Learn About Amazon S3: Insights into Storage, Security, and Replication
 Rawad Hossain
Rawad Hossain
In this blog, we'll explore Amazon S3, a versatile cloud storage service. We'll look at how S3 can simplify data management with its scalable storage options, security features, and flexible replication capabilities. We'll cover core components like buckets and objects, as well as advanced features such as encryption, access control, and versioning, all explained in a simple way. Click here to read previous blogs.
Amazon S3 (Simple Storage Service)
Let’s understand this with a simple example. Suppose you’re building a blogging website where you want to upload images for each blog post. Initially, you might consider storing these images directly on the web server where your website is hosted. However, there could be issues with storing images on your server as more images are added. This might slow down the site and affect the user experience. This is where Amazon S3 comes in.
Amazon S3, as the name suggests, is a simple storage service provided by AWS. It is an infinitely scalable, secure, and durable cloud storage service that lets you store and retrieve any amount of data at any time. One of its key features is that the cost is based on usage, without compromising on storage limits, availability, or backup capabilities.
Some Use Cases of S3
Backup and Archival
Data Lake and Big Data Storage
Static Content Hosting
Application and Media Hosting
Hybrid Cloud Storage and more.
To understand Amazon S3, there are a few core components you need to store, manage, and secure data. Some of them are:
S3 Buckets
Bucket is like a container which is used to store data or objects (files). Bucket names must be unique across all S3 users. It is like a high-level directory. For example, if the bucket name is blog-images, then the URL would look “https://blog-images.s3.site.com/”. In the console while creating bucket, region has to be specified in order to reduce latency for the users in specific regions.
S3 Objects
Within the bucket, the data or files that are stored are called Objects. It must have a key which will route to the actual data in the URL. The key is composed of prefix and object name. For example, an image object “cover.jpg“ in the bucket in URL may look like “https://blog-images.s3.site.com/cover.jpg“. This URL will route to the location in the server where image is stored.
The actual data or contents of the body are the Object Values. Each object can be up to 5 TB (5000GB) in size. For files larger than 5 GB, you need to use "multi-part upload," which breaks the file into smaller parts for faster, more reliable uploads.
S3 Security
Amazon S3 protects data by controlling access to its resources. It uses both user-based and resource-based mechanisms to maintain security.
An overview of the security features in S3:
Access Control
IAM Policies: AWS Identity and Access Management (IAM) allows to create users and manage their respective access. For example, you can grant which API calls should be allowed for a specific user from IAM.
Bucket Policies: Bucket policies are the JSON based policies which define which permissions are allowed for all the objects in the bucket. In the JSON data, the permissions include
Version - specifies the policy version
Statement - define who has access to the bucket, what actions they can perform, and which resources they apply to.
Effect - specifies if an action is allowed or denied
Principal - specifies who the policy applies to, (
"*"), means it applies to everyoneAction - specifies the allowed action
Resource - defines which resources the policy applies to
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": "*",
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::my-public-bucket/*"
}
]
}
An example of JSON policy to the objects in a bucket
Access Control Lists (ACLs): To make individual objects accessible to authorized users ACLs are used. It allows you to manage access for both Object and Bucket. They are effective for access management and ownership control. At the time of bucket creation, ACLs can be enabled or disabled.
S3 Encryption
Encryption is automatically applied to new objects stored in this bucket. In S3 it is called Server-Side Encryption (SSE) which can be of three types.
