ML Chapter 7: Natural Language Processing
 Fatima Jannet
Fatima JannetTable of contents
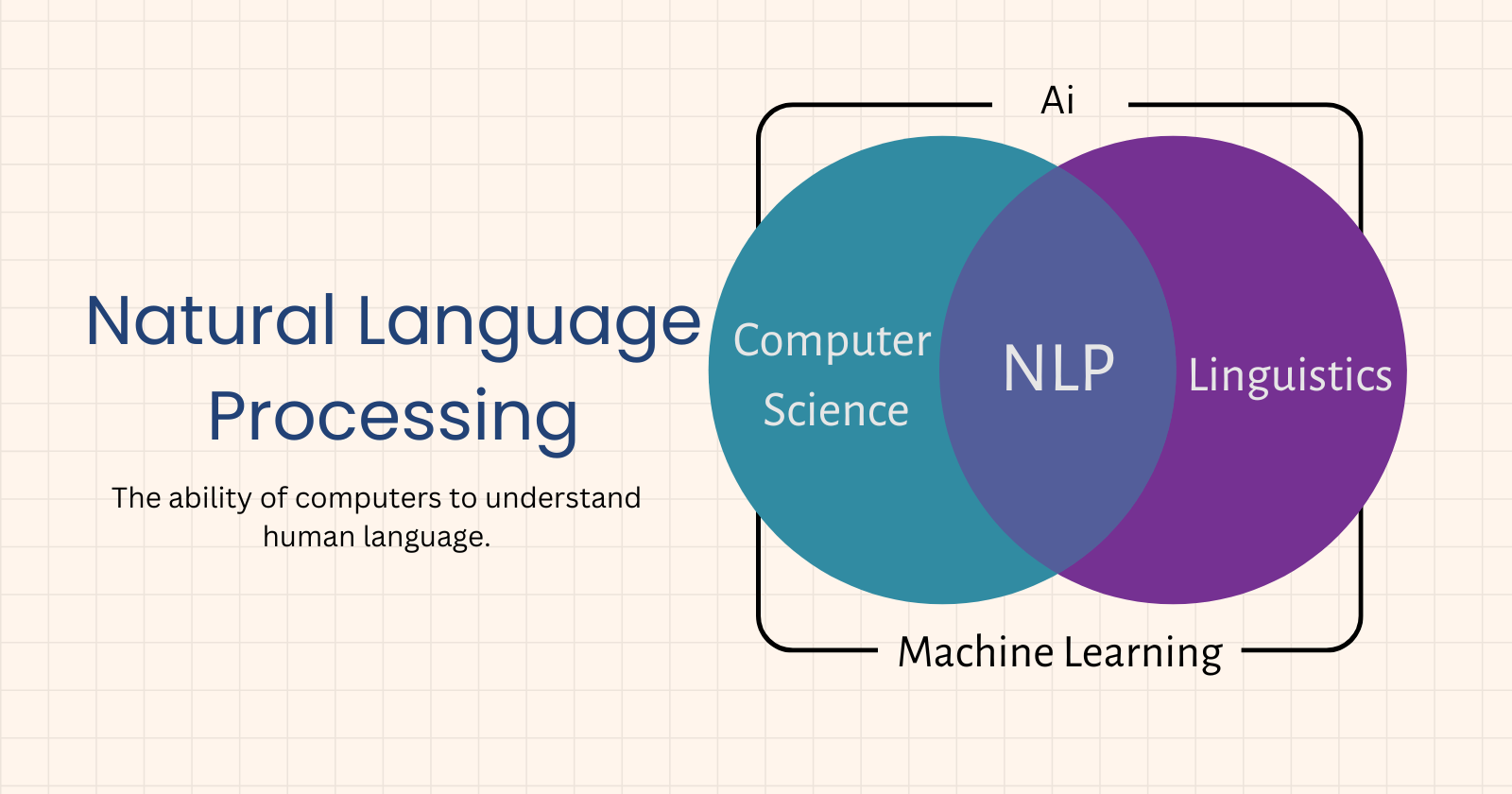
Natural Language Processing (NLP) involves using machine learning models to work with text and language. The goal of NLP is to teach machines to understand spoken and written words. For example, when you dictate something into your iPhone or Android device and it converts your speech to text, that's an NLP algorithm at work.
