Kubernetes 101: Part 12 : ETCD, KubeAPI server, Controller, Kube-scheduler, Kubelet, Upgrade cluster, backup etcd
 Md Shahriyar Al Mustakim Mitul
Md Shahriyar Al Mustakim MitulETCD
ETCD is an open-source, distributed key-value store that is used to store that is simple, secure and fast
A Key value store
This format is to store values in the format of key-value pair
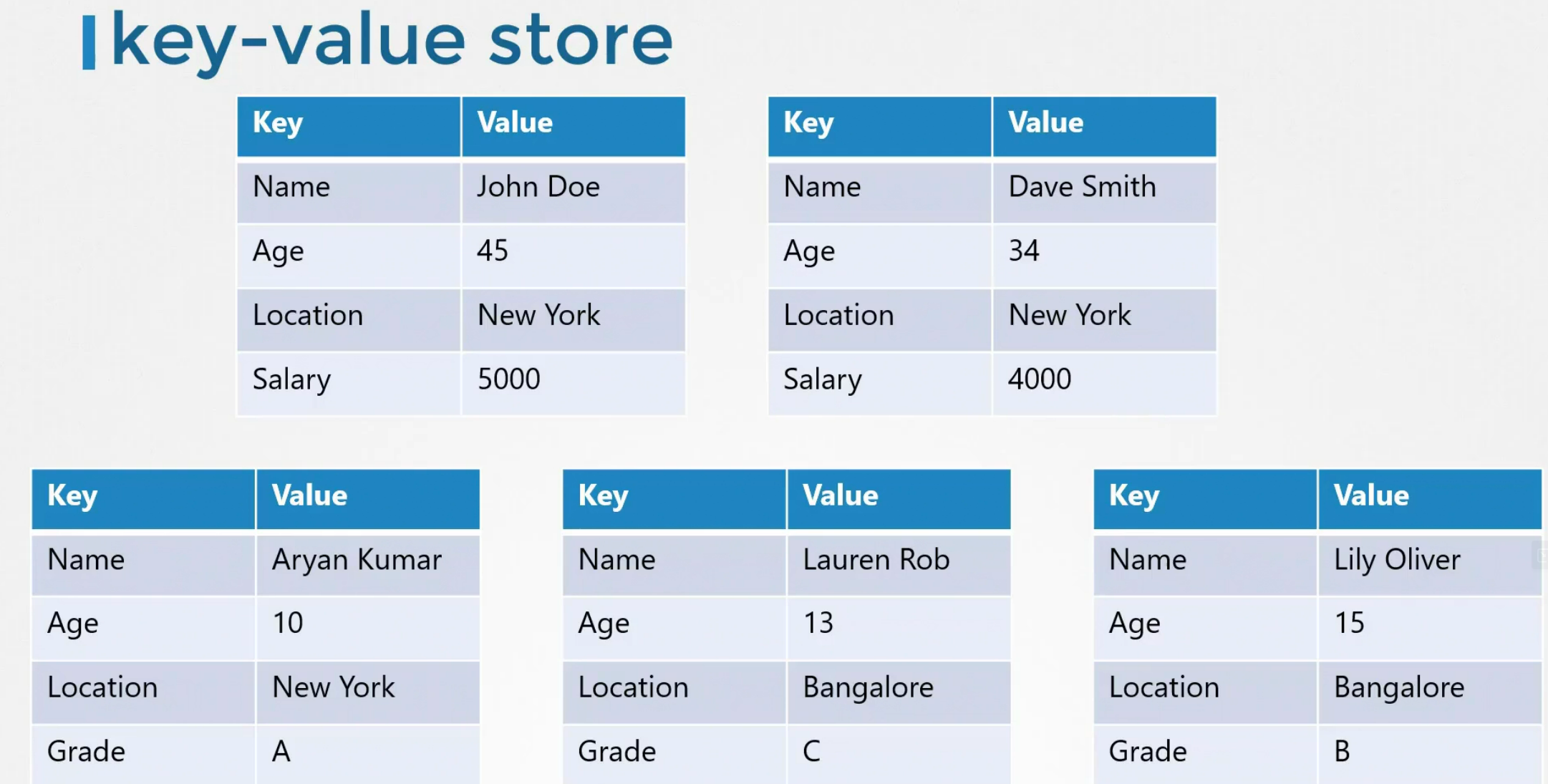
How to install etcd?
Download binaries and then extract it and run the executable
Once you run it , the etcd service listens to the port 2379
Then we can attach any client with the etcd service to store and retrieve information. A default client that comes with etcd is etcd control client (a command line client for etcd). We can store and retrieve key value pairs.
How to store one key value pair in etcd?
To do that, run using etcd control client (etcdctl)

now the key1:value1 is saved. To retrieve it, run this

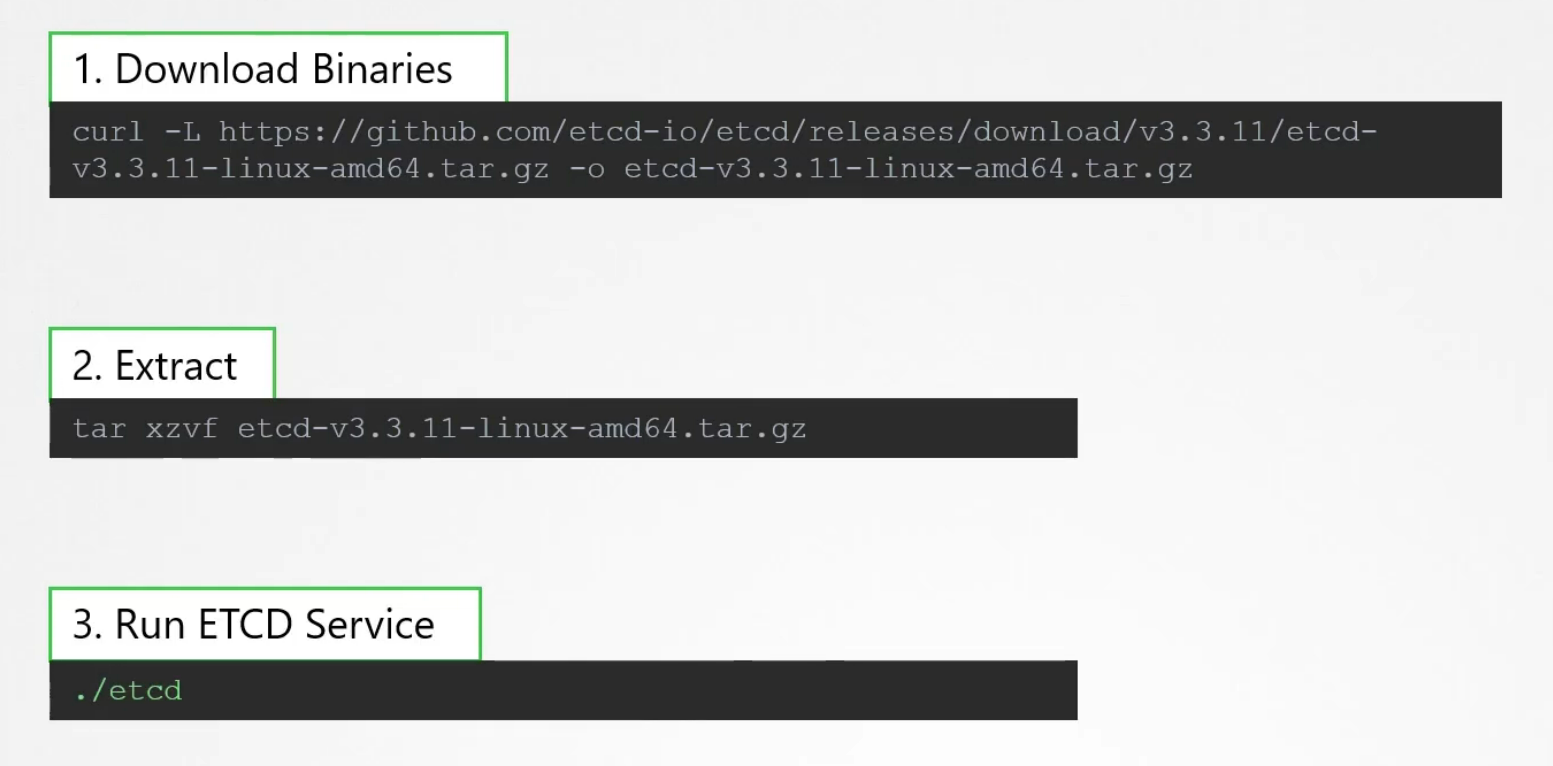
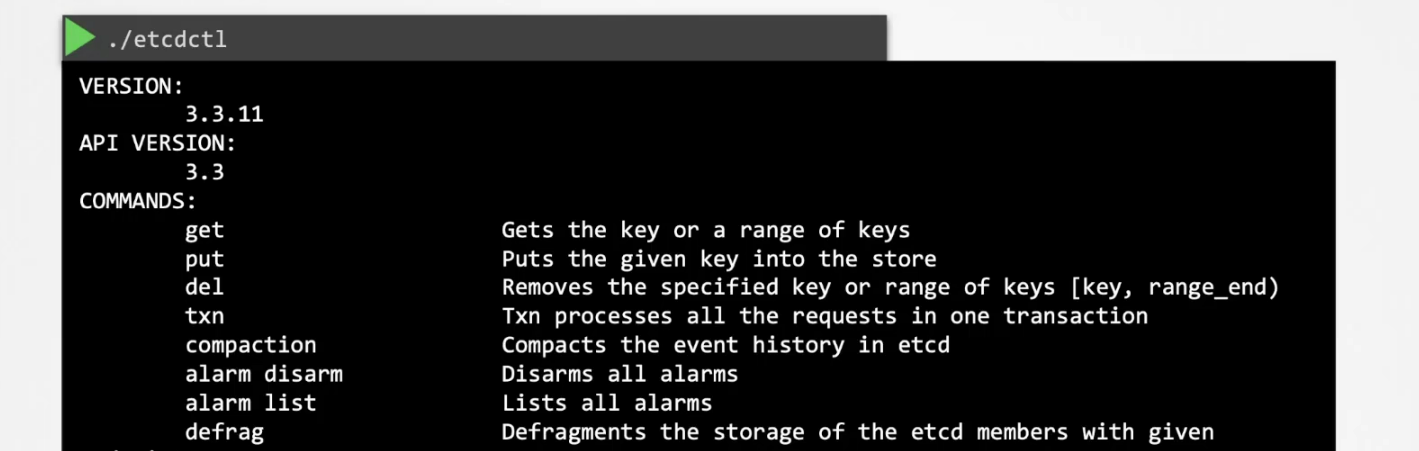
You can see more commands using ./etcdct1 command
Also another thing we need to keep in mind is etcdctl version
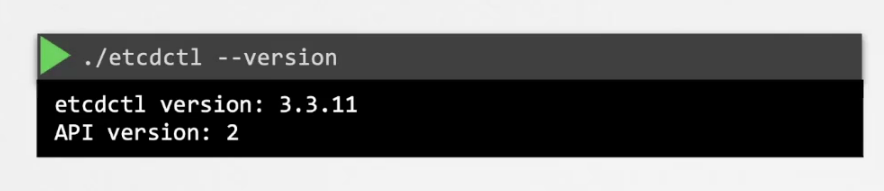
Here etcdctl version and API version is shown. From version etcdctl version 3.4, the API version is now 3. You can also specify which version of API you want to work with. For example, if you want to work with version 3, you can pass it or export it.
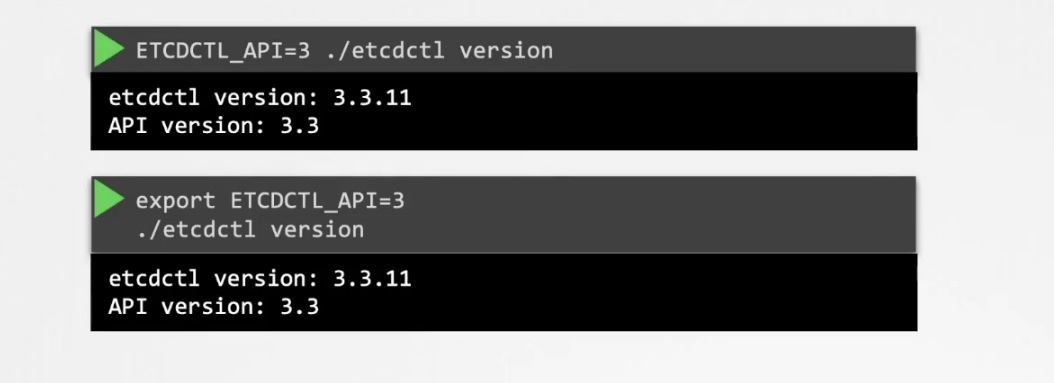
Note : In API version 3, version is now a command.
But you may say why? Why to change the API version? Yes, actually in version 3, the command to set key value is different. There are so many commands different to API version and you can just check the using
For example, now with API version 3, you have can save key value pair by this
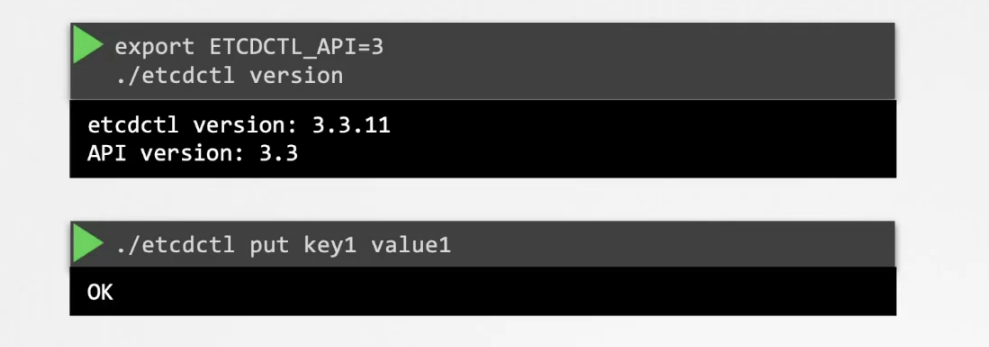
To retrieve it, use this one

By the way, why do we need ETCD in kubernetes?

