Machine Learning Chapter 5: Association Rule Learning
 Fatima Jannet
Fatima JannetTable of contents
- ARL - Apriori Intuition
- Apriori Python Steps
- Study Materials
- Python Implementation
- Importing
- Training the Apriori model on the dataset
- Displaying the first results coming directly from the output of the apriori function
- Putting the results well organised into a Pandas DataFrame
- Displaying the results non sorted
- Displaying the results sorted by descending lifts
- ARL - Eclat Intuition
- Eclat Python Steps

Welcome to Part 5 - Association Rule Learning!
ARL - Apriori Intuition
Before starting, i wanna tell you an urban legend in data science. This is not a myth, it actually happened a long time ago. Well the legend got distorted over time but here it is - What is the commonality is between these two products, diapers and beer? What do you think they have in common and why are they part of this urban legend?
As the story goes, a company, much like a convenience store, analyzed the products that people were buying. They looked at what customers were purchasing together and searched for patterns. After examining thousands of transactions, they discovered something interesting: during certain times of the day, particularly between 6 and 9 p.m., people who bought diapers also bought beer. This was surprising because these two products seem unrelated. Why would someone buy beer when buying diapers, or vice versa? The data revealed this pattern, and one possible explanation is that in the afternoons or evenings, when the husband comes home, if they realize they are out of diapers, the husband goes to pick them up. So, while he's at the convenience store, since it's after work hours, he also picks up some beer. This explanation seems reasonable, though it might not always be the case. But based on this insight, you can decide how to arrange products in your store.
Now, some stores might decide to place these two products closer together to encourage people to buy beer when they're buying diapers. However, many stores do the opposite. They separate beer and diapers, much like they separate bread and milk. You might notice in your convenience store that bread and milk are placed far apart. Why? Because they know these products are often bought together. By placing them at opposite ends of the store, you have to walk through the entire store to pick them up. As you walk, you see more products and are more likely to buy something you didn't plan to purchase initially.
There are many interesting marketing tactics based on this data, but how do you get this data? One way is through the Apriori algorithm. Let's discuss Apriori in more detail now.

The Apriori algorithm helps identify patterns, such as people who bought one item also buying another, or those who watched one thing also watching something else, or those who did one activity also doing another.
All right, so let's have a look.
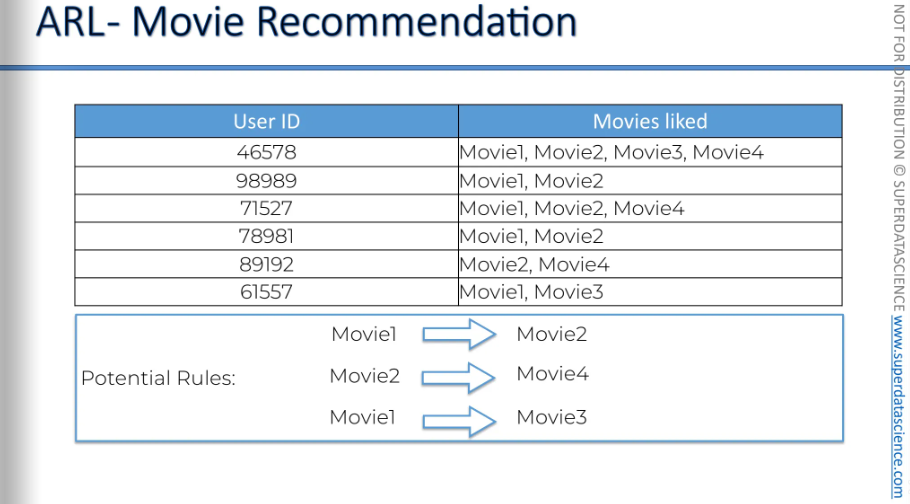
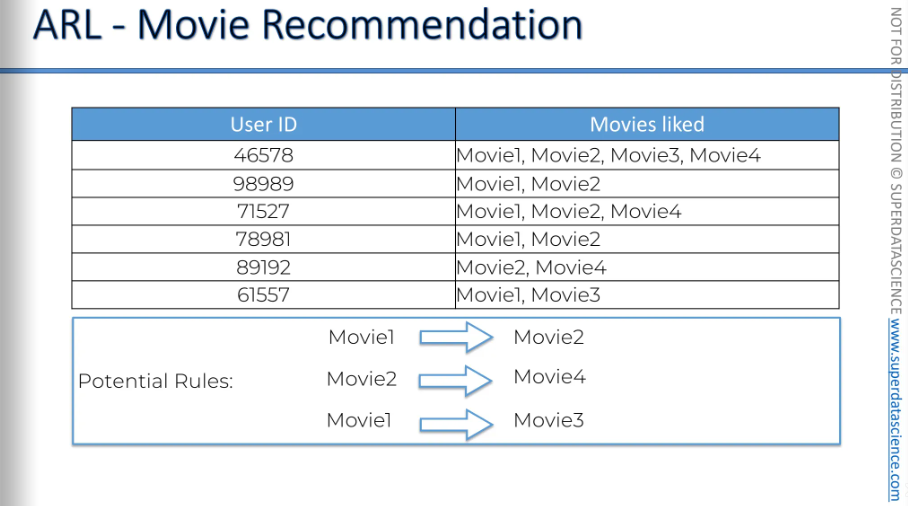
For example, in movie recommendations, you have user IDs and the movies they liked. Just by looking at this data, you can already see that...
