Understanding CQRS and Event Sourcing: A Path to More Robust Distributed Systems
 Siddhartha S
Siddhartha S
Introduction
Distributed systems are all the rage these days! With system design gaining traction in the software world, everyone is eager to learn and implement distributed systems. They (Distributed Systems) undoubtedly have their merits and provide viable solutions to many of the challenges modern software faces. However, they come with a few caveats.
While numerous tools and products are offered by most cloud providers to help tackle these challenges, it’s essential for developers to be aware of the hurdles. After all, orchestrating independent, separate pieces of software to function seamlessly as one giant unit is no easy task. But don't worry; we’ll explore this together!
In this article, we'll focus on a well-established distributed pattern known as Command Query Responsibility Segregation (CQRS) and combine it with Event Sourcing to make it even more relevant. Please remember that these are two distinct patterns that, while often used together, remain independent of one another.
I’ve kept this article approachable and jargon-light, so let’s settle in for some quality time! Grab a coffee (or your favorite drink) as we dive into the design and implementation of a complete CQRS-Event Sourcing system with tools like Kafka, MongoDB, and PostgreSQL, and for added flair, we’ll build a Next.js frontend. Though we’ll be working in .NET, the concepts are relevant and useful for any backend developer.
CQRS
Now that we know CQRS stands for Command Query Responsibility Segregation, let's take a quick look at what it is and why it’s beneficial.
What is CQRS and Why Do We Need It?
CQRS is a design pattern that allows us to separate the read operations of our domain entities from the write operations. This separation enables us to independently scale the reading operations separate from writing. If you’ve been exploring distributed system designs for a while, you may already be familiar with the famous Tiny URL system design question. It states that once a URL is generated (written), it is read at least 100 times. Thus, the read-to-write ratio for a domain entity (the tiny URL, in this case) is 1:100.
Doesn’t it make sense to separate the read and write functionalities so that we can scale the reading independently while maintaining lower infrastructure costs for writing? This is a classic case for CQRS, and trust me, a lot of the software we build today revolves around this concept.
Let’s illustrate this with a straightforward example: customers and orders.
Info: A customer can be created, and a customer can place many orders.
If I were to design the database schema for storing this data, I would create the following two tables:
Customers Table:
+--------------+-----------------+----------------+----------+
| CustomerId | Name | Email | Phone |
+--------------+-----------------+----------------+----------+
| 1 | Alice Smith | alice@email.com| 123-4567 |
| 2 | Bob Johnson | bob@email.com | 234-5678 |
| 3 | Carol Davis | carol@email.com| 345-6789 |
+--------------+-----------------+----------------+----------+
Orders Table:
| OrderId | CustomerId | OrderDate | Amount |
+----------+--------------+--------------------+--------+
| 101 | 1 | 2024-05-01 | 150.00 |
| 102 | 1 | 2024-05-03 | 200.00 |
| 103 | 2 | 2024-05-02 | 300.00 |
| 104 | 3 | 2024-05-04 | 120.00 |
| 105 | 1 | 2024-05-05 | 50.00 |
+----------+--------------+--------------------+--------+
In this schema, the CustomerId from the Customers table serves as a foreign key in the Orders table.
For the requirements listed in the left column of the following table, we will perform the corresponding operations mentioned in the right column:
| Requirement | Operation |
| Add a customer | Add the entry in the Customers Table |
| A customer places an order | Add entry in the Orders Table with the Customer ID |
| Generate reports for purchases between specified dates | Join the Orders table with the Customers table to obtain information |
| Generate reports for daily purchases | Join the Orders table with the Customers table to obtain information |
This approach works well for a small store application with a limited customer base.
But what happens when we move to larger stores that cater to countless customers and want to leverage purchase orders to uncover meaningful patterns? These larger enterprises will require various analytical tools to gather data for multiple analyses. Here are a few examples:
What were the total sales for each month over the last year, categorized by customer segment? [Sales Performance]
Which customer segments have the highest purchase amounts and frequency of orders? [Customer Segmentation]
What are the top five products sold by order count and total revenue for the last quarter? [Product Performance]
What percentage of customers made repeat purchases in the last six months? [Customer Retention]
What is the average time taken to fulfill orders for each customer segment? [Supply Chain Assessment]
How did customer orders change during and after the last promotional campaign? [Marketing Analysis]
What revenue is generated from different regions, and how does it compare to customer demographics? [Geographic Analysis]
There can be numerous use cases requiring data from the databases above. Some of these services will also need real-time data. Just imagine the number of joins your database will have to perform!
