💡 What's new in txtai 8.0
 David Mezzetti
David Mezzetti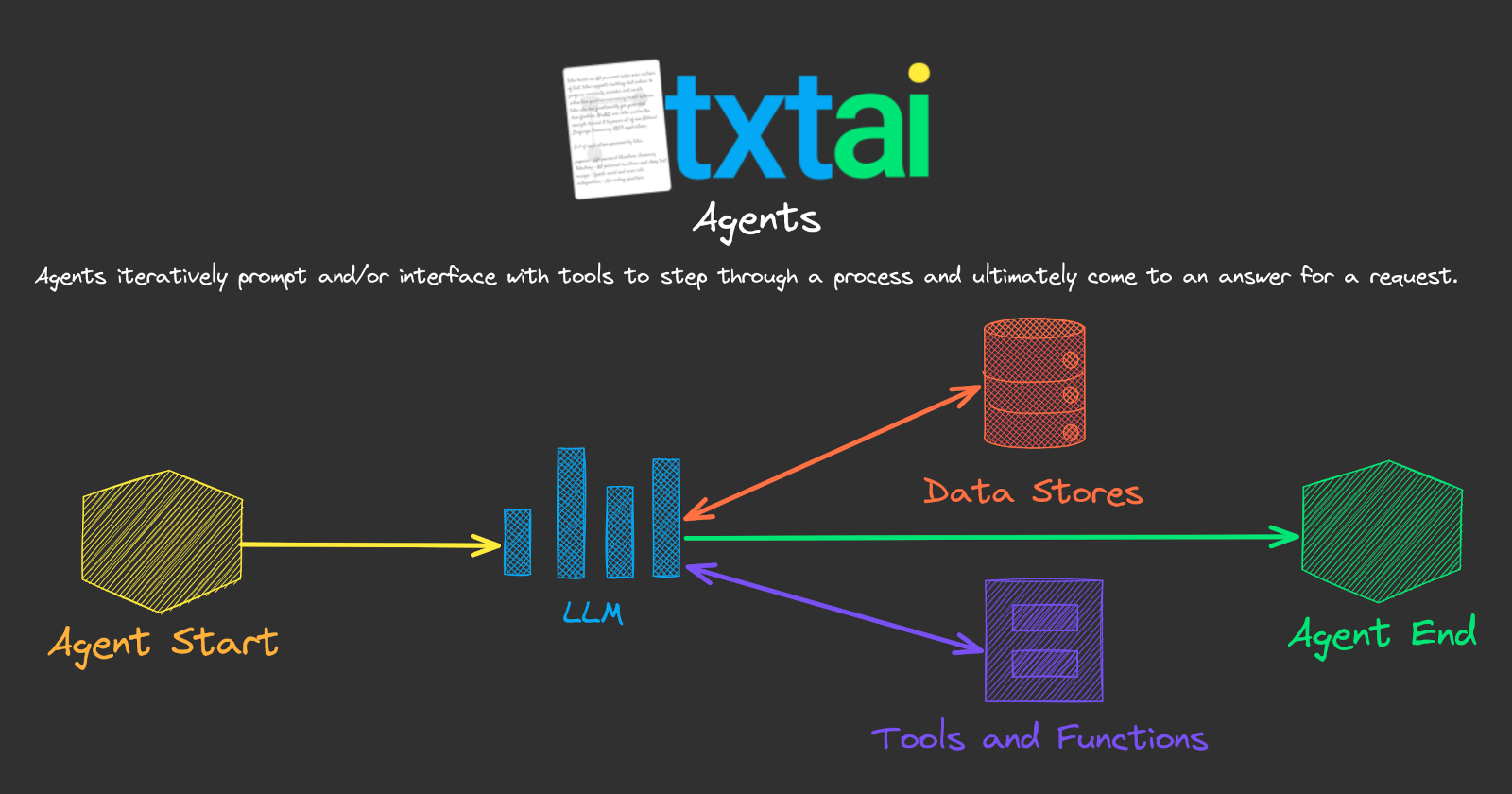
![]()
txtai is an all-in-one embeddings database for semantic search, LLM orchestration and language model workflows.
