Collecte d'informations Bug Bounty
 FIKARA BILAL
FIKARA BILAL
Dans un contexte de BugBounty ou de test de sécurité, la collecte d’informations est une étape qui consiste à recueillir un maximun de données sur une cible. Le but est de mieux comprendre son environnement et surtout identifier des vulnérabilités potentielles. Elle utilise des techniques variées dont certaines seront détaillées par la suite. Dans cet article, nous expliquerons en détail certains outils utiles lors de la collecte d’informations.
Google Dorking
Le Google Dorking est une technique de recherche qui utilise des requêtes avancées afin de trouver des informations sensibles, non accessibles via une recherche Google standard. Cela permet d’affiner la recherche pour découvrir des pages web, des fichiers et d’autres données cachées.
Options
<keyword> site: www.website.com filetype:pdfsite:effectue la recherche du keyword seulement sur le site spécifié.filetype:recherche un type de fichiers spécifiques, ici les pdf.
intitle:<keyword> inurl:<keyword> cache:<keyword>intitle:recherche des pages web dont le titre contient le mot spécifiéinurl:recherche les pages web dont l’URL contient le mot spécifié. Cette technique permet de retrouver des pages spécifiques, des répertoires ou des fichiers qui incluent le mot-clé.cache:permet d’afficher la version en cache d’une page web. C’est à dire elle affiche une copie sauvegardée par un moteur de recherche.Elle est souvent utilisée pour afficher une page qui a été supprimée, mais toujours visible dans le cache du moteur de recherche. Ou encore voir comment un site apparaissaît avant des modifications majeures.
Sur l’image ci-dessous, on peut voir que la recherche retourne juste des fichiers PDF qui ont le terme "bug bounty" dans le titre.
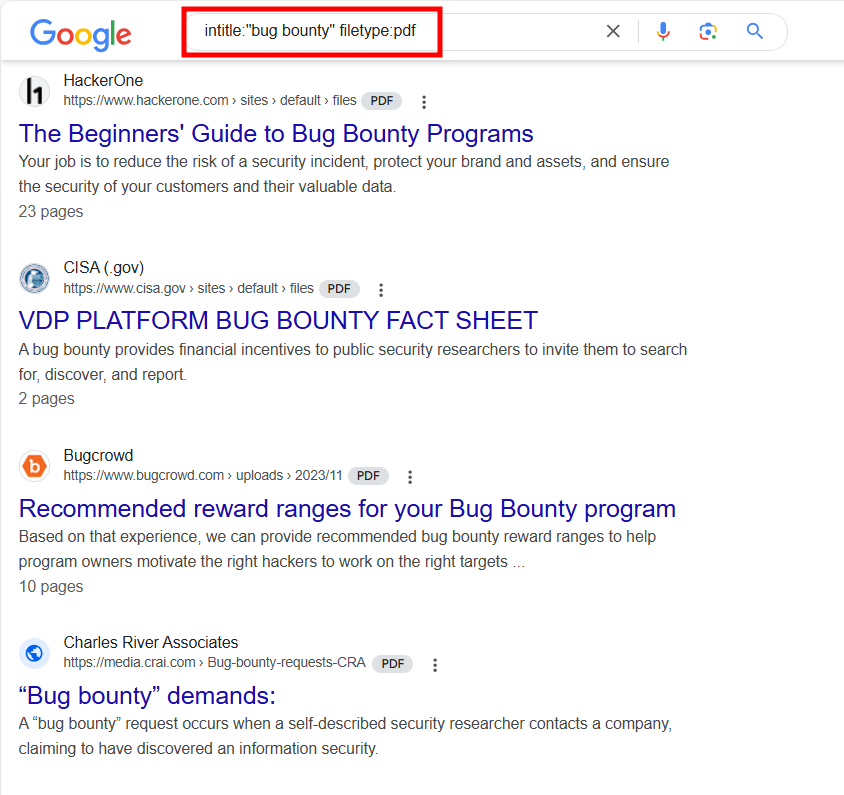
On peut utiliser des Google Dorks pour des informations plus sensibles.
intitle:"index of" "server-status" site:www.website.com: cette requête recherche des pages sur le site dont le titre contient ”index of ” et “server-status“. Cela peut permettre d’avoir des informations sur le serveur ou des pages de statut de serveur."public" "key" filetype:pem site:www.website.com: pour rechercher des fichiers de type PEM sur le site contenant les mots “public" et “key". Ces fichiers sont souvent utilisés pour stocker des clés pour la cryptographie. On pourrait donc potentiellement retrouver des clés publiques exposées.