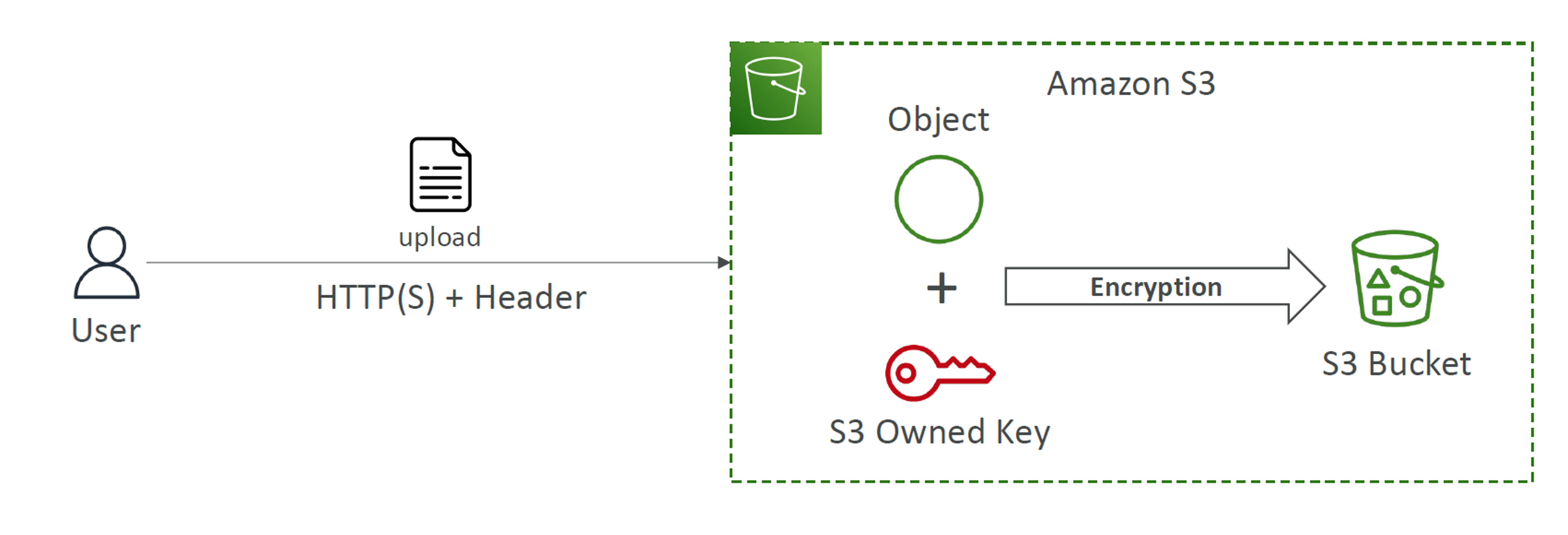
SSE-S3
In this encryption, keys are owned, managed and handled by AWS S3. Data is encrypted using “AES-256“.
Whenever new buckets and objects are created, S3 automatically encrypts it (by default) with a unique key and manages it for further use.
The picture below describes the scenario in simpler way.
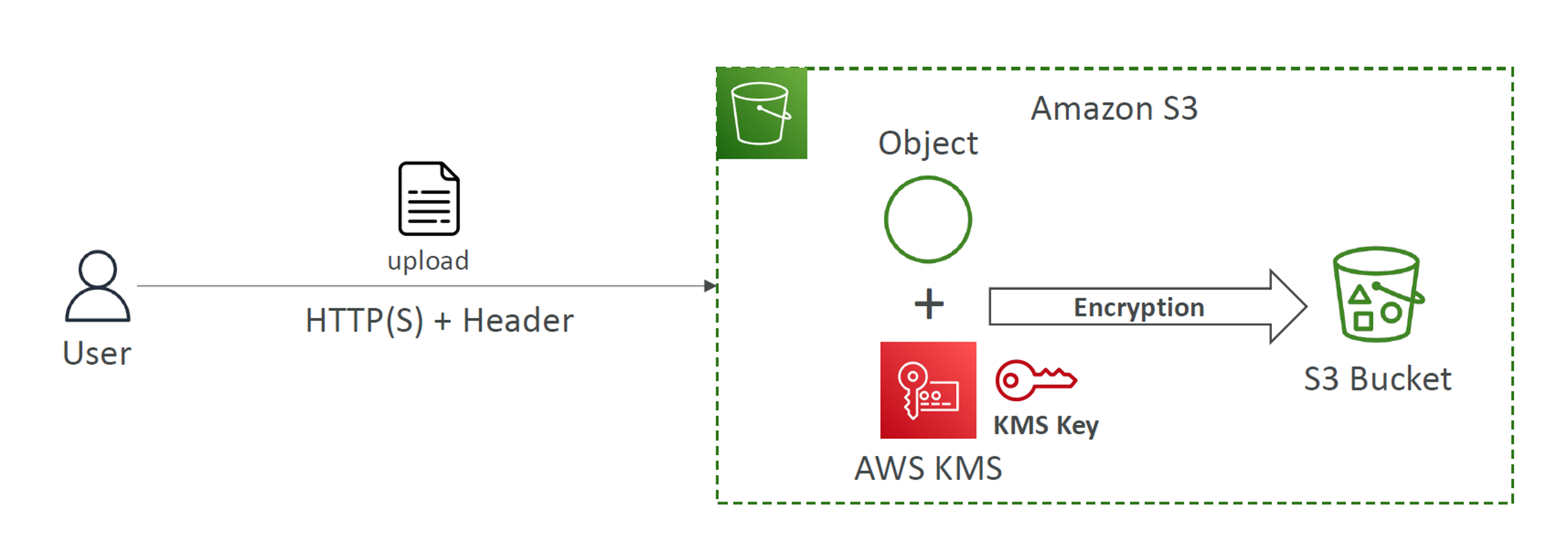
SSE-KMS
It uses the AWS Key Management Service (KMS) for handling and managing encryption keys.