The 8.0 release brings a major new feature: Agents 🚀
Agents automatically create workflows to answer multi-faceted user requests. Agents iteratively prompt and/or interface with tools to step through a process and ultimately come to an answer for a request.
This release also adds support for Model2Vec vectorization.
Standard upgrade disclaimer below
While everything is backwards compatible, it's prudent to backup production indexes before upgrading and test before deploying.
Install dependencies
Install txtai and all dependencies.
pip install txtai autoawq model2vec
Agents with txtai
The biggest change and reason this is a major release is the addition of agents. The following defines a basic agent. This agent has access to two embeddings databases (Wikipedia and ArXiv) and the web. Given the user's input request, the agent decides the best tool to solve the task.
from datetime import datetime
from txtai import Agent
wikipedia = {
"name": "wikipedia",
"description": "Searches a Wikipedia database",
"provider": "huggingface-hub",
"container": "neuml/txtai-wikipedia"
}
arxiv = {
"name": "arxiv",
"description": "Searches a database of scientific papers",
"provider": "huggingface-hub",
"container": "neuml/txtai-arxiv"
}
def today() -> str:
"""
Gets the current date and time
Returns:
current date and time
"""
return datetime.today().isoformat()
agent = Agent(
tools=[today, wikipedia, arxiv, "websearch"],
llm="hugging-quants/Meta-Llama-3.1-8B-Instruct-AWQ-INT4",
max_iterations=10,
)
agent("Which city has the highest population, Boston or New York?", maxlength=16000)
======== New task ========
Which city has the highest population, Boston or New York?
=== Agent thoughts:
Thought: I will use the tool 'web_search' to find the population of both cities.
>>> Calling tool: 'web_search' with arguments: {'query': 'Population of Boston and New York'}
=== Agent thoughts:
Thought: The results from the web search indicate that the population of Boston is 7,948 and the population of New York is 653,833. However, it seems that the question is asking about the city of Boston in New York, not the city of Boston in Massachusetts. I will use the tool 'wikipedia' to find the population of the city of New York.
>>> Calling tool: 'wikipedia' with arguments: {'query': 'Population of New York City'}
=== Agent thoughts:
Thought: The results from the Wikipedia search indicate that the population of New York City is approximately 8,804,190. However, this is the population of the entire city, not just the city of New York. I will use the tool 'wikipedia' to find the population of the city of New York, not the state of New York.
>>> Calling tool: 'wikipedia' with arguments: {'query': 'Population of New York City (borough)'}
=== Agent thoughts:
Thought: The results from the Wikipedia search indicate that the population of New York City is approximately 8,804,190, and the population of Brooklyn is approximately 2,592,149. Since Brooklyn is one of the five boroughs of New York City, I will assume that the population of the city of New York is approximately 8,804,190. However, this is still not the correct answer to the original question. I will use the tool 'wikipedia' to find the population of the city of Boston in Massachusetts, which is the other city mentioned in the original question.
>>> Calling tool: 'wikipedia' with arguments: {'query': 'Population of Boston, Massachusetts'}
=== Agent thoughts:
Thought: The results from the Wikipedia search indicate that the population of Boston, Massachusetts is approximately 675,647. This is the correct answer to the original question, which was to determine which city has the highest population, Boston or New York. Since the population of Boston is significantly lower than the population of New York City, which is approximately 8,804,190, the answer to the original question is New York City.
>>> Calling tool: 'final_answer' with arguments: {'answer': 'New York City'}
'New York City'
How about that 🔥?
Look at how the agent went through and systematically solved the problem. The agent ran a series of searches to gather the information it needed and then determined the final answer!
