Build your own SQLite, Part 3: SQL parsing 101
 Geoffrey Copin
Geoffrey Copin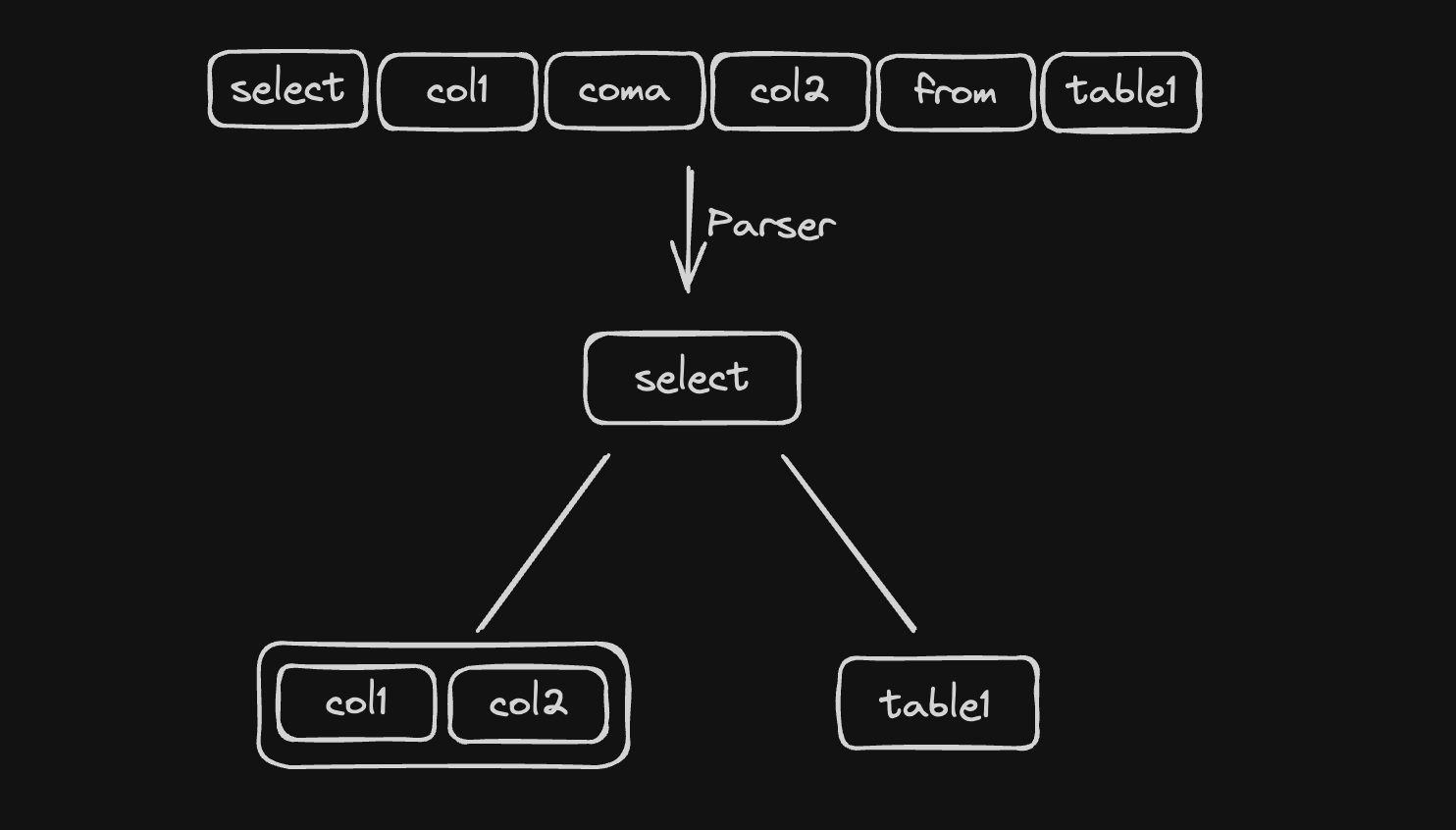
After discovering the SQLite file format and implementing the .tables command in part 1 and part 2 of this series, we're ready to tackle the next big challenge: writing our own SQL parser from scratch.
