Backend which Handle 1 Million Request
 Ankur saini
Ankur saini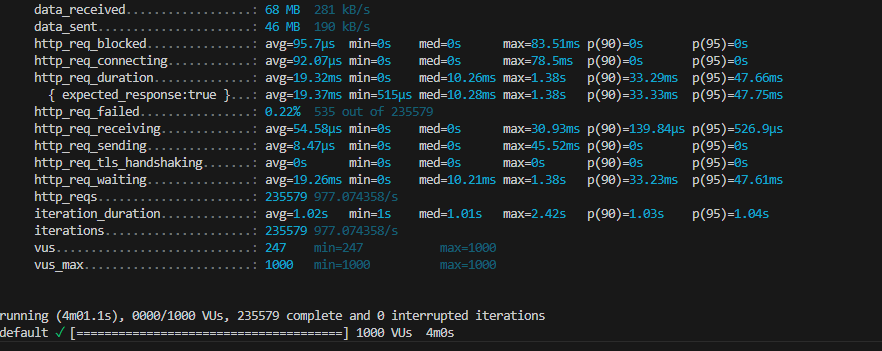
Source Code : https://github.com/AnkursainiRD/v2_EDA_Project
Every time when i saw these big tech giant’s severs i thought how could have they handle the millions of requests. I were very curious about that. So i started learning advanced backend. And then understand the various techniques which allow us to build a server which can handle million of request at a time.
1 . Usually in initial phase we build our project on Monolithic Architecture. Which is not bad approach. But as i thought if the project will become large and complex in future then it will become headache for developer to maintain all the code in single place.
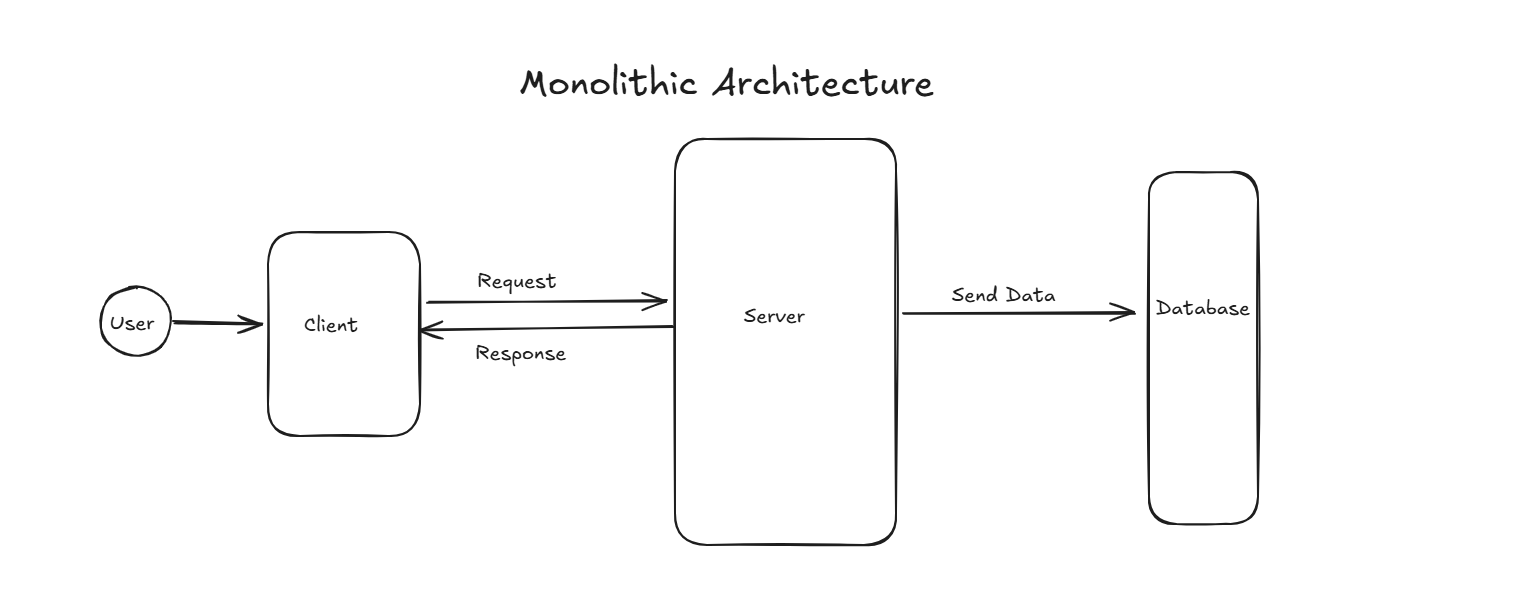
Pros : It is easy to debug cause all the code is running in a single server. When an application is built with one code base, it is easier to develop. One executable file or directory makes deployment easier.