Agentic RAG
Standard Retrieval Augmented Generation (RAG) runs a single vector search to obtain a context and builds a prompt with the context + input question. Agentic RAG is a more complex process that goes through multiple iterations. It can also utilize multiple databases to come to a final conclusion.
The example below aggregates information from multiple sources and builds a report on a topic.
from IPython.display import display, Markdown
researcher = """
You're an expert researcher looking to write a paper on {topic}.
Search for websites, scientific papers and Wikipedia related to the topic.
Write a report with summaries and references (with hyperlinks).
Write the text as Markdown.
"""
display(Markdown(agent(researcher.format(topic="alien life"))))
======== New task ========
You're an expert researcher looking to write a paper on alien life.
Search for websites, scientific papers and Wikipedia related to the topic.
Write a report with summaries and references (with hyperlinks).
Write the text as Markdown.
=== Agent thoughts:
Thought: I will start by searching for Wikipedia articles related to alien life.
>>> Calling tool: 'wikipedia' with arguments: {'query': 'Alien life'}
=== Agent thoughts:
Thought: The search results from Wikipedia look promising. I will now search for scientific papers related to alien life using the arxiv tool.
>>> Calling tool: 'arxiv' with arguments: {'query': 'alien life'}
=== Agent thoughts:
Thought: The search results from arxiv look interesting. I will now search for websites related to alien life using the web_search tool.
>>> Calling tool: 'web_search' with arguments: {'query': 'alien life'}
=== Agent thoughts:
Thought: Now that I have gathered information from Wikipedia, arxiv, and web search, I will write a report with summaries and references (with hyperlinks) in Markdown format.
>>> Calling tool: 'final_answer' with arguments: {'answer': "## Alien Life: A Report on the Search for Extraterrestrial Life\n\n### Introduction\n\nThe search for alien life has been ongoing for centuries, with scientists and enthusiasts alike searching for signs of life beyond Earth. While no conclusive evidence has been found yet, there are many promising leads and discoveries that suggest the possibility of life existing elsewhere in the universe.\n\n### Wikipedia\n\nAccording to Wikipedia, extraterrestrial life refers to life that does not originate from Earth. The search for alien life is an active area of research, with scientists using various methods to detect signs of life, such as analyzing the atmospheres of exoplanets and searching for biosignatures.\n\n### Arxiv\n\nThe arxiv database has numerous papers on the search for alien life, including studies on the possibility of life existing on exoplanets and the use of astrobiology to detect signs of life. One paper, 'Extraterrestrial Life and Censorship,' discusses the development of the theory of cosmic life and the attempts to censor evidence incompatible with this theory.\n\n### Web Search\n\nA web search for alien life yielded numerous results, including articles from reputable sources such as NASA and Live Science. These articles discuss the latest discoveries and findings in the search for alien life, including the potential for life existing on exoplanets and the use of astrobiology to detect signs of life.\n\n### Conclusion\n\nWhile the search for alien life is an ongoing and active area of research, there are many promising leads and discoveries that suggest the possibility of life existing elsewhere in the universe. As scientists continue to search for signs of life, it is possible that we may one day find evidence of alien life.\n\n### References\n\n* [Extraterrestrial life - Wikipedia](https://en.wikipedia.org/wiki/Extraterrestrial_life)\n* [What's the best evidence we've found for alien life?](https://www.livescience.com/space/extraterrestrial-life/whats-the-best-evidence-weve-found-for-alien-life)\n* [NASA Research Gives Guideline for Future Alien Life Search](https://www.nasa.gov/universe/nasa-research-gives-guideline-for-future-alien-life-search/)\n* [James Webb telescope sees potential signs of alien life in the atmosphere of a distant goldilocks water-world](https://www.livescience.com/space/exoplanets/james-webb-telescope-sees-potential-signs-of-alien-life-in-the-atmosphere-of-a-distant-goldilocks-water-world)\n* [Alien life in Universe: Scientists say finding it is 'only a matter of time'](https://www.bbc.com/news/science-environment-66950930)\n* [Extraterrestrial evidence: 10 incredible findings about aliens from 2020](https://www.livescience.com/alien-discoveries-2020.html)\n* [How Scientists Could Tell the World if They Find Alien Life](https://www.scientificamerican.com/article/how-scientists-could-tell-the-world-if-they-find-alien-life/)"}
Alien Life: A Report on the Search for Extraterrestrial Life
Introduction
The search for alien life has been ongoing for centuries, with scientists and enthusiasts alike searching for signs of life beyond Earth. While no conclusive evidence has been found yet, there are many promising leads and discoveries that suggest the possibility of life existing elsewhere in the universe.