You can also use NLP to analyze a text review and predict whether it's positive or negative. NLP can categorize articles or determine the genre of a book. It can even be used to create machine translators or speech recognition systems. In these cases, classification algorithms help identify the language. Most NLP algorithms are classification models, including Logistic Regression, Naive Bayes, CART (a decision tree model), Maximum Entropy (also related to decision trees), and Hidden Markov Models (based on Markov processes).
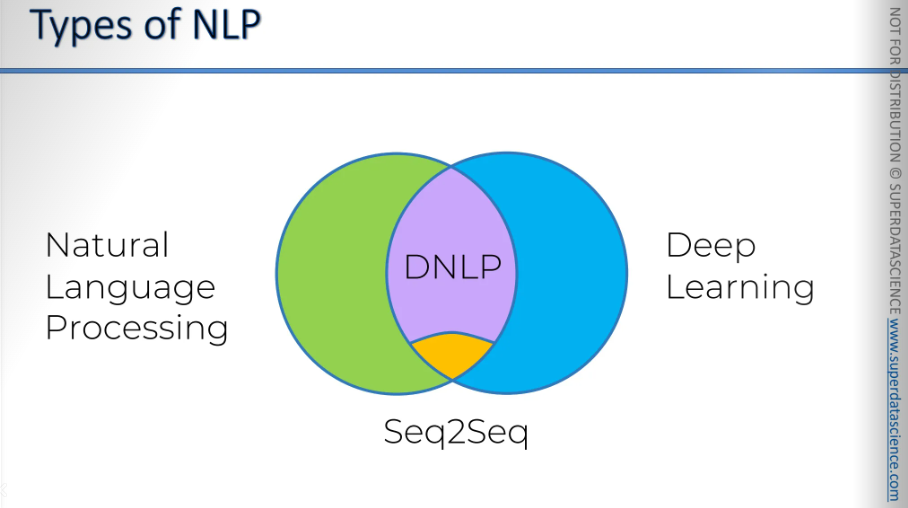
Small insight before starting: On the left of the Venn diagram, we have green representing NLP. On the right, we have blue representing DL. In the intersection, we have DNLP. There's a subsection of DNLP called Seq2Seq. Sequence to sequence is currently the most cutting-edge and powerful model for NLP. However, we won't discuss seq2seq in this blog. We will be covering basically the bag-of-words classification.
In this part, you will understand and learn how to:
Clean text to prepare it for machine learning models.
Create a Bag of Words model.
Apply machine learning models to this Bag of Words model.
Here’s what we will be focusing on. Note: We will not discuss Seq2Seq, chatbots, or deep NLP. The materials I have used are from NLP with DL, so we will exclude the DL part.

Bag-Of-Words Model
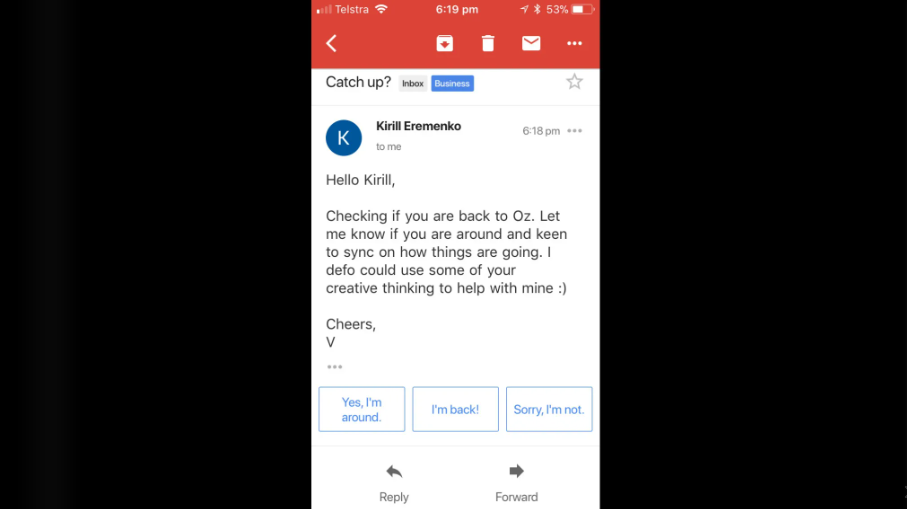
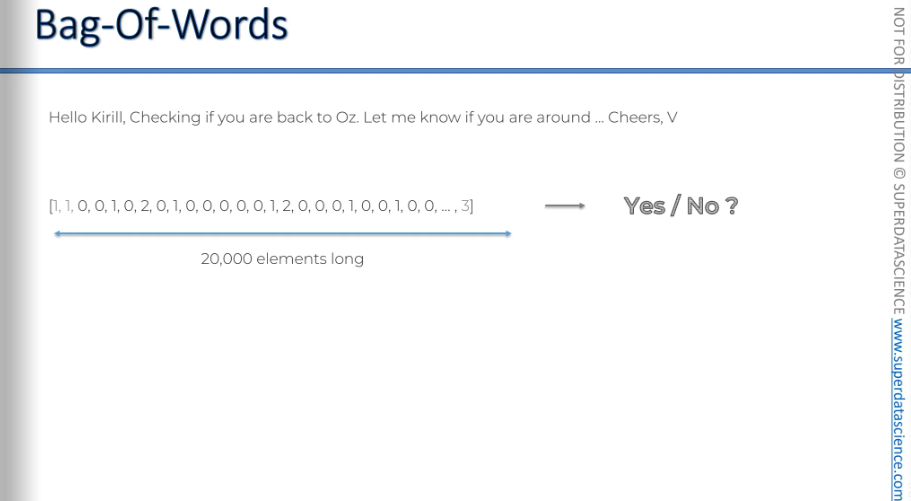
Before starting, I would like you to look at this email. Let’s say I’m Kiril, and my friend send me a catch-up email.
Okay so the interesting part is, we are going to see how we can apply NLP to this email. As you can see, the email is giving me some suggestions, right? It’s suggesting me some quick replies. Okay, we will come back to this later. Let’s focus on another thing: We will create a model that will give us a YES/NO response.