People who watch movie one will likely also like movie two.
People who like movie two are likely to also like movie four.
People who like movie one are likely to also like movie three.
you can create many potential rules, but some will be stronger than others. We want to find the strongest ones to base our business or other decisions.
We don't have to ask people questions like, "Do you like movie number one?" or "Would you like movie number two?" Instead, we can understand their preferences from the data. We aim to extract this information, and as long as we have a large enough sample size—say, 50,000 or 500,000 people, not just five—we can develop some solid rules.
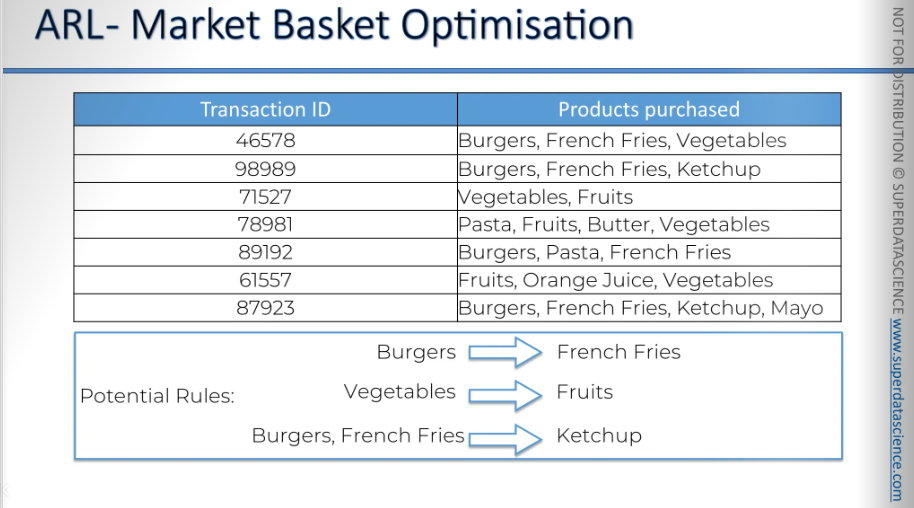
This is another example of “people who purchased this also purchased that..”
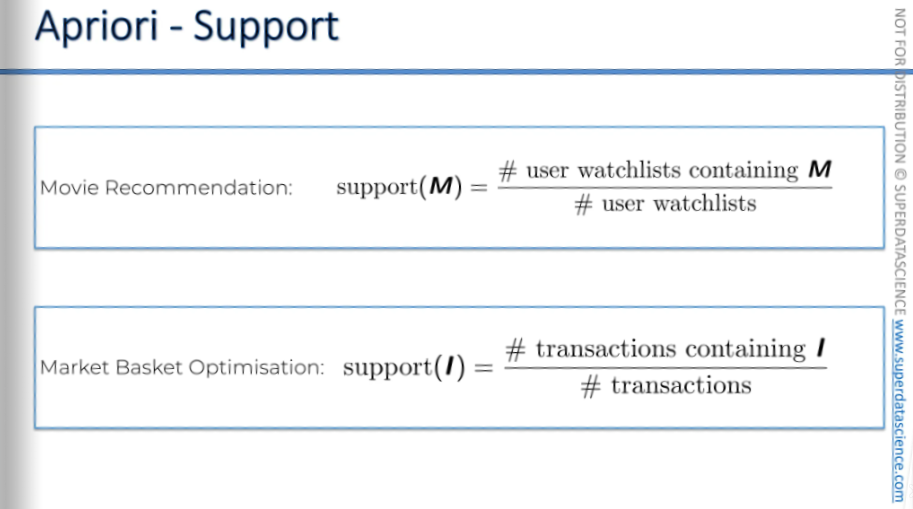
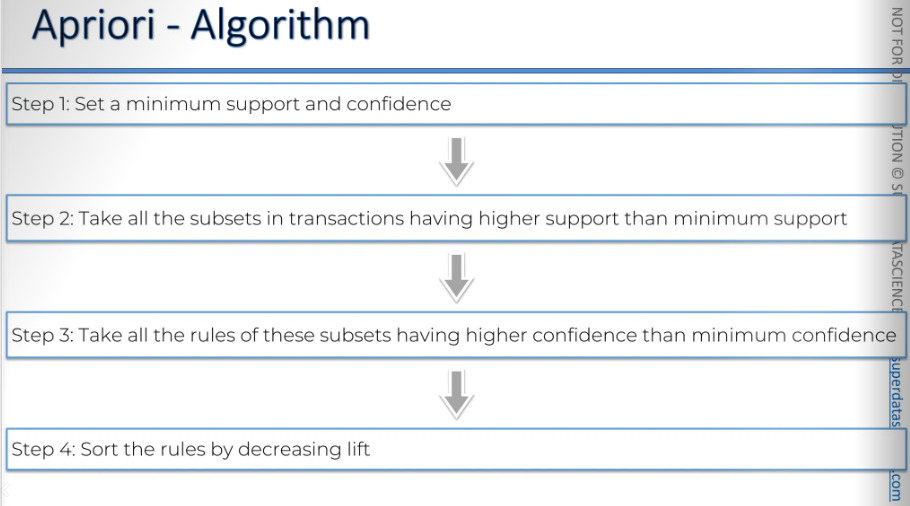
The Apriori algorithm has three parts to it, it got the:
Support
Confidence
Lift
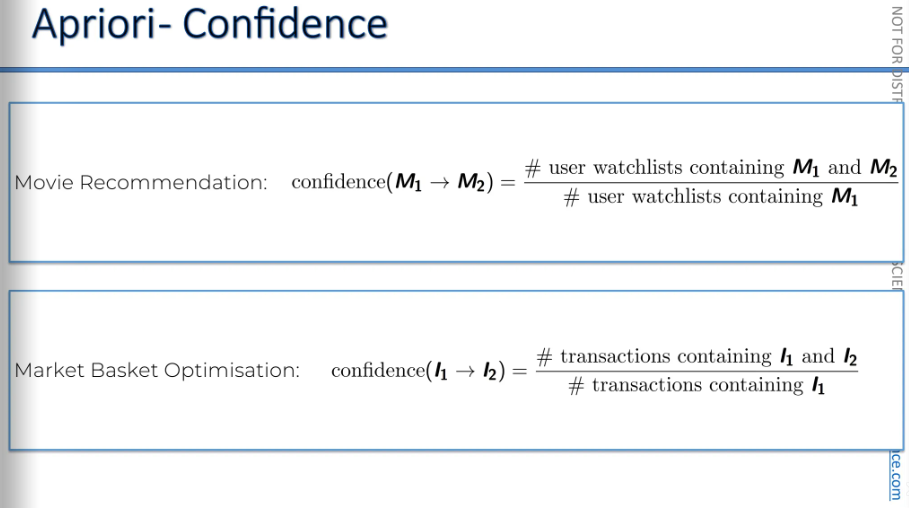