So, we have a problem. Our database is normalized, making it well-suited for OLTP (Online Transaction Processing). However, this database would struggle under the demands of our analytical processes.
Solution
The solution is to break operations into two distinct flows and utilize two databases. These databases will have replicated data but distinct schemas. While write operations can continue feeding data into the previous schema (OLTP), we can have another database designed with a read-friendly schema for the OLAP (Online Analytical Processing) flow.
Thus, the same data captured in the earlier case would now be organized like this:
CustomerOrders Table
+--------------+-----------------+----------------+----------+------------+--------+
| CustomerId | Name | Email | OrderId | OrderDate | Amount |
+--------------+-----------------+----------------+----------+------------+--------+
| 1 | Alice Smith | alice@email.com| 101 | 2024-05-01 | 150.00 |
| 1 | Alice Smith | alice@email.com| 102 | 2024-05-03 | 200.00 |
| 2 | Bob Johnson | bob@email.com | 103 | 2024-05-02 | 300.00 |
| 3 | Carol Davis | carol@email.com| 104 | 2024-05-04 | 120.00 |
| 1 | Alice Smith | alice@email.com| 105 | 2024-05-05 | 50.00 |
+--------------+-----------------+----------------+----------+------------+--------+
If you notice, while the above table schema may not be normalised, it eliminates the need for joins for read operations!
Here is a rough diagram of what we discussed so far:
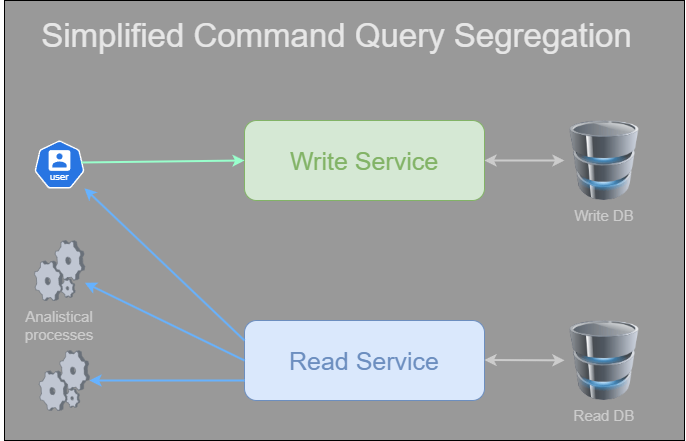
You might argue that storing duplicate data is wasteful, but I would counter that data storage has never been as cost-effective as it is today! Investing in extra storage saves a great deal of computational costs and minimizes the risk of database failure.
Pros and Cons of CQRS
Pros:
Separation of concerns. Separate read and write models. Enable both flows to grow independently.
Scalability increases.
Improved security. Read and Write operations are separate flows so it's easy to implement selective security.
Cons:
Increased complexity.
Data consistency issues as the read and write databases should be in sync always.
Data duplication. (But we already countered that, didn’t we?)
Not for small systems.
By the way, if you’ve followed along, you now have a solid understanding of CQRS! We have successfully segregated the responsibilities of Command (Write) and Query (Read). How cool is that!
Event Sourcing
Let's start with a clean slate! Understanding Event Sourcing is straightforward if you are already familiar with the State Pattern. The State Pattern is a behavioral design pattern that maintains the current state of an entity based on the actions taken on it.
In Event Sourcing, whenever we perform an action on any object, we essentially raise an event for that object. This pattern revolves around storing these events in what we call an event store. The final state of that object is then the aggregate of all those events.
Example: Bank Account
Let's illustrate this with an example: imagine a bank account as an entity that supports the following events:
Created: The account is opened when you walk into the bank and create it, receiving an account ID.
Deposit: You deposit money into the account.
Withdraw: You withdraw money from the account.
Closed: You close the account.
Consider the following time series of events over the account's lifespan, which spans a year:

Clearly, various events are recorded throughout the life of the account. Now, if storing an updated balance seems simpler, why not just maintain the balance directly?
During account closure, when a customer requests the available balance (let's say $300), one might think it could simply be stored in our banking system. However, that’s not how customers expect it to work! Banks, and many systems, require a log of all transactions to ensure complete transparency from creation to closure. This audit trail is essential for both customers and banks.
The bank records all transactions on the account for audit purposes and can aggregate them to derive the final balance at any given moment. For example, if I query the banking system to provide the balance as of May 28th 2023, the system will replay all the events from creation:
Starting balance: $0
+$500 (Deposit)
-$200 (Withdrawal)
-$100 (Withdrawal)
+$100 (Deposit) = $300.
