A Comprehensive Look into Amazon S3 Storage Classes: Availability and Lifecycle Policies
 Rawad Hossain
Rawad HossainTable of contents

In this blog, we will deep dive into different storage classes in Amazon S3, their availability and Lifecycle Policy. We'll also see the transition flow of data among storage class and how objects can be placed under rules using Console, AWS CLI, or SDK. Click here to read blog on Amazon S3.
A brief intro to Amazon S3
Amazon S3, a simple storage service provided by AWS. It is an infinitely scalable, secure, and durable cloud storage service that lets you store and retrieve any amount of data at any time. One of its key features is that the cost is based on usage, without compromising on storage limits, availability, or backup capabilities. — From last blog
S3 storage services can be categorized into different Classes. These classes are configured for different use cases, optimizing cost, performance, and durability.
S3 Storage Classes
The Storage Classes provide high durability (99.999999999% or 11 9's) of objects across multiple Availability Zones (AZ). However, they vary in availability, latency, and costing based on consumption pattern.
Each S3 storage class is tailored for specific needs, whether it's for frequent access, storage archival, or data replication across regions. By choosing the right storage class, you can save on costs while still maintaining great performance and durability.
The storage classes and their details are as follows:
S3 Standard - General Purpose
S3 standard is used for frequently accessed data (e.g., web applications, dynamic sites, mobile apps)
Durability is the same across all storage classes, which is 99.999999999% (or 11 nines). However, availability is 99.99%, meaning it may be unavailable for about 53 minutes per year.
Low latency (millisecond access.), high throughput.
Highest Cost among other storage classes, but most suitable for high-access data like handling dynamic workloads and real-time analytics.
A real-life example can be Netflix, a streaming platform that can store movies and shows for frequent access by users.
S3 Standard-Infrequent Access (IA)
Suitable for data that is accessed occasionally, not frequently, but needs to be available immediately when accessed.
Availability is 99.9% with low latency
Storage cost is lower than S3 Standard
In case of disaster recovery or backups this storage class is used.
S3 One Zone-Infrequent Access (One Zone-IA)
Used when data can be recreated if lost and stored within a single AZ, also it does not require multiple AZ redundancy.
Availability is 99.5% and High durability (99.999999999%) within a single AZ, data is lost when AZ is destroyed
Cost is comparatively lower for infrequent data access
An example would be a small business storing logs or reports that can be recreated if lost.
S3 Glacier Instant Retrieval
This storage class is appropriate for archiving or backing up data that are accessed occasionally.
Can archive storage with milliseconds retrieval, which is great for accessing data once a quarter.
The minimum storage duration is 90 days, and the cost is cheaper than Standard-IA, with pricing similar to archival storage.
S3 Glacier Flexible Retrieval
Storage class for archiving data for long period of time which are infrequently accessed.
Retrieval Times are Expedited (1–5 minutes), Standard (3–5 hours), Bulk (5–12 hours). Minimum storage duration is of 90 days.
It is a cost optimized option, lower cost than Glacier Instant Retrieval.
S3 Glacier Deep Archive
This class is designed for data that are accessed rarely and for very long-term storage archiving.
Retrieval Times are Standard (12 hours), Bulk (48 hours). Minimum storage duration is of 180 days.
It has the lowest cost among all S3 storage classes.
A real-life example could be a university storing graduation records that are 20 years old.
S3 Intelligent Tiering
S3 Intelligent Tiering can automatically move objects between different storage classes based on data access patterns, optimizing costs.
It has little monthly monitoring and auto-tiering fee but no retrieval charges between tiers.
Some tiers of S3 Intelligent Tiering are shown in the picture.

An overview of the storage classes is shown in the picture below:

S3 Lifecycle Policies
When using Amazon S3, a key benefit is the ability to move objects (data) between storage classes based on needs and time periods. This helps to optimize performance and cost according to access patterns.
These automation of the movement of objects between storage classes according to some predefined rules is called Lifecycle Policies of S3. These policies can be initialized through AWS Management Console, AWS CLI, and SDK.
