Hitting the Bullseye: How Bias and Variance Impact Your Model's accuracy?
 Abeer Mahmoud
Abeer Mahmoud
Imagine you're playing darts. You don't want to be a one-hit wonder who can only hit the bullseye when you've practiced on that exact spot. You want to be a pro who can nail it every time, no matter the dartboard. Statistical learning is the same. We want to build models that can predict the future, not just memorize the past. But how do we know if our model is a pro? We judge it like a dart game! The closer each prediction is to the real answer (the bullseye), the better. And for models that predict numbers, we use a special scorecard called Mean Squared Error (MSE) given by:
$$MSE = 1/n * Σ (yi - ŷi)²$$
$$yi=observed value$$
$$ŷi=predicted value$$
The equation for Mean Squared Error (MSE) represents the average of the squared differences between the actual and predicted values in your dataset.
Simply put, MSE measures how close your predictions are to the actual values:
Small MSE: Your model's predictions are on target! 🎯
Large MSE: Your model missed the mark. ❌
MSE is calculated from the training data set and is called training MSE
However, the true test of a model's performance lies in its ability to predict new, unseen data (test data). That's what we really care about – how well the model generalizes to real-world scenarios, not just the examples it's already seen.
Suppose we have a dataset containing clinical data for a number of patients, including variables such as cholesterol levels, body mass index (BMI), smoking status, physical activity level, diet, and genetic predisposition to heart disease. Additionally, we have information on whether each patient has developed heart disease. We can use this dataset to train a statistical learning model to predict the risk of developing heart disease based on these clinical variables. In practice, our goal is to have this model accurately predict heart disease risk for future patients based on their clinical data. We are not primarily concerned with how well the model predicts heart disease risk for the patients used to train the model, as we already know which of those patients have developed heart disease.
We want to choose the method that gives the lowest test MSE, as opposed to the lowest training MSE.
How do we pick the best prediction method, the one that will be most accurate on new, unseen data?
Ideally, we'd have a separate set of data (test data) that we didn't use for training our model. We could then test the model on this new data and choose the method that performs best.
But what if we don't have extra data? It might seem intuitive to pick the method that works best on the training data itself (lowest training MSE). However, this can be misleading.
Just because a model excels on the training data (low training MSE) doesn't mean it will perform equally well on new, unseen data (low test MSE). This is because many statistical methods are designed to specifically minimize the error on the training data.
