Models: Using
OpenAIEmbeddings, embeddings are created and associated with document chunks, which is essential for similarity search.
- Embedding Models: Using
Creating a Vector Database
- Chroma Integration: LangChain wraps the
Chromadatabase, storing the document embeddings in a vector database. The database is persisted for quick future access.
- Chroma Integration: LangChain wraps the
Retrieving Relevant Chunks with a Query
- Retriever: A retriever object queries the vector database to find the most relevant chunks based on the user query, returning chunks with metadata such as document source.
Using an LLM for the Final Response
Prompt Creation: A system prompt provides context to the LLM (e.g., instructing it to answer concisely).
LLM Response: The retrieved chunks are passed along with the user query to the LLM (like GPT-3.5 Turbo), which generates a coherent, context-based answer.
Quick Example Code (with LangChain)
# Import necessary components
from langchain.document_loaders import DirectoryLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.retriever import VectorStoreRetriever
from langchain.prompts import SystemMessagePromptTemplate
from langchain.llms import OpenAI
from langchain.chains import ChatCompletion
# Step 1: Load Documents
loader = DirectoryLoader("data/articles", glob="*.txt")
documents = loader.load()
# Step 2: Split Documents
splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=20)
split_docs = splitter.split_documents(documents)
# Step 3: Generate Embeddings
embeddings = OpenAIEmbeddings(model="text-embedding-ada-002")
# Step 4: Create Vector Database with Chroma
db = Chroma.from_documents(split_docs, embeddings, persist_directory="chroma_db")
# Step 5: Create Retriever
retriever = db.as_retriever()
# Step 6: Generate Response using LLM
llm = OpenAI(api_key="YOUR_API_KEY")
query = "Tell me about recent AI acquisitions."
retrieved_docs = retriever.retrieve(query)
# System prompt for LLM
system_prompt = SystemMessagePromptTemplate(content="Answer concisely based on the provided context.")
completion_chain = ChatCompletion.from_messages([system_prompt, query], model=llm)
# Get Answer
answer = completion_chain.run()
print(answer)
Section Summary
LangChain as a Wrapper: LangChain simplifies the integration of LLMs with vector databases by providing streamlined, high-level functions.
End-to-End Workflow: Loading, chunking, embedding, storing, querying, and generating responses are all handled efficiently, allowing for quick setup of complex workflows.
Benefits: Faster development, reduced code, and flexibility in switching components like vector stores or LLMs make LangChain ideal for building AI applications that leverage vector similarity and advanced query responses.
LangChain is a comprehensive tool for developing sophisticated AI applications, enabling quick prototyping and deployment of solutions that require LLM integration with vector databases.
Pinecone Vector Database with LangChain Integration
Here's a structured workflow to get started with Pinecone, from account setup to performing similarity search with LangChain. This example also explores creating, upserting, querying, and cleaning up the Pinecone database.
Step 1: Set Up Pinecone
Create an Account on Pinecone
Visit Pinecone and sign up for a free account.
In the dashboard, locate your API Key and Environment under the default project.
Install Pinecone Client
pip install pinecone-clientInitialize Pinecone Client in Python
import pinecone from dotenv import load_dotenv import os load_dotenv() API_KEY = os.getenv("PINECONE_API_KEY") ENV = "us-east-1" # Your Pinecone environment pinecone.init(api_key=API_KEY, environment=ENV)
Step 2: Create a Pinecone Index
index_name = "quickstart-index"
dimension = 8 # Replace with actual dimension of your vectors
# Create index if not exists
if index_name not in pinecone.list_indexes():
pinecone.create_index(name=index_name, dimension=dimension, metric="cosine")
index = pinecone.Index(index_name)
Step 3: Upsert Data into Pinecone
# Example vectors with metadata
vectors = [
{"id": "vec1", "values": [0.1, 0.2, 0.3, ...], "metadata": {"genre": "drama"}},
{"id": "vec2", "values": [0.2, 0.3, 0.4, ...], "metadata": {"genre": "action"}}
]
# Upsert data
index.upsert(vectors=vectors)
Step 4: Query Pinecone Index
# Query with metadata filtering
query_vector = [0.1, 0.2, 0.3, ...]
response = index.query(vector=query_vector, top_k=2, filter={"genre": "action"})
print(response)
Step 5: Use LangChain’s Pinecone Wrapper for Integration
Install LangChain and Pinecone Extensions
pip install langchain pinecone-clientLoad Documents and Create Embeddings with LangChain
from langchain.document_loaders import DirectoryLoader
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Pinecone
# Load documents
loader = DirectoryLoader("data/articles", glob="*.txt")
documents = loader.load()
# Create embeddings
embeddings = OpenAIEmbeddings(api_key=API_KEY)
doc_search = Pinecone.from_documents(documents, embeddings, index_name=index_name)
- Perform Similarity Search
query = "Tell me about recent AI advancements."
retriever = doc_search.as_retriever()
results = retriever.retrieve(query)
print(results)
Step 6: Retrieve and Chain with LLM for Final Response
from langchain.prompts import SystemMessagePromptTemplate
from langchain.llms import OpenAI
from langchain.chains import ChatCompletion
# Set up LLM
llm = OpenAI(api_key=API_KEY)
# Define system prompt
system_prompt = SystemMessagePromptTemplate(content="Answer concisely based on the provided context.")
chain = ChatCompletion.from_messages([system_prompt, query], model=llm)
# Get the answer
response = chain.run()
print(response)
Step 7: Clean Up - Delete Pinecone Index
pinecone.delete_index(index_name)
Summary
This workflow shows how Pinecone offers managed services for vector storage and retrieval, simplifying large-scale, real-time indexing and query processing. Using LangChain's wrappers further enhances integration with LLMs, streamlining document loading, embedding, and response generation in fewer lines of code.