As the keys are managed by yourself, you can audit key usage using CloudTrail. Moreover, KMS handles key rotation automatically making it more secure.
SSE-C
This Server-Side Encryption provides the freedom to the clients or customers to create and manage own encryption keys.
Whenever Customer provides the key, AWS encrypts the data and discards the key once encryption is done, meaning Amazon S3 does not store the key you provide.
However, S3 requires HTTPS for all requests that use SSE-C to maintain secured transmission of customer provided keys.
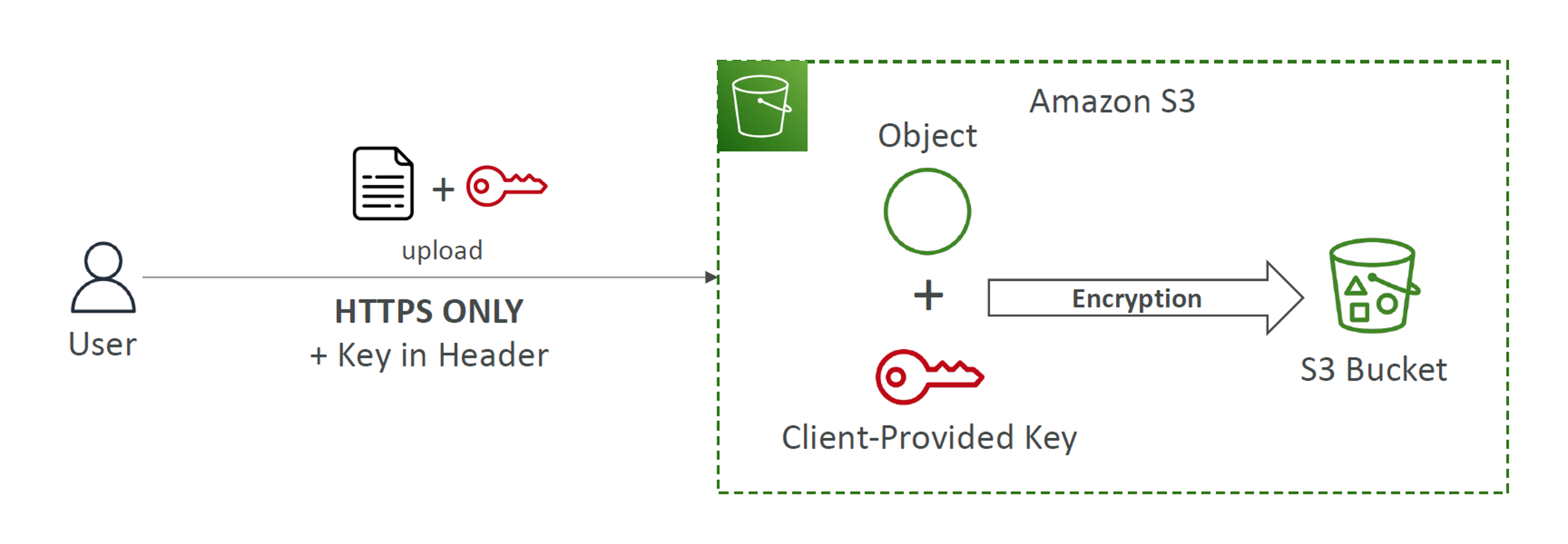
SSE-C encryption is suitable for users who want to manage their own keys, also want to use S3' encryption features.
Bucket policies are processed first, followed by the 'Default Encryption' settings.
S3 Block Public Access
This block public access setting prevents accidental exposure of buckets and objects to the public internet. You can apply block public access settings to restrict all unauthorized public access or cross-account access.
