Knowing When Enough is Enough: Pull Request Sizing
 Tomasz Gil
Tomasz Gil
Deciding the right size for a change in software projects can be challenging. Is a larger change necessarily bad? How do you effectively decide when to stop working on a change? How do you break it down?
In this article, we explore the intricacies of pull request sizing, focusing on how to balance change size and scope to maintain momentum and reduce complexity.
You’re never done
In the world of software engineering, we’re never truly done. There’s always something to address. This applies at the system level, the feature level, and even to a single change introduced to a codebase. Here are a few scenarios that might sound familiar.
Maybe I’ll just go and implement this next bit as well…
Ugh, this looks ugly - this could use a little refactoring…
This lacks tests - let me add some while I’m at it…
These are all good instincts—I even wrote a blog post about this—instincts that, when shared by engineers working on a project, can significantly help maintain that project long-term. However, these instincts can also lead to a loss of focus, causing engineers to become sidetracked by improvements that, while beneficial, may not be immediately necessary and negatively impact the overall delivery.
At some point, we have to call it a day, let others review the change, and merge it. But is a longer change always bad?
Change size and change scope
First off, it’s good to clarify ways in which we can describe how large a change is. I really like the terms that the book "Software Engineering at Google" uses for that. The terms introduced are size and scope.
Change size is the quantifiable measure of code modifications, typically involving in metrics like lines of code changed or number of files modified.
Change scope refers to the broader impact and implications of a modification. It considers factors like the number of dependent systems affected, potential performance implications, security considerations, and the extent of testing required.
What to focus on
Both size and scope are important, but they are not the end goal. What we are ultimately trying to assess is the change complexity - and potentials risks related to it. Change size is simple to measure through tooling, so it’s easy to assume that this is equal to change complexity. Even though it can serve as some indicator, it can be widely misleading. To give a few examples:
A one-line change to a critical API could be small in size but have massive implications on the entire system.
Refactoring of documentation might involve many lines but carry minimal risk.
Running an automated change across dozens of files is large in size, but not complex or hard to review.
A small change that covers a few unrelated concerns makes it harder to thoroughly review the code.
Change complexity isn’t equal to change size—it is a combination of size and scope. What we want to aim for is reducing change complexity. By doing that, we gain several benefits.
Easier review - the review process is quicker and, because the change is more focused, it can be more accurate at the same time.
Reduced risk - there is less impact if something goes wrong, making it easier to identify and roll back issues when they occur.
Better testing - test coverage becomes more focused, making it clearer what needs manual testing and what might cause regression.
Team collaboration - more frequent code integration leads to better knowledge sharing across the team and reduces the chances of blocking other team members.
Maintaining momentum
On a practical level, reducing change complexity is important, but so is maintaining momentum. This applies to both you and those who will review your code. There is a point of diminishing returns—splitting changes too much can slow you down as the operational costs, like creating separate branches, managing commits or introducing feature flags, may simply take too much time and, as a result, outweigh the benefits. The same goes for the reviewer—it's helpful to review small changes, but if there are multiple review requests every half hour or so, it leads to constant context switching.
Where this point lies depends on many factors, and there is no strict rule for it. Nevertheless, t's important not to spread yourself too thin.
Practical tips
We discussed the reasons for reducing change complexity; now let's talk about how to do it. There are several ways to simplify changes, and you can apply these steps at any stage—before starting, while working on the change, or even after it's ready. Here are some methods that have worked well for me. The approach you take should take, however, depends on different factors, so you can choose what works best for each situation.
Assess the complexity. As we've discussed, assessing complexity involves two dimensions: size and scope.
How many lines of code have you or will you change? How many of these is effective code (not autogenerated or moved)? How many files were touched? These factors will contribute to your change size.
How many different concerns have your covered? Does you change include feature implementation, introducing tests, generating translations and some related refactoring work? How many other services will depend on this change? These factors will drive up the change scope.
