Querying Fabric KQL Database Using REST API
 Sandeep Pawar
Sandeep PawarI have previously explained how to query a KQL database in a notebook using the Kusto Spark connector, Kusto Python SDK, and KQLMagic. Now, let's explore another method using the REST API. Although this is covered in the ADX documentation, it isn't in Fabric (with example), so I wanted to write a quick blog to show how you can query a table from an Eventhouse using a REST API.
Requirements:
Cluster URI
Kusto Database name
KQL query
Access token : You can use a service principal or use the default Fabric user token
Fabric Runtime >= 1.2
import requests
import json
import pandas as pd
from datetime import datetime
def query_kusto(cluster_url: str, database: str, query: str, token: str):
"""
Function to query Fabric Kusto db using REST API
Args:
cluster_url: Full cluster URL (e.g., 'https://guid.kusto.fabric.microsoft.com')
database: Database name
query: KQL query
token: Bearer token
"""
headers = {
'Authorization': f'Bearer {token}',
'Content-Type': 'application/json',
'Accept': 'application/json'
}
body = {
'db': database,
'csl': query
}
response = requests.post(
f'{cluster_url}/v1/rest/query',
headers=headers,
json=body
)
return response.json()
Example
# Example
cluster_url = 'https://<guid>.z4.kusto.fabric.microsoft.com'
database = '<dbname>'
kqlquery = '''
table | take 2
'''
token = notebookutils.credentials.getToken(cluster_url)
try:
results = query_kusto(cluster_url, database, kqlquery, token)
# Print the results for debugging if needed -optional
# if results.get('Tables'):
# rows = results['Tables'][0]['Rows']
# for row in rows:
# print(row)
except Exception as e:
print(f"Error querying Kusto: {str(e)}")
# results
This will return the result as JSON text and we need to parse the output to create a dataframe for further analysis. It also returns the data types.
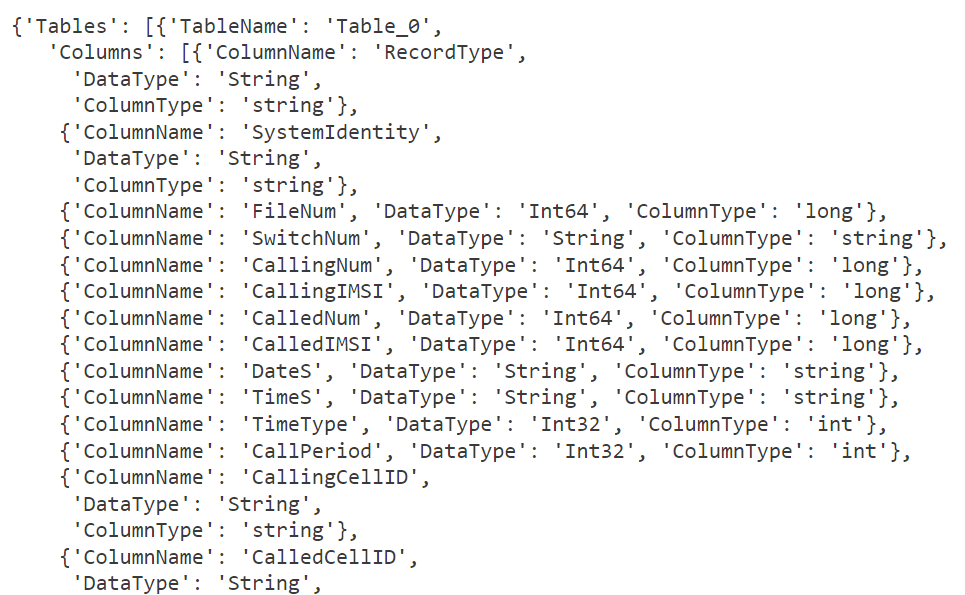
Parse the output:
Below we parse the JSON and assign datatypes (string, numeric, datetime only. For dynamic and other dtypes, assign dtypes as required).
def kusto_to_df(results):
"""
Convert Kusto query results to pandas DataFrame with appropriate data types.