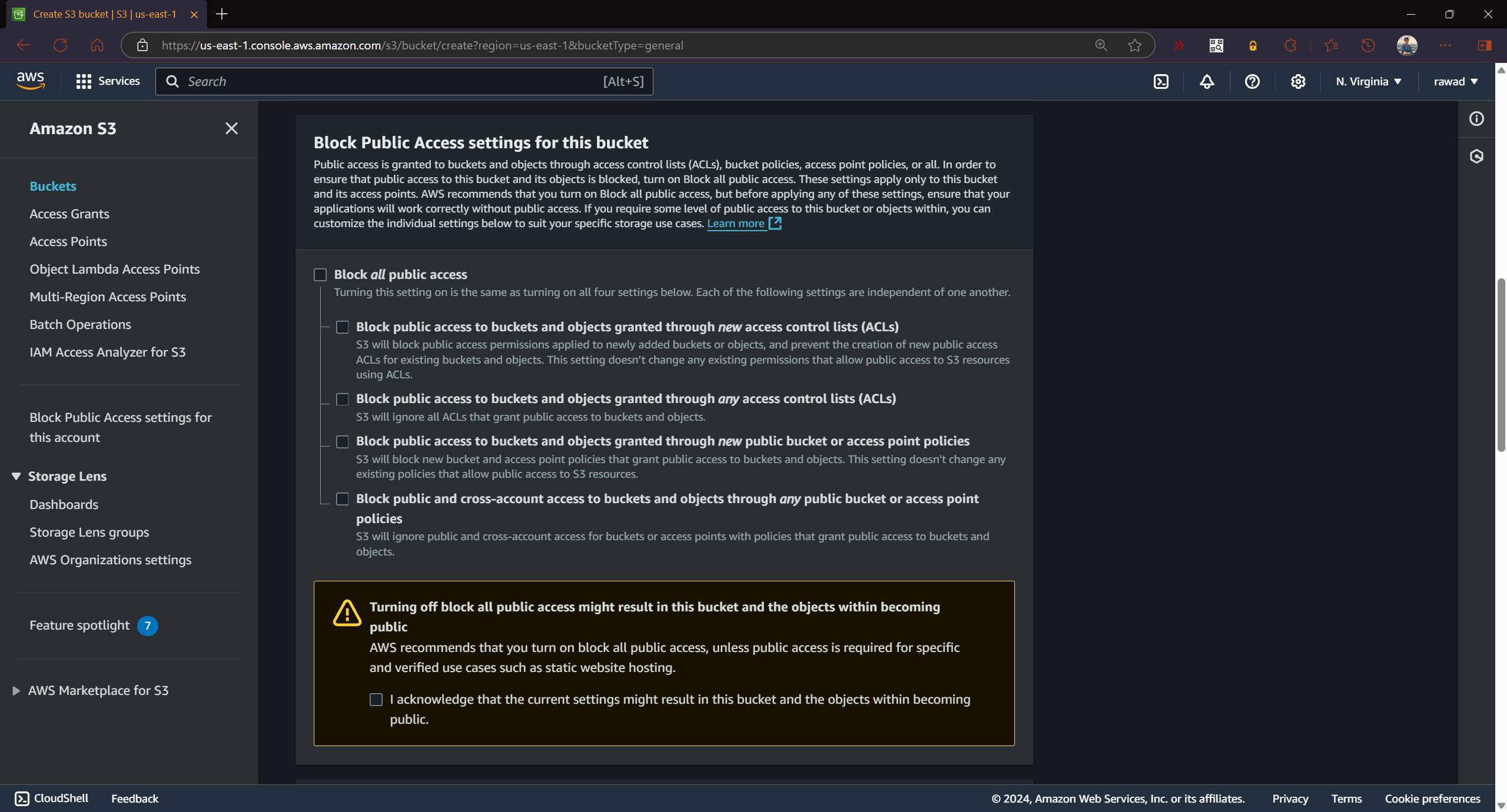
These settings let you override bucket policies and ACLs, making sure your data stays private, even if permissions are accidentally set to public.
Object Lock and Versioning
In S3, the Object Lock feature prevents objects from being deleted or overwritten for a set period or indefinitely. This means that users or administrators cannot modify or delete the object until the specified time has passed.
