Understanding Data Literacy: The Essential Skill for the Information Age
 Queen Carine
Queen Carine
Data Literacy Is A Life Skill
Why learn about data literacy? Just as we had to adjust to using computers and the Internet, we now live in a time where data is all around us. As a consequence, to keep up with the changing world, it is essential to know data, know how to interact with it and know what it can and cannot do. Data literacy has become an essential skill for individuals and organizations alike. It is no longer confined to analysts or statisticians; it is a critical competency for everyone. Compare this with learning how to drive a car: it is not necessary to know all the bits and pieces under the hood or how to repair it, but you do need to know the difference between the brakes and the gas, know how to follow the instructions of traffic signs, and that you can't drive in water. This article delves into data literacy, why it matters, and how it empowers us to navigate the ever-evolving digital landscape.
What is Data Literacy?

Data literacy is the ability to read, understand, create, and communicate data as information. It involves interpreting data accurately, recognizing patterns, and using insights to make informed decisions. Much like traditional literacy, it's about understanding and effectively using a language—in this case, the language of data.
From data to insights
One of the main reasons why data is so important is the added value of turning data into insights.
The DIKW pyramid
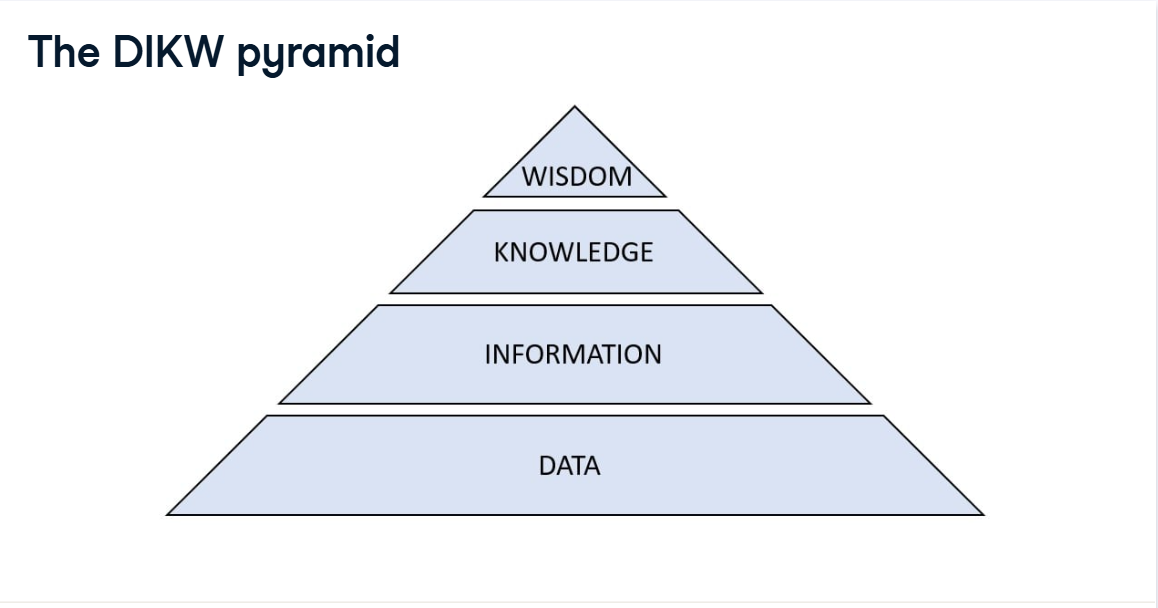
We can use the Data-Information-Knowledge-Wisdom framework to understand the value of data better. Each step of this pyramid represents a new step we can take. The higher we go, the more value we can get from data, from raw data to perfect wisdom. In the following slides, we'll break down each step.
DIKW pyramid: Data
Raw data consists of loose observations or measurements. It has yet to have meaning. It needs to be more organized and unprocessed. For example, we can measure with a thermometer that it is 15 degrees Celsius, observe dark clouds, and that some raindrops are falling.
DIKW pyramid: Information
Information consists of raw data placed into context. This is typically done by organizing or aggregating data. In the weather example, we can manage our raw data by putting it in order: first, the temperature drops, then it becomes cloudy, and then the raindrops fall.
DIKW pyramid: Knowledge
In the knowledge step, we combine information to connect, learn, and gain meaning. This is typically done by detecting patterns and making generalizations or predictions. In the weather example, we can surmise the possible causal connection between temperature, clouds, and raindrops and use this to predict whether it will rain.