Les Google Dorks peuvent être des moyens efficaces pour identifier des vulnérabilités sur un système. Il existe aussi des fichiers et des listes disponibles sur Internet contenant des google Dorks pour diverses recherches
Bug Bounty Search Engine
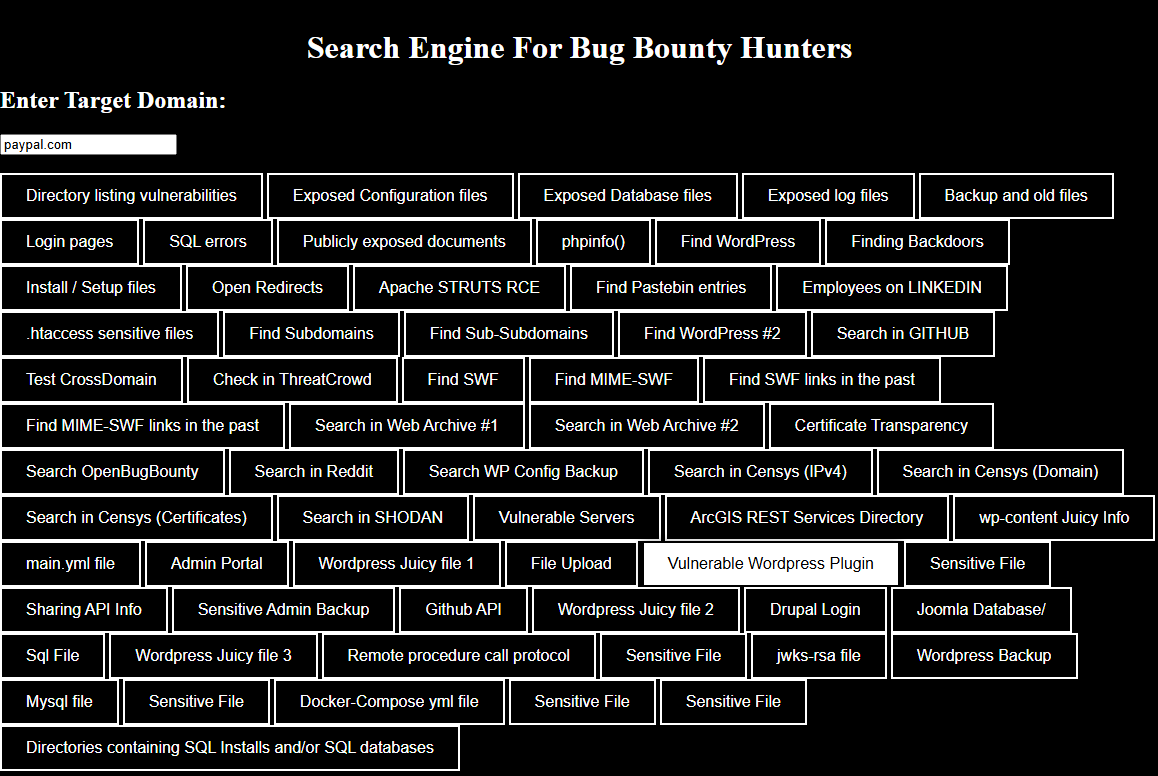
BugBountySearchEngine est un moteur de recherche qui regroupe plusieurs moyens de rechercher des vulnérabilitées et des informations sensibles sur des domaines, des sites et même des personnes. Il offre des options pour trouver des fichiers de configuration ou de sauvegarde, des bases de données exposées, des sous-domaines et bien d’autres. On peut aussi y rechercher des données spécifiques sur des sources publiques comme Github, Shodan, Censys et d’autres.