A Lifecycle Policy can have one or more rules, with each rule applying to a specific object. Rules can be created for certain prefix or object tags. These rules can move objects to different class or can delete it at a scheduled time.
Using AWS Management Console, you can navigate to Management Tab and select Lifecycle Rules to create rule and define actions there.
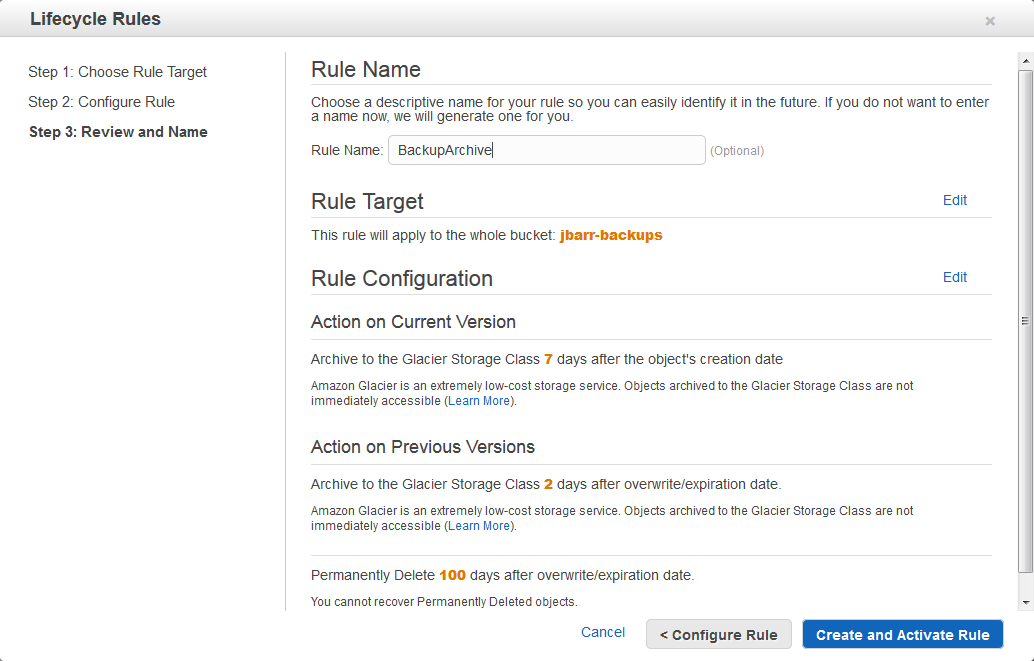
Using AWS CLI, you can directly update the storage class of object.
aws s3 cp s3://source-bucket/object-key s3://source-bucket/object-key --storage-class STANDARD_IA
This command copies an object within the same S3 bucket to itself, effectively updating its storage class to Standard-IA without changing its name or location.
Also, by using this JSON data, we can set policies and understand them better.
{
"Rules": [
{
"ID": "DemoRule",
"Filter": {
"Prefix": "logs/"
},
"Status": "Enabled",
"Transitions": [
{
"Days": 90,
"StorageClass": "GLACIER"
}
],
"Expiration": {
"Days": 365
}
}
]
}
Here, the rules for Lifecyle Policy are set such that it moves objects to S3 Glacier Flexible Retrieval after 90 days. And it is applied only to the objects with the prefix "logs/" which specifies that after 365 days of creation, object should be deleted from bucket.
Transition of Objects Between Storage Classes
To understand the flow to transition of data among different storage classes, we can have a look at the diagram below.
