Overview of RAG
 Rahul Lokurte
Rahul Lokurte
When an User prompts the questions to the LLM, it produces the response based on the training data. The pre-trained LLM data is its parametric data. It might not have an context specific to our query. LLM still produces an answer confidently. It is termed as Hallucinations. The high level issues with using the pretrained LLM are:
It lacks the context of the query.
It hallucinates and confidently produces a response.
To overcome this challenges, we can provide our own data from different sources within the organisations. The own data that we provide to LLMs are termed as non-parametric data. Now we ask LLM to verify our own data and the capabilities of pretrained data together when it produces an response to a query. This is termed as Retrieval Augmented Generation.
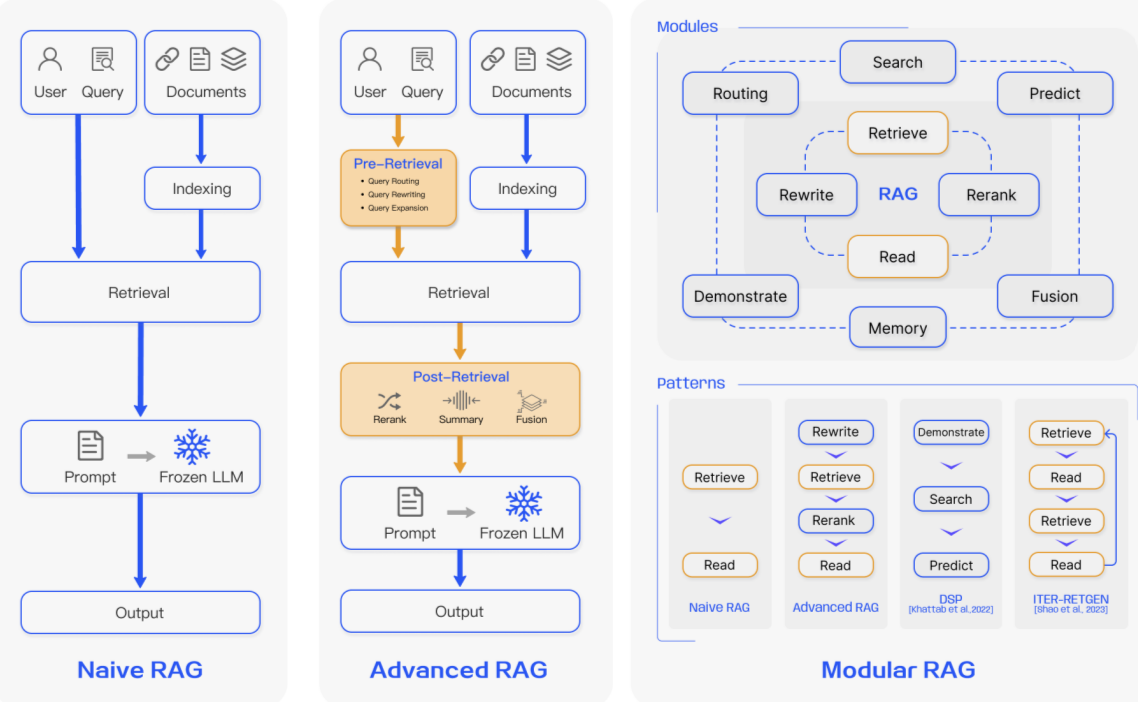
Different Research Paradigms of RAG
The research on RAG is continuously evolving. It can be categrized into 3 stages.
Naive RAG
Advanced RAG
Modular RAG
Naive RAG
Most of the initial research was done in this space.It is a traditional process that includes indexing,retrieval and Generation. It is called as Retrieve-Read framework.
Indexing involves cleaning and extracting the raw data from various sources. Due to LLM models context limitations, we need to break the text to smaller chunks. The chunks are encoded into vector representation using the embedding model and stored in a vector database. This step is very important as in retrieval stage, we use it to do similarity searches.
When we receive an input query, we use the same encoding that was used during Indexing to transform the query to vector representation. Now, we compute the similarity scores with the query and stored chunks vectors. We can extract configurable number of chunks that are matched with the query. This context is passed to LLMs as a context information along with the original input query.
In generation phase, the LLM uses the context information and the original query to formulate the response. We can also pass extra conversational history, so the LLM can use it further to enhance its response. The response will depend on the parametric knowledge that the LLM model has.
Drawbacks
Some of the drawback are
Retrieval challenge - If we ask same question multiple times, it may respond with different answers everytime. It struggles with accuracy and also it cannot recall what the answer were given previously. So, we may get different chunks in the context and miss crucial informations.
Generation challenges - The model may still hallucinate and it may produce a response that is not provided in the context. It shows bias towards specific outputs. It may not generate quality response and answers are not reliable, if it generates different response every time with the same question.
Data challenges - The context that was provided may not be sufficient for the models to provide a response when we do different tasks with the same data. Specifically, if we have data from different sources, it may provide repeated similar answers for different tasks. Sometimes, the models will just respond to the retrieved content without providing additional content from the parametric data it has been pretrained.
Advanced RAG
It is an improvement on the limitations that we have in Naive RAG. For quality of retrieval, it introduces pre-retrieval and post-retrieval steps. To improve the indexing, it uses some of advanced techniques like sliding window, fine-grained segementation, metadata.
During pre-retrieval, its main focus is to optimize the indexing and original input query. The query optimization will help in making the original question more clearer. It helps in retrieval process, if the context is accurate. It involves query rewriting, query-transfomation, query-expansion
During post-retrieval, It mainly focuses on reranking the chunks and compressing of context, so that only relevant information are passed to the models. It ensures that LLM does not get the unrelated context that may overweigh the original intentions.
Modular RAG
As more advanced in RAG space is evolving, we are leaning more towards the Modular approach of tackling RAG systems. The main focus is adaptability. It supports complex and efficient retrival mechanisms. It adds different kinds of the specialized modules to enhance particular components in RAG systems.
Search Module is added to enhance the similarity searches and also improving the retrieval through fine tuning.The search module helps in efficient searching across different data sources like search engines, databases, knowledge graphs.
RAGFusion adds a capability for expanding user queries and can do parallel vector searches. Thus it will have more insights in the provided data.
Memory module adds a capability to the LLM retrival memory. It can retain most of the informations in memory and it will have relavant information more closer to the data. It adds more depth to the knowledge base.
Routing module helps in getting relavant information by selecting most appropriate data source to a given input query. It can combine from various data sources or access specific database.
Predict module enhances LLM capability to predict accurately, so the models can filter out unnecessary information to the input query.
By using these modules, it makes significant improvements in retrieval quality, thereby advancing the capabilities of RAG systems.
Reference Source from research paper: https://arxiv.org/abs/2312.10997
Subscribe to my newsletter
Read articles from Rahul Lokurte directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Rahul Lokurte
Rahul Lokurte
I am a Lead Engineer from India. Love to blog about serverless and help teams design and develop serverless architecture. An AWS cloud practitioner. Blogs about AWS Services utilising AWS CDK, CloudFormation, Terraform.