L’outil est disponible ici.
Pour l’utiliser, entrez un domaine cible dans l’interface. Sélectionnez ensuite l’une des recherches prédéfinies en fonction des informations que vous souhaitez avoir.
Github Recon
Le Github Recon est une technique utilisée pour rechercher des informations sur des projets, des organisations ou même des individus en explorant les dépôts sur Gihub. Elle consiste à analyser l’historique des commits, surveiller les activités dans le but de découvrir des informations sensibles. Vous pouvez aussi utiliser les Github Dorks pour affiner les recherches. Il est parfois possible que les développeurs oublient ou laissent des informations sensibles comme des clé APIs, des mots de passe par défaut et d’autres.
Dans la barre de recherche, il suffit d’inscrire les dorks ou les requêtes souhaitées. Il faut ensuite examiner les codes, les commits afin d’y recueillir des informations qui pourraient être utiles.
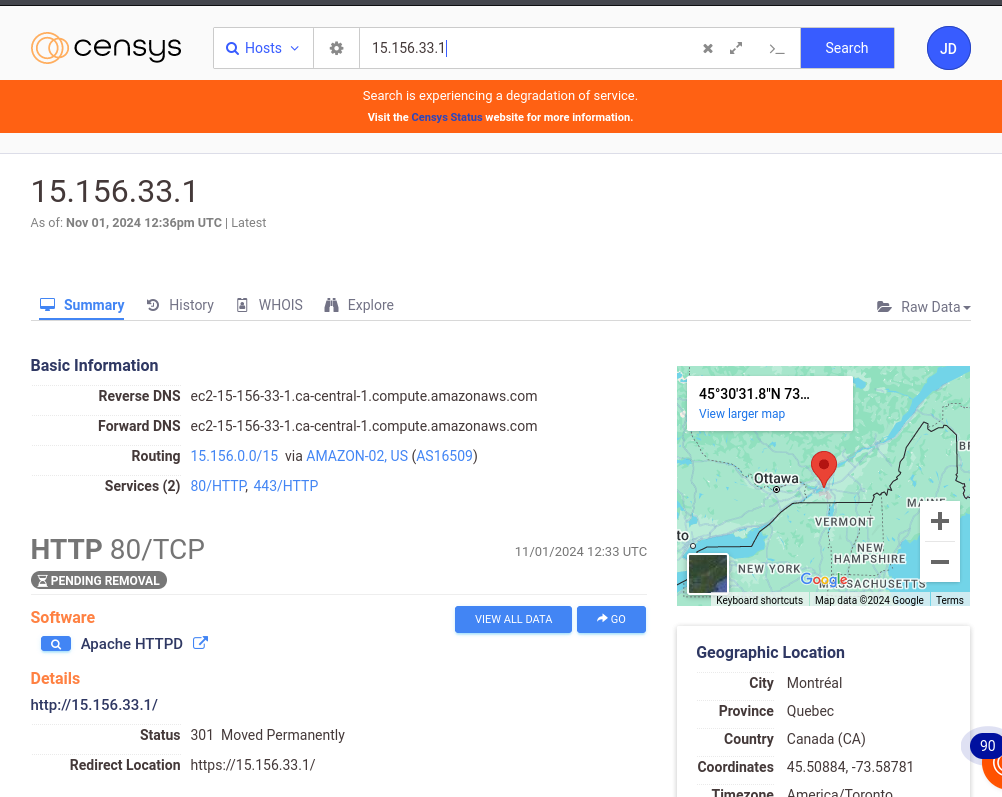
Censys
Censys est un moteur de recherche et une plateforme qui contient des données provenant de diverses sources sur les infrastructures connectées à Internet. Il dispose de données en temps-réel et retourne les informations sur des appareils, services ou des domaines. Il peut donc être très utile dans un processus de collecte d’informations sur une cible.