Cons: If a line of code will face error then the server crash and whole server will shut down. Every time on deployment if deploy the whole code make more latency. Can’t scalable that much. Hard to handle so large code in single Repo.
————————————————————————————————————
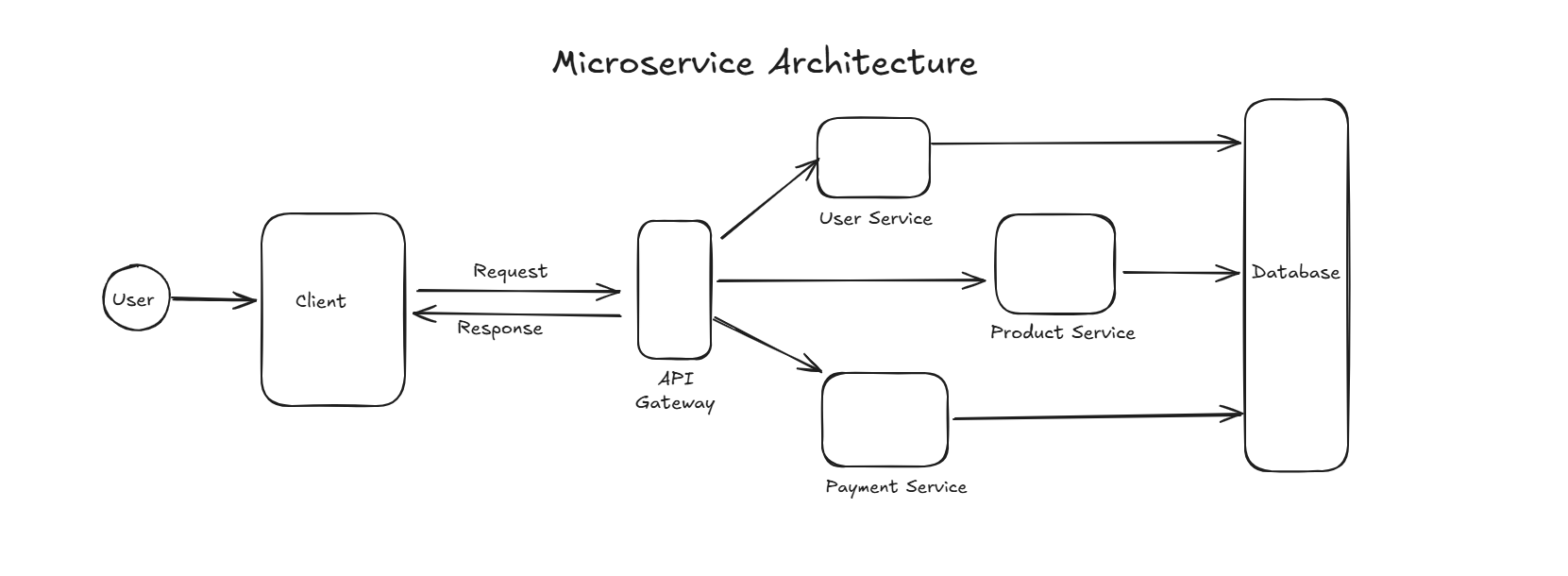
2 . One major approach is to follow Microservice Architecture. Where you created different different small server which handle some service. Like service 1 is handle User service, service 2 handle Payment service like that.
Pros: It is distributed so if one of server will crash then whole server won’t shut down. Easy to scale. You can scale particular service which is continuously getting multiple requests. Easy for developers to divide the task for each service.
Cons: As code is distributed so it will hard to debug the code in less time. Lack of standardization in code. If more service added in future then it will become highly coupled between microservices.