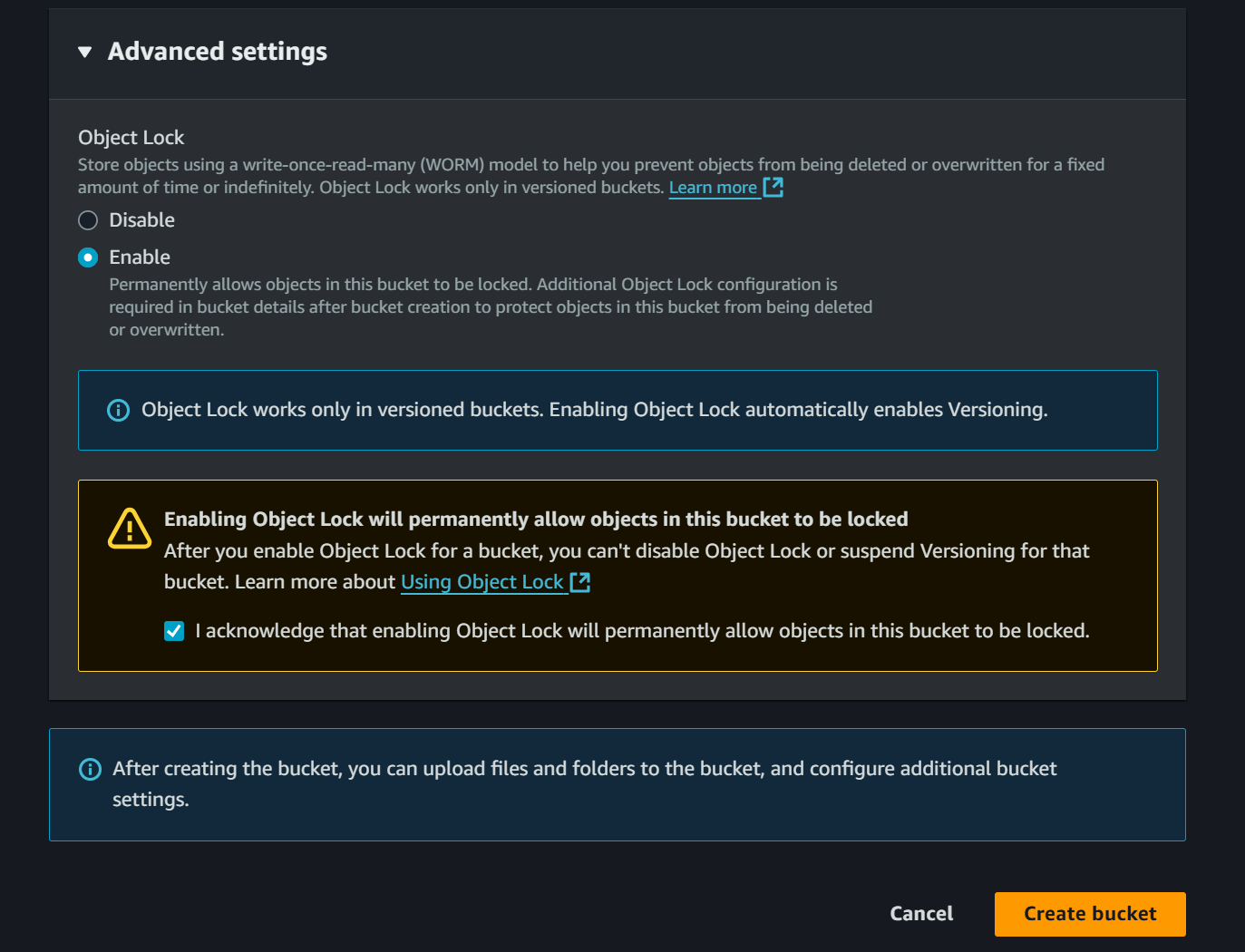
More details about Object Lock here.
S3 Versioning is having multiple versions of your files, and it is enabled at bucket level. By this, you can recover the files that have been overridden or deleted. Also, you can use versioning to preserve, retrieve, and restore every version of every object stored in your Amazon S3 bucket. The old version of the files is called “noncurrent version“, which can be easily rolled back upon user request.
