A Guide to Information Architecture and Taxonomy Structure for Web3 Docs
 Owanate Amachree
Owanate AmachreeTable of contents

According to the Interaction Design Foundation, Information architecture (IA) is the discipline of making information findable and understandable. It includes searching, browsing, categorising and presenting relevant and contextual information to help people understand their surroundings and find what they’re looking for online and in the real world.
Before proceeding, read the previous series on Exploring Web3 Documentation: Key Challenges and Growth Opportunities and User Research Methods to Boost Your Information Architecture Design.
Considering the above definition and with results from the user research and journey mapping exercise, categorise or group the information into different buckets using a system in human-computer interaction known as mental models. “A mental model is what the user believes about the system (web, application, or other product). Mental models help the user predict how a system will work and influence their interaction with an interface”. Another common approach or framework used in the documentation space is the diataxis framework, which suggests approaches to content, information architecture and form that emerge from a systematic approach to understanding the needs of documentation users. Diataxis suggests categorising content into Tutorials, how-to guides, explanations and references. This systematic approach will be slightly different when categorising information for a web3 platform.
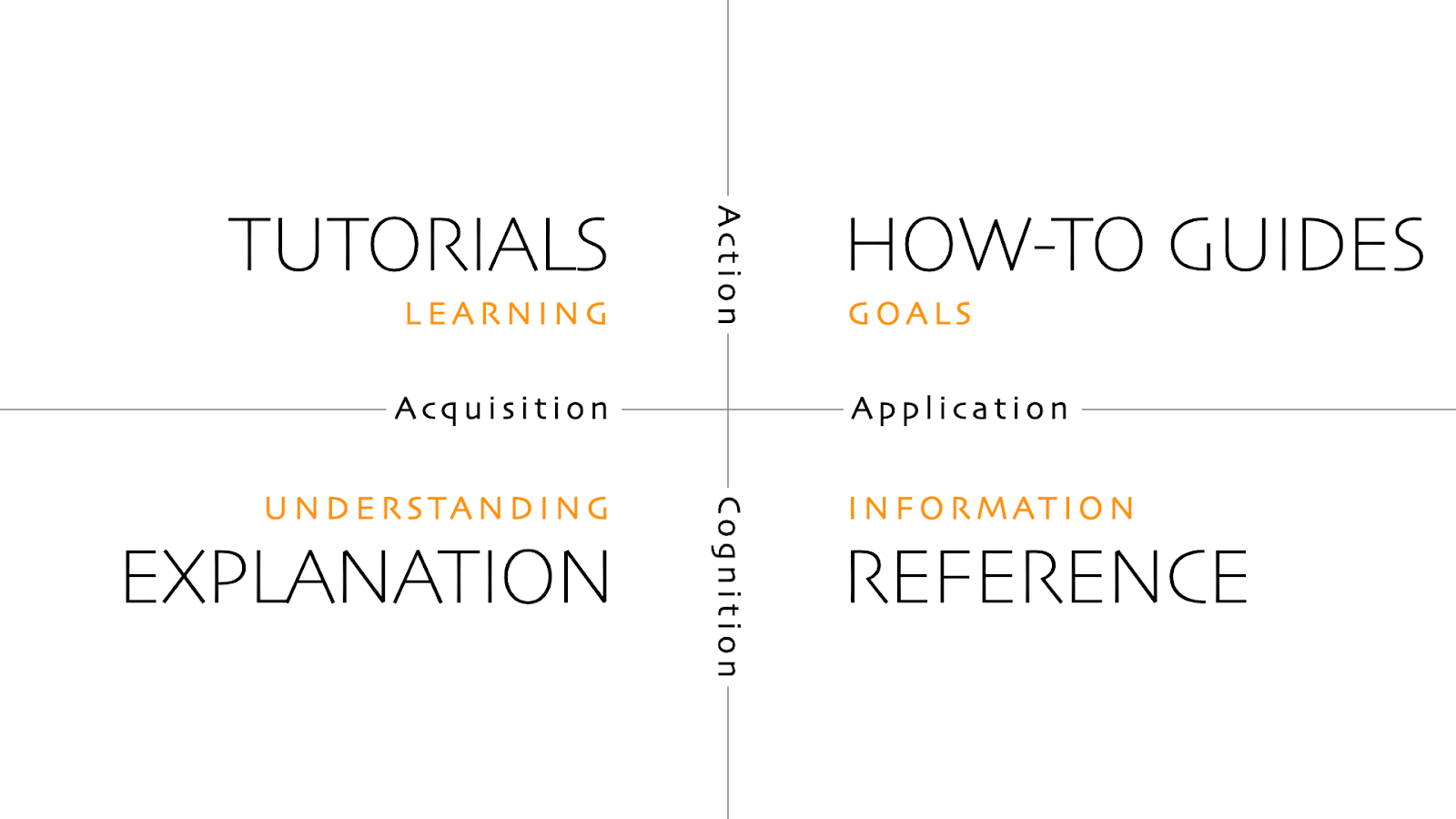
We will look at how to apply this systematic approach but from a web3 platform POV.