Starting with support: Support for movie M is calculated by dividing the number of users who watched movie M by the total number of users. It's the same for market basket optimization: the number of transactions containing item I divided by the total number of transactions.
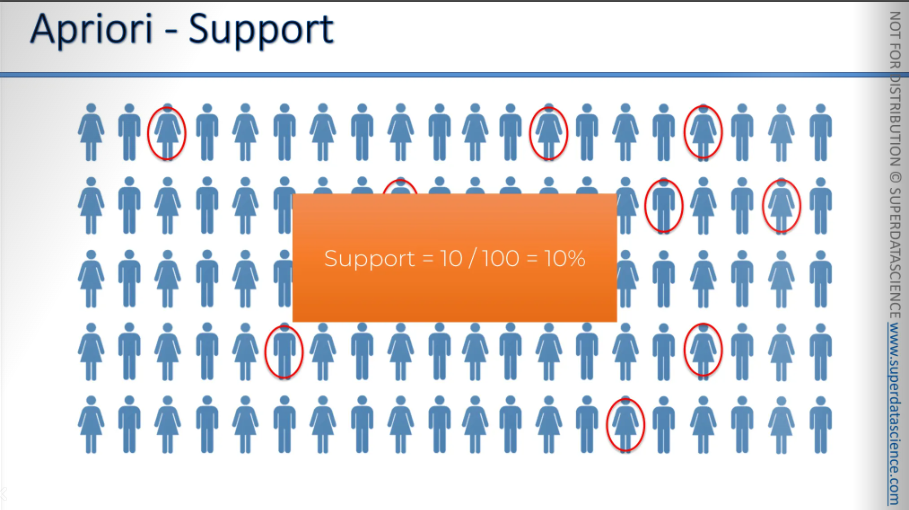
Let’s say we have a 100 people here, 5 rows and 20 columns. 10 of them watched the Ex-Machina. That means our support here is 10%.
Now, step two: We need to find the confidence. Confidence is calculated by dividing the number of people who have seen both movies, M1 and M2, by the number of people who have seen movie M1.
For example, people who have seen "Interstellar" are also likely to have seen "Ex Machina." In this case, movie number one, M1, is "Interstellar."
And in market basket optimization, it's similar. For example, people who order burgers often also order french fries. At the top, you have people who ordered both burgers and fries, and at the bottom, those who ordered burgers, whether or not they got fries.
Okay, so we're going to take everyone who has seen "Interstellar" and check how many of them have also seen "Ex Machina."
