El Camino Hacia la Comprensión Infinita: Cómo los Nuevos LLMs Revolucionan la IA
 Roberto Andrade Fonseca
Roberto Andrade Fonseca
Los modelos de lenguaje masivo (LLMs, por sus siglas en inglés) han transformado nuestra interacción con la tecnología, desde la redacción de correos electrónicos hasta la generación de contenido creativo. Estos sistemas, entrenados con vastas cantidades de texto, identifican patrones y contextos para producir respuestas coherentes y relevantes. Sin embargo, una limitación significativa ha sido su capacidad para manejar contextos extensos sin perder información crucial. La innovación presentada en Infini-attention promete superar este obstáculo, redefiniendo nuestra interacción con la inteligencia artificial.
LLMs: Más que Grandes Modelos de Texto
Los LLMs son sistemas entrenados con cantidades colosales de texto para comprender patrones lingüísticos y semánticos. Imagina a un bibliotecario que no solo memoriza cada libro, sino que también puede predecir qué viene después en cualquier página o incluso crear nuevos textos coherentes basados en todo lo que ha leído.
A nivel técnico, estos modelos no procesan palabras como lo hacemos los humanos. En lugar de eso, descomponen oraciones en unidades llamadas tokens —pequeñas piezas de texto como palabras o partes de palabras— y utilizan esos tokens para aprender relaciones estadísticas. Esto les permite generar respuestas altamente coherentes y relevantes. Sin embargo, la habilidad de manejar contextos amplios es crítica, y aquí es donde su diseño original encuentra barreras significativas.
La Revolución de la Atención: Attention is All You Need
En 2017, el artículo Attention is All You Need introdujo el modelo Transformer, una arquitectura que cambió el juego en el mundo del procesamiento del lenguaje natural (NLP). Su componente clave es el mecanismo de atención, una técnica que permite a los modelos enfocar su procesamiento en las partes más relevantes del texto.
¿Cómo funciona? La atención crea representaciones numéricas (vectores) para cada token en una entrada y luego evalúa qué tan importante es cada uno en relación con los demás. Para lograrlo, utiliza tres elementos: queries (consultas), keys (claves) y values (valores). Imagina que estás buscando una palabra clave en un libro. El modelo utiliza las queries para hacer preguntas como ¿Qué tan relevante es este token?, las compara con las keys para evaluar similitudes, y luego selecciona los values que necesita procesar. Este proceso permite al Transformer mantener el contexto de las palabras a lo largo de una oración o incluso un párrafo.
El problema es que este mecanismo, aunque efectivo, es intensivo en términos de memoria. Cada token en una entrada necesita conectarse con todos los demás, lo que significa que el costo computacional crece exponencialmente con la longitud del texto. Este diseño limita su capacidad para procesar secuencias largas.
La Memoria Perdida: Una Limitación Crítica
Uno de los problemas más frustrantes para los usuarios es la incapacidad de los LLMs para recordar interacciones previas. Cada vez que inicias una conversación nueva con un modelo como ChatGPT, el contexto de tus charlas anteriores desaparece. Esto significa que tienes que proporcionar el trasfondo cada vez, lo cual es ineficiente y poco intuitivo. En aplicaciones prácticas, como asistencia médica o tutorías personalizadas, esta amnesia puede llevar a interacciones fragmentadas y poco satisfactorias.
En tareas más complejas, como el análisis de datos a largo plazo o el seguimiento de conversaciones empresariales extensas, esta limitación puede convertirse en un obstáculo crítico. No solo implica un mayor esfuerzo para los usuarios, sino que también limita la profundidad y calidad del análisis que el modelo puede ofrecer. En resumen, la falta de una memoria robusta no solo afecta la experiencia del usuario, sino también el valor práctico de estas herramientas en contextos reales.