Okay, we are gonna start off with a vector. Vector or, an array with zeros, 20k zeroes in total. 20,000 is the number of words commonly used by an average native English speaker (you can see the google reference here)
What I wanted to point out is: How many words are there in the English language? Even this, on its own, is actually Google applying natural language processing. It's analyzing what we wrote and checking other similar answers.
"How many words does the average person know in the English language?"
That's not the question I asked, but it came up with that. Then it suggested many other questions. So you can see the irony here. Even in this search, we're already using natural language processing, even though that wasn't our intention. That's not what we're going to discuss. But it's amusing that it happened.
Anyway, 20,000 words. Oxford English Dictionary has 171,476 words and out of these we only use about 3,000 words. So it’s guaranteed that our array of 20k zeroes will definitely cover all the words. So every English word has a position somewhere in our vector. For example, "if" might be in the 7th position, "badminton" could be in another position, and "table" could be in yet another position—but their positions remain fixed.

Here, I've grayed out the first two and the last one. The first two are reserved for SOS (start of sentence) and EOS (end of sentence). The last one is for special words. Any kind of word we can’t recognize, we’ll throw them into the last element.

Now, its time for the email: We gonna check how the email fits into the bag of words. As you might have guessed, the vector with 20k words is basically our bag of words. I'm just gonna throw the words in it.