Now we want to know, not from our entire population, but just from those who have seen "Interstellar," how many have also seen "Ex Machina?" Among them, we have seven people who have also watched "Ex Machina."
Let’s say the people in grey has seen Interstellar. And the red marked (7 people) are people who has seen Interstellar as well as Ex-Machina.
So our confidence = 7/40 = 17.5%

Last step: The lift. Lift is basically confidence/support.

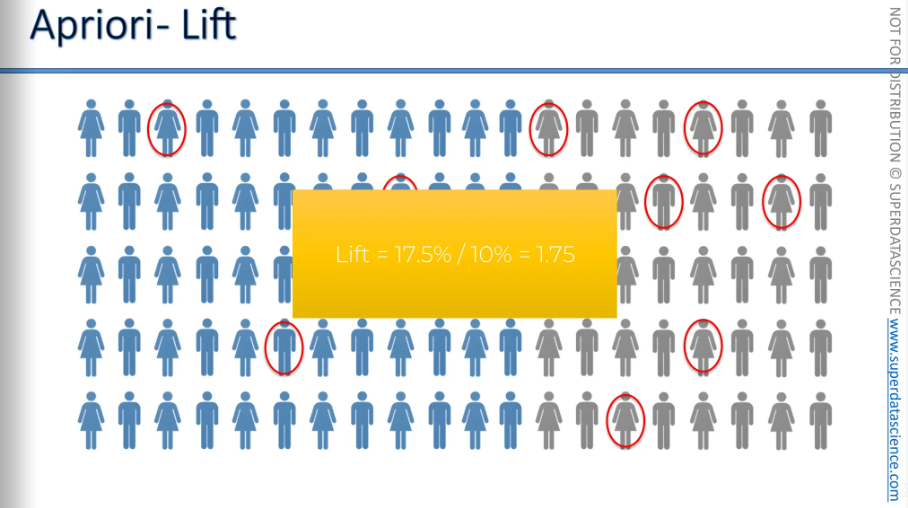
So here, the people in grey have seen "Interstellar." The people circled in red have seen "Ex Machina” (10 peoples)
Now, if we just randomly suggest to a person to watch "Ex Machina," what is the likelihood that they will like it? Assume that if they haven't watched it, they won't like it. The likelihood is 10% right? Because 10 of them has seen Ex-Machina.
But now the question is, can we prove that result using some prior knowledge? That's why the algorithm is called Apriori.
Let’s create a new group and only recommend "Ex Machina" to people who have already seen "Interstellar," marked in grey in this group. So we'll only ask, "Have you seen Interstellar?"
If they have, then we'll recommend "Ex Machina."
What is the chance that a person will actually like "Ex Machina" if we recommend it this way? In that case, as we've calculated, 17.5% of the people in the grey group actually liked "Ex Machina."
The lift is the improvement in your prediction.
Your original prediction is 10%. If you randomly choose a person from your new group and recommend "Ex Machina," the chance they will like it is 10%.
If you first ask, "Have you seen and liked 'Interstellar'?" and they say yes, then recommend "Ex Machina," the chance of a successful recommendation is 17.5%.
So the lift is 1.75.
This is the step by step progress.
Apriori Python Steps
We're going to explore a new method for understanding relationships and correlations. This time, we'll learn about association rules. You know, like the popular phrase, "people who bought this also bought that." That's what Amazon uses in its recommendation system. It predicts what customers will buy based on their previous purchases, which is why you see suggestions for new products when you buy something. In this section, I'll show you how to create a model that can do these kinds of things, okay?
It's very useful, especially for retail businesses or any type of e-commerce. So, if you are a data scientist working for an e-commerce company, you will definitely use it.
Study Materials
apriori.ipynb (save a copy in drive)
Market_Basket_Optimisation.csv
(download and upload it to your copy. But DO NOT OPEN THE FILE because it's very large, and Google Colab won't allow you to open it. However, you can view the downloaded version.)
About the datasheet: Imagine a lively place in French where happy people walk down the streets, visit grocery stores, and stop by coffee shops regularly, a lively area.
Now, imagine you own one of these stores, maybe selling food and delicious treats. As a business owner, you want to optimize and boost sales. And you have an idea. You want to offer the popular deal: buy this and get that for free. Each week, the owner gathers all the different customer transactions.7,500 transactions were collected throughout the entire week. At the end of the week, you receive this list of transactions to learn the association rules and determine the best deals the owner should offer to the clients. All right? That's your mission.
Here, we'll use association rule learning to find strong rules that show if customers buy one product, they're likely to buy another. We'll measure this likelihood to offer deals like "buy this product and get that one for free."
Python Implementation
As usual, delete all the code cells keeping the text cells only.
The first step is to implement data pre-processing. This time, we'll only use the libraries from our template and the first line of code to load the dataset. We won't create a matrix of features or a dependent variable vector because we're doing association rule learning. We also won't split the dataset into training and test sets, as we'll learn all the rules from the entire dataset.