As the SQL dialect supported by SQLite is quite large and complex, we'll initially limit ourselves to a subset that comprises only the select statement, in a striped-down form. Only expressions of the form select <columns> from <table> will be supported, where <columns> is either * or a comma-separated list of columns names (with an optional as alias), and <table> is the name of a table.
The full SQL syntax, as implemented in SQLite is described in great detail in the SQL As Understood By SQLite document.
Parsing Basics
Our SQL parser will follow a conventional 2 steps process: lexical analysis (or tokenization) and syntax analysis (or parsing).
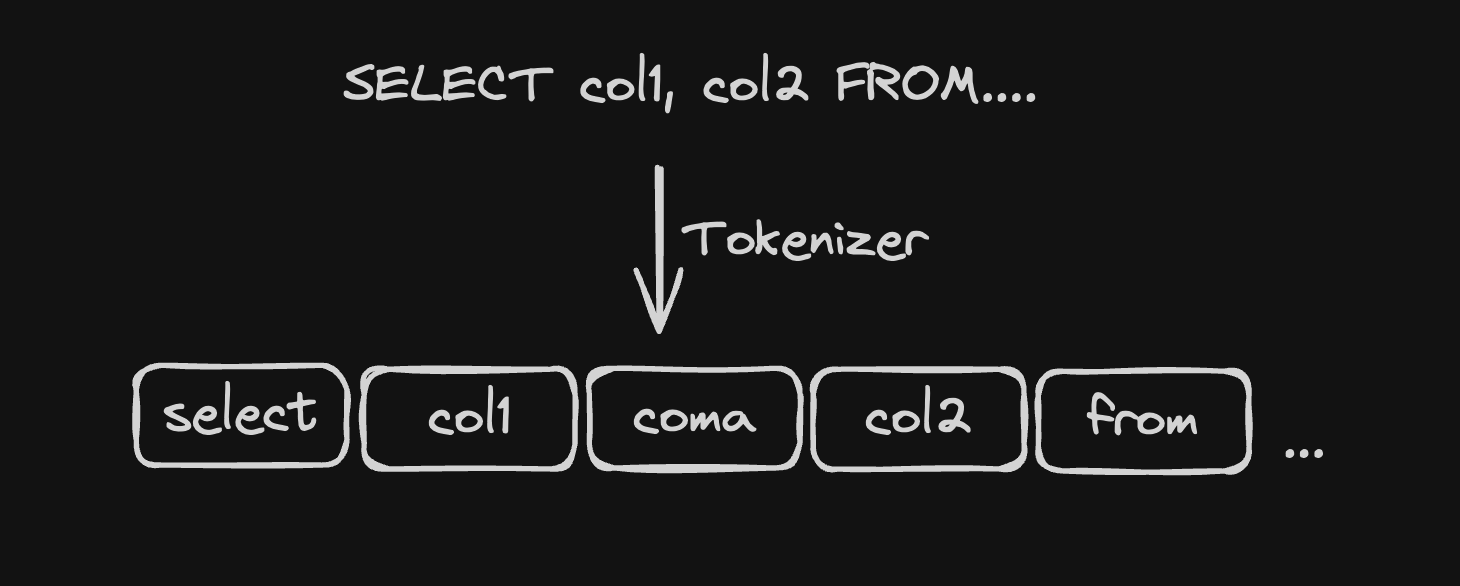
The lexical analysis step takes the input SQL string and groups individual characters into tokens, which are meaningful units of the language. For example, the character sequence S-E-L-E-C-T will be grouped into a single token of type select, and the sequence * will be grouped into a token of type star. This stage is also responsible for discarding whitespace and normalizing the case of the input.