Basically in kubernetes, it stores all the key value pair for nodes, pods , configs etc.
Depending on the deployment, the etcd cluster is set differently. We will focus on 2 types of deployments:
Deployed from scratch
Deployed using kubeadm tool
Once deployed form scratch, one downloads the binary and activate etcd as a service
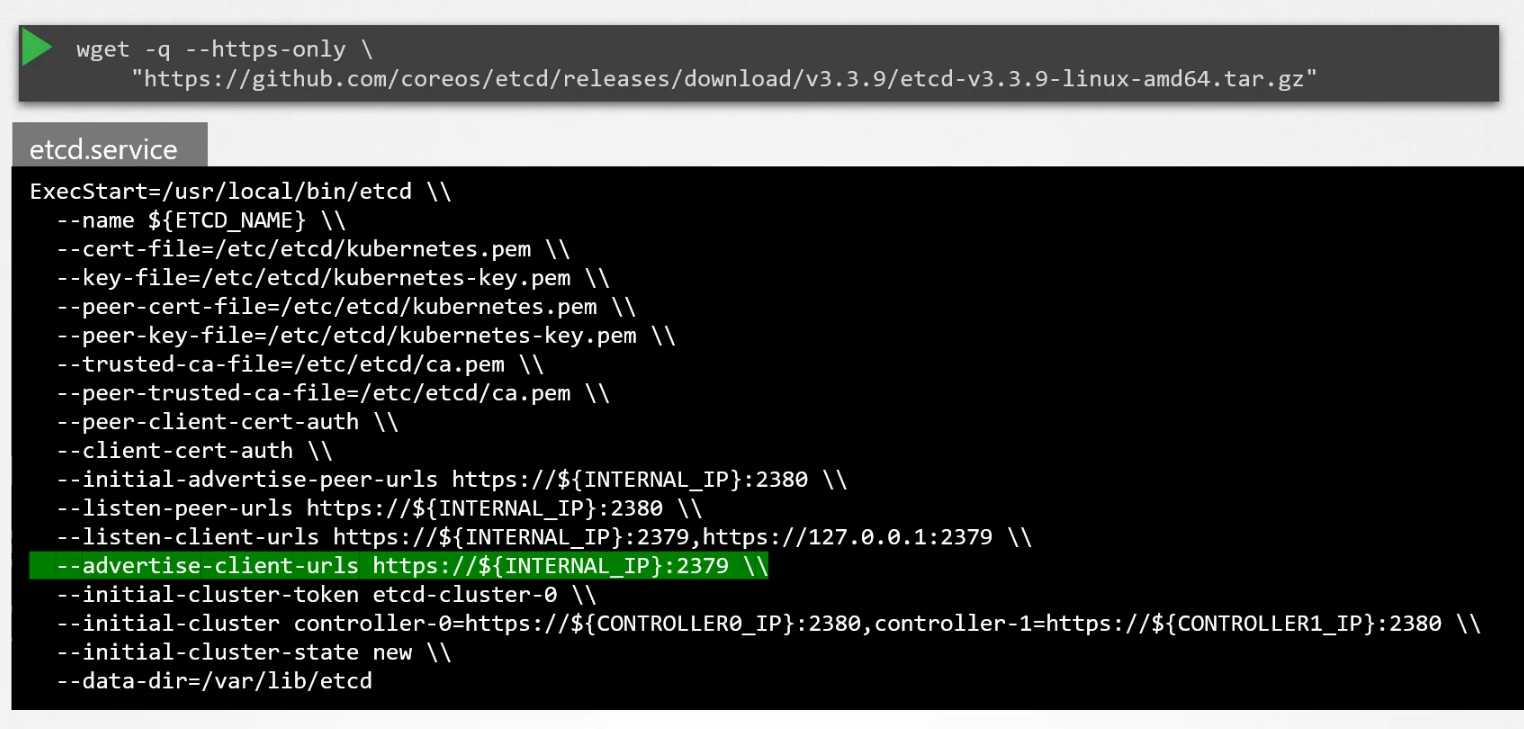
Here you can see the etcd listens to port 2379
But if we deploy etcd using kubeadm, then this etcd is deployed as a pod in the system.
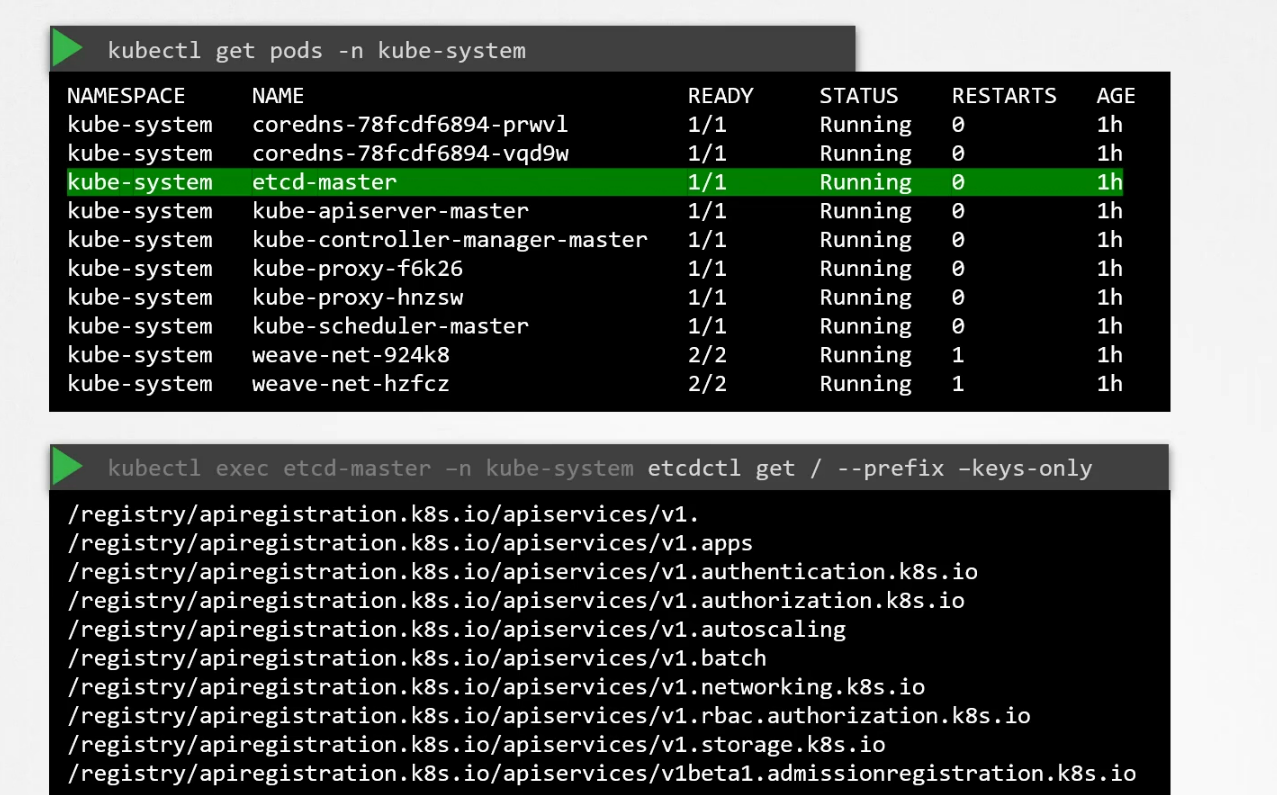
You can also see all of the keys kept in etcd here.
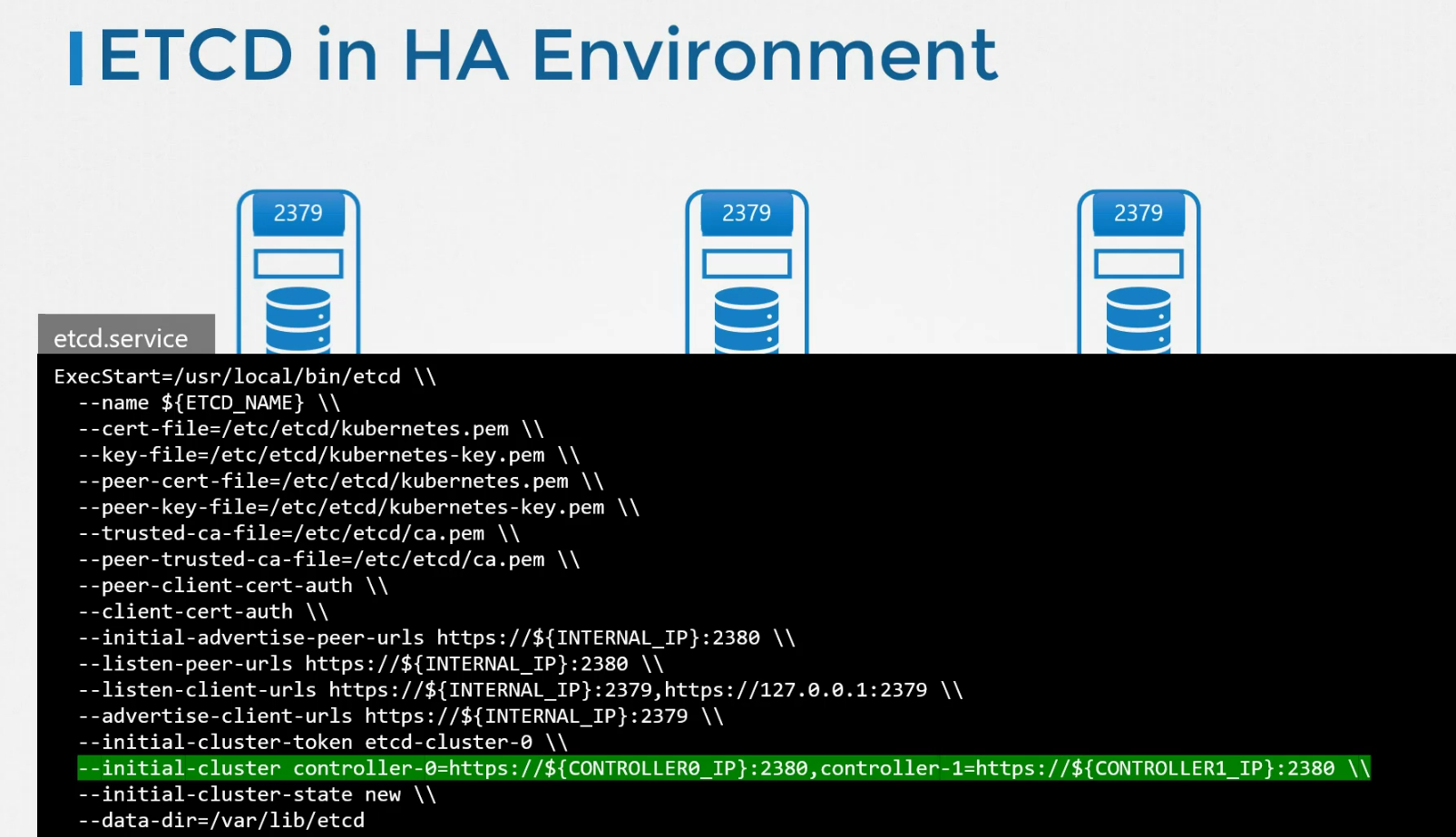
In a big and High Available environment, there will multiple master and therefore multiple etcd. Make sure that each etcd knows about other one.
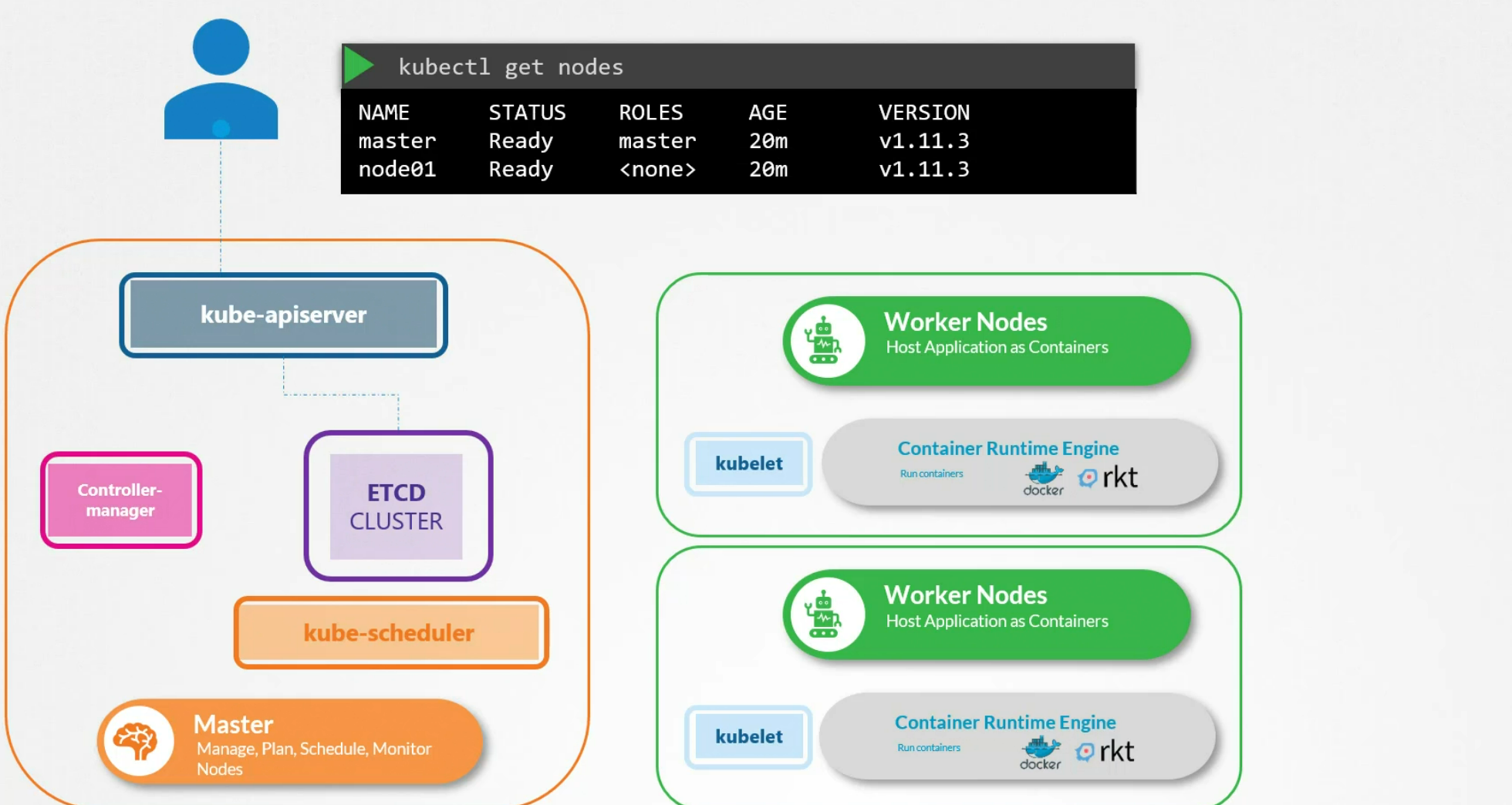
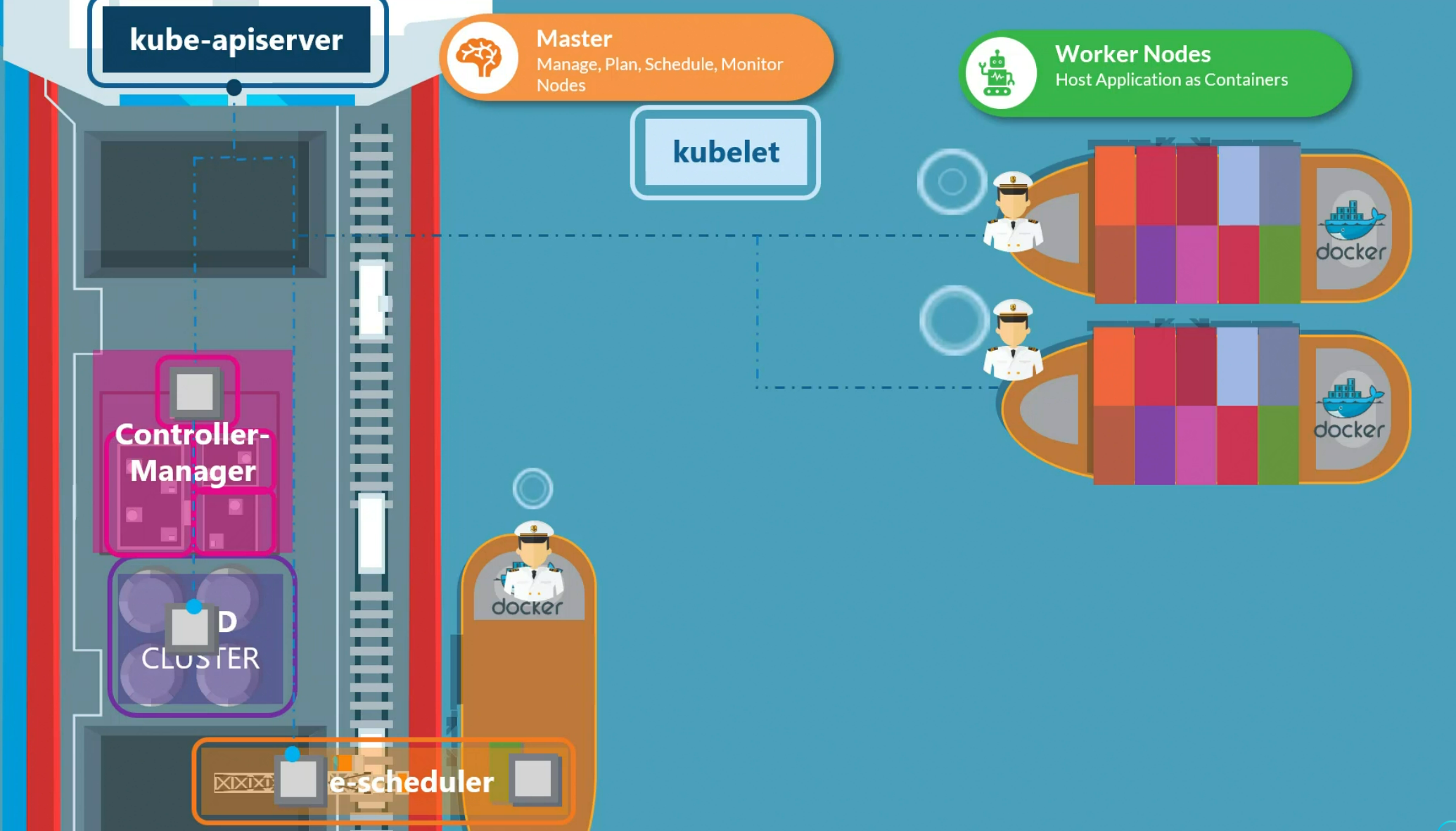
Kube API server
When you use kubectl to get any information , it first reaches to kube-apiserver and once it validates, it goes to etcd cluster and retrieves key-value pair according to your need. Then the kubeapi server gets the information and shows you
We could have done the same thing without using kubectl command. How? We could use API requests to authenticate user, validate the request and retrieve the data from etcd cluster
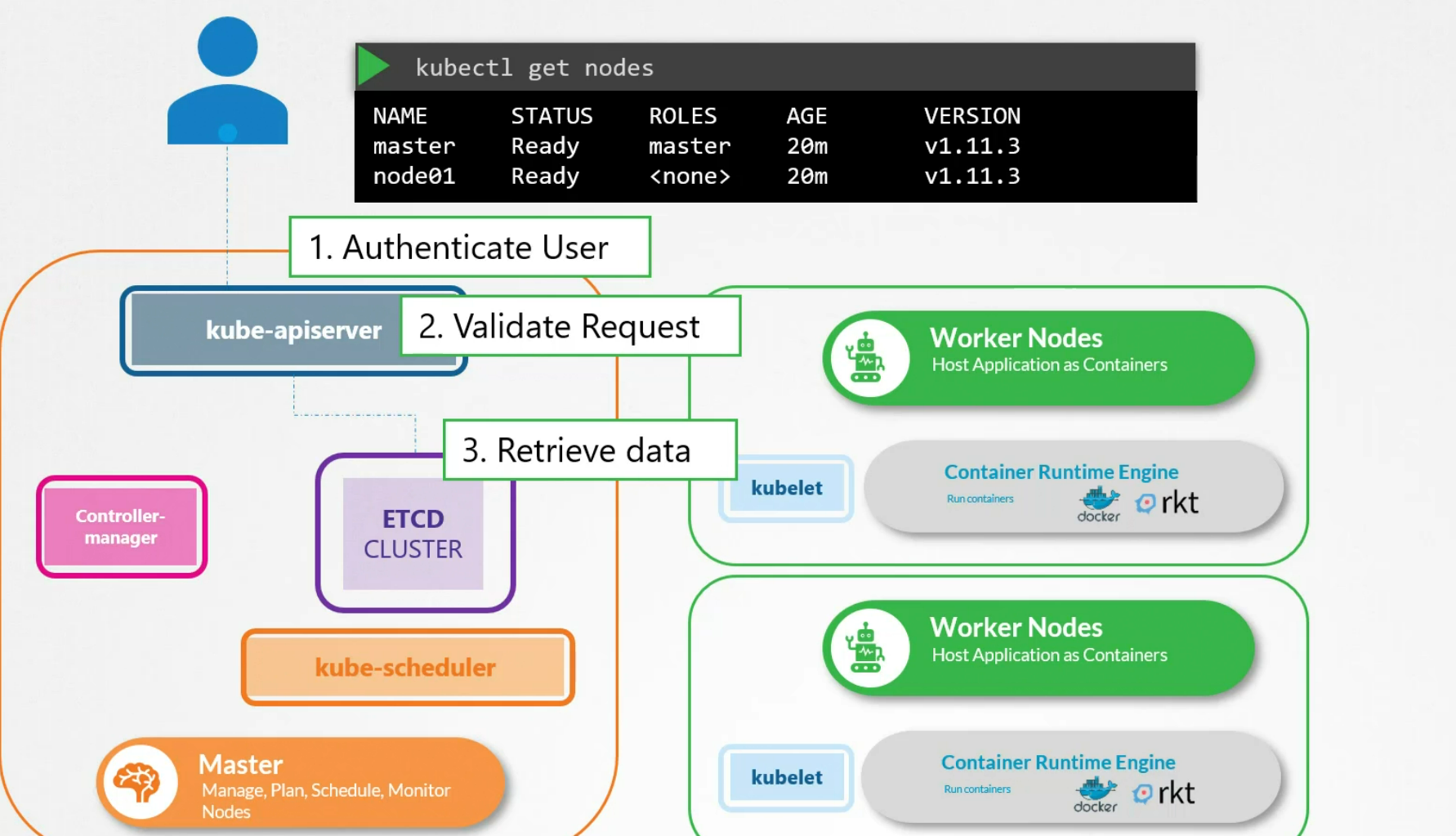
Let’s check that for creating a pod:
First it creates a pod object without assigning it to any node and keeps the keyvalue pair to etcd server
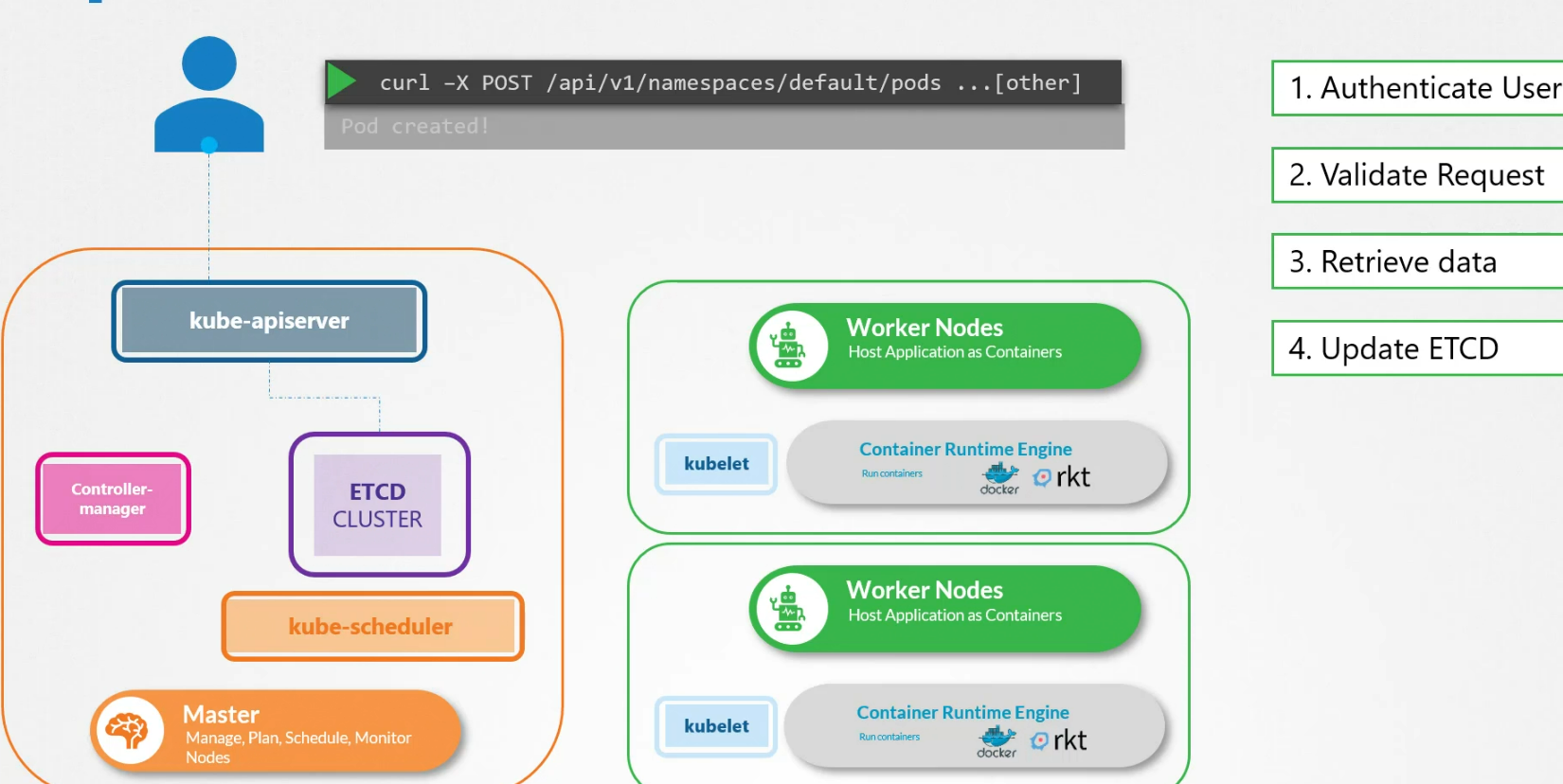
Then it updates the user that the pod is created
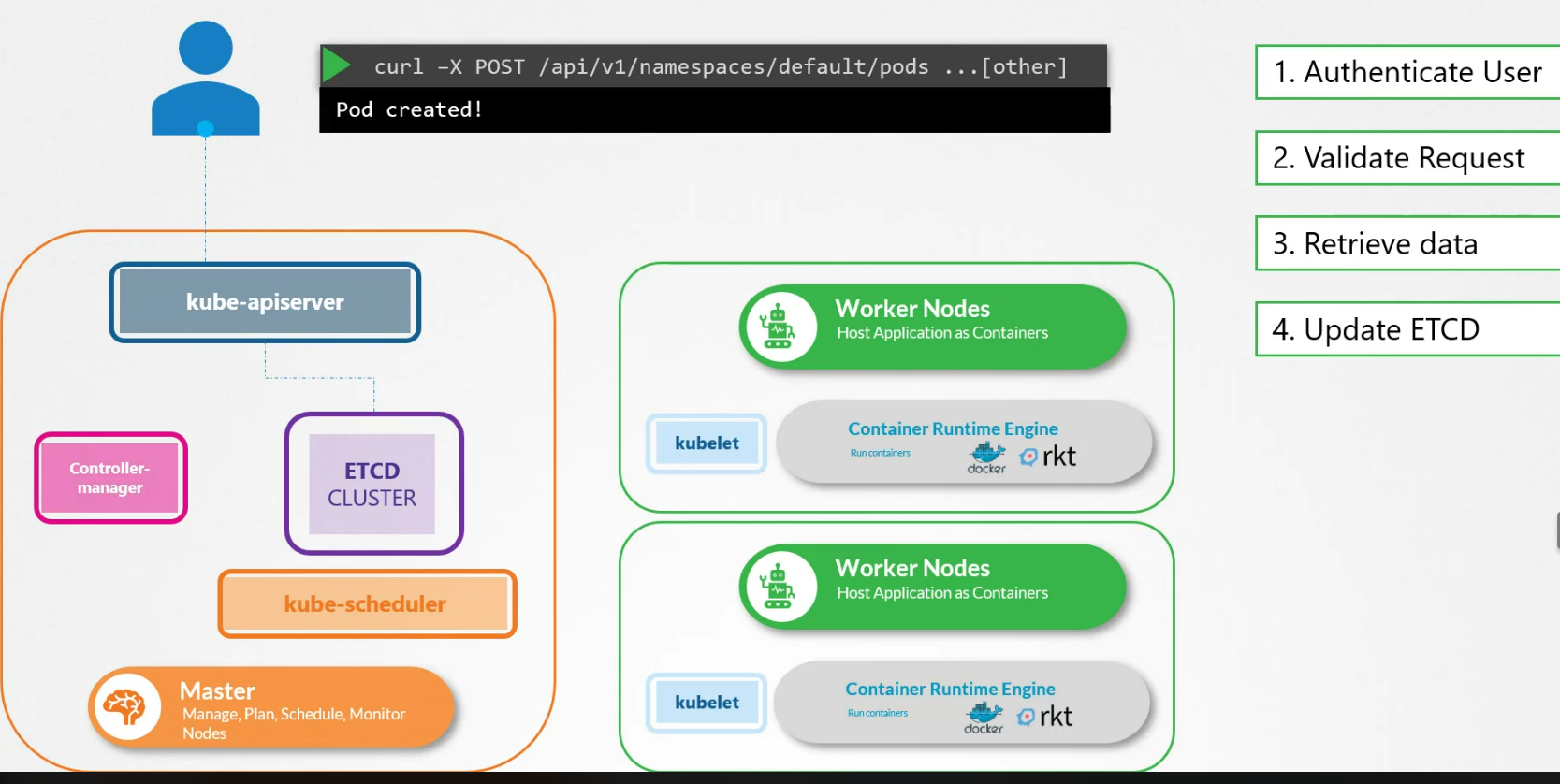
The kubescheduler then notices that there is a pod created but no node is assigned to it. It then chooses a node and let’s kubeapi server know about it. Also the kubeapi server lets the etcd cluster know about it. Then the kubeapi server reaches the desired node’s kubelet api and informs about the pod.
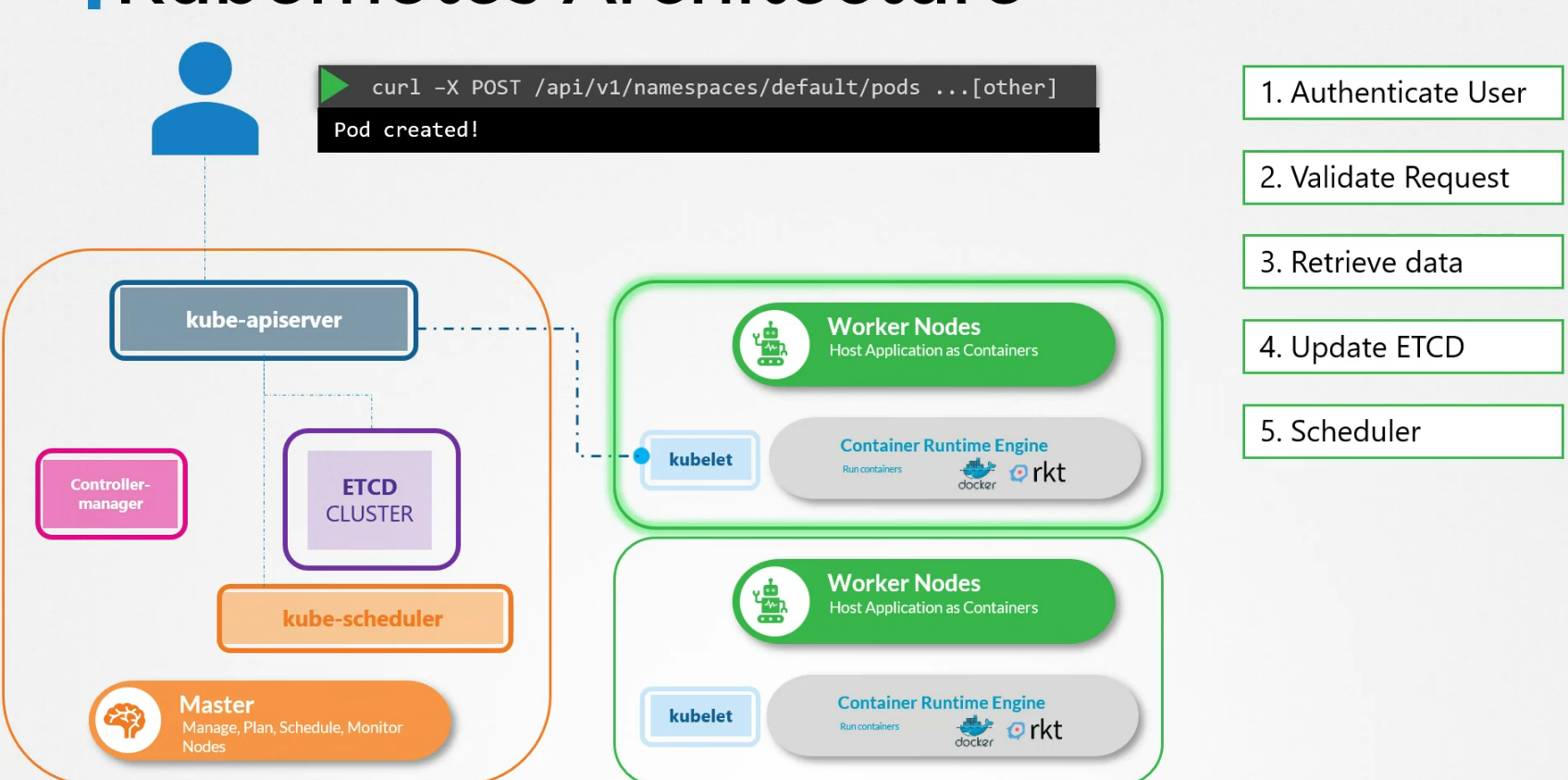
Then the kubelet adds the pod to the node and informs the kubeapi server. The kubeapi server then informs etcd cluster about it.
So, we can see kubeapi server is used everytime we do anything. How to install that? You can install it as a service
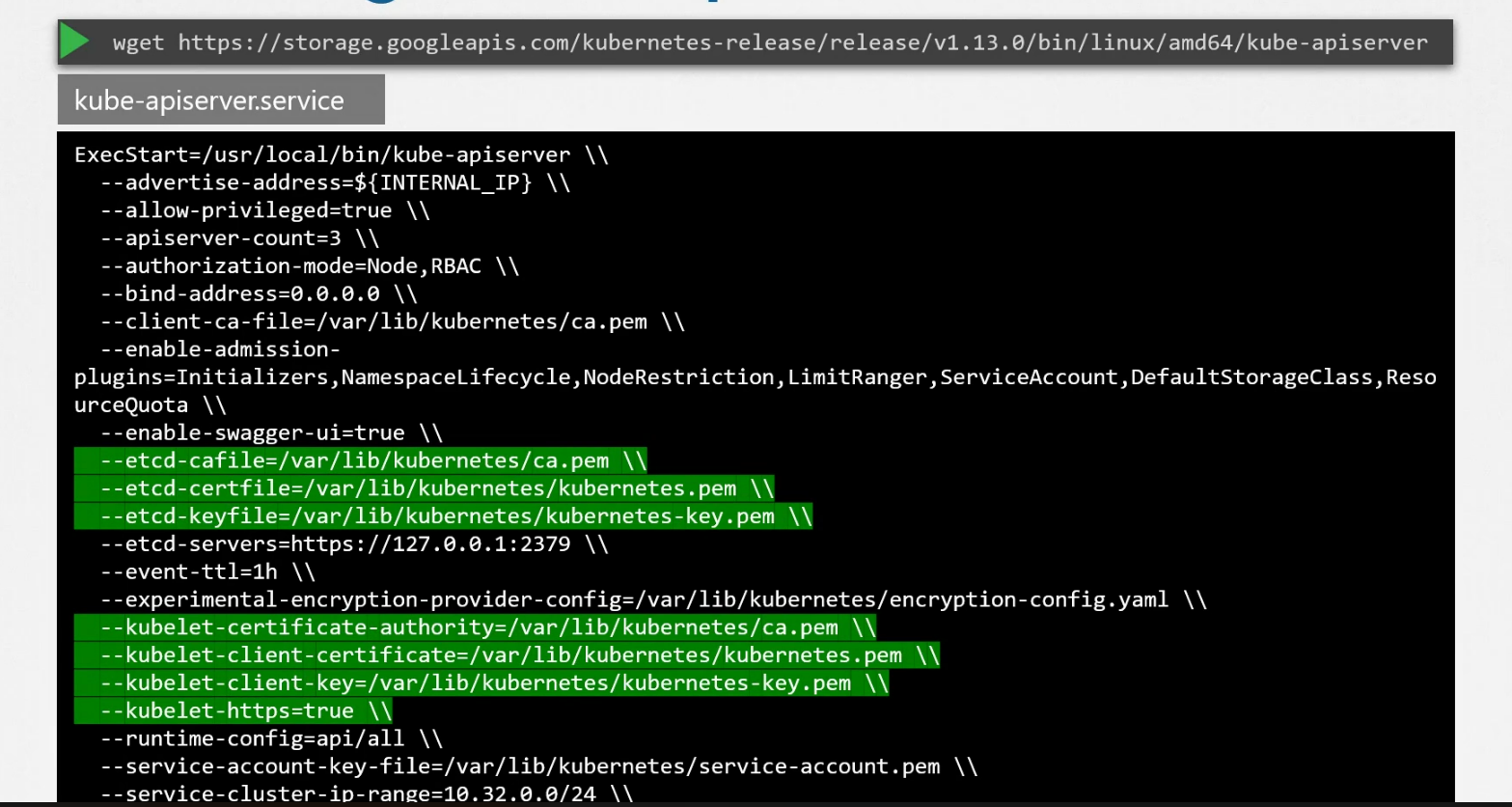
Also here you can see the location of etcd server within kubeapi.
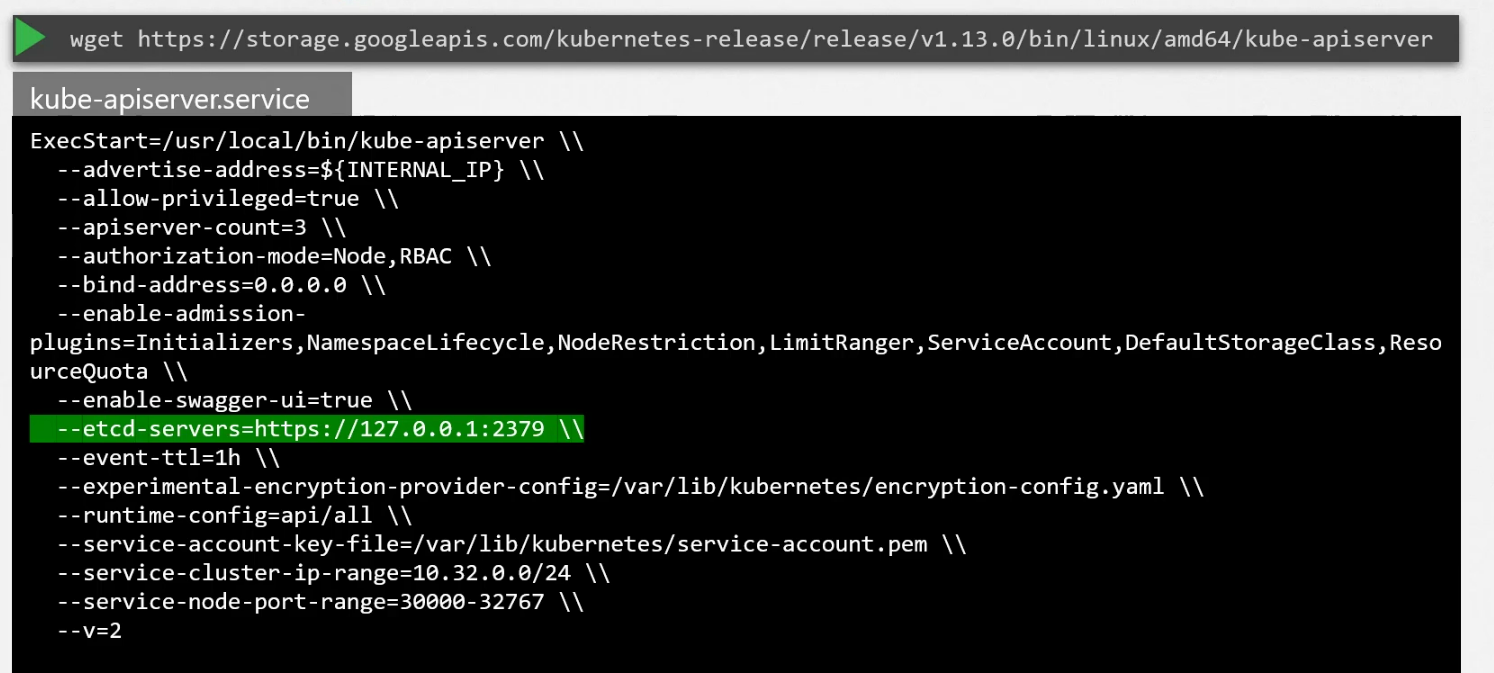
This is how kubeapi server knows about etcd server and contact it.
Controller
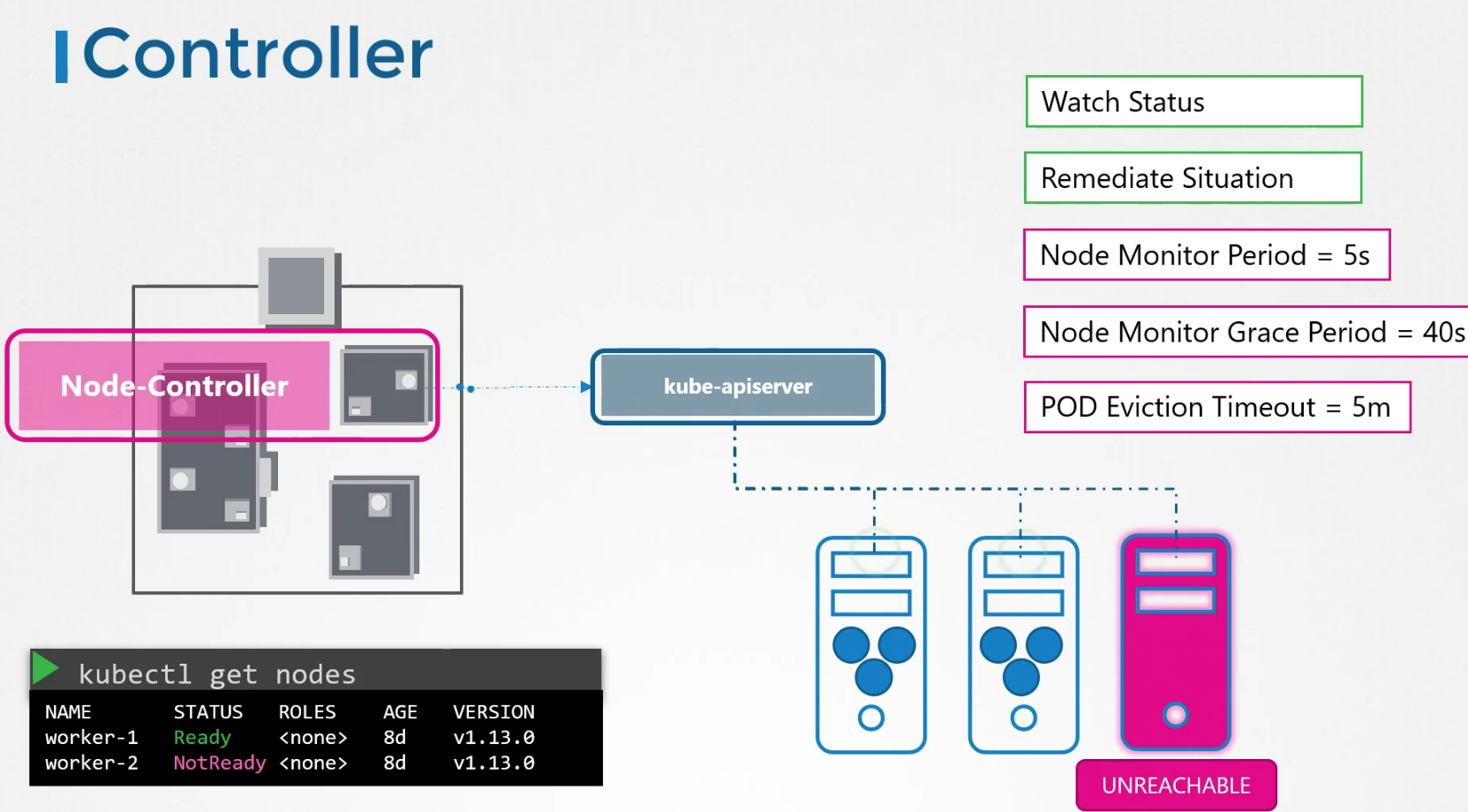
There are various controllers whose task is to monitor certain things and make sure that’s in the desired state. For example, here we can see a node controller which contacts kubeapi server to connect to a node. The node controller checks the status of the nodes every 5 seconds. If it stops receiving heartbeat from a node, it is marked as unreachable. (Note: the controller waits for 40 seconds before marking it unreachable)
Once marked as unreachable, it waits the pod to come back up within 5 minutes. It it fails, the pod is removed. Then healthier pods are created here.
Just like this one, there are lots of controllers for different services.
They are all packed in kube-controller manager