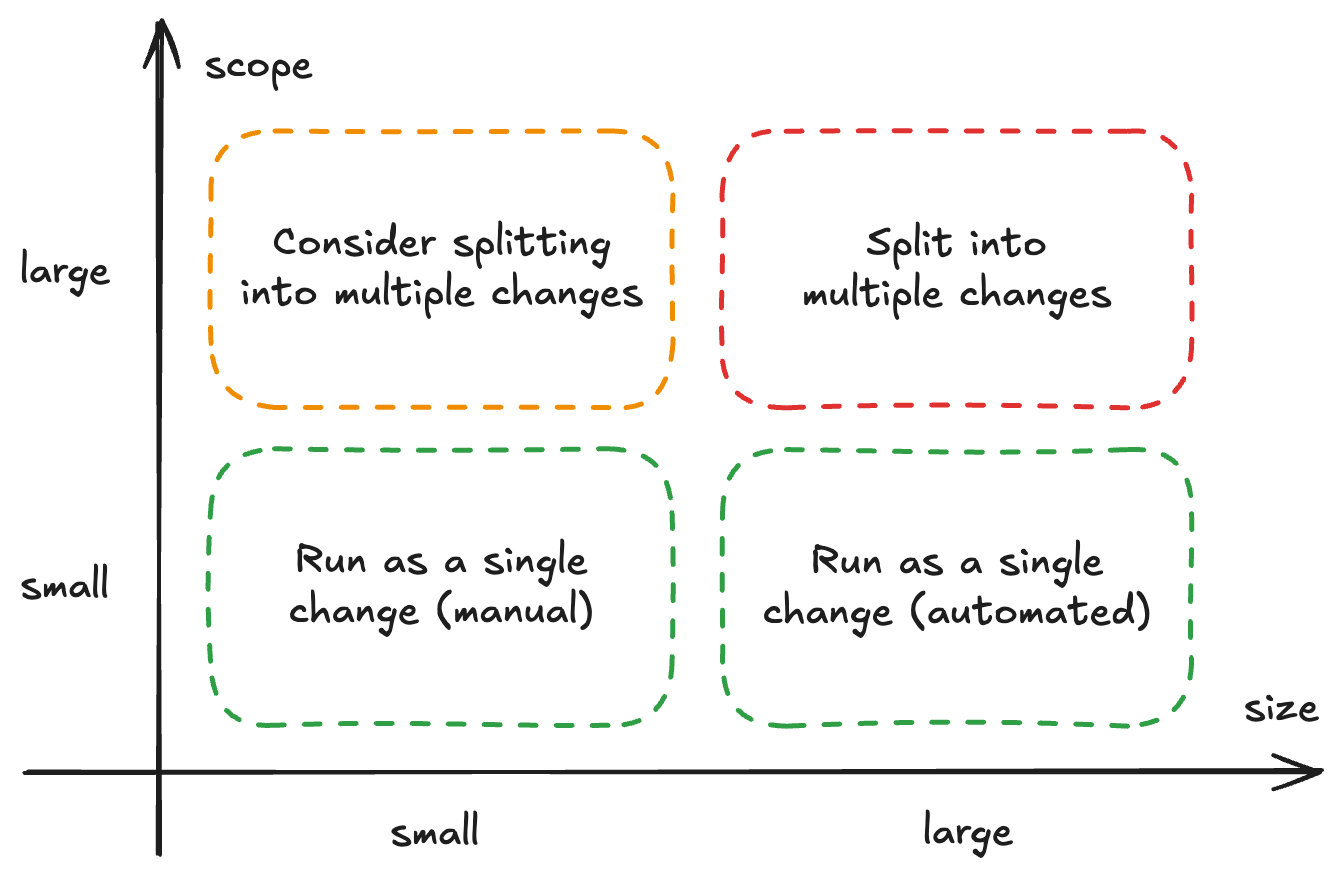
Decide how to run your change. Once we know the change size and scope, we should decide if the change actually needs to be split or not. Here are some guidelines that work for me.
Small in size, small in scope. It's the best and probably the most common type of change, like addressing a single issue in one part of the code. It can be handled as a single change and will likely be easy to review and deploy.
Large in size, small in scope. An example of this type of change might be addressing a specific concern throughout the entire codebase, like updating imports for a reusable package. These changes can often be automated, both in implementation and possibly in review. It's fine to run them as one change, and they are often easier to manage that way.
Small in size, large in scope. These are focused changes that affect critical functions or handle multiple concerns—this type of change might be worth splitting into smaller parts. It all depends on the context and circumstances. Even if you decide to keep it as a single change, it's important to consider ways to make it easier to review.
Large in size, large in scope. There are changes that affect multiple concerns across different parts of the codebase—they should always be divided into smaller parts. The approach will vary depending on the specific situation, but it's always helpful to break these into smaller pieces.
Document with comments. Even if you decide to keep it as a single change, it's helpful to document your change with comments. Comments in the code at the right places can be useful, but here I mainly mean comments for reviewing the change. There are two ways you can do this.
Change description. It's important to include several elements. Did you provide context for the problem you're addressing and outline the high-level approach to the solution? Did you clearly describe the scope of the change, detailing what areas it covers? Did you make sure to link to any relevant resources that can offer additional insights or background information? Lastly, if you have a recommended way to review the change, have you included that as well? This can all help reviewers to evaluate your work effectively.
Change comments. Adding context for reviewing in the change description is good, but adding comments is even better—the information is placed exactly where it's most needed. I often comment on my own pull requests before submitting them for review to highlight areas with significant changes, outline the type of change, or indicate that the code has been moved. When writing these comments, it's also helpful to consider if the comment will only be useful during the review or also afterward. If it's the latter, consider moving that information into a code comment.
Think about your commits. If the comments aren't enough to provide all the necessary context for reviewing a change, it might be worth splitting the change into individual commits. You can create commits based on the files or areas affected, or by concerns, such as separating a commit for implementation from a commit for tests. The individual commits still make up a single change but offer a clear separation.
Consider a follow-up pull request. Taking it a step further, you can open a follow-up pull request. This can be especially helpful for addressing optional code review feedback or making improvements. It's similar to splitting commits but provides even more separation and clarity.
Split the task. To give yourself even more flexibility, you can split the task entirely. This allows you to open separate pull requests, similar to the previous point, with the added benefit of getting back to the drawing board, reconsidering requirements, and planning individually.
Conclusion
That’s it! Deciding the right size for changes in software projects involves balancing change size and scope to reduce complexity and maintain momentum. While instincts to refine and improve code are valuable, they can distract from the main goals. Assessing change size and scope helps in managing change complexity, risks, and reviewing efficiency.
If you enjoyed the article or have a question, feel free to reach out to me on X or leave a comment below!
Subscribe to my newsletter
Read articles from Tomasz Gil directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Tomasz Gil
Tomasz Gil
I help product teams build quality software and lead engineering efforts. Currently working at Salesloft as a Senior UI Engineer.