Paper review - A Study and Comparison of Human and Deep Learning Recognition Performance Under Visual Distortions
 Victor Z
Victor ZTable of contents
While this is an older paper (2017), it holds significant relevance in the field of robustness.
The paper addresses a fundamental and still relevant question: do neural networks and human vision operate similarly? How do they handle distorted image inputs?
During this period, DNNs were believed to outperform humans on large dataset test sets (though this has always been a contentious claim, and more recent evidence suggests otherwise [2]).
Previous studies had shown that NN performance degraded significantly under distortion, raising doubts about the entire paradigm.
Defining a "bad image" lacks a clear analytical definition. In fact, developing image quality metrics that correlate well with human perception remains an active research area.
Specifically, the paper investigates how a neural network (ResNet) compares to humans when processing images with gaussian blur (5 blur levels, \(2<\sigma < 10\)) and additive gaussian noise (5 noise levels, \(40< \sigma < 200\)). Would fine-tuning improve the network's performance?
To illustrate these distortion levels:

The challenge involves classifying dog images (from ImageNet validation set) into 10 classes (50 images per class, with 20 used for testing and the rest for fine-tuning).
Humans receive training through exposure to ~30 images to familiarize them with dog breeds. Noisy images are presented from worst to best to avoid memory effects where subjects might correctly classify an image from having seen its cleaner version.
The tested networks include VGG16, GoogleNet, and ResNet50 in two variants:
ImageNet-trained and fine-tuned on clean images of the 10 dog breeds (~1200 images total).
ImageNet-trained and fine-tuned on noisy versions of the same images.
Results:
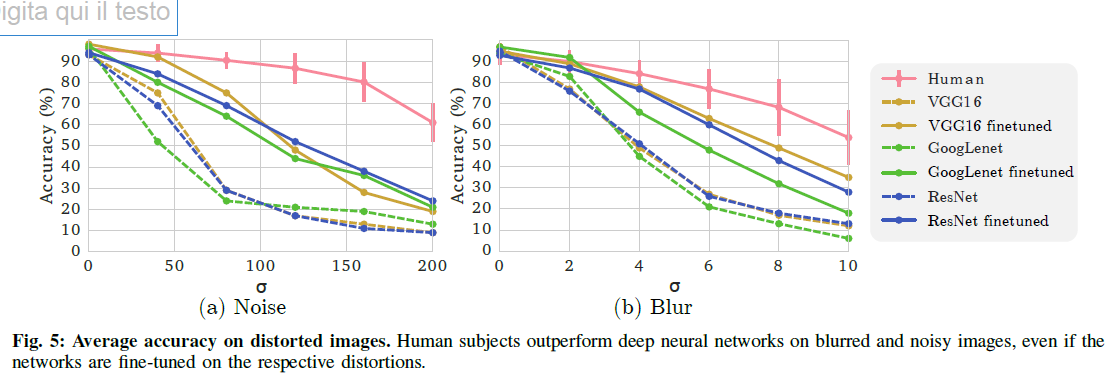
Humans clearly outperform the networks.
Key findings and considerations:
Non-fine-tuned networks quickly approach random guessing as degradation increases, especially for blur.
Little correlation exists between NN and human errors (Pearson correlation coefficient ~0.1), though larger sample sizes might reveal patterns.
Limitations/afterthoughts:
Human subject experiments prove costly and challenging (finding volunteers for tedious tasks is difficult), as the authors acknowledge.
While the authors conclude networks perform worse under distortion, a more accurate interpretation might be that humans demonstrate better sample efficiency.
Fine-tuning notably improves performance - achieving ~+20% accuracy per 25 examples is remarkable!
It would be interesting to explore potential scaling laws: would ten times the noisy images yield linear performance improvements?
This behavior makes sense from a distribution/order of magnitude perspective. After training on ~10^6 datapoints from one distribution, fine-tuning on just ~20 samples naturally limits adaptation potential.
References:
[2] V. Shankar et al. - Evaluating machine accuracy on ImageNet
Subscribe to my newsletter
Read articles from Victor Z directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by