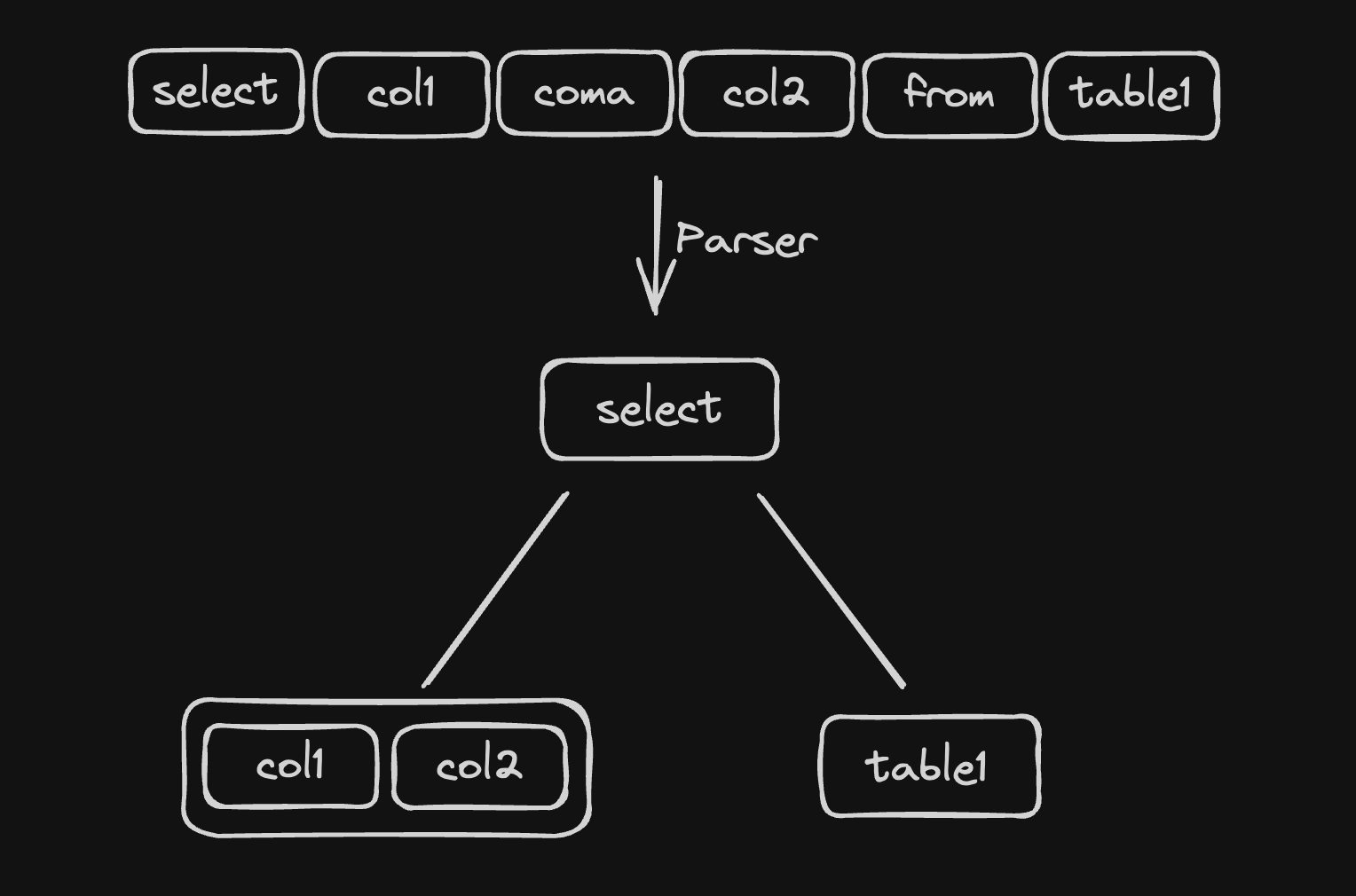
The syntax analysis step takes the stream of tokens produced by the lexical analysis, and tries to match them against the syntax rules of the language. Its output is an abstract syntax tree (AST), which is a hierarchical representation of the input SQL.