Think of it like studying for a test by memorizing the answers to practice questions. You might ace the practice test, but that doesn't guarantee you'll do well on the actual exam with new questions. Similarly, a model that's too focused on minimizing training error might not be able to generalize to new situations, leading to a higher test MSE.
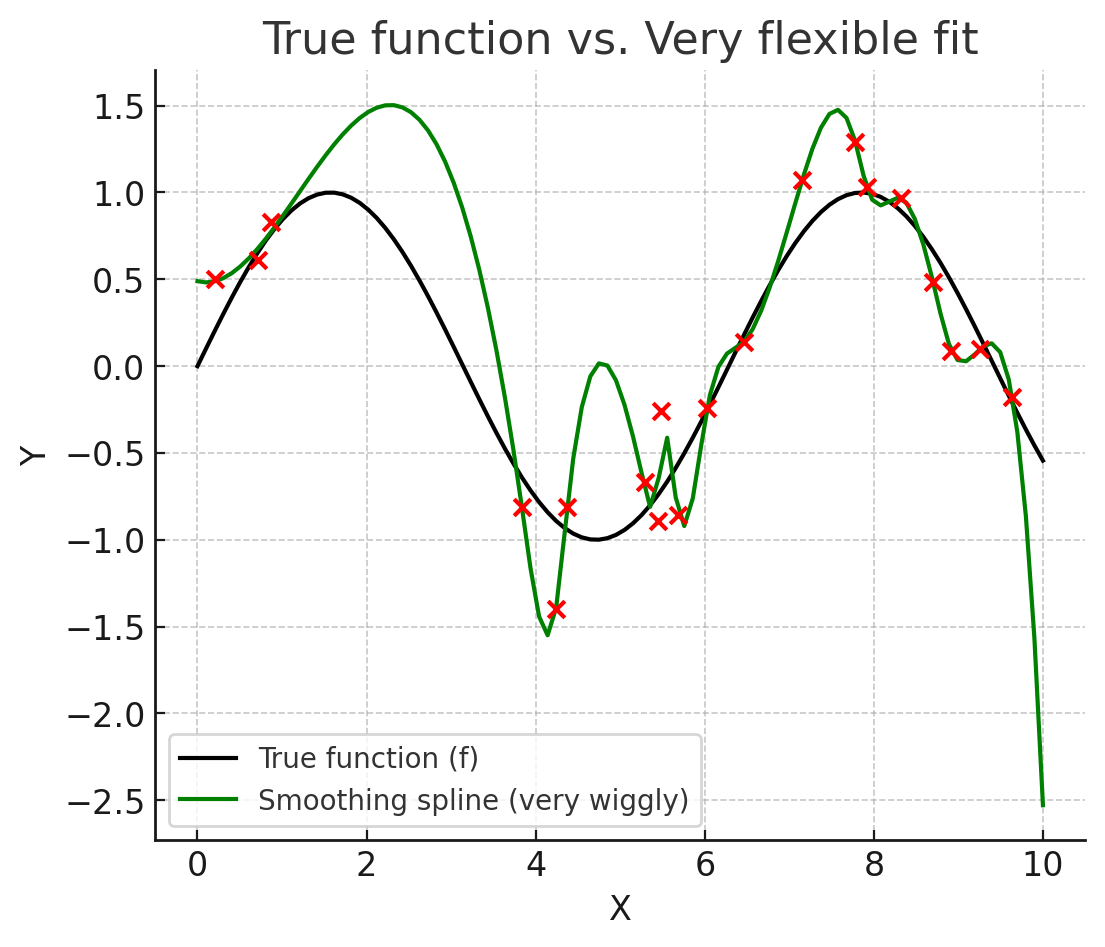
Image is generated by chatgpt
It is clear that as the level of flexibility increases(more degrees of freedom), the curves fit the observed data more closely,but because it is so wiggly it doesn’t capture the true function.so it has a low training MSE, but the test MSE may not. When a method produces a small training MSE but a large test MSE, we are said to be overfitting the data.
Bias variance trade off:
The test MSE for a given value x0 can always be broken down into three components: the variance , the squared bias , and the variance of the error.:
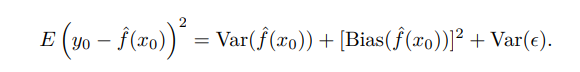
Credit : An Introduction to Statistical Learning by Gareth James, Daniela Witten, Trevor Hastie, Robert Tibshirani
The equation indicates that to minimize the expected test error, we must choose a statistical learning method that achieves both low variance and low bias.
Because variance and squared bias are always nonnegative, the sum of these components with the variance of the error (Var(ϵ)) ensures that the expected test MSE cannot be less than Var(ϵ), the irreducible error.
Bias represents the error that comes from making overly simplistic assumptions in a model when trying to solve a complex real-life problem. For instance, linear regression assumes a straight-line relationship between the variables Y and X1, X2, ..., Xp. In reality, such a simple relationship is rare, so using linear regression will introduce some bias in estimating f.
- Imagine a dart game where you always throw the darts in a consistent pattern, but that pattern is off-center from the bullseye. This means you're always missing the target by the same amount. High bias means your throws (predictions) are consistently off in the same way, causing a systematic error.
Variance:
Variance represents the error that arises from a model's complexity and its sensitivity to small changes in the training data. It indicates how much f^ would vary if we used a different training data set. Generally, more flexible statistical methods tend to have higher variance.
In a dart game, imagine your throws are scattered all over the target—sometimes close to the bullseye, sometimes far away, with no consistent pattern. High variance means your throws (predictions) vary widely, leading to inconsistencies.
Typically, as we use more flexible methods, the variance increases while the bias decreases. The relative rate of change between these two quantities determines whether the test MSE increases or decreases.
Optimal Tradeoff:
Ideally, you want a balance where your darts are reasonably close to the bullseye and are also grouped together.
- This means finding a model that is just right—not too simple (low bias) and not too complex (low variance).
Subscribe to my newsletter
Read articles from Abeer Mahmoud directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by