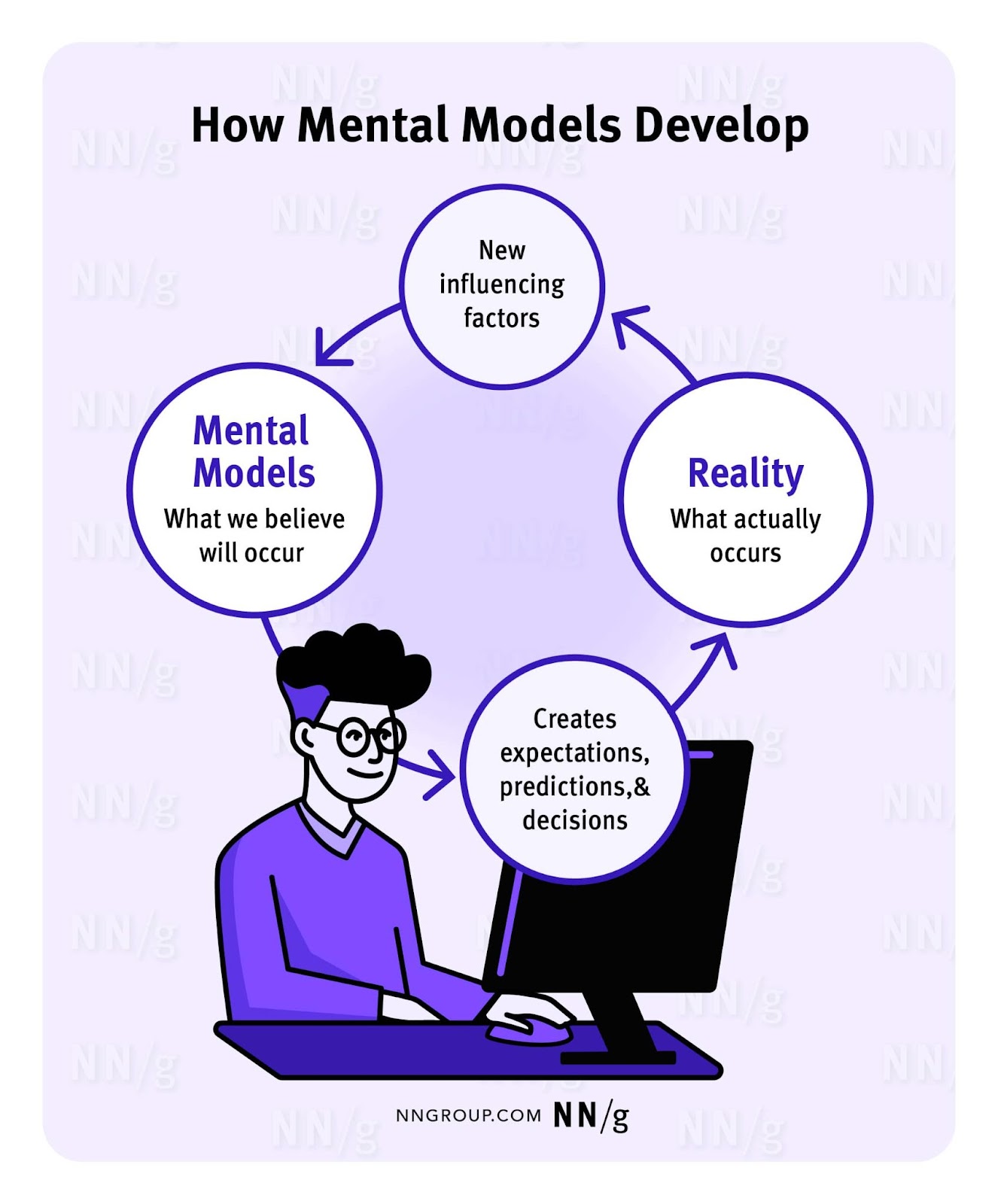
A practical example…
We covered vital differences between web2 and web3 documentation, some of which were decentralisation and Technology.