In summary, Event Sourcing involves recording events for an entity in an event store. Whenever the state of the object is needed for a specific point in time, all relevant events can be replayed from the beginning to arrive at the entity's final state.
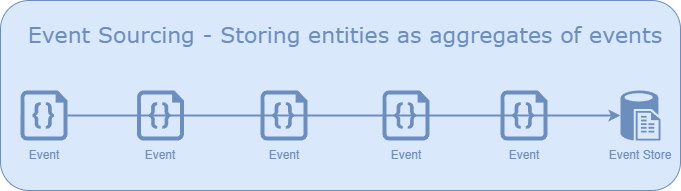
Now, let’s reconsider the definition of the entity. If the entity’s state is an aggregate of the events, why not refer to it as an aggregate? Indeed, we can redefine a bank account as an aggregate that has an ID (aggregate ID, also known as account ID) and contains a collection of all its events (transactions). The state (balance) can then be derived by replaying all the events associated with the aggregate.
If you follow along, congratulations—you now understand Event Sourcing!
Pros and Cons of Event Sourcing
Like any architectural pattern, Event Sourcing has its pros and cons:
Pros:
History and Auditability: All changes are recorded, providing a complete history for auditing purposes.
Temporal Query Support: Enables historical analysis by allowing you to query states at specific points in time.
Analytical Data: Captures not only the data but also the transitions and history, making it suitable for analytics.
Cons:
Storage Requirements: A large volume of events may accumulate, even for relatively simple entities, leading to increased storage needs.
Complex State Retrieval: There’s no quick way to access the current state of an entity without aggregating all the events, which can be time-consuming.
By considering these aspects, one can make informed decisions about whether to implement Event Sourcing in a given system.
Combining CQRS and Event Sourcing
Now that we understand what CQRS and Event Sourcing are, you may already be starting to see why and how they are often combined.
Event Sourcing provides a way to approach data for historical purposes and enhances auditability. However, it does come with slower read capabilities. On the other hand, CQRS allows us to separate our read and write flows.
By using CQRS for our writing flow and keeping aggregated data in our read flow, these two patterns empower us to scale efficiently and store more granular data simultaneously! This synergy typically operates within an event-driven architecture. Here is a complete diagram that ties everything together and fills in the missing pieces!
Flow Overview
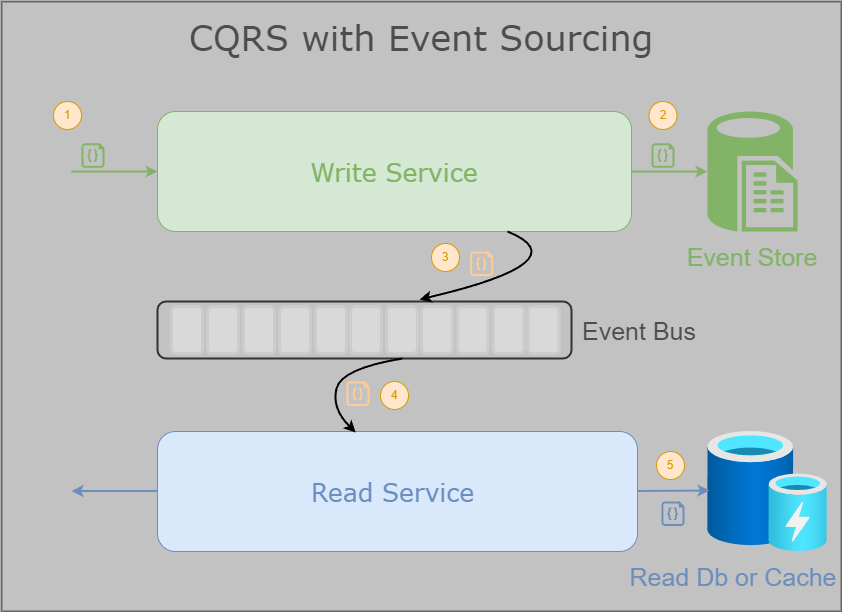
Let’s iron out the flow for clarity:
The Write Service Receives an Event: This service is responsible for handling incoming commands and generating events.
Writing to the Event Source: The write service records the event in the event store, which is always append-only, meaning there are no delete or update operations.
Publishing to the Event Bus: The write service then publishes a projected event to the event bus. Note that this is a projection of the received event, not the exact event itself.
Listening for Events: The read service, which listens to the event bus, receives the projected event.