Writing the tokenizer
The first step in writing our tokenizer is to define a Token type that will represent the individual tokens of our SQL dialect. This definition will live in a new module: sql::tokenizer.
// sql/tokenizer.rs
#[derive(Debug, Eq, PartialEq)]
pub enum Token {
Select,
As,
From,
Star,
Comma,
SemiColon,
Identifier(String),
}
impl Token {
pub fn as_identifier(&self) -> Option<&str> {
match self {
Token::Identifier(ident) => Some(ident),
_ => None,
}
}
}
We also define a utility function as_identifier that will return the string value of a token if it is an Identifier, and None otherwise.
The logic of the tokenize function is quite simple: we iterate over the input string's characters, and based on the current character we decide which token to emit:
if the character matches a single-character token, we emit it immediately
if the character is a whitespace, it is discarded
finally, if the character is a letter, we start a new identifier token and keep accumulating characters until we reach a character that is not a valid identifier character. At this point, if the accumulated string is a keyword, we emit the corresponding token, otherwise, we emit a raw
Identifiertoken.
// sql/tokenizer.rs
use anyhow::bail;
pub fn tokenize(input: &str) -> anyhow::Result<Vec<Token>> {
let mut tokens = Vec::new();
let mut chars = input.chars().peekable();
while let Some(c) = chars.next() {
match c {
'*' => tokens.push(Token::Star),
',' => tokens.push(Token::Comma),
';' => tokens.push(Token::SemiColon),
c if c.is_whitespace() => continue,
c if c.is_alphabetic() => {
let mut ident = c.to_string().to_lowercase();
while let Some(cc) = chars.next_if(|&cc| cc.is_alphanumeric() || cc == '_') {
ident.extend(cc.to_lowercase());
}
match ident.as_str() {
"select" => tokens.push(Token::Select),
"as" => tokens.push(Token::As),
"from" => tokens.push(Token::From),
_ => tokens.push(Token::Identifier(ident)),
}
}
_ => return Err(anyhow::anyhow!("unexpected character: {}", c)),
}
}
Ok(tokens)
}
Since SQL is case-insensitive, all identifiers are normalized to lower case.
Representing SQL statements
Before we dive into the implementation of the parser, we need to decide how to represent SQL statements in our code. We'll settle on a conventional representation, based on the description of the SQL syntax in the SQLite documentation, and write the corresponding Rust types in a new module sql::ast.
// sql/ast.rs
#[derive(Debug, Clone, Eq, PartialEq)]
pub enum Statement {
Select(SelectStatement),
}
#[derive(Debug, Clone, Eq, PartialEq)]
pub struct SelectStatement {
pub core: SelectCore,
}
#[derive(Debug, Clone, Eq, PartialEq)]
pub struct SelectCore {
pub result_columns: Vec<ResultColumn>,
pub from: SelectFrom,
}
#[derive(Debug, Clone, Eq, PartialEq)]
pub enum ResultColumn {
Star,
Expr(ExprResultColumn),
}
#[derive(Debug, Clone, Eq, PartialEq)]
pub struct ExprResultColumn {
pub expr: Expr,
pub alias: Option<String>,
}
#[derive(Debug, Clone, Eq, PartialEq)]
pub enum Expr {
Column(Column),
}
#[derive(Debug, Clone, Eq, PartialEq)]
pub struct Column {
pub name: String,
}
#[derive(Debug, Clone, Eq, PartialEq)]
pub enum SelectFrom {
Table(String),
}
The following query:
select col1 as first, col2
from table
Will be parsed into the following rust structure:
Statement::Select(SelectStatement {
core: SelectCore {
result_columns: vec![
ResultColumn::Expr(ExprResultColumn {
expr: Expr::Column(Column {
name: "col1".to_string()
}),
alias: Some("first".to_string())
}),
ResultColumn::Expr(ExprResultColumn {
expr: Expr::Column(Column {
name: "col2".to_string()
}),
alias: None
}),
],
from: SelectFrom::Table("table".to_string()),
},
})
You may notice a few redundancies in this representation, such as the Expr enum that comprises a single variant. This is intentional, as it will allow us to add new syntactic constructs in future episodes without breaking too much of the existing code.
