Behind the Scenes of kubectl get pods: How Kubernetes Components Collaborate
 Shubham Taware
Shubham Taware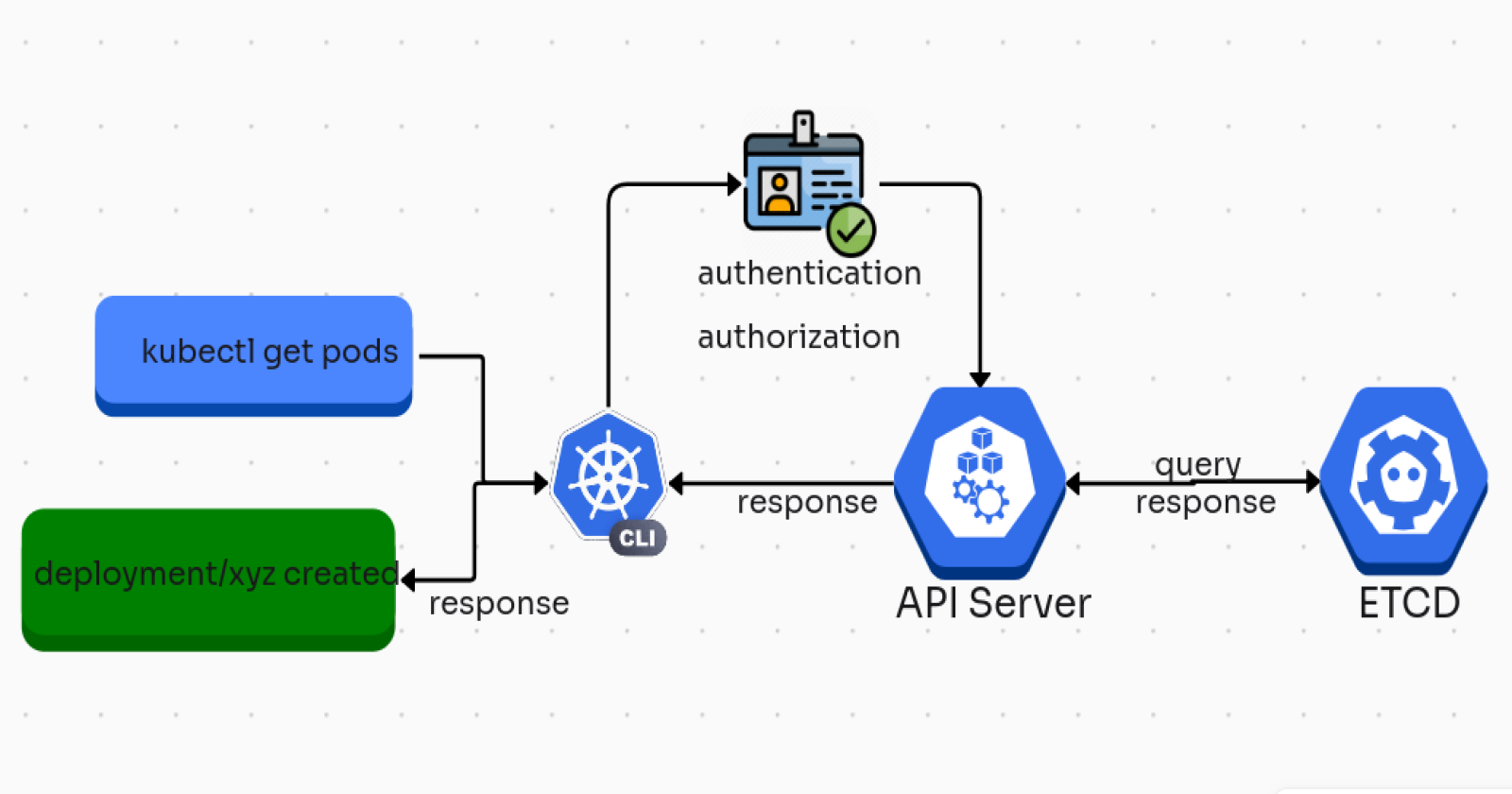
The kubectl get pods command is used to retrieve the status and details of Pods running in a Kubernetes cluster. To understand the detailed workflow of how Kubernetes components work together when you execute this command, let's break it down into multiple layers of the Kubernetes control plane and data flow.