Once you install the controller manager, all the other controllers also gets installed. But how to install it?
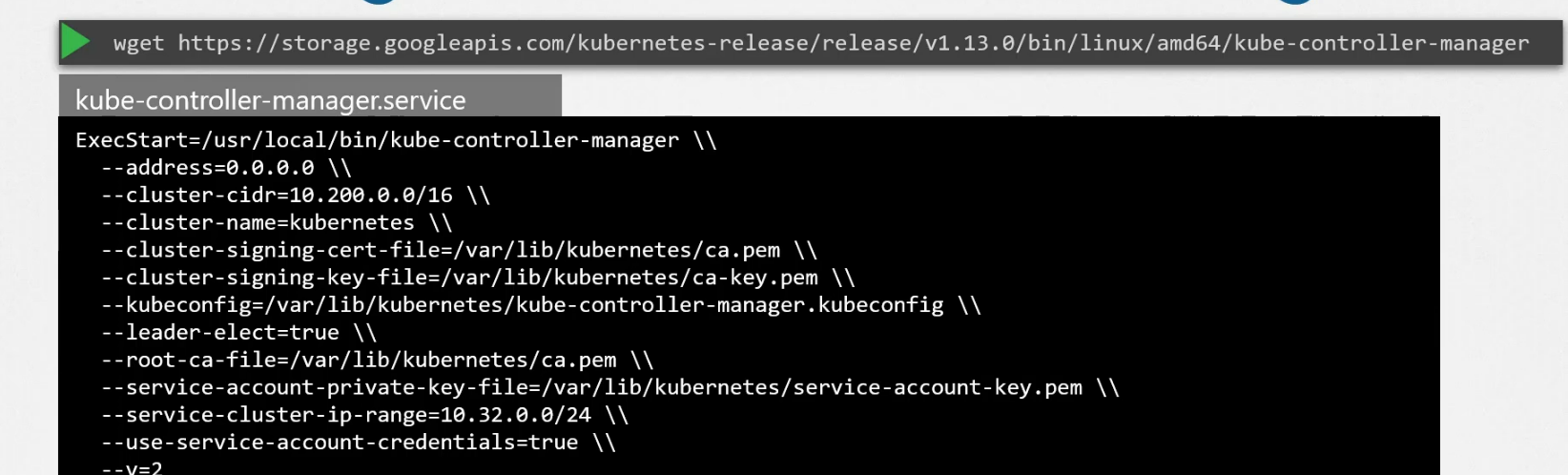
Just download it as a service.
You can also customize it and set the node-monitor period etc. Also you can set which controllers you want to use
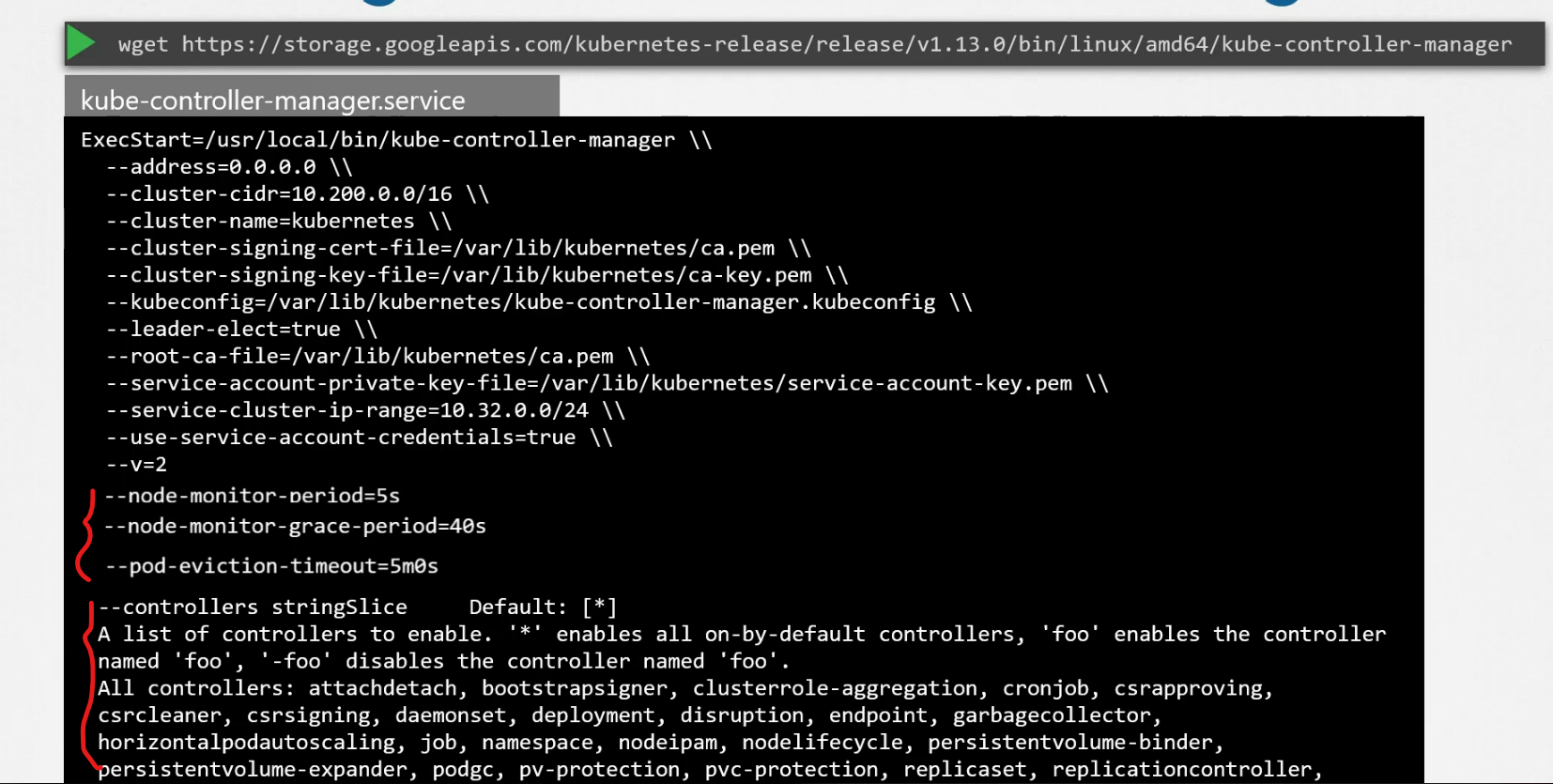
How to view the controller? You can check it as a service
but if it’s installed using kubeadm, you can check that from the yaml file
Kube-Scheduler
First of all, keep it mind that kube-scheduler decides which pod is assigned to which node but never schedule the pod in the node. It’s done by kubelet api.
How does it work? Assume that this pod needs CPU space 10 and we have 4 nodes here
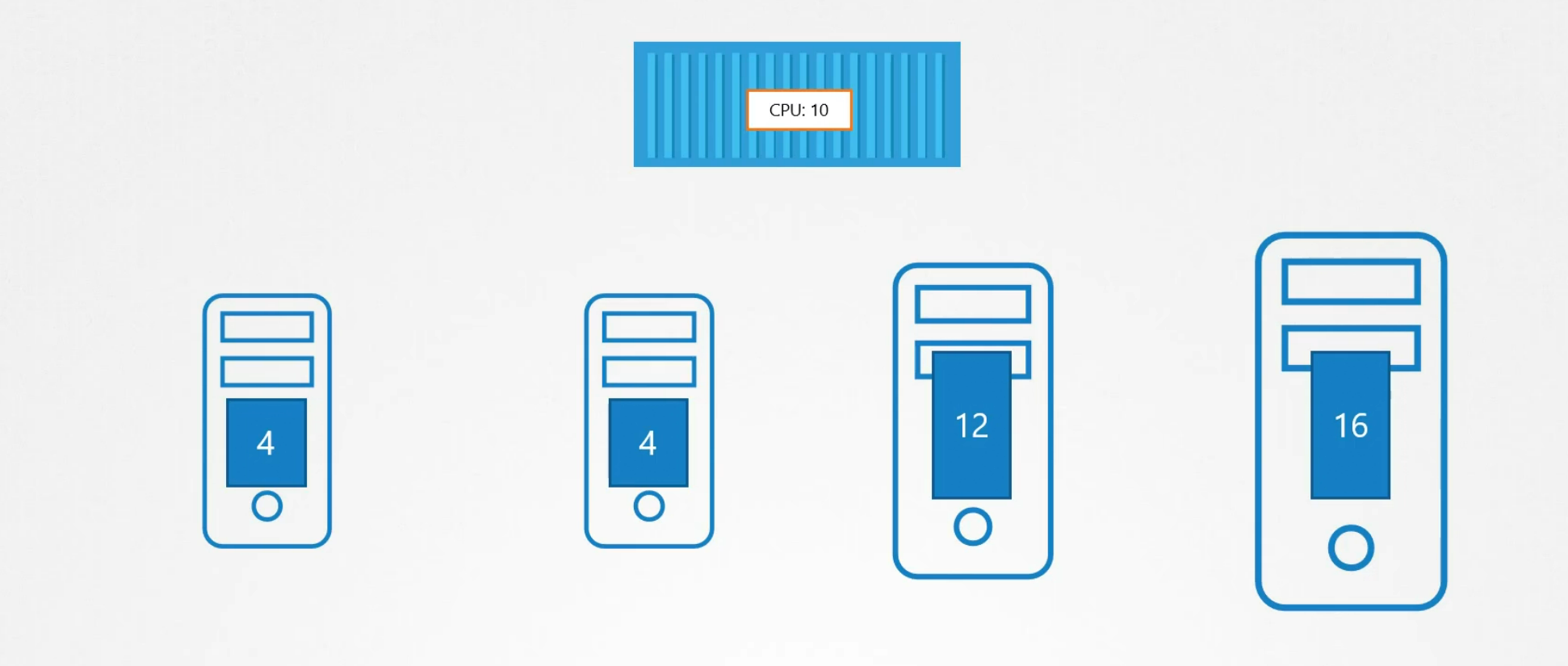
Here, the pod will surely get appointed to node which has cpu space 16, right?
How to install the kubescheduler?
Run it as a service