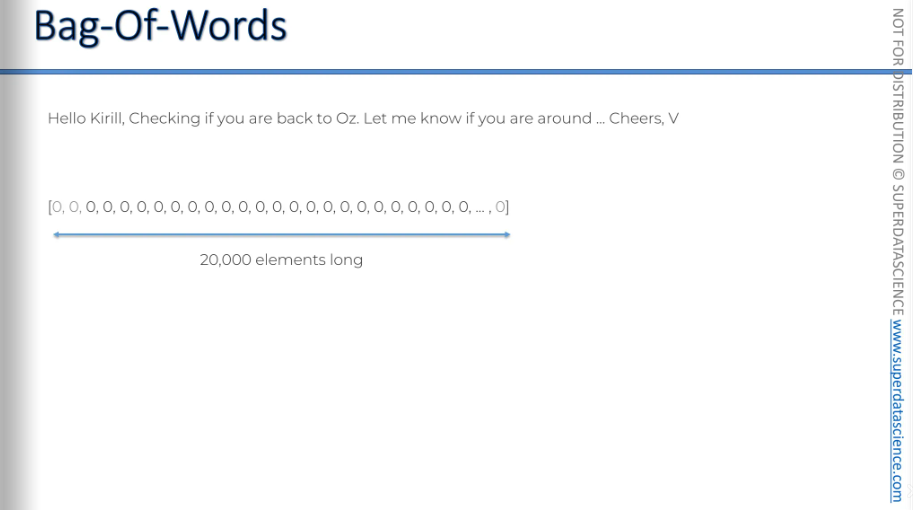
This is our result: we took the 20,000 words and assigned each position to a word. Now, we go through our text, find each word, and then increase the counter in the position associated with that word.
"hello" is in position number five in our vector.
- We have one "hello" in the email, so we put a one here.
"Kirill" is not an English word, so it goes into the last element.
- The last element is three because 'Kirill', 'Oz', and 'V' are not English words.
The comma has a position.
There are two commas, let's forget about that comma.
I didn't notice it, sorry. So this is a 1 for comma.
"Checking" is associated with an element in the vector.
- We have one "checking", so this is a one.
"If" is a two because we have two "if"s in the email.
"You" is a two because we have two "you"s in the email, including the rest of the text.
I don't think there's any more used in there. And so on. That's how we fill this bag of words, by counting words for each position. It's straightforward. We're filling in this vector, which will be quite sparse, with almost 20,000 zeros.

So, regarding our goal, it was to create a YES/NO response that works with the email. We will do it through training data.
So we're going to look at all the emails I have replied to, which will serve as our training data. Let’s look at couple of replies:
"Hey mate. Have you read about Hinton's capsule networks?" → NO
"Did you like that recipe I sent you last week?" → YES
"Hi Kirill, are you coming to dinner tonight?" → YES
…. ……… …….
And so on. Honestly, if we filter out in this way we will find thousand of YES/NO replies. However, how we gonna use this training data?
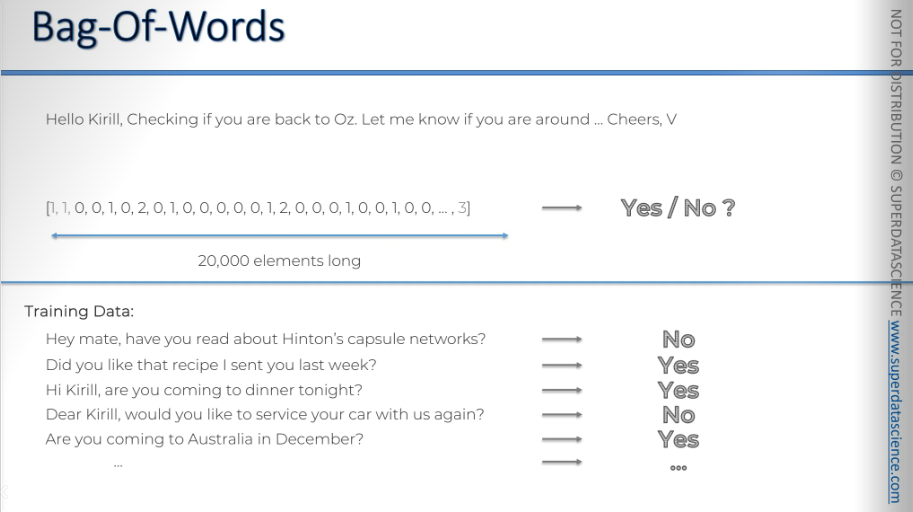
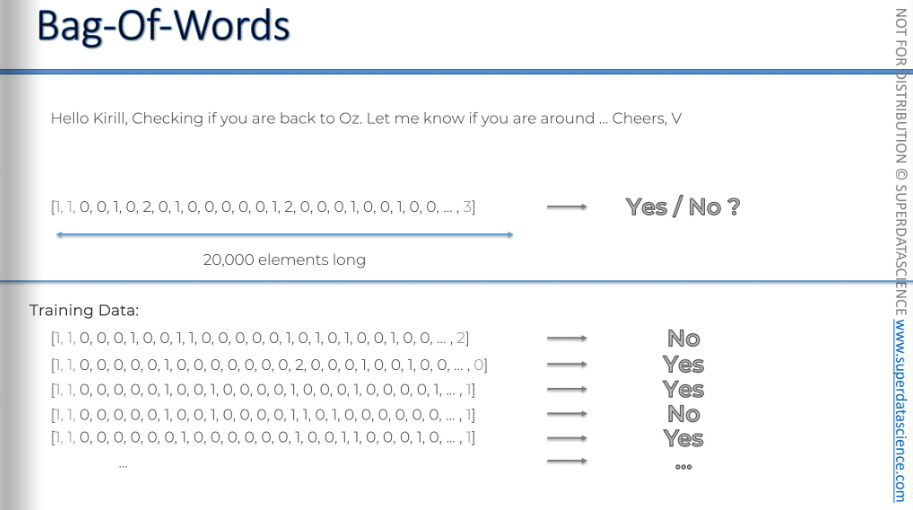
Well, we’ll simply turn each of the emails into a vector or, bag of words. Once we have all the data, we will apply a model.