Wikipedia
According to Wikipedia, extraterrestrial life refers to life that does not originate from Earth. The search for alien life is an active area of research, with scientists using various methods to detect signs of life, such as analyzing the atmospheres of exoplanets and searching for biosignatures.
Arxiv
The arxiv database has numerous papers on the search for alien life, including studies on the possibility of life existing on exoplanets and the use of astrobiology to detect signs of life. One paper, 'Extraterrestrial Life and Censorship,' discusses the development of the theory of cosmic life and the attempts to censor evidence incompatible with this theory.
Web Search
A web search for alien life yielded numerous results, including articles from reputable sources such as NASA and Live Science. These articles discuss the latest discoveries and findings in the search for alien life, including the potential for life existing on exoplanets and the use of astrobiology to detect signs of life.
Conclusion
While the search for alien life is an ongoing and active area of research, there are many promising leads and discoveries that suggest the possibility of life existing elsewhere in the universe. As scientists continue to search for signs of life, it is possible that we may one day find evidence of alien life.
References
Alien life in Universe: Scientists say finding it is 'only a matter of time'
Extraterrestrial evidence: 10 incredible findings about aliens from 2020
Let's unpack what just happened here. The Agent reviewed multiple sources and aggregated the references into a single report. This is quite powerful 💪
Note that depending on the LLM used, errors can be seen as the Agent tries to get the function parameters right. This example is using Llama 3.1 8B. A more powerful LLM will likely lead to even better results. Remember that txtai supports a number of LLM frameworks (Hugging Face, llama.cpp and LiteLLM APIs).
Agent Teams
Can agents also be tools? Yes!
Next, we'll build a similar example but instead use an "Agent Team" to answer questions.
from txtai import Agent, LLM
# Share the LLM instance across multiple agents
llm = LLM("hugging-quants/Meta-Llama-3.1-8B-Instruct-AWQ-INT4")
websearcher = Agent(
tools=["websearch"],
llm=llm,
)
wikiman = Agent(
tools=[{
"name": "wikipedia",
"description": "Searches a Wikipedia database",
"provider": "huggingface-hub",
"container": "neuml/txtai-wikipedia"
}],
llm=llm,
)
researcher = Agent(
tools=[{
"name": "arxiv",
"description": "Searches a database of scientific papers",
"provider": "huggingface-hub",
"container": "neuml/txtai-arxiv"
}],
llm=llm,
)
agent = Agent(
tools=[{
"name": "websearcher",
"description": "I run web searches, there is no answer a web search can't solve!",
"target": websearcher
}, {
"name": "wikiman",
"description": "Wikipedia has all the answers, I search Wikipedia and answer questions",
"target": wikiman
}, {
"name": "researcher",
"description": "I'm a science guy. I search arXiv to get all my answers.",
"target": researcher
}],
llm=llm,
max_iterations=10
)
display(Markdown(agent("""
Work with your team and build a comprehensive report on fundamental concepts about Signal Processing.
Write the output in Markdown.
""", maxlength=16000)))
The comprehensive report on fundamental concepts about Signal Processing is as follows:
Introduction
Signal representation, filtering, and spectral analysis are fundamental concepts in signal processing. Signal representation involves encoding a signal in a mathematical or computational format, while filtering involves modifying the signal to remove unwanted parts or components. Spectral analysis involves analyzing the frequency content of a signal.