High-Level Overview:
The kubectl get pods command performs a query for the current state of Pods in the Kubernetes cluster. The request passes through several Kubernetes components: from your local kubectl client to the Kubernetes API Server, and then from there to etcd (Kubernetes’ key-value store) and back. The data is then returned to kubectl, which formats and displays it in your terminal.
Detailed Breakdown:
1. The kubectl Command Execution
When you run:
kubectl get pods
You are invoking the kubectl command-line tool to interact with the Kubernetes cluster.
a. Kubeconfig and Context
kubectllooks at your localkubeconfigfile (typically located at~/.kube/config) to determine which Kubernetes cluster to interact with. This file contains the API server's endpoint URL, your authentication credentials, and other configuration details.The current context defined in the kubeconfig file specifies:
Which cluster to communicate with.
The user credentials and authentication methods (e.g., token, certificate, etc.).
The namespace in which to query resources (unless specified otherwise).
The kubectl command uses this context to authenticate and make requests to the correct API server.
2. Sending Request to the Kubernetes API Server
After resolving the context, kubectl makes an HTTP request to the Kubernetes API Server (kube-apiserver). Specifically, for the command kubectl get pods, it makes a GET request to the /api/v1/pods endpoint.
Example request:
GET /api/v1/pods
API Server: The Kubernetes API Server is the central component of the control plane, responsible for serving all API requests in the cluster. It acts as a gateway between external users and the cluster’s internal state.
Authentication and Authorization: When the request reaches the API Server:
Authentication: The API Server checks the credentials included in the request (either in the kubeconfig file or via HTTP headers) to ensure the client is authenticated.
Authorization: After authentication, the API Server checks the user’s RBAC (Role-Based Access Control) policies to ensure that the user is authorized to retrieve information about Pods.
If either authentication or authorization fails, the request is rejected with a corresponding error message.
3. API Server Queries the etcd Database
The Kubernetes API Server maintains the cluster's desired state, such as information about Pods, Deployments, Services, etc., in etcd, a distributed key-value store.
The API Server queries etcd for the latest state of Pods. In this case, it asks for all the Pod resources in the cluster or a specific namespace (if specified in the request).
etcd contains the following data for Pods:
Pod metadata (name, namespace, labels, annotations, etc.)
Status of the Pod (e.g., whether it's running, pending, succeeded, etc.)
Container details (name, image, ports, volumes, etc.)
The current state of the Pod (e.g., the list of containers and their states)
4. Controller Manager (Indirect Role)
Although the Controller Manager is not directly involved in retrieving Pods, it plays a crucial role in maintaining the desired state of the cluster.
Controllers (like ReplicaSet, Deployment, etc.) continuously monitor the actual state of the cluster. If the actual state does not match the desired state (e.g., Pods that should be running are not), controllers will create or terminate Pods to match the desired state.
In the case of
kubectl get pods, the Controller Manager ensures that any Pods that need to be running are indeed up-to-date and scheduled. It does not directly impact the query result but ensures the state in etcd is consistent with the desired state.
5. Scheduler (Indirect Role)
The Scheduler also does not directly impact the kubectl get pods request, but it ensures that Pods are scheduled on Nodes.
- Scheduler is responsible for assigning Pods to available Nodes when they are first created. If a Pod is not yet scheduled, it will show as being in a "Pending" state, and the scheduler may later place it on a Node based on available resources.
6. API Server Responds to kubectl
Once the API Server has the necessary data from etcd, it packages the requested information (Pod status, metadata, etc.) into a JSON or YAML response and sends it back to kubectl.