In decentralisation, it was observed that Documentation must be accessible to a wide range of stakeholders, including Developers, Node Operators, and General Users.
In technology, it was observed that given the complex nature of the blockchain, a documentation or developer portal needs to explain complex concepts like blockchain fundamentals, smart contracts, cryptographic concepts, etc., which is vital.
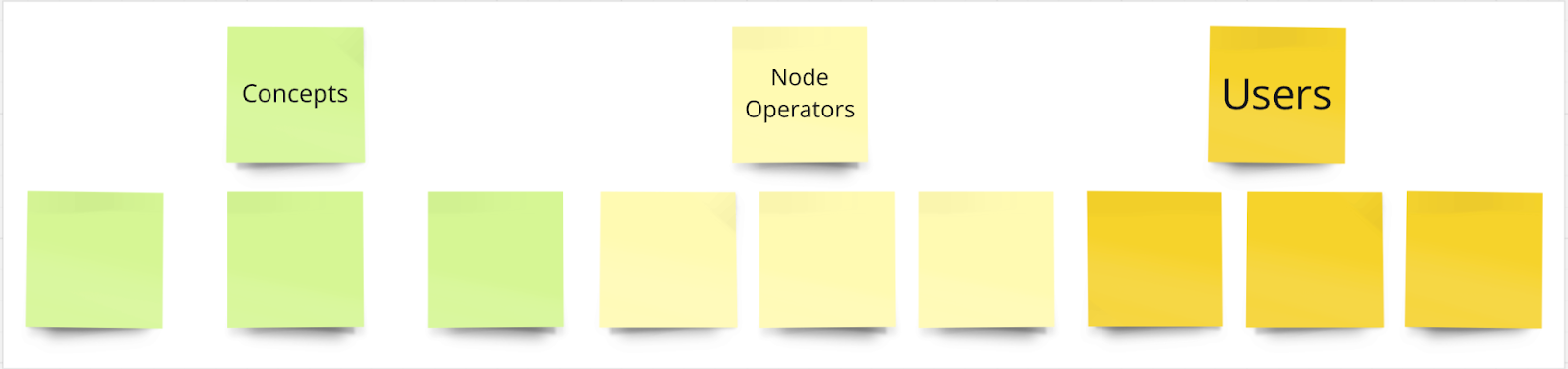
Based on the above, we can now draw up a simple IA. In the image below, we have categorised and labelled the content into three buckets: Concepts, Node Operators, and Users. Recall the definition of mental models. This means a beginner to your Web3 platform will most likely navigate to the concepts section, a node operator will likely navigate to the Node Operators section, and a user of that product or tool will most likely navigate to the Users section.
Some examples of exemplary IA implementations that applied the mental model and journey mapping include the Ethereum Developer Resources, Polygon Knowledge Layer, Casper Documentation, Rootstock Developer Portal, etc.
In the following article in this series, we will cover how to assess the existing content by conducting a content inventory and taxonomy planning.
Resources
Huge thanks to Brendan Graetz for the review and feedback.
Subscribe to my newsletter
Read articles from Owanate Amachree directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Owanate Amachree
Owanate Amachree
I’m a lead technical writer with over four years of experience helping global blockchain companies drive product adoption. Through high-quality product documentation, guides, and articles, I have empowered over 7,000 developers, users, and enterprise businesses to engage effectively with blockchain technologies. Currently serving as a Lead Technical Writer at RootstockLabs, I have authored and published over 50 guides and tutorials, significantly improving developer onboarding and user experience.