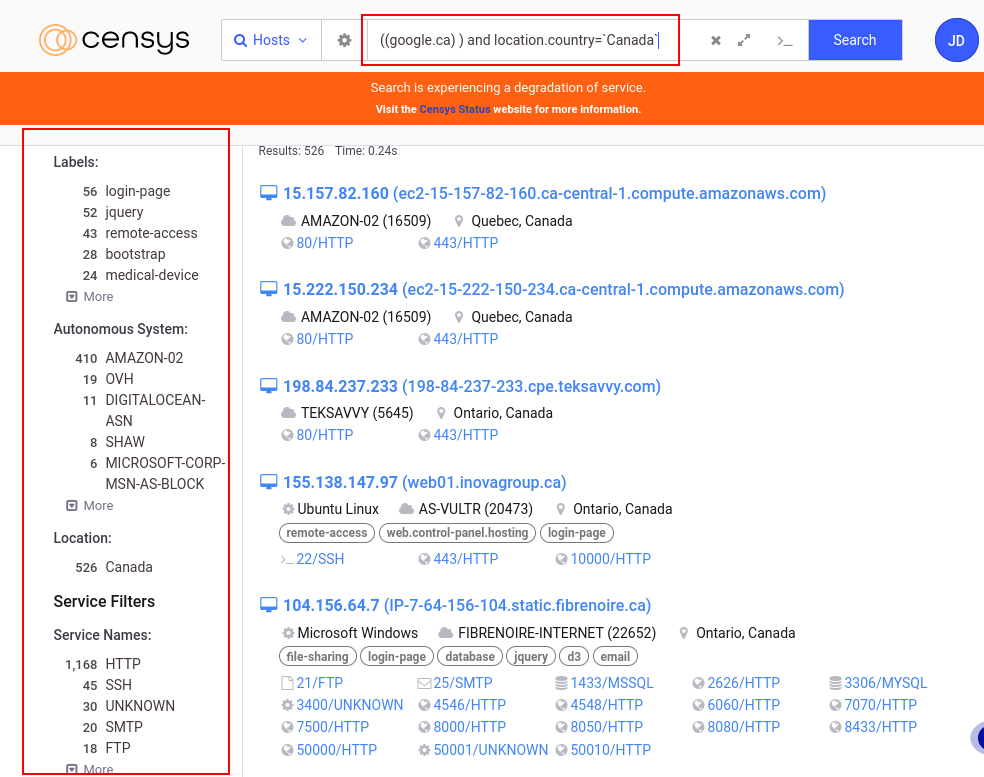
Censys permet de collecter des informations comme les adresses IP, les services et les ports ouverts. Avec les filtres avancés , on peut affiner les résultats selon les labels (hôtes IPV6, accès à distance, email etc.), les systèmes autonomes (AS), la localisation des serveurs, les fournisseurs de logiciels (Amazon, Akamai, Google, Apache, nginx)
En faisant une recherche sur Google, on peut voir qu’on a accès a beaucoup d’informations, et le résultat de la recherche retourne beaucoup d’hôtes qui pourraient être analysés.
En choisissant un hôte, on a d’autres informations comme le routage, les services , la localisation, l’historique des évènements associés et aussi un onglet Whois qui fournit des détails sur le propriétaire de l’adresse IP.
Enum4Linux
Enum4linux est un outil d'énumération pour extraire des données de systèmes utilisant le protocole SMB (Server Message Block). Il permet de recueillir divers informations à propos des comptes utilisateurs, des noms de domaines, les groupes locaux les dossiers partagés sur un réseau.
Options
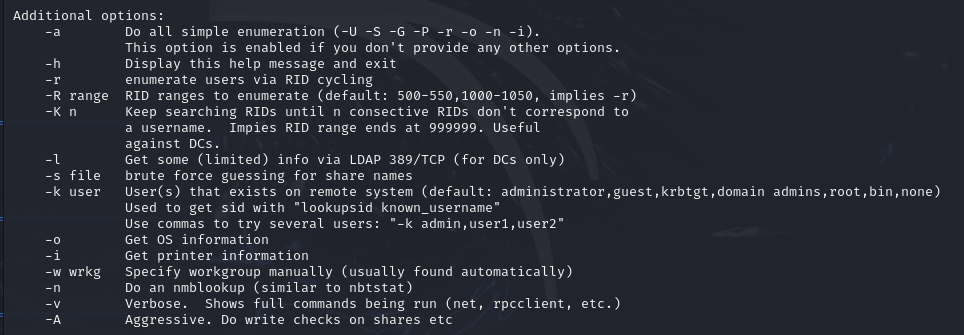
enum4linux -U -S -P -G [ip_adress]l’option
-Upermet de lister les utilisateurs sur le système ciblel’option
-Spermet de lister les partages disponibles sur le système ciblel’option
-Ppour afficher la politique des mots de passel’option
-Gliste les groupes du systèmel’option
-acombine toutes les options (-U -S -G -P -r -o -n -i). C’est l’option par défaut lorsqu’aucune n’est sélectionnée.