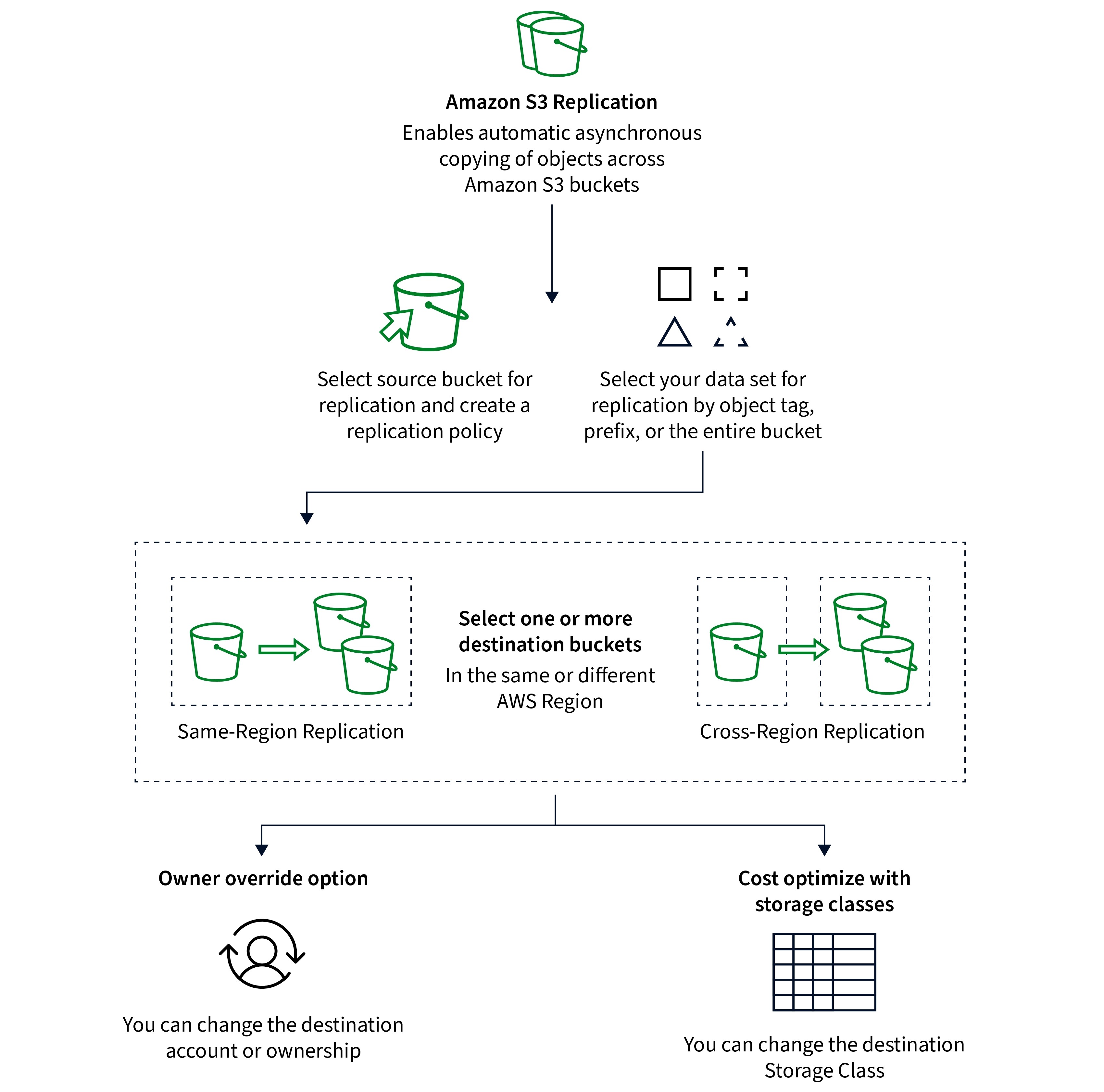
Replication (Cross-Region & Same-Region)
Replication means making multiple copy (asynchronous copy) of objects from one bucket to another, so versioning must be enabled. These replication methods are here to help you easily manage redundancy, disaster recovery, and compliance needs.
Amazon S3 offers two types of replications.
Cross-Region Replication (CRR)
Copies objects from a source bucket in one AWS region to a destination bucket in a different region. This way, data is stored closer to users in various regions, greatly reducing latency. You can set up rules to replicate only certain objects based on prefixes, tags, or object sizes.
Using IAM role, this replication of objects in source bucket can be done across different AWS account as well by enabling permissions to replicate objects (using get/put operations) to the target bucket.
In short, CRR is ideal for distributing data across different regions, disaster recovery, and ensuring data redundancy on a global scale.
The image below represents the scenario in a much simpler way.

Same-Region Replication (SRR)
Copies objects within the same region, that is from one bucket to another within the same region. This allows to maintain backup of data within the same region, giving you an extra layer of redundancy.
SRR can combine data from multiple source buckets into one bucket, which is useful for analyzing logs or centralizing data for processing.
In short, SRR is best for in-region compliance, backup within the same region, and log aggregation for centralized analysis.
This picture illustrates the working mechanism of S3 Replication in both types.
This is the end of this blog.
In the next one, we'll explore different storage classes in S3, their availability, lifecycle policy and more.
Subscribe to my newsletter
Read articles from Rawad Hossain directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by