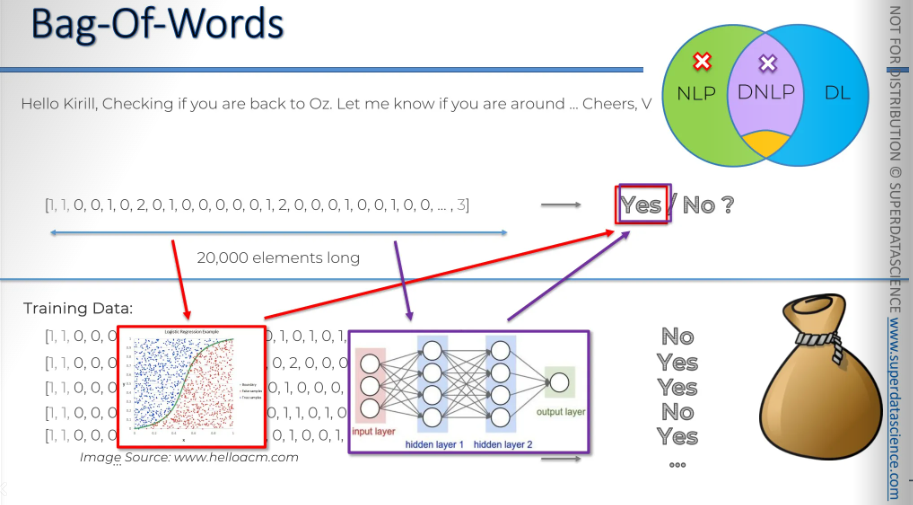
One of the models or algorithms we can use to create our bag of words model is logistic regression. We will apply logistic regression to our yes-no responses. After that, we should be able to determine what will be a YES and what will be a NO, and find the boundary between them. Then, we can input the actual email we receive into this model and get a response and that’s it!
The other approach that we can take here, oh before that! let's put this on our Venn diagram.
Another approach we could use here, instead of logistic regression, is a neural network. We have a vector, right? We could make them the input layer of our neural network, with over 20,000 neurons. It would pass through one hidden layer, two hidden layers, or as many as we want, depending on how we decide to structure it. Then, bam! we have an output layer that tells us YES or NO.
Once again, we would use all the data we have here—all our millions of emails and responses—to train our neural network. Through backpropagation and stochastic gradient descent, all the weights would be updated, and then, we would have an answer. We have a neural network which is all trained up. Then we will feed the network our vector and Voila, we get our answer.
So we got to know about two cases here:
NLP bag of words
Deep NLP bag of words.
Both of them has their our limitations and issues. But hopefully it won’t occur as we are just building a simple YES/NO response. If we were to build a chatbot here (which we can’t) than that would be something to discuss about.
However, as i mentioned - we won’t enter into deep learning.
NLP in Python
This is the branch of machine learning that allows you to build chatbots and machine translations. Of course, that's not what we're going to do in this part, as this involves really advanced NLP.