NOTE: Unfortunately, the PsycLearn library doesn't include some classes or functions from apyori. It doesn't have the apyori model. Instead, we'll use another library called apyori. The apiary.py is a Python implementation that contains all the algorithms of the apyori model. However, Google Colab usually has most libraries and packages pre-installed, but it doesn't include the apyori module. So, we'll need to install it ourselves. It's good to see this process because you might encounter this situation occasionally. It's important to know how to install a package or library from the web. We'll use a pip command to download the apyori file from the internet and then install it in this notebook.
Importing
We are done with importing necessary things.
We need to be careful with the dataset. Notice that unlike our previous dataset, this one doesn't have column names. Each element represents different products, so there's no need for column names. To handle this, we must specify in the read_csv function that the first row doesn't contain column names. We do this by setting the header parameter to None in pandas.
The issue is that this dataset needs to be in a specific format, which is not a pandas DataFrame. So, we need to recreate the dataset from the original pandas DataFrame to match the format expected by the apyori function, which will train the apyori model on the entire dataset. This format is simply a list of transactions. Instead of having the dataset as a pandas DataFrame, we need it as a list of transactions. That's exactly what we need to do now: create that list.
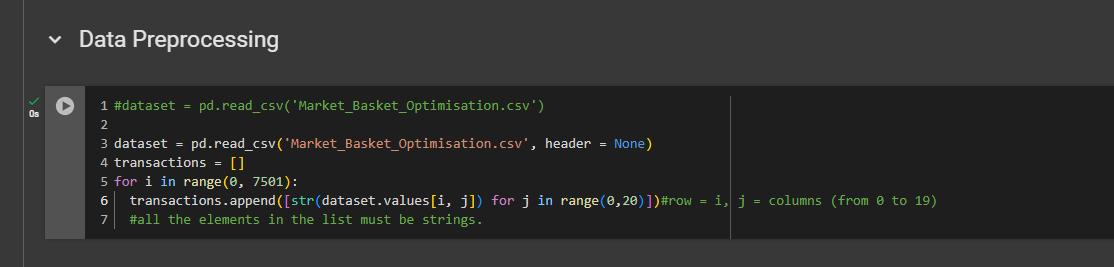
Now we put all 7,500 transactions into the transactions list in a str format.
Training the Apriori model on the dataset
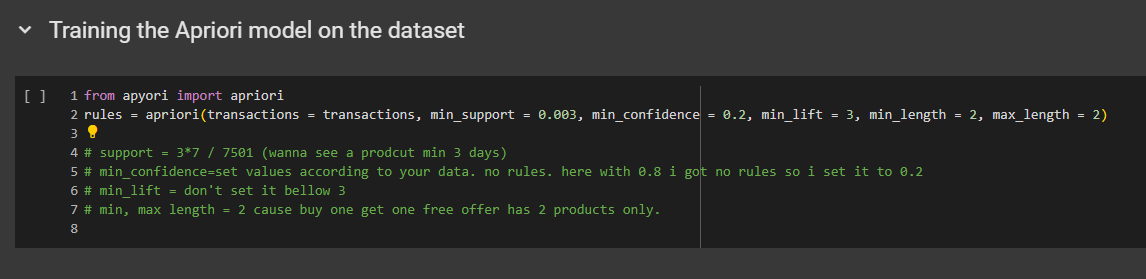
The first thing to understand is that this function will return the rules. It will not only train an Apriori model on the dataset but also, at the same time, provide the final rules with different supports, confidences, and lifts.
Displaying the first results coming directly from the output of the apriori function
So, now we will clearly visualize the rules and see their support, confidence, and lift for each one. Mainly, we will identify the best deals, like buying one product and getting another one for free.
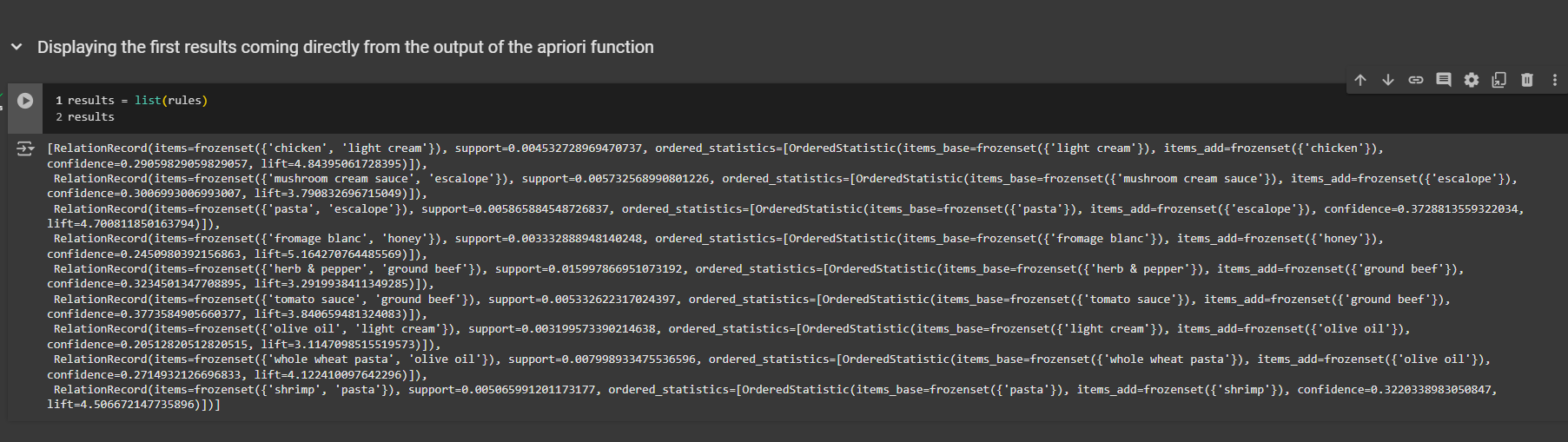
All the rules are given here one by one, in different rows.