enum4linux -u [username]-p [password] -U [ip_adresss]- les options
-uet-pspécifient un nom d’utilisateur et un mot de passe
- les options
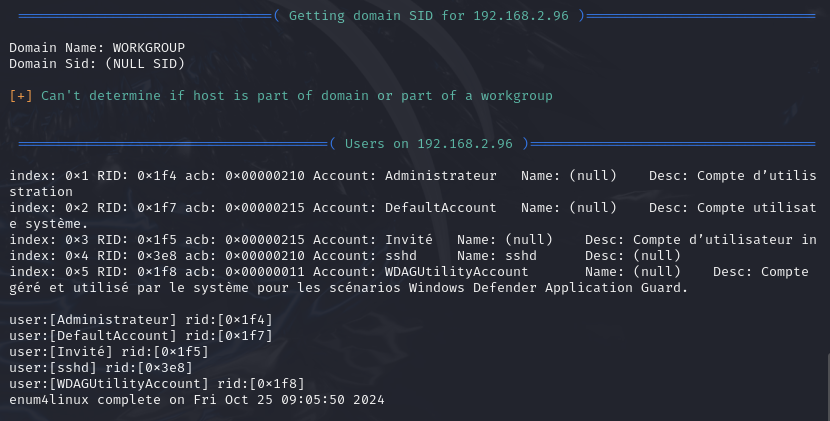
On y voit plusieurs utilisateurs sur le système: Administrateur,Invité etc
Enum4linux peut être très utile car les informations comme les utilisateurs, les partages de fichiers sur le réseau, ou encore les groupes et permissions peuvent être exploitées pour identifier de potentielles vulnérabilités.
WaybackURL
WaybackURL est un service qui permet d’accéder à des versions anciennes ou archivées de site web en utilisant l’Internet Archive, un service d'archivage de pages web. Il sert à consulter des anciennes versions de site web, et même si elles ont été modifiées, elle peuvent toutefois contenir des vulnérabilités qui n’ont peut être pas été corrigées ou toujours accessibles via ces archives.
La documentation officielle se retrouve sur GitHub.
Pour installer WaybackURL, utilisez la commande suivante:
go install github.com/tomnomnom/waybackurls@latest
Options
waybackurls -h: l’option-hpermet de lister toutes les options de waybackurlswaybackurls https://site.com -dates | grep [word]l’option
-datesaffiche la date d’archivage de chaque URLgrep filtre les résultats pour ne montrer que les URLs contenant le terme “word“
cat domains.txt | waybackurls | grep -vE "\.(js|txt)$" > urls.txtCette commande lit le fichier domains.txt et redirige la sortie vers waybackurl. Les résultats sont stockés à la fin dans le fichier urls.txt
l’option
-vEexclut les lignes correspondant à l’expression indiqué juste après(avec l’option -v) et active les expressions régulières étendues (avec l’option -E).l’expression
".\(js|txt)$"est utilisée pour correspondre à des chaînes de caractères qui se terminent par.jsou.txt.Cette commande va donc lister les URL archivées, en excluant celles qui se terminent par
.jsou.txt.