We'll just cover the basics with sentiment analysis, which involves training a machine to understand some text and predict a certain outcome for these texts.
Find code and datasheet: Machine Learning Repo
About the datasheet: In our case study, we'll use restaurant reviews as our texts. We'll train a machine to determine whether each review is positive or negative. It's a simple and classic approach, but it's the best way to get introduced to NLP.
Why use classification models? Because we will predict a binary outcome: positive review → 1, negative review → 0. Also, this time, the datasheet type is not a CSV(comma separate value), but a TSV(tab separate value) dataset.
Importing the libraries
Copy and paste from the data preprocessing template.
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
Importing the dataset
dataset = pd.read_csv('Restaurant_Reviews.tsv', delimiter = '\t', quoting = 3)
First, we need to clean the dataset. Then, we will create two features: a matrix of features and a dependent variable.
Since it is a TSV file, we'll need to add some extra parameters to specify that we are indeed dealing with a TSV file instead of a comma-separated value (CSV) file.
delimiter: For which the default value is a comma, meaning the default dataset we import withread_CSVis CSV. However, we can also useread_CSVto import a TSV file.The way to specify a TSV file is to use
'\t'.quoting: A very important param while dealing with text. Our texts may have double or single quotes. To process them correctly, we must instruct our model to ignore double quotes. Otherwise, this can cause processing errors.I recommend adding the quoting parameter and setting its value to 3 to ignore quotes and avoid processing errors.
That's how you correctly import a TSV file, which is the format for a dataset separating text and a binary outcome like 0 or 1. This is the classic method for sentiment analysis.
Cleaning the texts
Are you ready to do some cleaning? Because now we're about to do a deep cleaning of the text.
We'll remove punctuation, non-letter characters, and standardize capitalization. This simplification is crucial for natural language processing. Cleaning the text helps our machine learning model learn better, understand the reviews, and predict if they are positive or negative. Let's get started.
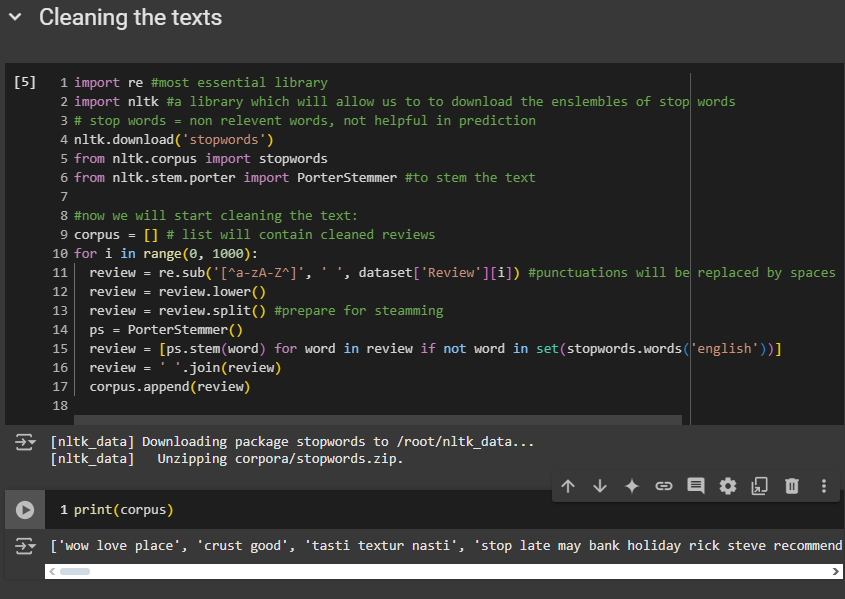
nltklibrary lets us download stop words, which are words we don't want in our reviews after cleaning, like "the", "er", "end". These words don't help in predicting if a review is positive or negative.corpus module : will import the stop words we downloaded.
stem module: we're going to import the
PorterStemmerclass. Stemming involves taking the root of a word to convey its meaning. For example, in a review saying, "Oh, I loved this restaurant," stemming changes "loved" to "love" to simplify the review. Whether it's "loved" or "love," the meaning is the same, indicating a positive review. We remove verb conjugations, keeping only the present tense to simplify reviews.Cleaning steps:
Remove all punctuations.