First, we see that the two products in this rule are light cream and chicken. But be careful—the order is not that if customers buy light cream, they will buy chicken. It's actually the other way around. If we look closely, the base item is light cream, and the added item is chicken. This means the left side of the rule is light cream, and the right side is chicken. So, if people buy light cream, there is a high chance they will also buy chicken. This chance is measured by the confidence, which is 0.29 here. This means if customers buy light cream, there is a 29% chance they will buy chicken. This makes sense, especially in France, where people often use light cream with lemon as a sauce for chicken. It's a common traditional French meal.
Next, we can see the lift, which is quite good at 4.84. Remember, all our rules here have a lift greater than three. The support is 0.0045, meaning this rule with these two products appears in 0.45% of the transactions.
The second rule involves mushroom cream sauce and escalope. Here, the base item is mushroom cream sauce, and the added item is escalope. This means if customers buy mushroom cream sauce, there is a high chance they will also buy escalope, with that chance being 30%. The lift is 3.79, or about 3.8, and the support is 0.005, meaning this combination appears in 0.5% of the transactions.
Okay, great.
We have these rules, and they look good, but viewing them could be easier. Scrolling left and right is overwhelming. I found a helpful code snippet online, possibly from Stack Overflow or a similar site. We'll use to organize the results into a Pandas data frame.
Putting the results well organised into a Pandas DataFrame
We don't need to rewrite that code snippet from scratch because it's very specific to this association rule learning implementation, and you'll likely only use it once. It's not crucial to understand every detail, so we'll simply copy and paste it here from our original implementation.
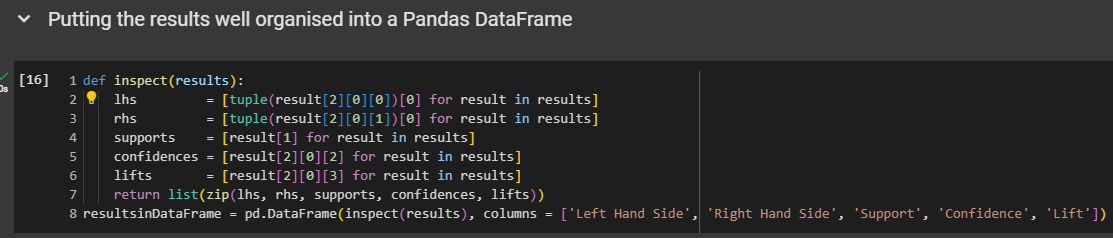
I found it online, and it's very practical for what we're doing right now, which is association rule learning. Sounds good?
Displaying the results non sorted
Now let's take a look at the results.
First, we'll run this cell to build the inspect function and create a new data frame, which I've named results_in_dataframe. This will contain the same rules, but they will be better organized and more visually appealing.
Next, we'll create a new code cell to display the unsorted results. To do this, we simply need to call what we created here, meaning resultsinDataFrame
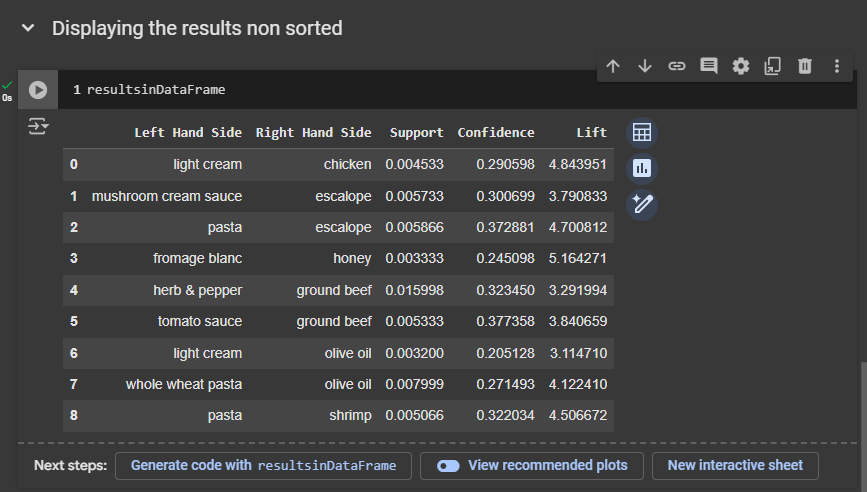
First rule:
If customers buy light cream, they have a 29% chance of buying chicken.