How to check the kube scheduler? If you use kubeadm, check it as a yaml file
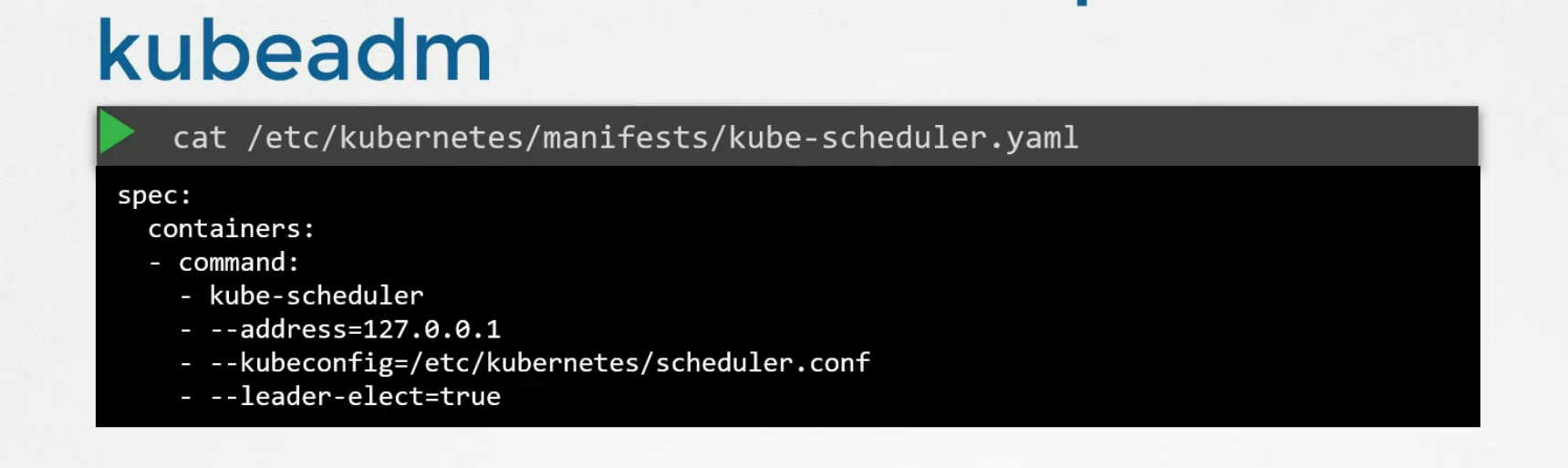
else check that as a service.
You can also check all processes related to kube-scheduler by this. Use
ps -aux | grep <your-desired-service-name>