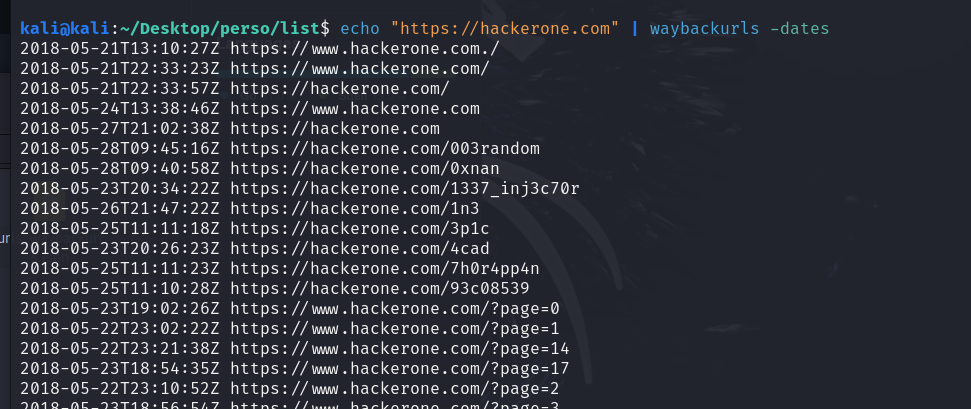
echo "https://hackerone.com" | waybackurls -no-subsl’option
-no-subsexclut les sous-domaines du domaine cible dans les résultatsCette commande affichera toutes les URLs archivées de
hackerone.com
Gowitness
Gowitness est un outil utilisé pour effectuer des captures d’écran de sites web, collecter des informations sur les en-têtes HTTP et créer des rapports sur les sites visités de manière automatisée.
Cet outil, même s'il peut sembler "inutile" parce qu'on pourrait simplement visiter les pages web, est en fait très pratique lorsqu'on a plusieurs sites à vérifier sans perdre un temps fou à les ouvrir un par un.
Pour l’installer, utilisez la commande suivante:
go install github.com/sensepost/gowitness@latest
Options
gowitness -h: cette option liste toutes les options de gowitnessgowitness scan -h: montre les options disponibles pour effecturer des scans.gowitness scan single --url https://google.com --screenshot-path ./PATH--screenshot-format png --screenshot-fullpagel’option
--urlindique à l’outil d’effectuer la capture sur l’URL spécifiél’option
--screenshot-pathdéfinit le chemin où la capture d'écran sera sauvegardée.l’option
--screenshot-formatdéfinit le format de la capture d’écran. Par défaut elle est en format JPEG. Et seuls les formats JPEG et PNG sont valides.l’option
--screenshot-fullpagecapture la page entière, plutôt que seulement la partie visible de la page. Elle est utile pour les pages avec beaucoup de contenu en défilement
gowitness scan file -f ./PATH --log-scan-errors --write-dbl’option
file -fspécifie un fichier contenant une liste d’URLs à afficherl’option
--log-scan-errorssignale les erreurs survenues lors des scans.l’option
--write-dbenregistre les résultats dans une base de données pour une consultation ultérieure.
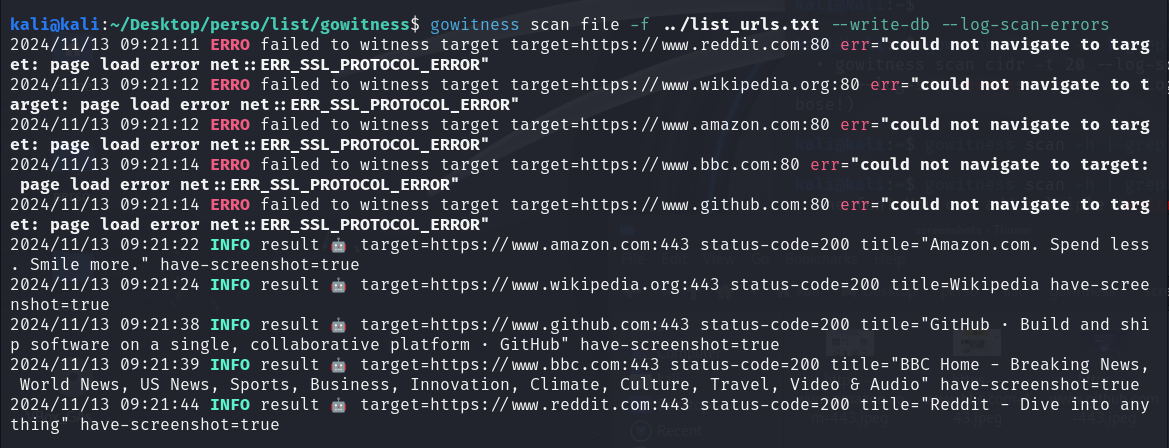
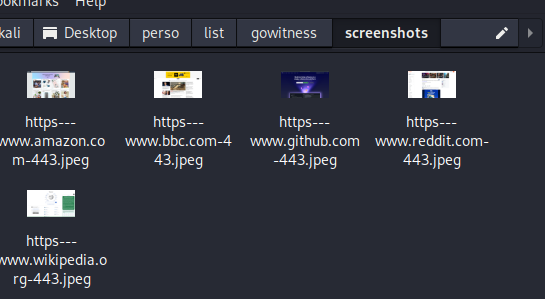
La photo ci-dessous montre l’exécution d’une commande avec gowitness. Des messages indiquent une tentative échouée via le port 80 pour les connexions non sécurisées en HTTP. Par contre, la connexion a réussi via le port 443 pour les connexions HTTPS, avec les captures d’écran prises.