Writing the parser
Parsing algorithms come in all shapes and sizes, and a full discussion of the topic if beyond the scope of this article. The one we'll use here is called recursive descent and is reasonably simple to understand and implement:
for every node type, we'll define a function that tries to build the node from the current input tokens, and fails if it is not possible. For example, we'll define a method that builds a
Columnnode by consuming anIdentifiertoken, and fails if the current token is not anIdentifiertoken.complex "nested" nodes are build by delegating the parsing of their child nodes to other functions. For example,
ExprResultColmnis build by parsing anExprnode and an optionalastoken followed by anIdentifiertoken.
In a fully-fledged parser, these functions can be mutually recursive.
First, let's define a ParserState struct that will hold the state of the parser: the list of tokens, and the current position in the list.
// sql/parser.rs
use anyhow::{bail, Context};
use crate::sql::{
ast::{
Column, Expr, ExprResultColumn, ResultColumn, SelectCore, SelectFrom, SelectStatement,
Statement,
},
tokenizer::{self, Token},
};
#[derive(Debug)]
struct ParserState {
tokens: Vec<Token>,
pos: usize,
}
impl ParserState {
fn new(tokens: Vec<Token>) -> Self {
Self { tokens, pos: 0 }
}
fn next_token_is(&self, expected: Token) -> bool {
self.tokens.get(self.pos) == Some(&expected)
}
fn expect_identifier(&mut self) -> anyhow::Result<&str> {
self.expect_matching(|t| matches!(t, Token::Identifier(_)))
.map(|t| t.as_identifier().unwrap())
}
fn expect_eq(&mut self, expected: Token) -> anyhow::Result<&Token> {
self.expect_matching(|t| *t == expected)
}
fn expect_matching(&mut self, f: impl Fn(&Token) -> bool) -> anyhow::Result<&Token> {
match self.next_token() {
Some(token) if f(token) => Ok(token),
Some(token) => bail!("unexpected token: {:?}", token),
None => bail!("unexpected end of input"),
}
}
fn peak_next_token(&self) -> anyhow::Result<&Token> {
self.tokens.get(self.pos).context("unexpected end of input")
}
fn next_token(&mut self) -> Option<&Token> {
let token = self.tokens.get(self.pos);
if token.is_some() {
self.advance();
}
token
}
fn advance(&mut self) {
self.pos += 1;
}
}
current_token_ischecks if the current token is equal to the expected tokenexpect_identifierreturns the content of the current token if it is anIdentifier, and fails otherwiseexpect_eqchecks if the current token is equal to the expected token, and fails otherwisepeak_next_tokenallows us to look at the next token without consuming it, and fails if there are no more tokensnext_tokenreturns the current token and advances the parser's positionadvanceincrements the parser's position
Armed with these primitives, we can write our simplest parser function: parse_expr! As the only expressions that we support for now are identifiers, the parsing function only has to check that the current token is an Identifier token and build a Expr node from its value.
// sql/parser.rs
impl ParserState {
//...
fn parse_expr(&mut self) -> anyhow::Result<Expr> {
Ok(Expr::Column(Column {
name: self.expect_identifier()?.to_string(),
}))
}
//...
}
A bit more involved, the parse_expr_result_column function parses terms of the form columnName or columnName as alias. It starts by parsing the initial Expr node (columnName, in our examples), then if the next token is as, it consumes it and parses the Identifier token that follows.