This rule appears in 0.4% of transactions.
It has a lift of 4.84, which is very good.
Second rule:
If people buy mushroom cream sauce, they have a 30% chance of buying escalope.
It has a lift of 3.79, which is still pretty good.
Third rule:
If people buy pasta, they have a 30% chance of buying escalope.
The lift is 4.7, which is quite good.
Fourth rule:
If customers buy fromage blanc, they have a good chance of buying honey.
Fromage blanc with honey is a delicious French dessert.
The lift is 5.16, which is very, very good.
Fifth rule:
If people buy herb and pepper, they have a good chance of buying ground beef.
This combination is popular among French people and others.
The confidence is good, but the lift is not very high.
Tomato sauce:
It's nice to put tomato sauce on ground beef.
The lift is still close to 4.
Light cream and olive oil:
I don't really see the association, but why not?
I'm not really a good cook, but maybe there is a recipe where we can combine olive oil and light cream.
Not so sure about that, but this one is definitely something I would do.
Wholewheat pasta and olive oil:
Whenever I buy wholewheat pasta, I also get olive oil.
The lift is pretty high.
Pasta and shrimps:
That's a very good specialty of the south of France, especially near the coast.
French people love mixing pasta and shrimps.
The lift is 4.5, so very good.
Displaying the results sorted by descending lifts
Now we have sorted lists according to the lift.
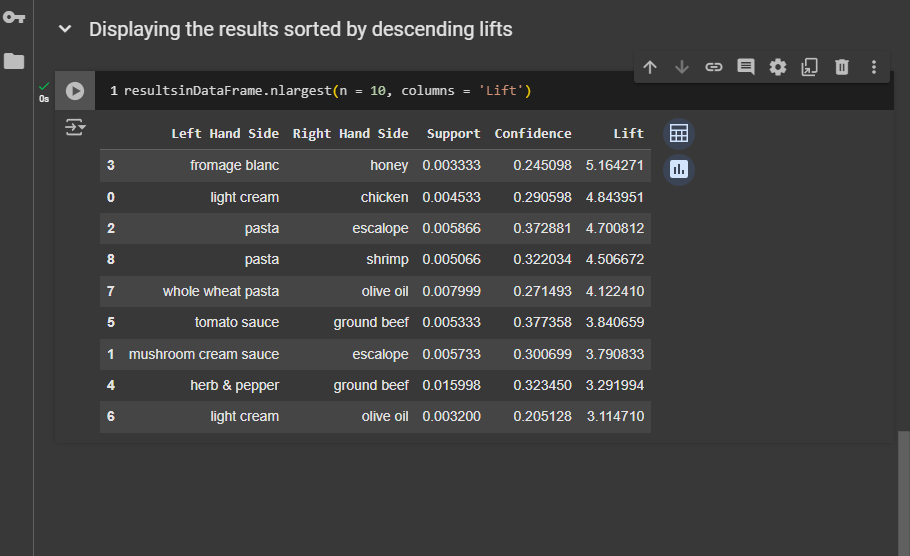
French people love to add honey to fromage blanc. If I owned the shop, I would definitely offer a deal: buy fromage blanc and get honey for free. That's definitely a very strong rule here.
This is the second strongest rule: light cream and chicken. So, another great deal would be if you buy light cream, you get chicken for free. That's actually a very good deal. However, as I mentioned, the owner can set smart prices to make buying both items worthwhile. But that's another topic. Here, we're focusing on association rules, not pricing strategy.
So, let's move on to the next rule. If people buy pasta, they will also enjoy buying escalope. A third great deal would be to buy pasta and get escalope for free. The same goes for pasta and shrimp; if you buy pasta, you can get shrimp for free. If you buy wholewheat pasta, you can get olive oil for free. These deals will be very attractive to customers because they often buy these combinations of products.
ARL - Eclat Intuition
After we have already studied the Apriori model, it's kind of like a simplified version.
The Eclat model also focuses on "people who bought, also bought." It's similar to a recommender system.
Here we got some movie recommendations and some rules.