KarmaV2
KarmaV2 est un outil de reconnaissance OSINT qui permet de trouver des informations publiques et approfondies sur une cible. La documentation officielle se retrouve sur GitHub.
Vous pouvez installer KarmaV2 avec les commandes suivantes
Cloner le répertoire
git clone https://github.com/Dheerajmadhukar/karma_v2.gitInstaller shodan et le module python mmh3
python3 -m pip install shodan mmh3Installer le parser JSON JQ s’il n’est pas déjà installé
apt install jq -yInstaller httprobe
go install -v github.com/tomnomnom/httprobe@master cd httprobe go build main.go mv main httprobe sudo mv httprobe /bin/Installer Interface
git clone https://github.com/codingo/Interlace.git cd Interlace pip install -r requirements.txt sudo python3 setup.py installInstaller Nuclei
go install -v github.com/projectdiscovery/nuclei/v2/cmd/nuclei@latestInstaller Lolcat
apt install lolcat -yInstaller anew
git clone https://github.com/tomnomnom/anew.git cd anew go build main.go mv main anew sudo mv anew /bin/Créez un compte sur Shodan.io pour obtenir votre clé API Shodan
Insérez la clé dans le fichier
.tokendans le répertoire /karma_v2nano ./token SHODAN_API_KEY_FROM_SHODANLancer karma avec la commande suivante
bash karma_v2 -h
Dépendamment de votre système, il est possible de devoir exécuter karma_v2 dans un environnement virtuel.
Options
bash karma_v2 -h: pour voir la liste de toute les options de Karma_v2bash karma_v2 -d [DOMAIN] -l [INT] -ip -cvel’option
-dspécifie le domaine;l’option
-iprecherche des adresses IP associées à ce domaine;l’option
-lspécifie le nombre de résultats lors de la recherche. On peut spécifier -1 pour indiquer un nombre illimité de résultats.l’option
-cverecherche les vulnérabilités associées au domaine.
Les options
-d,-let les options pour le mode (-ipou-asnou-cveetc..) sont requises pour exécuter karma_v2L’option
-deepprend en charge toutes les options count, ip, asn, cve, favicon, leaks.
Crunchbase
Crunchbase est une plateforme payante qui donne des informations sur les entreprises et les investisseurs. Elle fournit des données permettant d’analyser les acquisitions des entreprises sur le marché comme les startups, et aussi les membres de l’entreprise.
Arjun
Arjun est un outil qui permet de découvrir des paramètres HTTP cachés dans les requêtes GET et POST qui pourraient être vulnérables dans des applications web. Il permet d’identifer des points d'entrée potentiels pour des attaques en testant plusieurs paramètres possibles. Pour information, les requêtes GET et POST sont des méthodes pour envoyer des données à un serveur web. Le méthode GET consiste à envoyer les données via l’URL ; c’est-à-dire qu’elles apparaissent dans la barre d’adresse du navigateur. La méthode POST consiste à envoyer les données dans le corps de la requête HTTP, ce qui les rend invisibles dans l'URL. L’outil Arjun permet donc de chercher ces paramètres dans les applications.