Kubelet
Kubelet works as the captain in each node. They deal things in each node (ship here)
They inform kube-api server once anything happens
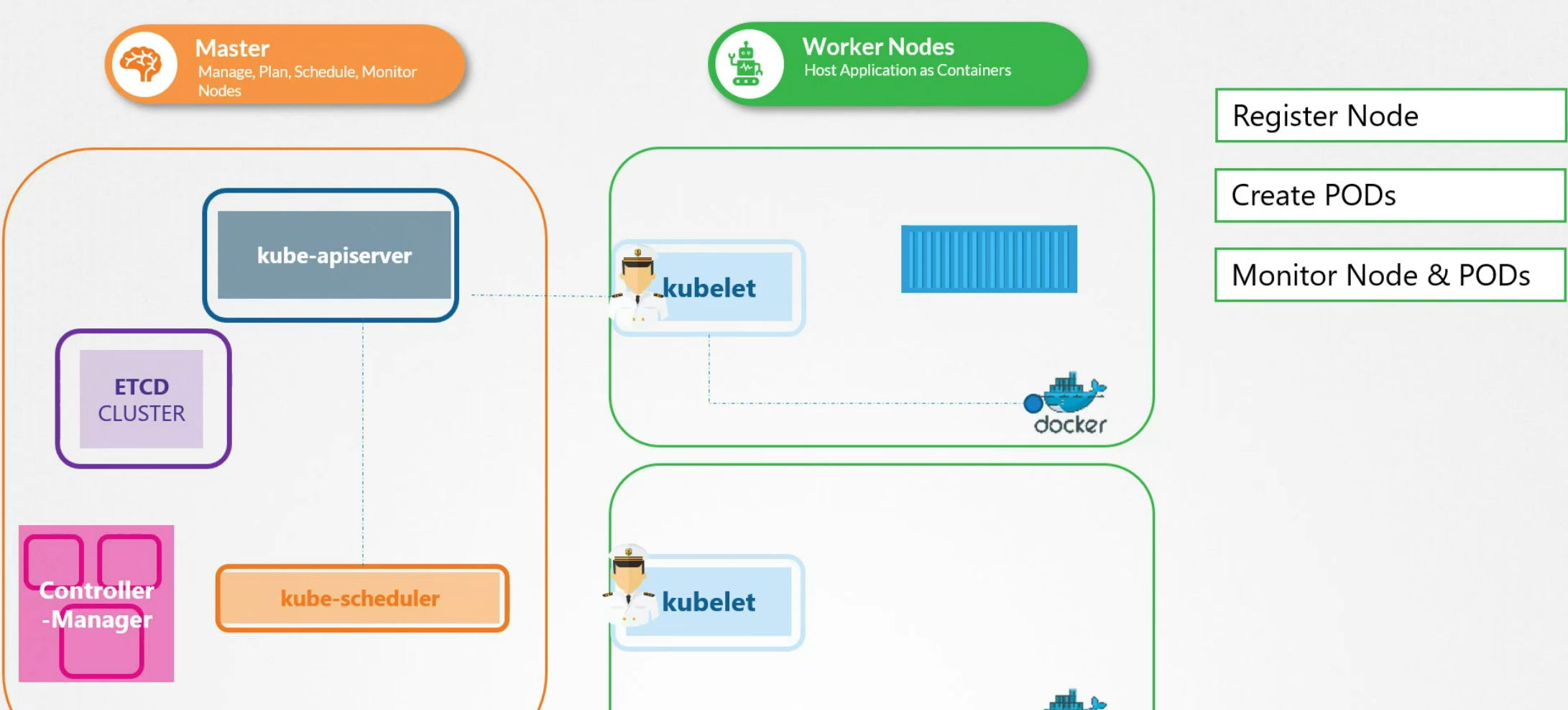
A kubelet api register a node ( a ship), once it’s told to add a pod in it’s node, it fetches the image of the pod and creates that using the container runtime (docker etc). It then monitors the pods , node and informs kube-apiserver.
How to install this? Just install it as a service
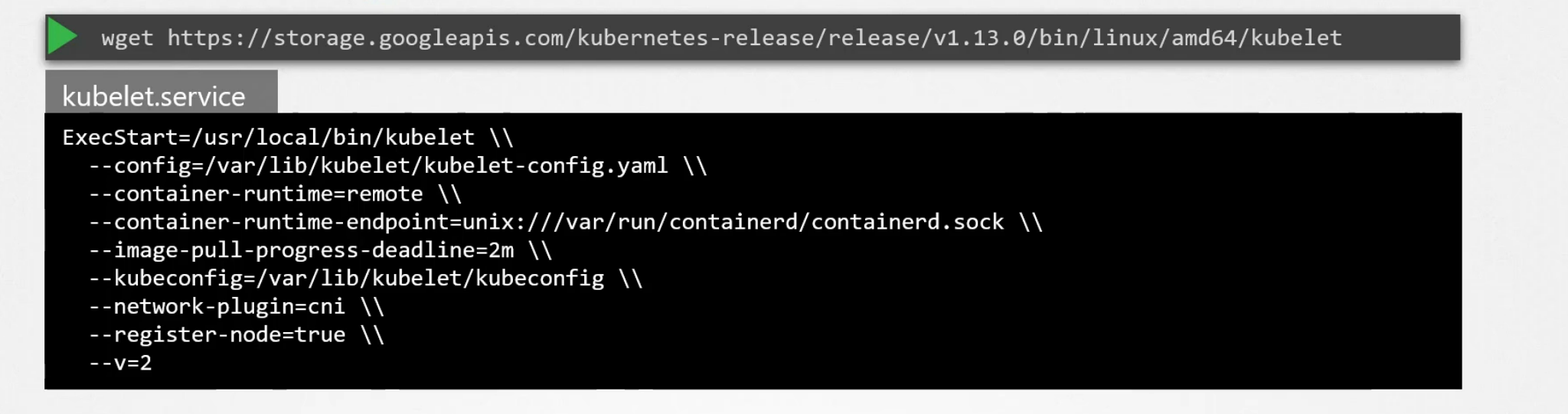
You can view the running processes related to kubelet :