DIKW pyramid: Wisdom
Wisdom is applied knowledge or knowledge in action, allowing us to act proactively. This is typically done by combining knowledge logically to determine the course of action. To return to our weather example, with my accumulated wisdom, I know when it will rain and when to bring my umbrella.
Data-driven decision making
We will discuss how to get the most value from data through data-driven decision-making.
Data-driven decision-making can be defined as follows: "It is the process of using data to make an informed decision about a specific problem and acting upon it." It can optimize performance, gain a better understanding, protect against risks, or determine the best course of action.
Misconceptions about data-driven decision making
Data-driven decision-making is not just for large organizations; you can start small. It is not just the responsibility of the data team; in fact, by including people with different backgrounds, the data-driven process will be enriched. It is one of many or always the best options. Data-driven decision-making is a strategy with its advantages and disadvantages.
Data-driven process
Five main steps underpin every data-driven process, no matter what type of project you undertake. The first -and very important- step is defining a problem statement, which will guide the rest of the process. The second step is to collect the necessary data. The third step is to perform data analysis. The last two steps are about communicating the results and taking action on our newly gained insights while reflecting on the process.
Data is all around us
What is data?
When you think of data, think of something like this: a table with many numbers. Or you may have a graph in your mind. While this is one of the most common forms of data, there are also forms you might need to consider.
Data comes in all shapes and sizes.
Take images and text, for example. Digital photos have many tiny pixels, each with its own color value. These pixels and their color values can be used as data to detect what can be seen in the image automatically. Social media posts, emails, and reviews are all text that can be analyzed to answer specific questions. For example, we could do a Twitter analysis of a soccer match to find out whether people found it exciting or looking at the words they used and their frequency.
Other forms of data include network and spatial data. Network data can answer questions like "Are many social connections linked to happiness?" Or spatial data can be used to answer questions such as: "Where is the best place to open a new coffee shop?"
Data sources: open data
Nowadays, a lot of data is publicly available. This is especially the case with government or non-profit data. Your local government will also provide data on social or economic topics on its website. APIs are another excellent source of data. APIs act as a go-between to collect specific data on the Internet. The Twitter API, for example, allows you to collect tweets about a particular subject quickly and easily.
Data sources: internal data
Another critical data source is internal data. This data is shared with you or your business under specific conditions. This data is not publicly available and typically is protected by privacy regulations. For example, customer data, such as age or how long they have been customers—transaction data, like the sales number for a particular product. Data can also come from a website, like the number of visitors each day or which part of the website gets the most clicks. Lastly, surveys could be used to gain specific data on a certain topic, such as satisfaction with a particular product or service.
Common data types
Importance of the data type
We'll often have to use different data types to get a complete picture in an analysis. The data type mainly affects how to collect the data, how to store the data, and how to analyze the data. We need to make two main distinctions: whether the data is structured or unstructured and whether the data is qualitative or quantitative.
Structured vs. unstructured data
Structured data is data in tabular form, organized in rows and columns. Because it has such a strict structure, a computer can easily read and use it. It is typically stored in relational databases. Spreadsheets, like Excel, are a typical example. Unstructured data, on the other hand, has no pre-defined structure. Because of that, more preprocessing is necessary before this type of data can be used in an analysis. Unstructured data is typically stored in document databases. Examples are images, videos, sound files, and texts like email, social media posts, or ratings.
Quantitative vs. qualitative data
The second important distinction is between quantitative and qualitative data. Quantitative data describes something numerically; it can be measured or counted, like the distance between home and work. If we were to describe ice cream quantitatively, for example, we could measure or count things like the number of ice cream scoops, the minutes before the ice cream starts to melt, or the length of the cone. Qualitative data, however, describes something with categories that can be observed, like the color of your eyes. Unlike quantitative data, calculating statistics and analyzing qualitative data is more restricted. For example, we can calculate the average length, but the average color would make little sense. If, on the other hand, we would qualitatively describe ice cream, we could talk about the flavor of the ice cream, the color, or whether we want a cone or a cup.
Managing data
Databases: basic concepts
A database is a general, loose term for the storage of data. A database is typically managed with a database management system; this is software that allows the user to store, retrieve, and access the data. There are several specialized types of databases—a document database stores unstructured data. Relational databases store structured data. These are called 'relational' because they usually store multiple databases that are related to each other. For example, one data table contains the sales data of a particular product. Another data table can be accessed through the customer ID to get the complete customer data. Another important distinction is a data warehouse versus a data lake. A data warehouse contains processed, organized data in preparation for further analysis.