Challenge
Explore other vector databases such as FAISS, Milvus, and Weaviate to understand their unique capabilities and limitations.
Choosing the Right Vector Database: Key Criteria and Recommendations
Selecting the right vector database depends on multiple factors that align with your specific project needs and infrastructure. Here’s a comprehensive guide on evaluating and choosing the best vector database for your use case, including a comparison of popular options.
1. Deployment Options
| Database | Local Deployment | Self-Hosted Cloud | Managed Cloud | On-Premises |
| Pinecone | ❌ | ❌ | ✅ | ❌ |
| Milvus | ✅ | ✅ | ❌ | ✅ |
| Chroma | ✅ | ✅ | ✅ | ✅ |
| Weaviate | ✅ | ✅ | ✅ | ✅ |
| FAISS | ✅ | ❌ | ❌ | ❌ |
Recommendation: If your organization requires a cloud-managed, scalable solution with minimal maintenance, Pinecone or Weaviate may be preferable. For on-premises or local deployments, Chroma or Milvus could be a better choice.
2. Integration & API Support
| Database | Language SDKs | REST API | GRPC API |
| Pinecone | Python, Node.js, Go | ✅ | ✅ |
| Milvus | Python, Java, Go, C++ | ✅ | ✅ |
| Chroma | Python | ✅ | ❌ |
| Weaviate | Python, Java, .NET, JS | ✅ | ✅ |
| FAISS | C++, Python | ❌ | ✅ |
Recommendation: If language flexibility is critical, Weaviate and Milvus offer the broadest SDK support across Python, Java, and .NET. For projects needing REST and GRPC APIs, Pinecone or Milvus may be more appropriate.
3. Community & Open Source Support
| Database | Open Source | Community | Framework Integration |
| Pinecone | ❌ | Medium | ✅ |
| Milvus | ✅ | Strong | ✅ |
| Chroma | ✅ | Growing | ✅ |
| Weaviate | ✅ | Strong | ✅ |
| FAISS | ✅ | Limited | ✅ |
Recommendation: For open-source projects and community-driven development, Milvus, Weaviate, and Chroma are recommended due to their open-source nature and strong community support. Pinecone is managed and not open-source, which may limit customization but is beneficial for maintenance.
4. Pricing & Budget Considerations
| Database | Free Tier | Pay-As-You-Go | Enterprise Plans |
| Pinecone | ✅ | ✅ | ✅ |
| Milvus | ✅ | ❌ | ❌ |
| Chroma | ✅ | ❌ | ❌ |
| Weaviate | ✅ | ❌ | ✅ |
| FAISS | ✅ | ❌ | ❌ |
Recommendation: Pinecone and Weaviate offer more structured pricing options suitable for enterprise needs, including pay-as-you-go and enterprise plans. For budget-friendly, free-tier solutions, Milvus or Chroma can be excellent choices.
5. Core Evaluation Criteria
To select the best fit, assess the following key requirements:
Project Requirements:
Scalability: Choose a scalable solution like Pinecone or Weaviate for handling increasing data volumes.
Performance Needs: For real-time response systems (e.g., recommendation engines), consider low-latency solutions like Pinecone.
Data Type & Volume:
- If handling unstructured data like text or images, opt for databases optimized for high-dimensional embeddings (e.g., Milvus, Chroma).
Ease of Use & Integration:
Developer-Friendly: Ensure the solution has strong SDK support and an intuitive API (e.g., Weaviate, Pinecone).
Community Support: Choose databases with active forums or open-source communities (e.g., Milvus, Weaviate, Chroma).
Feature Set:
- Look for databases with built-in support for embeddings, multiple similarity metrics (e.g., cosine, Euclidean), and support for customizability.
Cost & Infrastructure:
Budget Constraints: For cost-effective, smaller deployments, Chroma or FAISS may be suitable.
Enterprise Support: For larger teams needing extensive support and infrastructure, Pinecone or Weaviate might be preferable.
Security & Compliance:
- Ensure the database aligns with security and compliance needs, particularly in regulated industries (e.g., Pinecone offers managed security, which may be preferable for highly sensitive data).
Final Recommendations
Evaluate Project-Specific Needs:
- Create a shortlist based on deployment type, data volume, budget, and compliance needs.
Prototype & Test:
- Test shortlisted databases on a sample dataset to gauge performance, latency, and ease of integration.
Engage Community Feedback:
- Explore online forums and user groups for each database to understand real-world user experiences and potential limitations.
In Summary
By aligning database features with project requirements, you can ensure that the chosen vector database enhances the efficiency, scalability, and success of your AI applications. Testing with realistic data is vital to confirm the database will meet your expectations in production scenarios.
Subscribe to my newsletter
Read articles from Anix Lynch directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by