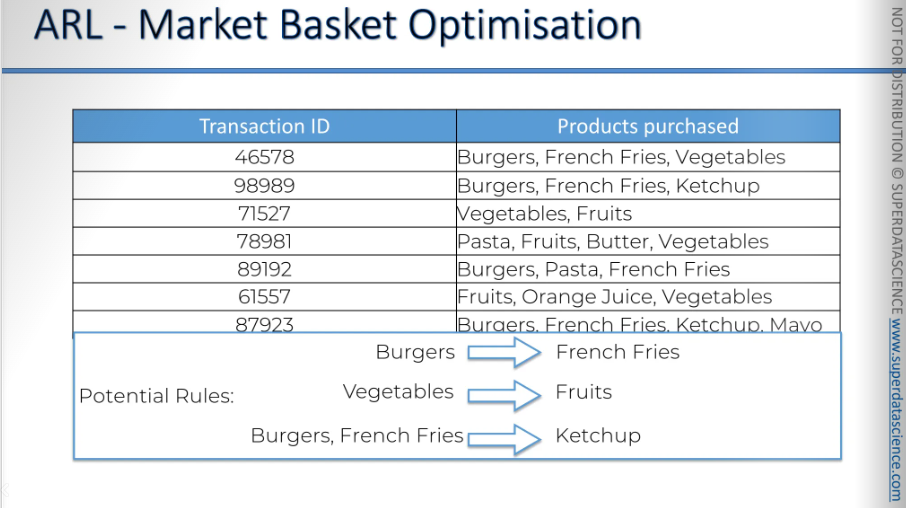
Here, we have the market basket optimization. It's similar to how people who buy burgers are likely to buy french fries too. People who buy vegetables are likely to buy fruits. These are just some possible rules. We're not saying these rules are strong or that we're choosing them; we're just exploring potential outcomes.
The Eclat model is responsible for analyzing all these combinations and telling us what we should focus on.
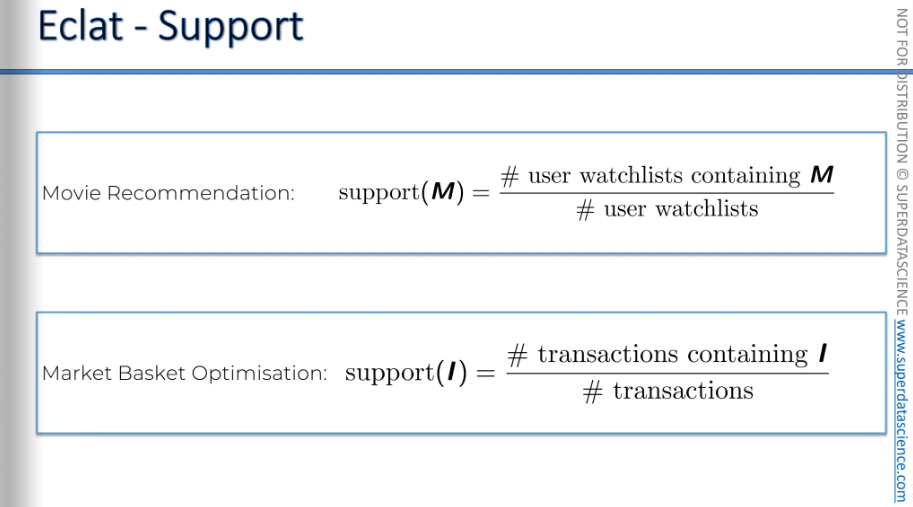
We have the support factor for Eclat as well. In the apriori model we had support, confidence and lift. In the Eclat model, we only have support.
[Here M stands for a set of two movies or more]
When we calculate support, we're asking how often a set of two movies, like Interstellar and Ex Machina, appears in all watch lists. What percentage of watch lists, or lists of movies that people liked, contain both of these movies together? Not just one of them, but both together.
Let's say, hypothetically, if 100% of the lists in a large dataset contain both movies together, it would mean that anyone who likes Interstellar also likes Ex Machina, and vice versa. So, if someone has seen one of these movies, you should recommend the other one to them.
If 80% of your lists have these two movies together, it indicates a high likelihood that they come in pairs. If someone likes one, they will likely like the other.
The same applies to transactions. For example, if chips and burgers appear together in 75% of all orders, then if someone is buying burgers, recommending chips to them has a 75% chance of success. It's a straightforward approach.
That's essentially the Eclat model. It's much faster.
The steps involved are set a minimum support

Eclat Python Steps
This tutorial is going to be a quick one. Because we’ll be doing support only. If you need to choose an association rule learning model for mining, I definitely recommend the Apriori Model. However, in some business cases, you might only focus on support. If you're only interested in support analysis, you might use Eclat in special situations. But even with Apriori, you can still perform this analysis.
Market_Basket_Optimisation.csv
(download and upload it to your copy. But DO NOT OPEN THE FILE because it's very large, and Google Colab won't allow you to open it. However, you can view the downloaded version.)
So, we build the Eclat Model by adapting the Apriori Model to match the Eclat Model's output. If you want to analyze larger sets of products (since we're only doing this for sets of two products), you just need to change the parameters in the training cell. Specifically, adjust the maximum length to include larger sets of products. Even if you end up with several products on one side and one product on the other, that's okay. The support for a rule with multiple products on the left and one on the right is the same as the support for the set containing all these products.
Subscribe to my newsletter
Read articles from Fatima Jannet directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by