Updating the Read Database: The read service processes the projected event and makes the necessary updates in the read database, as this database reflects the final state of the entity.
Pros and Cons
Pros:
Scalability: The architecture allows for independent scaling of the read and write flows.
Access to Historical Data: You can access historical data while achieving fast reads since the read service stores the final state.
Separation of Reading and Writing: The distinct paths for reading and writing enhance clarity and manageability in the system.
Cons:
Consistency Issues: Consistency could become a problem if something goes wrong. For example, if the event bus goes down or the read service is not operational while the write service is publishing events, there may be discrepancies.
Eventual Consistency: Data consistency is not immediate; it is eventual. This is due to the delay between when the write service receives the event and when the read service updates the read database.
By understanding these dynamics, we can effectively leverage CQRS and Event Sourcing to create low latency, scalable applications that meet the demands of many large scale systems.
Design of CQRS Plus

In my attempt to learn CQRS with event sourcing, I started by developing a couple of .NET Web API applications: one for reading entities and another for writing events on them. Gradually, these applications evolved into a labor of love, leading me to integrate a gateway using YARP and a UI with Next.js, resulting in a comprehensive codebase.
Here is the repository :
The repository's README file contains all the instructions you need to try it out on your end. Note that Docker Desktop is required to run the entire application.
Tech Stack

The services are written in C#.
Kafka is used as the event bus for its high availability.
PostgreSQL is utilized for the query service (reading entities) to provide the final state, leveraging its ACID capabilities as a robust RDBMS.
MongoDB serves as the event store due to its ability to handle large event store growth, making it suitable for horizontal scaling.
The UI is built with Next.js using TypeScript because I enjoy working with React!
The entire application is hosted using Docker and Docker Compose, as nothing is better suited for running a distributed application on a local machine.
Design
If you have read the article this far, the design of CQRS Plus should be straightforward to understand:
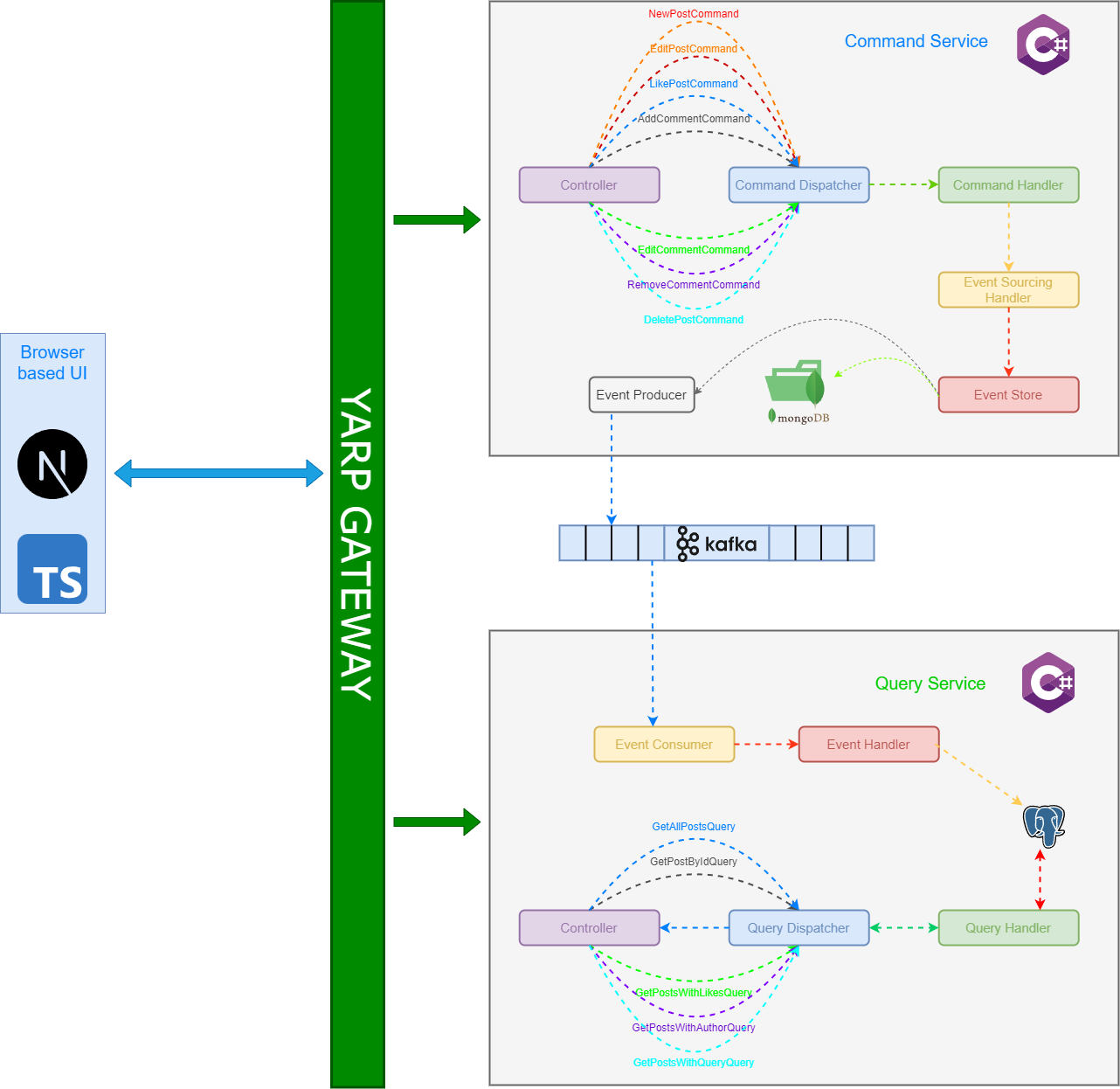
Command Service
The controllers, upon receiving requests, raise a command to the command handler.