Unrecognized types default to string.
Args:
results (dict): Kusto query results containing Tables, Columns, and Rows
Returns:
pandas.DataFrame: DataFrame with properly typed columns
"""
# Extract columns and data types
columns_info = results['Tables'][0]['Columns']
rows = results['Tables'][0]['Rows']
# Create a df
df = pd.DataFrame(rows, columns=[col['ColumnName'] for col in columns_info])
# dtypes, only numeric, datetime and string. Dynamic and other will be cast as string
for col_info in columns_info:
col_name = col_info['ColumnName']
data_type = col_info['DataType']
try:
if data_type == 'DateTime':
df[col_name] = pd.to_datetime(df[col_name])
elif data_type in ['Int64', 'Int32', 'Long']:
df[col_name] = pd.to_numeric(df[col_name], errors='coerce').fillna(0).astype('int64')
elif data_type == 'Real' or data_type == 'Double':
df[col_name] = pd.to_numeric(df[col_name], errors='coerce')
else:
# Convert any other type to string, change as needed
df[col_name] = df[col_name].astype(str)
except Exception as e:
print(f"Warning: Could not convert column {col_name} to {data_type}, defaulting to string: {str(e)}")
df[col_name] = df[col_name].astype(str)
return df
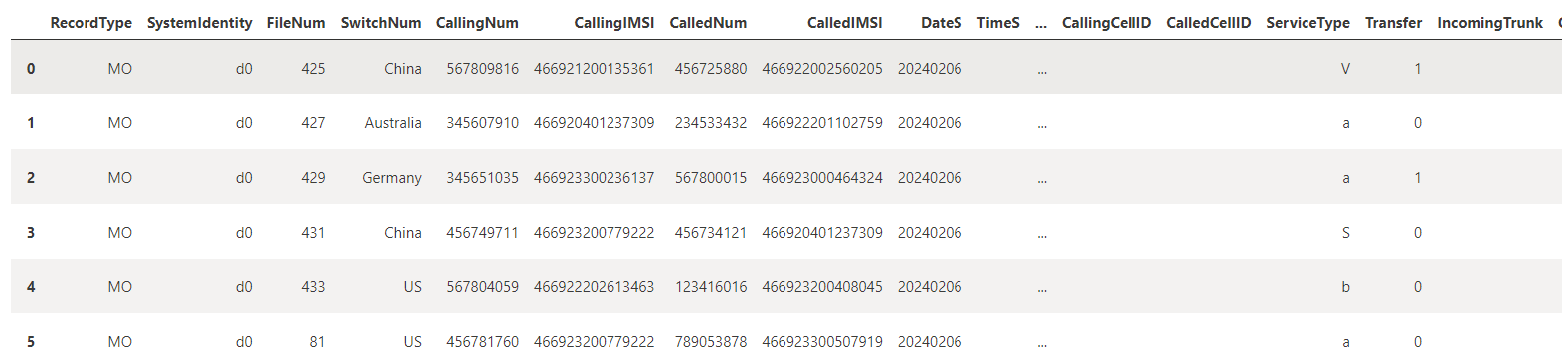
kusto_to_df(results) #returns a pandas df
Notes
Unlike Kusto spark connector, KQLMagic etc, this is language agnostic as long as you can generate a token and call an API. You can query in an external application as well.
This not meant to be used to return large amount of data. I am not sure of the limits, but I am sure just like other Fabric APIs, this endpoint also has rate and size limitations.
You can also ingest data using an API with
/v1/rest/ingestURI.
Subscribe to my newsletter
Read articles from Sandeep Pawar directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Sandeep Pawar
Sandeep Pawar
Principal Program Manager, Microsoft Fabric CAT helping users and organizations build scalable, insightful, secure solutions. Blogs, opinions are my own and do not represent my employer.