Infini-attention: Un Salto hacia la Comprensión Infinita
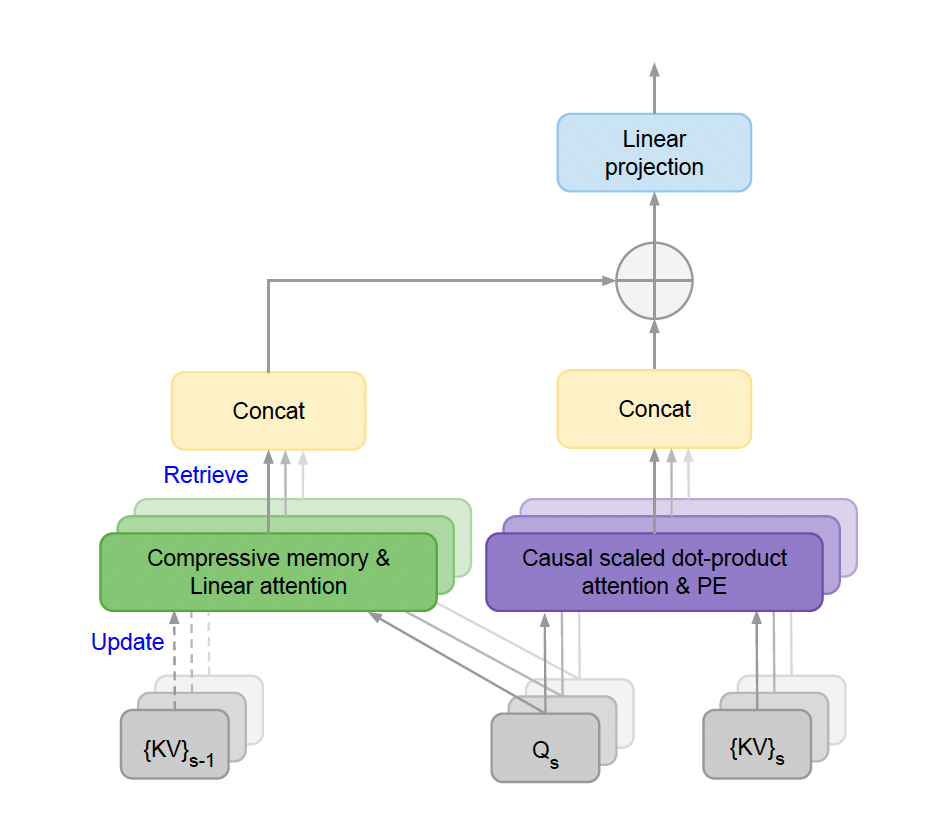
El trabajo reciente en Infini-attention aborda directamente estas limitaciones al introducir un enfoque revolucionario para manejar contextos infinitos. Este mecanismo incorpora una memoria compresiva que almacena información clave de manera eficiente, permitiendo a los modelos recuperar contexto pasado sin sobrecargar los recursos computacionales.
En lugar de desechar las conexiones previas entre tokens, como ocurre en la atención estándar, Infini-attention guarda estas conexiones en una memoria que se actualiza continuamente. A nivel técnico, combina la atención local —que maneja dependencias cercanas en los datos— con una memoria lineal que almacena información de largo plazo. Este diseño híbrido permite que los modelos procesen secuencias de longitud arbitraria, como libros completos o bases de datos históricas, con un costo computacional fijo.
Ventajas de la Memoria Infinita
¿Por qué es importante esta innovación? Primero, permite que los modelos recuerden información crítica de interacciones previas, haciendo que las conversaciones sean más fluidas y contextuales. Imagina un asistente virtual que no solo responde a tus preguntas, sino que también recuerda tus preferencias y necesidades a lo largo del tiempo, ofreciendo recomendaciones más precisas y personalizadas.
Además, en aplicaciones industriales, esta capacidad puede transformar áreas como:
Educación personalizada: Los tutores virtuales podrían recordar el progreso de los estudiantes y adaptar sus estrategias de enseñanza.
Análisis financiero: Los sistemas podrían procesar años de datos históricos para ofrecer predicciones más precisas.
Diagnósticos médicos: Modelos que analicen historiales médicos completos para detectar patrones y ofrecer mejores diagnósticos.
Resultados Prometedores
Las pruebas iniciales de Infini-attention han producido resultados sobresalientes. Los modelos equipados con esta tecnología pueden procesar secuencias de hasta un millón de tokens, superando ampliamente a los modelos tradicionales. En tareas como el resumen de libros completos, estos sistemas establecieron nuevos estándares de precisión y eficiencia.
Un aspecto destacable es su eficiencia en memoria. Infini-attention utiliza hasta 114 veces menos memoria que los métodos convencionales, gracias a su enfoque basado en compresión. Esto no solo reduce costos, sino que también hace que los modelos sean más accesibles para aplicaciones comerciales y de investigación.
Un Futuro Redefinido por la Memoria
La capacidad de procesar contextos infinitos tiene implicaciones profundas en la evolución de la inteligencia artificial. Por ejemplo, los modelos podrían volverse auto-reflexivos, aprendiendo continuamente de sus interacciones y adaptándose de manera más eficiente. Esto podría llevarnos a sistemas que no solo respondan preguntas, sino que también ofrezcan análisis predictivos complejos o incluso actúen como mentores para los usuarios.
Sin embargo, también plantea desafíos éticos y técnicos. ¿Cómo garantizamos que estos sistemas no perpetúen sesgos o almacenen datos sensibles sin el consentimiento adecuado? La capacidad de recordar implica responsabilidad, y el diseño de estas tecnologías debe considerar cuidadosamente cuestiones de privacidad y seguridad.
Conclusión: Más Allá del Horizonte
Infini-attention es un avance crucial que podría redefinir la manera en que usamos los modelos de lenguaje masivo. Al abordar la limitación crítica de la memoria, esta tecnología abre la puerta a aplicaciones más robustas, personalizadas y útiles en todos los aspectos de nuestra vida digital. Desde conversaciones más fluidas hasta análisis profundos y continuos, los beneficios son enormes.
El futuro de los LLMs no es solo ser más rápidos o precisos; es ser más inteligentes y conscientes del contexto en el que operan. Con Infini-attention, estamos un paso más cerca de lograr sistemas verdaderamente integrados en nuestras vidas, capaces de comprender y adaptarse a las complejidades de nuestro mundo.
Fuente: Este artículo incorpora ideas del trabajo original sobre Infini-attention y del análisis presentado en VentureBeat.
Subscribe to my newsletter
Read articles from Roberto Andrade Fonseca directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by