On the other hand, a data lake stores raw data that has yet to be prepared. Typically, a data engineer's responsibility is designing and optimizing database systems. They help ensure that the necessary data is available and ready for use.
Data storage in the cloud

A lot of data is stored in the cloud nowadays, which means the data is stored on remote servers and accessed over the Internet. A specialized third party typically provides these services. Storing data on the cloud instead of on-site servers is more flexible and cost-effective. Still, it can be problematic with sensitive data, as you would be dependent on the security of the third-party provider.
Automation through data pipelines
The purpose of pipelines is to move data from one database to another. This process can be automated using the ETL framework. ETL stands for Extract, Transform, Load, which refers to the different processing steps. Making use of pipelines ensures the availability of up-to-date and accurate data.
Getting data from databases
Retrieving data from databases is also called 'querying.' The industry standard for querying is SQL, which stands for Structured Querying Language. Further analysis can be done with programming languages like R and Python.
Dashboards

Another way to leverage the data available in databases is through dashboards. Databases are very technical, but dashboards offer a non-technical alternative to collecting, managing, and sharing data between teams. A dashboard provides information at a glance, typically metrics such as Key Performance Indicators to follow up on business goals. A dashboard has access to the data by being linked to a database. Dashboards typically show data in a very visually appealing way. They can be used for multiple purposes, including fundamental analysis or communication. Creating and managing dashboards is generally the responsibility of a data analyst.
Common data problems
Dirty data
Dirty data is incorrect, incomplete, or inconsistent data. Human error, technical issues, or selective data collection can cause it. Realistically, starting with data problems such as these is usually unavoidable. You must recognize dirty data as, if not resolved, it can eventually lead to data, not representative of what we are trying to analyze, leading to flawed analysis and wrong conclusions. Compare it with a dirty window: if it is filthy, you cannot see it on the other side until you clean it.
Data errors
Data errors consist of incorrect or inconsistent data. For example, they are typing errors or dates in the wrong format. Recording errors typically cause them. They can quickly be resolved if the original value or valid format is known. Otherwise, the data points in question need to be dropped.
Missing data
We say the data is missing if some data points are left blank. For example, some respondents may need to answer specific questions if you conduct a survey. Missing data can be especially problematic if many data points are missing or if there are underlying patterns in the missing data. For example, if only older adults or some other group did not answer the survey questions. Depending on the severity of the problem, the data can be dropped or imputed. The latter technique allows us to estimate the missing values statistically.
Data bias
The data can also take on real-world characteristics as we use real-world data. This means that societal bias can be reflected in data bias. Severely biased data can lead to unrepresentative data and results like foul data. Unfortunately, data bias can be hard to detect and resolve. The best way to counter data bias as much as possible is to ensure a solid data collection process and be aware of potential bias in our conclusions. Lastly, explainable AI techniques can more easily detect possible biases during analysis, making the models' output more interpretable.
Data cleaning
Data cleaning consists of a set of techniques to counter data problems. It is a necessary preparation step for any analysis, so allocate the required time. Not all data problems are solvable, however. For example, if you need to know the correct value of incorrect data. Even if the data is severely compromised due to data problems, it is always possible to do some analysis. For example, a descriptive study can be performed to identify the data problems and use that to improve the data collection process.
Data Literacy: A Cornerstone for the Digital Era
Data literacy—the ability to read, interpret, and communicate data—has become essential in today’s information-driven world. It involves understanding data's journey from raw form to actionable insights, as illustrated by the DIKW (Data-Information-Knowledge-Wisdom) pyramid. Structured and unstructured data types, alongside quantitative and qualitative distinctions, form the foundation of analysis. Sources like open data, internal databases, and cloud storage provide vast opportunities, but challenges like dirty data and biases require careful cleaning and preparation. Data-driven decision-making empowers informed actions, while tools like dashboards simplify complex analytics for broader audiences. In mastering these skills, individuals and organizations can unlock the true potential of data in problem-solving and innovation.
Subscribe to my newsletter
Read articles from Queen Carine directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Queen Carine
Queen Carine
As a Data Analyst, I'm passionate about turning data📊📈 into actionable insights that drive smarter decisions. On this journey, I share my experiences, challenges, and the tools I’m learning along the way. Join me as I explore the world of data analytics and uncover new ways to make data work for you.