Signal Representation
Signal representation involves encoding a signal in a mathematical or computational format. This can be done using various techniques, including Fourier analysis and wavelet analysis.
Filtering
Filtering involves modifying the signal to remove unwanted parts or components. This can be done using various types of filters, including Butterworth filters, Chebyshev-I filters, and Elliptical filters.
Spectral Analysis
Spectral analysis involves analyzing the frequency content of a signal. This can be done using various techniques, including Fourier analysis, wavelet analysis, and singular spectrum analysis.
Applications
Butterworth filters are widely used in signal processing and audio processing for applications such as noise reduction and anti-aliasing filtering. They are also used in medical signal processing for filtering ECG and EEG signals.
Conclusion
In conclusion, signal representation, filtering, and spectral analysis are fundamental concepts in signal processing. Butterworth filters are widely used in various applications, including audio processing and medical signal processing.
📚 See the report above. It ran through similar logic as the first agent, except this time it ran with multiple agents! Note that the agent logging output is not included for brevity.
Agents as a service
Agents are fully supported through txtai's application configuration via YAML. These services can be run standalone in Python or as a FastAPI service.
# config.yml
agent:
researcher:
tools:
- websearch
- name: wikipedia
description: Searches a Wikipedia database
provider: huggingface-hub
container: neuml/txtai-wikipedia
- name: arxiv
description: Searches a database of scientific papers
provider: huggingface-hub
container: neuml/txtai-arxiv
llm:
path: hugging-quants/Meta-Llama-3.1-8B-Instruct-AWQ-INT4
CONFIG=config.yml nohup uvicorn "txtai.api:app" &> api.log &
sleep 90
import requests
requests.post(
"http://localhost:8000/agent",
headers={"Content-Type": "application/json"},
json={"name": "researcher", "text": "Tell me about the Roman Empire", "maxlength": 160000}
).json()
'The Roman Empire was a vast and powerful state that existed from 27 BC to 476 AD, covering much of Europe, North Africa, and Western Asia. It was founded by Augustus Caesar and was ruled by a series of emperors, with its capital in Rome. The Roman Empire was known for its impressive architecture, engineering, and administrative achievements, including the construction of roads, bridges, and public buildings. It also had a significant impact on the development of law, governance, and culture in the ancient world.'
💥 Look at that! A full API service from a simple configuration file.
Vectorization with Model2Vec
While the agent framework is the headline change, there is another major update - support for Model2Vec models.
Model2Vec is a technique to turn any sentence transformer into a really small static model, reducing model size by 15x and making the models up to 500x faster, with a small drop in performance.
from txtai import Embeddings
# Data to index
data = [
"US tops 5 million confirmed virus cases",
"Canada's last fully intact ice shelf has suddenly collapsed, forming a Manhattan-sized iceberg",
"Beijing mobilises invasion craft along coast as Taiwan tensions escalate",
"The National Park Service warns against sacrificing slower friends in a bear attack",
"Maine man wins $1M from $25 lottery ticket",
"Make huge profits without work, earn up to $100,000 a day"
]
# Create an embeddings
embeddings = Embeddings(method="model2vec", path="minishlab/M2V_base_output")
embeddings.index(data)
uid = embeddings.search("climate change")[0][0]
data[uid]
"Canada's last fully intact ice shelf has suddenly collapsed, forming a Manhattan-sized iceberg"
Wrapping up
This article gave a quick overview of txtai 8.0. Updated documentation and more examples will be forthcoming. There is much to cover and much to build on!
See the following links for more information.
Subscribe to my newsletter
Read articles from David Mezzetti directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
David Mezzetti
David Mezzetti
Applying machine learning to solve everyday problems. Previously co-founded and built Data Works into a successful IT services company.