Kube Proxy
Assume that we have web server (blue) and database server (green) on two pods.
They can reach each other using IP but the IP can change right?When?
Surely when pods are stopped or else.
So, make a good connection, we use service.
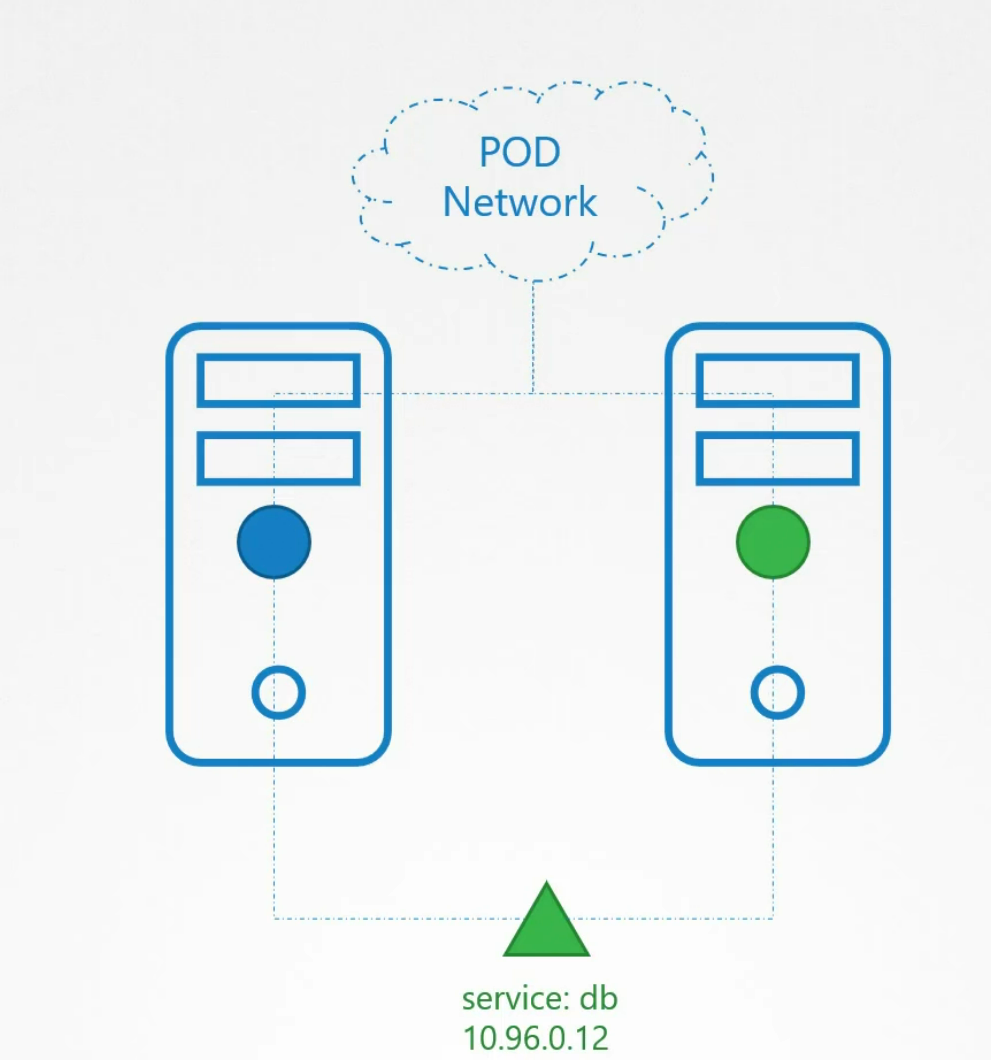
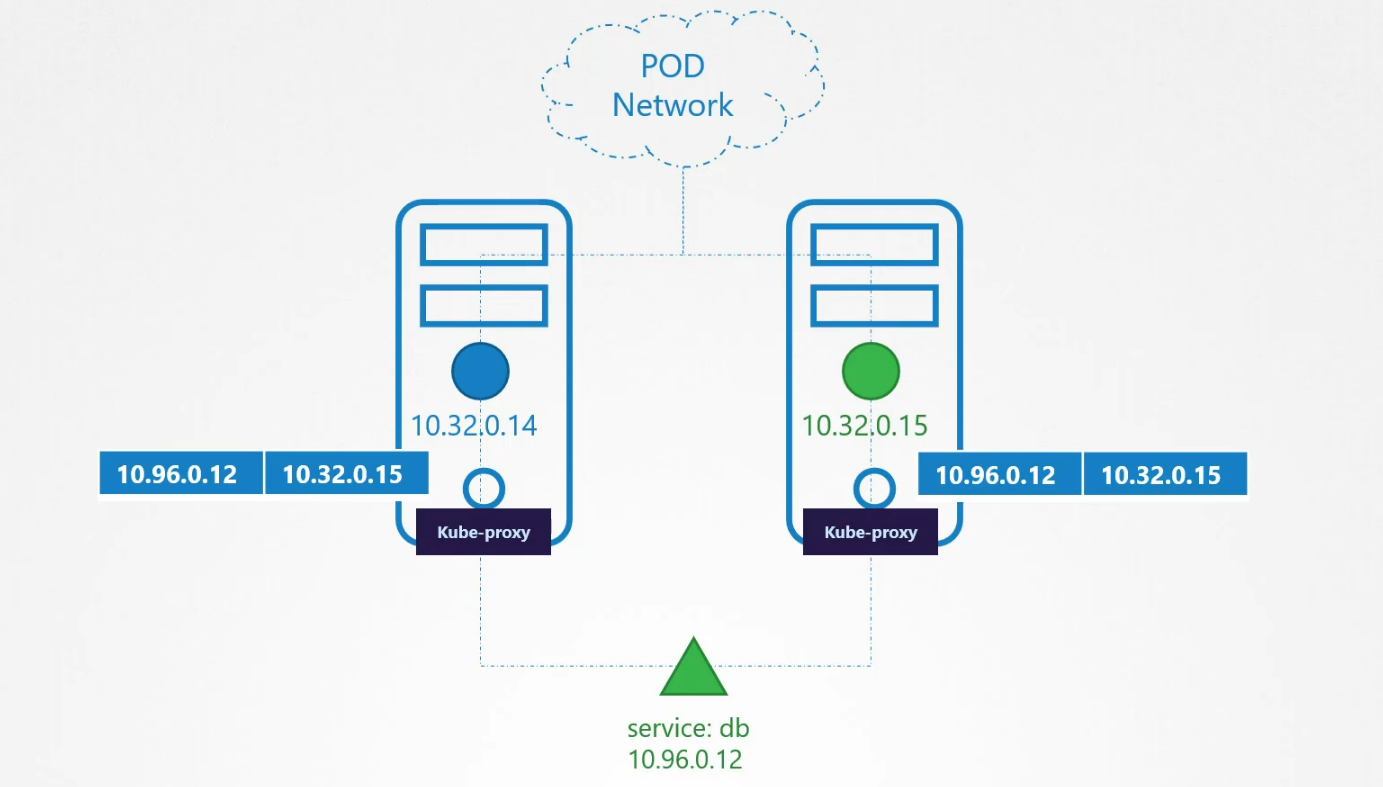
The web server can now access the database server using the IP of the service.
To make sure that the services are accessible throughout the whole cluster, kube-proxy comes up with a solution. It looks for services and once it finds them, it creates appropriate rules on each node to forward traffic to those services to the backend pods. To do that, it uses IP table.
How to install it?
You can run it as a service