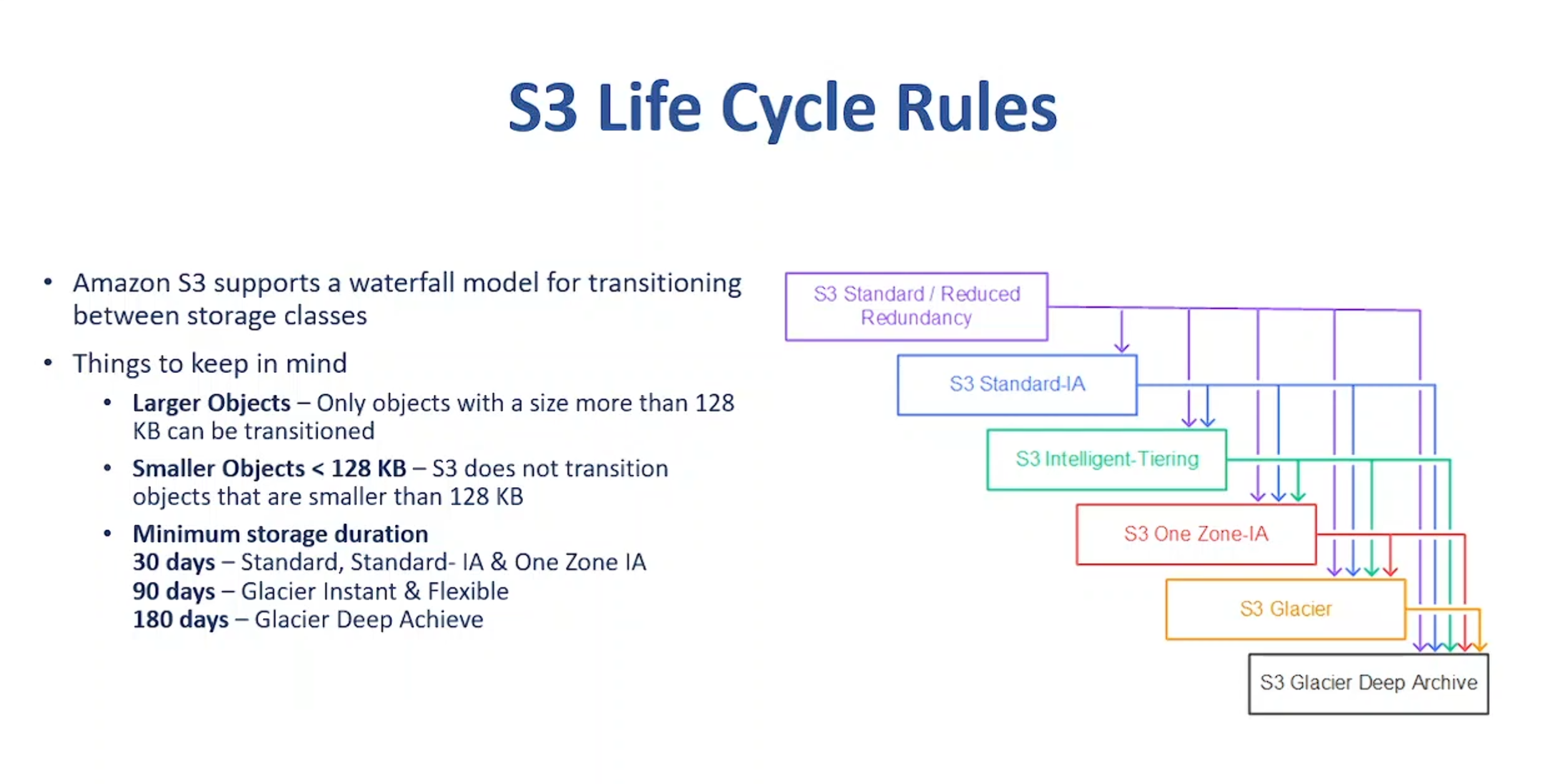
To understand the movement, we can see that data can shift from more expensive, frequently accessed classes to lower-cost, less accessible classes as it becomes less frequently accessed.
Moreover, objects (data) can skip few levels based on the policies set. For example, data can move directly from Standard to Glacier Deep Archive if the policy is set that way.
This updating of storage classes helps to optimize data that doesn't need to be accessed frequently, and objects can stay at a tier at lower cost for longer duration.
This is the end of this blog.
Subscribe to my newsletter
Read articles from Rawad Hossain directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by