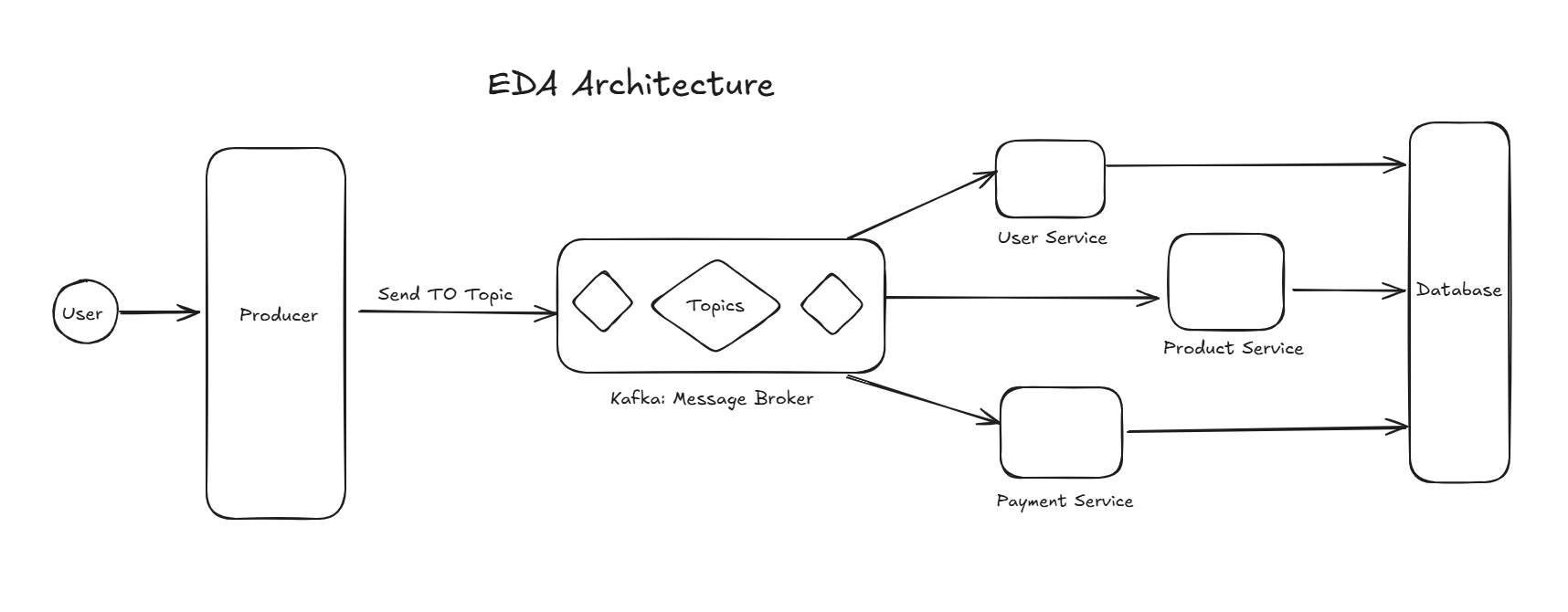
3 . So in Microservice also have some problem. Then a technique comes in picture called Event Driven Architecture. This approach is based of Microservice. But remove the problem of Congestion of Between Microservice. In this method we use a message broker for sending data from producer.
So we use Kafka cause its throughput is much much higher than database. So a producer create a Topic in Kafka and other services subscribe that topic. And once producer sent the data in the topic, subscribed service aka consumer get that data and store in database.
Also instead of sending data in database on every request, we can bundle them and make a Batch and then insert many in database. It will reduce the cost and also keep the load in DB less.
The code of this project where i successfully run 2.5 Lakh request in a minute is follow EDA architecture and you can checkout the code in my GitHub Repo. Link is given top of the blog.
Thank You for your time….
Subscribe to my newsletter
Read articles from Ankur saini directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Ankur saini
Ankur saini
Backend developer with a strong foundation in Node.js, Kafka, Redis, Docker, Kubernetes, AWS, and Django. Passionate about designing scalable, event-driven systems and optimizing backend performance for efficient cloud deployment