Kubeadm installs it as daemonset so that it’s installed in each node in a cluster.
OS Upgrades
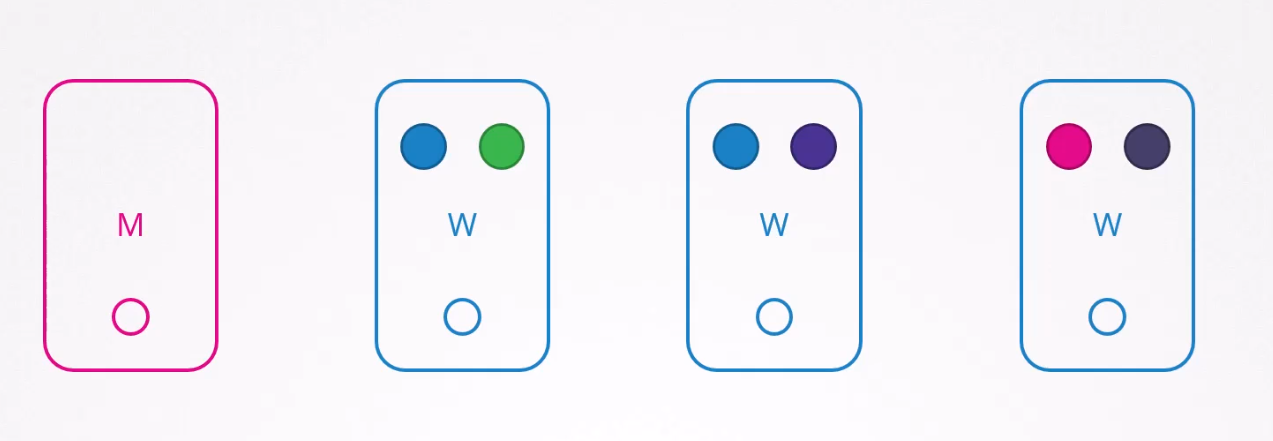
Assume we have 1 master node and 3 other nodes which has 2 pods each.
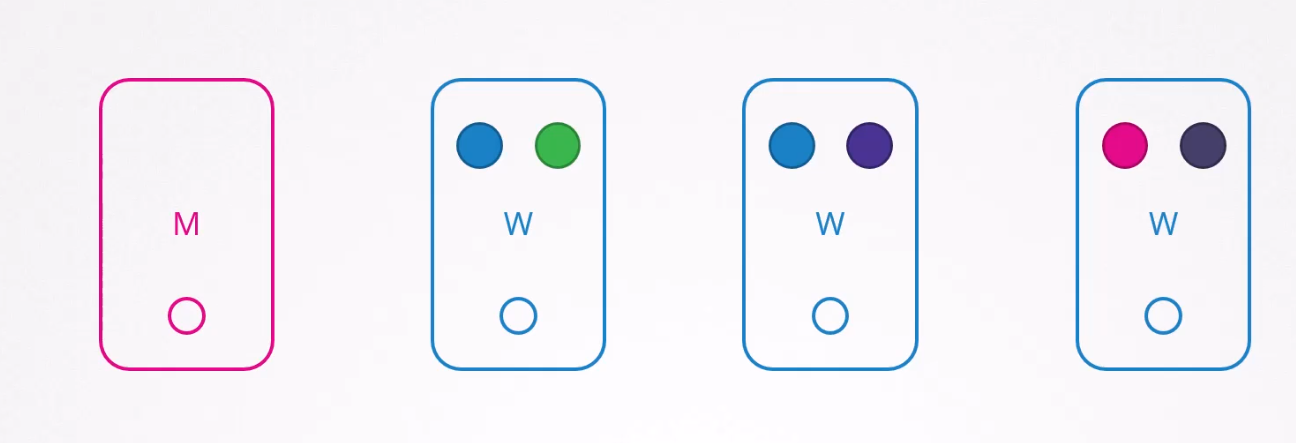
Now, assume that for updating purpose , we need to take down Node-1 (leftmost second one)
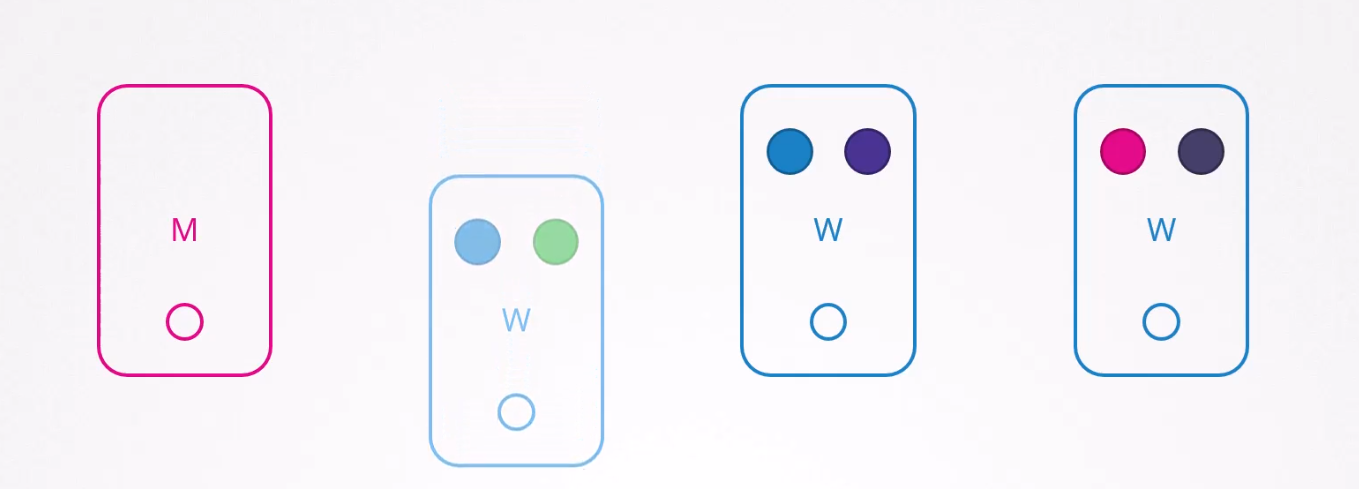
Notice that, this node (node 1) had a blue pod and a green pod. Services dependent on the blue pod will be safe as node2 also has a copy of blue pod.
But what about green pod? You guessed it right. The services associated with green pod will be gone!!
Now, if the node is available in less than 5 minutes, the pods come back as well. What happens to a node if that’s terminated for more than 5 minutes? Then the pods are terminated from the node.
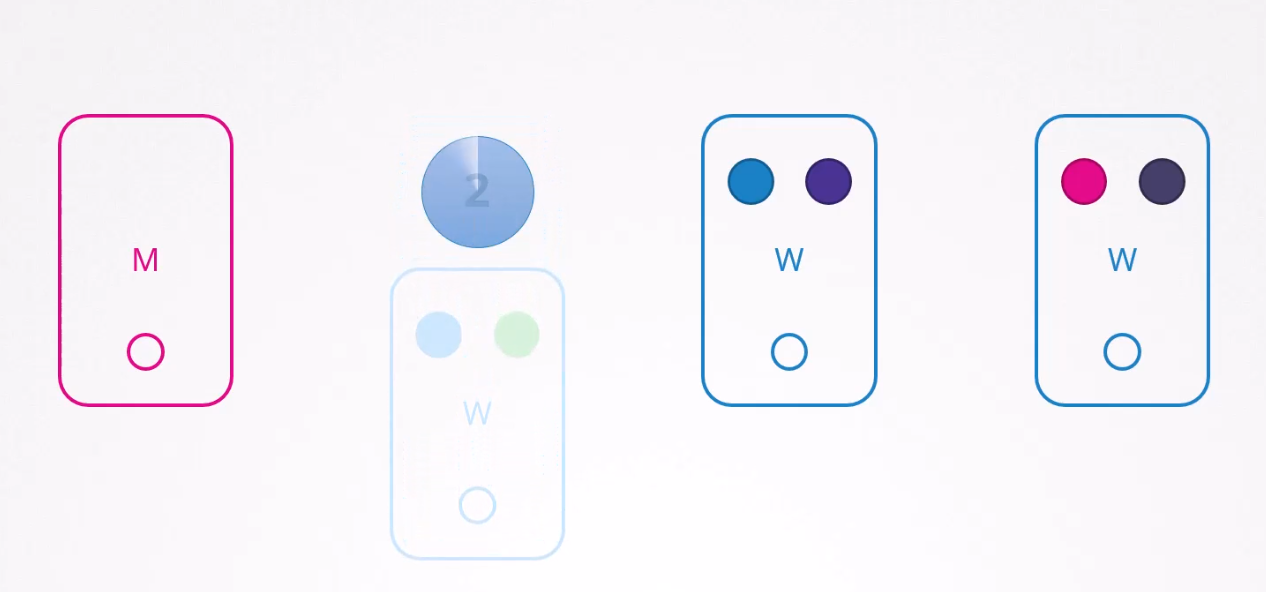
Now, assuming the node-1 is gone! And blue pod was part of a replicaset and green was not, what will happen?
The blue pod will be created as it’s part of a replicaset but node-1 is gone!
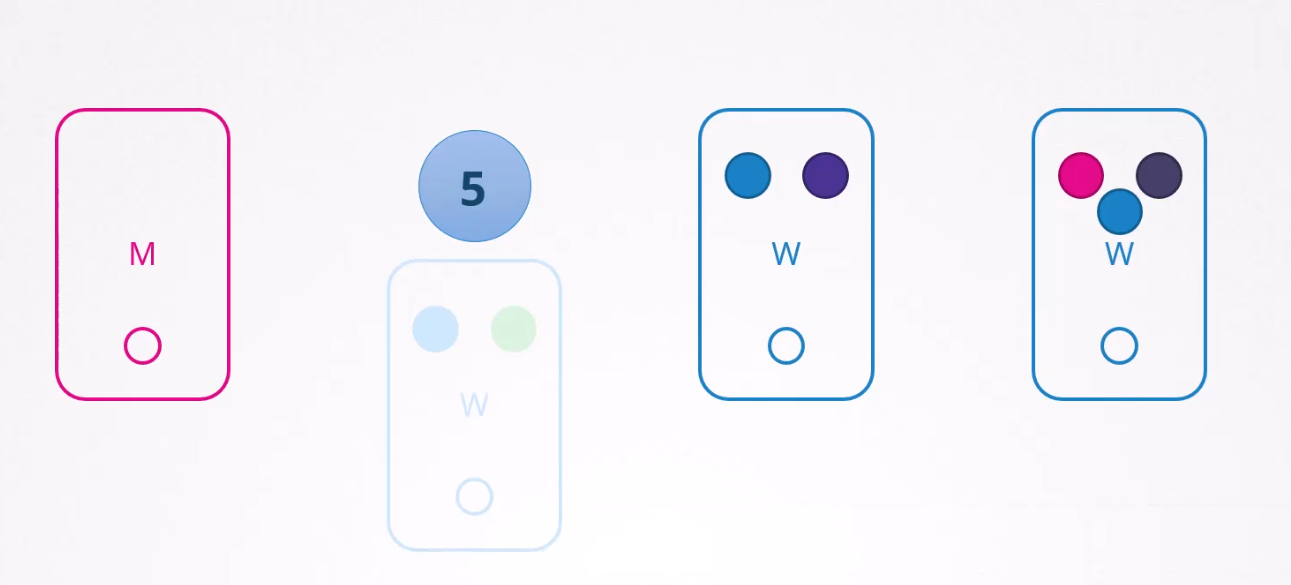
Assuming the node-1 comes back online after all of these processes, what will happen?
The node will have no pods at all.
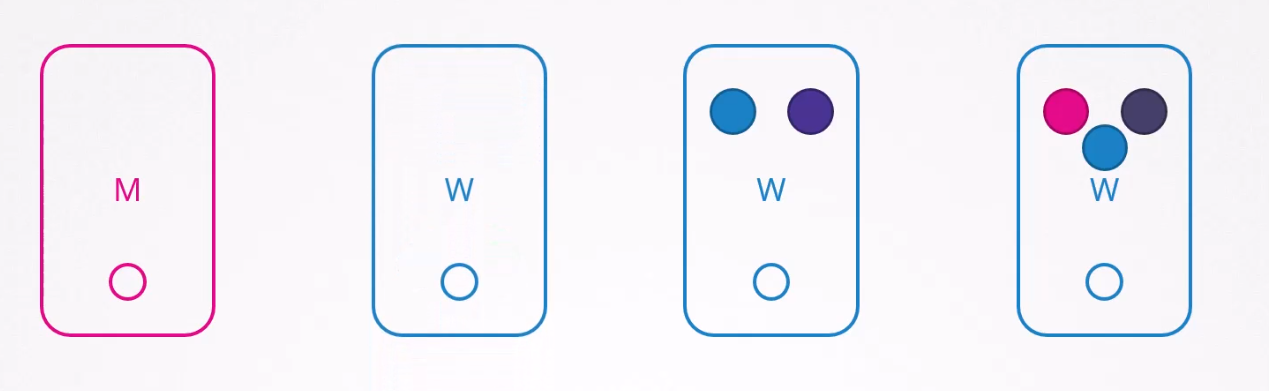
So, this is the scenario when we terminate a node and it’s gone for more than 5 minutes. Pod who are not part of the replicaset (green pod) is gone whereas pods who were part of the node (node-1) and was part of a replicaset is created on a different node.
Then, the node (node-1) gets created again but won’t have any pods in it.
So, as a maintainer, keep these in mind:
1) If a node is going to be active within 5 minutes of termination.
2) If the pods within the node is part of replicaset etc.
So, how to handle these situations?
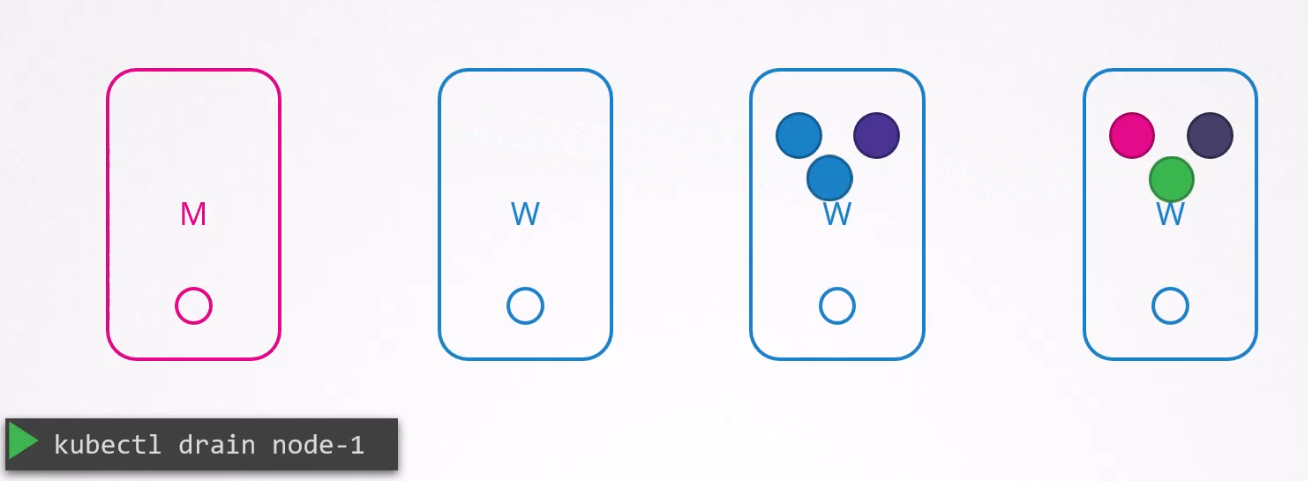
If we need to terminate the node-1, we can drain the pods within the pod. In this way, the pods (green and blue pod)
will be deleted from here and get created on other existing nodes.
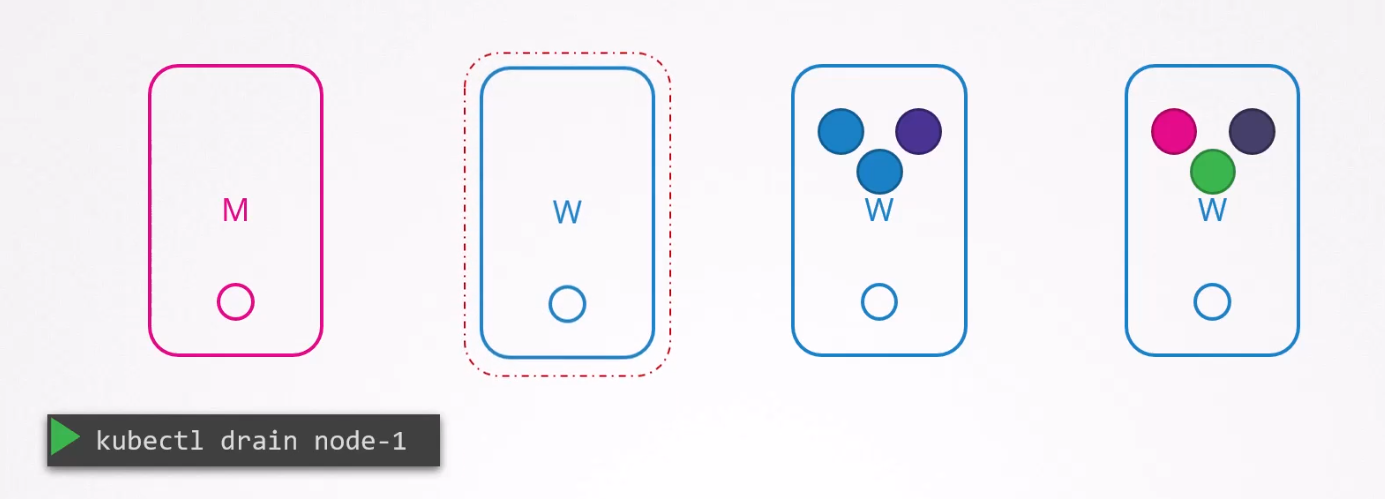
Now we can reboot the node-1 and do all other maintainance works as the pods are safe. Once the node-1 is back online, it remains unscheduled.
We have to uncordon node-1 to add any pods to it.
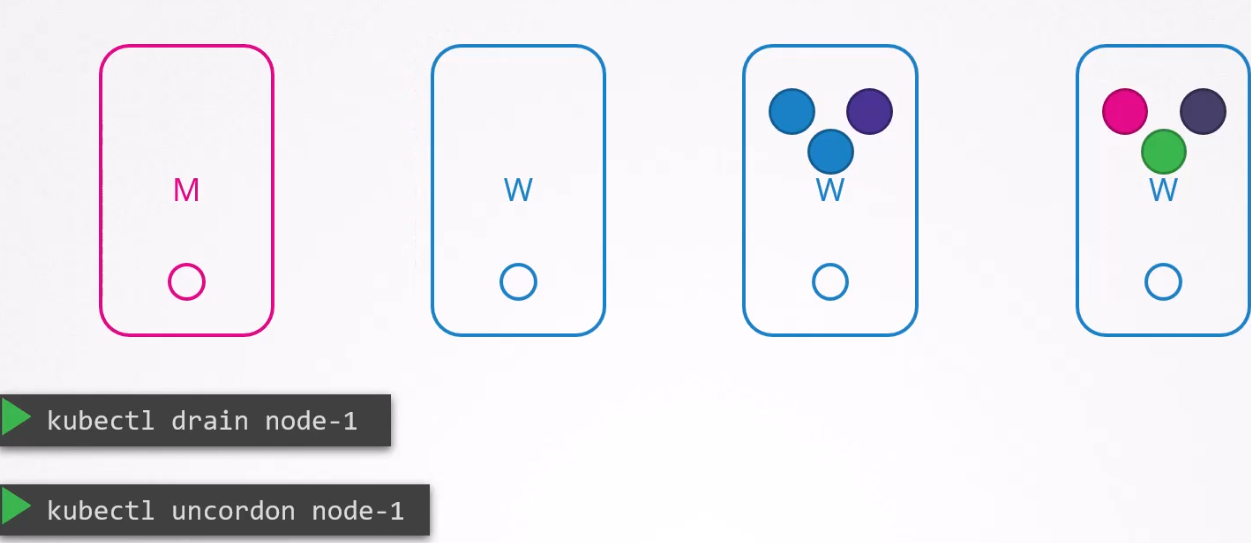
Also, there is another thing called cordon which can make a node unschedulable.
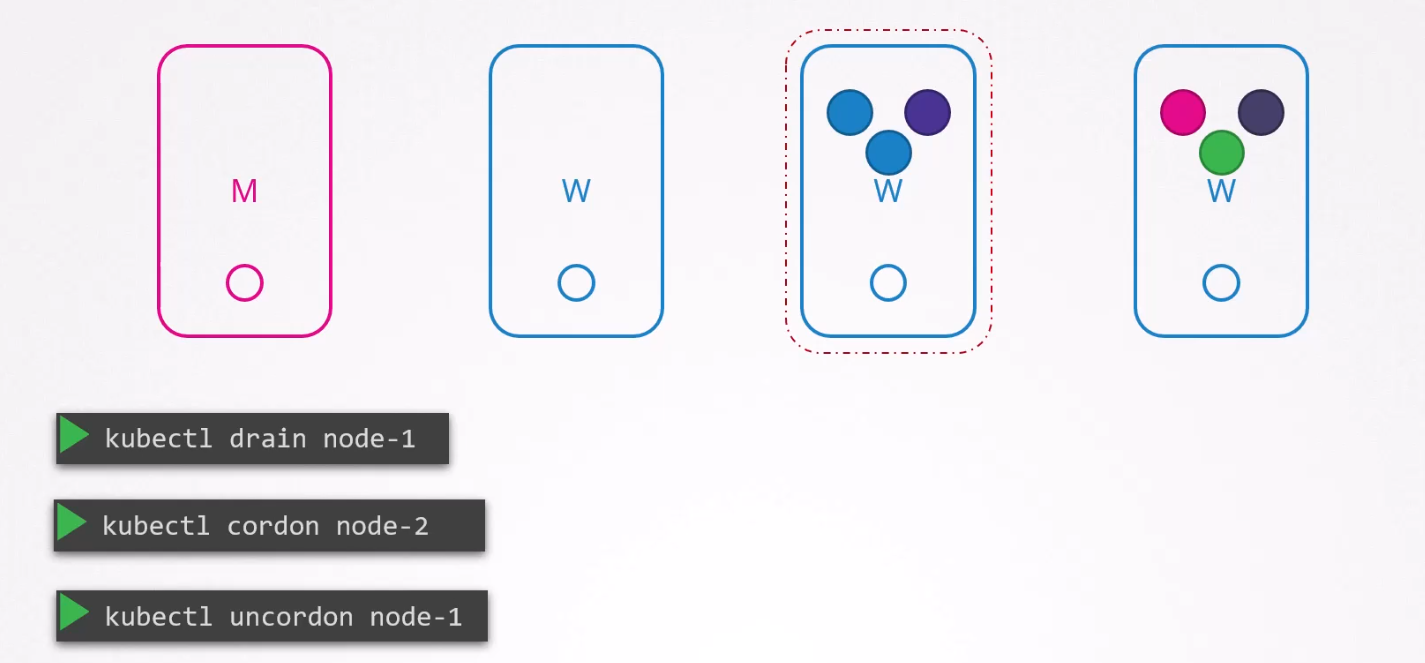
Here, node-2 has been unscheduled.
Hand-on:
Assume that we have a deployment kept on a node (controlplace) within the default namespace.
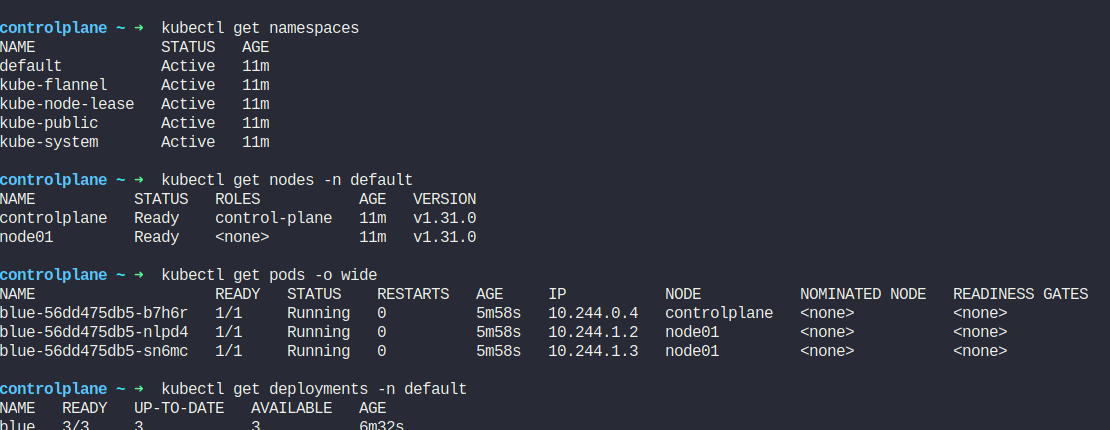
Here, pods are hosted on node01 and controlplane within default namespace