// sql/parser.rs
impl ParserState {
//...
fn parse_expr_result_column(&mut self) -> anyhow::Result<ExprResultColumn> {
let expr = self.parse_expr()?;
let alias = if self.next_token_is(Token::As) {
self.advance();
Some(self.expect_identifier()?.to_string())
} else {
None
};
Ok(ExprResultColumn { expr, alias })
}
//...
}
ResultColumn can represent terms of the form described above, or * to represent all columns of a table. The parse_result_column function checks if the current token is *, and returns a Star node if it is. Otherwise, it delegates the parsing of the ExprResultColumn node to the parse_expr_result_column function.
// sql/parser.rs
impl ParserState {
//...
fn parse_result_column(&mut self) -> anyhow::Result<ResultColumn> {
if self.peak_next_token()? == &Token::Star {
self.advance();
return Ok(ResultColumn::Star);
}
Ok(ResultColumn::Expr(self.parse_expr_result_column()?))
}
//...
}
Another interesting example is the parse_result_colums function, which parses a list of columns separated by commas. It starts by parsing the first column, then iterates over the following tokens as long as the token following a result column is a comma, accumulating the parsed columns in a vector.
// sql/parser.rs
impl ParserState {
//...
fn parse_result_columns(&mut self) -> anyhow::Result<Vec<ResultColumn>> {
let mut result_coluns = vec![self.parse_result_column()?];
while self.next_token_is(Token::Comma) {
self.advance();
result_coluns.push(self.parse_result_column()?);
}
Ok(result_coluns)
}
//...
}
As you are probably getting the hang of it, implementing the remaining parsing functions can be a fun exercise. In any case, here is my implementation for reference:
// sql/parser.rs
impl ParserState {
//...
fn parse_statement(&mut self) -> anyhow::Result<Statement> {
Ok(Statement::Select(self.parse_select()?))
}
fn parse_select(&mut self) -> anyhow::Result<SelectStatement> {
self.expect_eq(Token::Select)?;
let result_columns = self.parse_result_columns()?;
self.expect_eq(Token::From)?;
let from = self.parse_select_from()?;
Ok(SelectStatement {
core: SelectCore {
result_columns,
from,
},
})
}
fn parse_select_from(&mut self) -> anyhow::Result<SelectFrom> {
let table = self.expect_identifier()?;
Ok(SelectFrom::Table(table.to_string()))
}
//...
}
The final piece of the puzzle is a function that ties everything together, taking an input SQL string, tokenizing it, and parsing it into an AST:
// sql/parser.rs
//...
pub fn parse_statement(input: &str) -> anyhow::Result<Statement> {
let tokens = tokenizer::tokenize(input)?;
let mut state = ParserState::new(tokens);
let statement = state.parse_statement()?;
state.expect_eq(Token::SemiColon)?;
Ok(statement)
}
Putting it all together
We've covered a lot of ground! Now is the time to test our parser on some actual SQL queries. To that end, let's alter our REPL loop to parse then input as an SQL statement if it does not match a know command, and print it.
// src/main.rs
+ mod sql;
//...
fn cli(mut db: db::Db) -> anyhow::Result<()> {
print_flushed("rqlite> ")?;
let mut line_buffer = String::new();
while stdin().lock().read_line(&mut line_buffer).is_ok() {
match line_buffer.trim() {
".exit" => break,
".tables" => display_tables(&mut db)?,
+ stmt => match sql::parse_statement(stmt) {
+ Ok(stmt) => {
+ println!("{:?}", stmt);
+ }
+ Err(e) => {
+ println!("Error: {}", e);
+ }
+ },
- _ => {
- println!("Unrecognized command '{}'", line_buffer.trim());
- }
}
print_flushed("\nrqlite> ")?;
line_buffer.clear();
}
Ok(())
}
//...
Conclusion
Our database can read data and parse very simple SQL statements. In the next part of this series, we'll bridge the gap between these two functionalities and build a small query engine that compiles SQL queries into execution plans and executes these plans against the persisted data.
Subscribe to my newsletter
Read articles from Geoffrey Copin directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by