Example response (in JSON format):
code{
"kind": "PodList",
"apiVersion": "v1",
"items": [
{
"metadata": {
"name": "my-app-xyz",
"namespace": "default",
"labels": {
"app": "my-app"
}
},
"status": {
"phase": "Running",
"conditions": [
{
"type": "Ready",
"status": "True"
}
],
"containerStatuses": [
{
"name": "my-container",
"state": {
"running": {
"startedAt": "2024-11-09T00:00:00Z"
}
}
}
]
}
}
]
}
This JSON contains:
The list of Pods (
items), including metadata like name, namespace, and labels.The status of each Pod, including whether it is running, pending, or failed.
Container status that indicates the current state of the containers in the Pod.
7. kubectl Displays the Output
After receiving the response from the API Server, kubectl formats the data and displays it to the user.
- By default,
kubectldisplays a table format:
NAME READY STATUS RESTARTS AGE
my-app-xyz 1/1 Running 0 1d
If you specify an output format, such as
-o yamlor-o json,kubectlwill output the raw data in that format.kubectlcan also be used with options like-n <namespace>to query Pods in a specific namespace or--all-namespacesto query Pods across the entire cluster.
8. Final Output
The final output on your terminal will look something like:
NAME READY STATUS RESTARTS AGE
my-app-xyz 1/1 Running 0 5h
my-app-abc 1/1 Running 0 5h
This output shows the name, status, readiness, number of restarts, and age of the Pods.
Summary of the Workflow
Here’s a step-by-step summary of what happens when you run kubectl get pods:
kubectl sends an authenticated HTTP request to the API server to get information about Pods.
The API server authenticates and authorizes the request and queries the etcd store to fetch the current state of Pods.
The API server responds with Pod data (in JSON/YAML format).
kubectl formats and displays the data to the user.
Key Kubernetes Components Involved:
kubectl: The command-line interface that interacts with the cluster.
API server (kube-apiserver): The central control plane component that handles all REST API requests.
etcd: The distributed key-value store that holds the cluster's state.
RBAC: Ensures the user has permissions to access the requested resource (Pods).
Controller Manager: Ensures the cluster is maintaining the desired state (indirectly).
Scheduler: Ensures Pods are placed on the right nodes (indirectly).
Conclusion
In this blog, we’ve broken down the workflow behind the kubectl get pods command, highlighting how Kubernetes components like the API server, etcd, Controller Manager, and Scheduler work together to provide you with the current state of Pods in the cluster. While the command may seem simple, it triggers a series of steps that ensure you receive accurate and up-to-date information. Understanding this process gives you deeper insights into Kubernetes' inner workings, helping you better manage and troubleshoot your cluster.
For more insightful content on technology, AWS, and DevOps, make sure to follow me for the latest updates and tips. If you have any questions or need further assistance, feel free to reach out—I’m here to help!
Streamline, Deploy, Succeed-- Devops Made Simple!☺️
Subscribe to my newsletter
Read articles from Shubham Taware directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Shubham Taware
Shubham Taware
👨💻 Hi, I'm Shubham Taware, a Systems Engineer at Cognizant with a passion for all things DevOps. While my current role involves managing systems, I'm on an exciting journey to transition into a career in DevOps by honing my skills and expertise in this dynamic field. 🚀 I believe in the power of DevOps to streamline software development and operations, making the deployment process faster, more reliable, and efficient. Through my blog, I'm here to share my hands-on experiences, insights, and best practices in the DevOps realm as I work towards my career transition. 🔧 In my day-to-day work, I'm actively involved in implementing DevOps solutions, tackling real-world challenges, and automating processes to enhance software delivery. Whether it's CI/CD pipelines, containerization, infrastructure as code, or any other DevOps topic, I'm here to break it down, step by step. 📚 As a student, I'm continuously learning and experimenting, and I'm excited to document my progress and share the valuable lessons I gather along the way. I hope to inspire others who, like me, are looking to transition into the DevOps field and build a successful career in this exciting domain. 🌟 Join me on this journey as we explore the world of DevOps, one blog post at a time. Together, we can build a stronger foundation for successful software delivery and propel our careers forward in the exciting world of DevOps. 📧 If you have any questions, feedback, or topics you'd like me to cover, feel free to get in touch at shubhamtaware15@gmail.com. Let's learn, grow, and DevOps together!