Command handlers check the command and call the appropriate API on the event sourcing handler.
The event sourcing handler interacts with the MongoDB event store, saving an event for an aggregate and signaling the event producer to publish an event.
The event producer, an abstraction over the Kafka event bus, is responsible for placing an event in the Kafka stream.
Query Service
The Query Service includes a listener called
EventConsumer, thanks to .NET's Worker Services andAddHostedService. It pulls events from a Kafka topic.Upon receiving an event, the
EventConsumerinvokes the appropriate handler in the event handler, which then writes data to PostgreSQL.The query service handles read requests by delegating queries to the QueryDispatcher (similar to the
CommandDispatcherin the command service).The
QueryDispatcherinvokes the appropriate handler in the query handler, which reads data from PostgreSQL and serves the requested data.
ASP .Net Caveats
DTOs, Events and Entities
The entities carrying data within our applications should not be the same as those transmitting data externally. Therefore, request/response DTOs are often converted from/to data entities responsible for interacting with databases.
Events are models that transmit data across services through an event bus.
Although all are plain C# classes, they serve very different purposes, justifying their categorization.
Open API Support
CQRS Plus adheres to the OpenAPI standard for defining request routes. For example, if you want to read a comment with a comment ID cid under a post with a post ID pid, the request route would be: /api/v1/posts/{pid}/comments/{cid}
Gateway
A gateway acts as a thin abstraction layer over the different microservices within the cluster. The YARP gateway, also functioning as a reverse proxy, ensures there are no separate API services for the frontend, presenting a unified API interface to the caller.
Improvements
While CQRS Plus is nearly complete, it cannot yet be considered perfect. Currently, the operations involving saving to the event store and publishing to the event bus do not occur atomically. This process could be improved by implementing the outbox pattern. If I decide to implement it, I will update this article accordingly.
Further
A future topic of interest could be the deployment strategies for this microservice application. While there are many options, two notable choices include:
Kubernetes with managed instances like AKS (Azure) or EKS (AWS).
Elastic Container Service (ECS).
Conclusion
In this article, we explored a distributed implementation of the CQRS with Event Sourcing pattern. We delved into the intricacies of these patterns and their significance. We also examined the caveats associated with these approaches. While CQRS effectively addresses specific issues, it isn't necessary for all problems. We reviewed the implementation of a distributed CQRS with Event Sourcing and the rationale behind the technological choices.
Subscribe to my newsletter
Read articles from Siddhartha S directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Siddhartha S
Siddhartha S
With over 18 years of experience in IT, I specialize in designing and building powerful, scalable solutions using a wide range of technologies like JavaScript, .NET, C#, React, Next.js, Golang, AWS, Networking, Databases, DevOps, Kubernetes, and Docker. My career has taken me through various industries, including Manufacturing and Media, but for the last 10 years, I’ve focused on delivering cutting-edge solutions in the Finance sector. As an application architect, I combine cloud expertise with a deep understanding of systems to create solutions that are not only built for today but prepared for tomorrow. My diverse technical background allows me to connect development and infrastructure seamlessly, ensuring businesses can innovate and scale effectively. I’m passionate about creating architectures that are secure, resilient, and efficient—solutions that help businesses turn ideas into reality while staying future-ready.