'[^a-zA-Z^]', ' ': Things that won't get replaced will stay inside the brackets. Everything else will be replaced by whatever is in the second parameter, which in our case is a 'space'.dataset['Review'][i]: Name of the first column where we want to perform the replacement. You can also useilocand and then specifying the index 0 (if you wish)transform all the capital letters into lowercase.
We apply stemming to each word in the review after splitting it into separate words.
Review is now a list of different words.
Omitting: If the review word isn't in the set of English stop words, we'll apply stemming. If it is, we won't include it or apply stemming, so it won't be in the future sparse matrix.
Now the question is how do we apply the stemming?
Calling our object
ps, we will use the stem method. Inside the parentheses, we will place the word we want to apply stemming to.Now we update the review by joining these words back together to form the original format of the review as a string.
Append each cleaned reviews in the corpus list.
Use
print(corpus)to see the reviews after the cleaning process.
But, our 2nd review says “the crust is not good”. “Not” definitely is a negative word. But in out output we see “crust good”. So we need to do some extra work on our code.
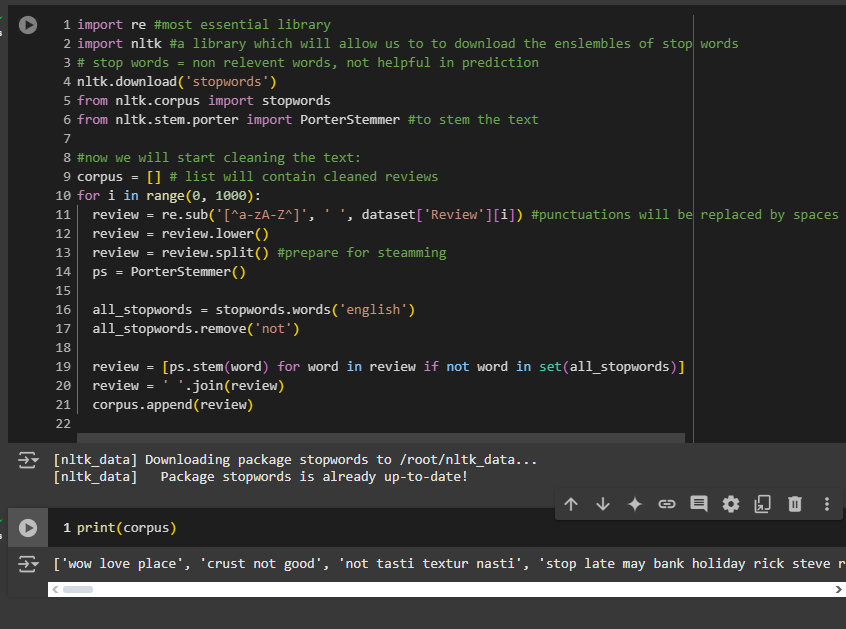
Now it’s all good. Changes made in line 16-19.
Creating the Bag of Words model
Now let's proceed with tokenization to create a sparse matrix. This matrix will have all the reviews in different rows and all the words from the reviews in different columns. Each cell will have a one if the word is in the review and a zero if it is not.
We still have some words that won't help predict whether a review is positive or negative. To remove them, we have to take the most frequent words. To do this, we need to set a parameter inside CountVectorizer() and choose a maximum size for the sparse matrix. However, we don't know how many words there are, so we will create our dependent and independent variable Then we will be able to figure out how many columns are there
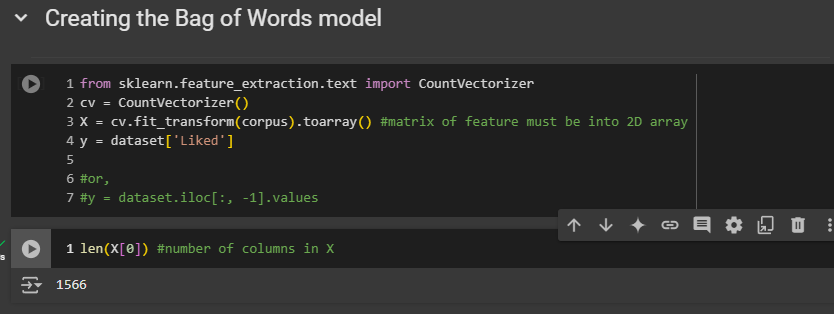
[Remember that the first index here in the pair of square brackets corresponds to index of the row]
Okay, we have 1,566 words taken from all the reviews. We can simplify this by selecting the 1,500 most frequent words. This way, we can remove words like Rick, Steve, holiday, or faux, which might not be useful. Words like rubber probably appear only once and don't help predict if the review is positive or negative. So, the idea is to focus on the 1,500 most frequent words.