La documentation officielle se retrouve sur GitHub.
Pour installer Arjun, utilisez la commande suivante:
pipx install arjun
Options
arjun -h: cette option affiche toutes les options de l’outilarjun -u http://website.com -m POST -o output.json -oBl’option
-upermet de spécifier le site à analyserl’option
-oenregistre les données dans un fichierl’option
-mpermet de définir la méthode HTTP à utiliser pour la requête. Les formats valides sont GET ou POST pour la méthode HTTP et JSON ou XML pour le corps de la requête.l’option
-oBredirige le trafic via Burp Suite pour l'analyse. Par défaut, Burp écoute sur127.0.0.1:8080. Cela va donc permettre de visualiser les requêtes et les réponses interceptées par Burp.
arjun -i urls.txt -w /PATH/TO/FILE --include “token=qwerty“l’option
-ispécifie un fichier avec une liste d’URLs à analyserl’option
-wpermet permet de spécifier un fichier contenant une liste de mots. Cette liste contient des noms de paramètres potentiels qu'Arjun utilisera pour tester l'URL cible. Par défaut, l’outil utilise une liste de mots intégrée située à{arjundir}/db/large.txtl’option
-inlcudepermet d’insérer des données pour chaque requête. La variable token avec une certaine valeur dans le cas d’applications nécéssitant des jetons d’authentifications. On pourrait inlure tout type de données comme des clé APIs, des clé d’authentification et autres.On peut aussi mettre les options
-m XML --include='<?xml><root>$arjun$</root>'qui incluent une structure XML spécifique dans la requête. Le marqueur$arjun$est l'endroit où l’outil va insérer les paramètres qu'il teste.
Interprétation des résultats
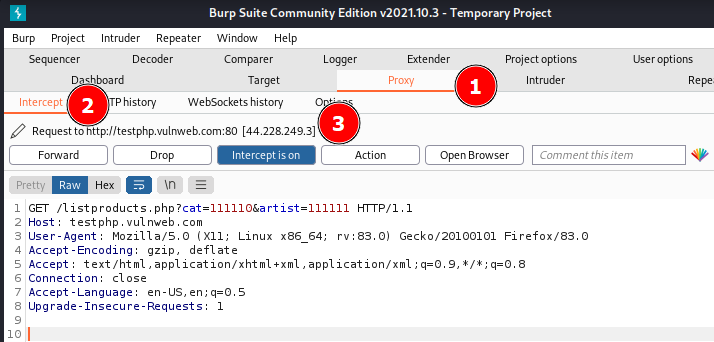
L’image ci-dessus montre la commande arjun -u http://testphp.vulnweb.com/listproducts.php -oB -o output.json exécutée.
On voit que la commande a identifié les paramètres artist et cat dans le corps la réponse.

Pour que l’option -oB fonctionne, il faut que Burp soit ouvert et configuré pour intercepter les requêtes. Vous pouvez ouvrir un terminal et lancer Burp avec la commande burpsuite. Allez dans les paramètres du Proxy et vérifiez que l’adresse du proxy sur Burp est bien configuré sur 127.0.0.1:8080. Activez ensuite l’interception.
On voit donc deux paramètres de requête “cat=111110“ et “artist=11111“ et d’autres détails comme l’hôte, le logiciel client etc.
Ces outils présentés sont adaptés lors d’une phase de reconnaissance dans le cadre d'un test de sécurité ou de bug bounty, où l'objectif est de découvrir des vulnérabilités potentielles en recueillant des données sur la cible.
À noter, qu’il est important de rappeler que l'utilisation de ces outils doit toujours se faire dans un cadre légal.
Subscribe to my newsletter
Read articles from FIKARA BILAL directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
FIKARA BILAL
FIKARA BILAL
As a newcomer to the cybersecurity industry, I'm on an exciting journey of continuous learning and exploration. Join me as I navigate, sharing insights and lessons learned along the way