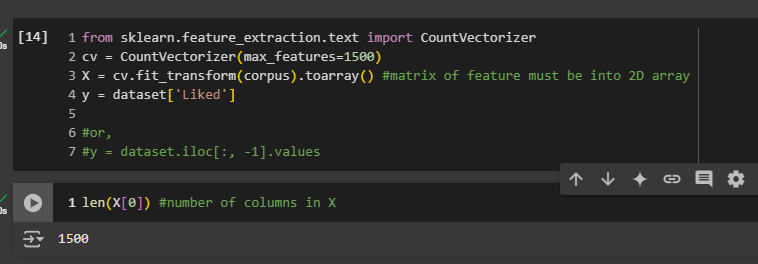
Now we have a nice bag of words with only relevant words!
Splitting the dataset into the Training set and Test set
Training the Naive Bayes model on the Training set
[Just a reminder, the choice of Naive Bayes was based on my experience. I've noticed it performs well with natural language processing problems]
Predicting the Test set results
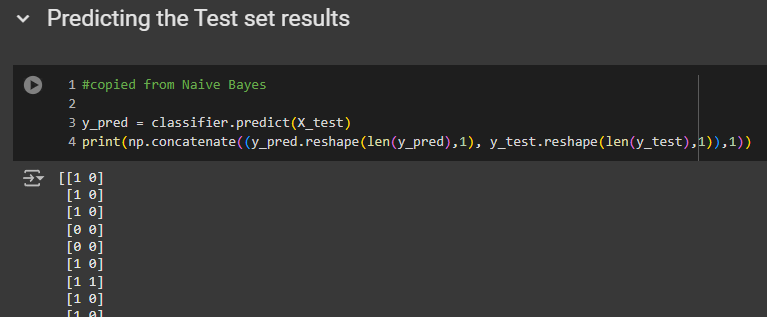
For the first review in the test set, our model predicted it to be positive, but it is actually negative. The same goes for the second review, predicted as positive, but it is negative. The third review was also predicted as positive, but it is negative. The next one, however, is correct.
Scrolling down, we can see that we actually have many correct predictions. We'll check this right away with our confusion matrix below.
Making the Confusion Matrix
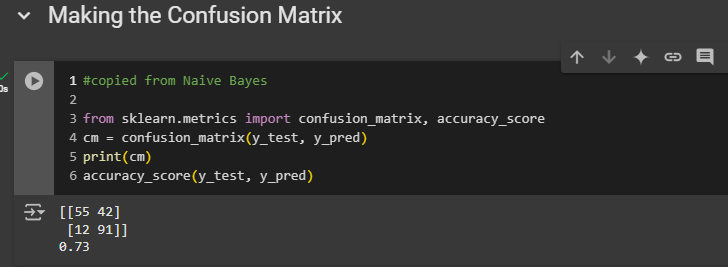
So, this is our last cell. The final accuracy is 73%, which is pretty good, but I'm sure we can improve it by experimenting with more classification models or by cleaning the text better. For example, we excluded "not" from the list of stop words, but maybe we should also exclude "isn't." I know "isn't" is actually part of the stop words list. So, you can do some extra work to improve this because I'm sure we can achieve better accuracy than 73%. Still, this is pretty good.
55 correct predictions of negative reviews
91 correct predictions of positive reviews
42 incorrect predictions of positive reviews
12 incorrect predictions of negative reviews
Try to reduce the number 42 and 12.
There you go! We finished it! We actually trained a machine to understand English which was impossible quite a few years ago! So congrats! See you in the next blog
Subscribe to my newsletter
Read articles from Fatima Jannet directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by