Our task now is to take node01 out for maintenance.
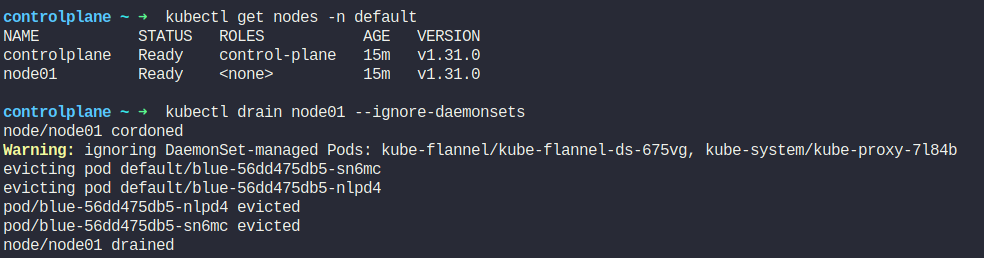
You can see that that node01 is drained and scheduling is disabled.

Remember 2 of our pods were on node01. Now what? As the node01 is drained, what happened with them? Let’s see.

You can see that the pods are now part of controlplane node. As these nodes were part of a deployment/replicaset (blue), the pods have been scheduled to other nodes.
Now, assume that the node01’s maintenance is done. Let’s make it schedulable again.

Now, we can see the node (node01) available.

Now, assume that node01 has a new pod (hr-app) and it’s not part of any deployment/replicaset.
Now, if we need to maintain the node01, lets drain the node01

We try to drain the node01 but it fails because the pod (hr-app) is not part of any deployment/replicaset.
To solve this issue, we can make the hr-app as part of the deployment.

Now, if we want to make make hr-app unschedulable, we can cordon the node

Kubernetes Releases
A version of kubernetes might look like this.

Here MINOR releases are out in every few months whereas PATCHes are out very often.
Other than that, there can be alpha and beta releases where alpha releases might have bugs and beta releases is fully tested and finally merges to main branch

Here you can see the releases
If you download the kubernetes.tar.gz and extract , you will see kube-apiserver, controller-manager, kube-scheduler, kubelet, kube-proxy, kubectl etc have the same version number although ETCD cluster and co
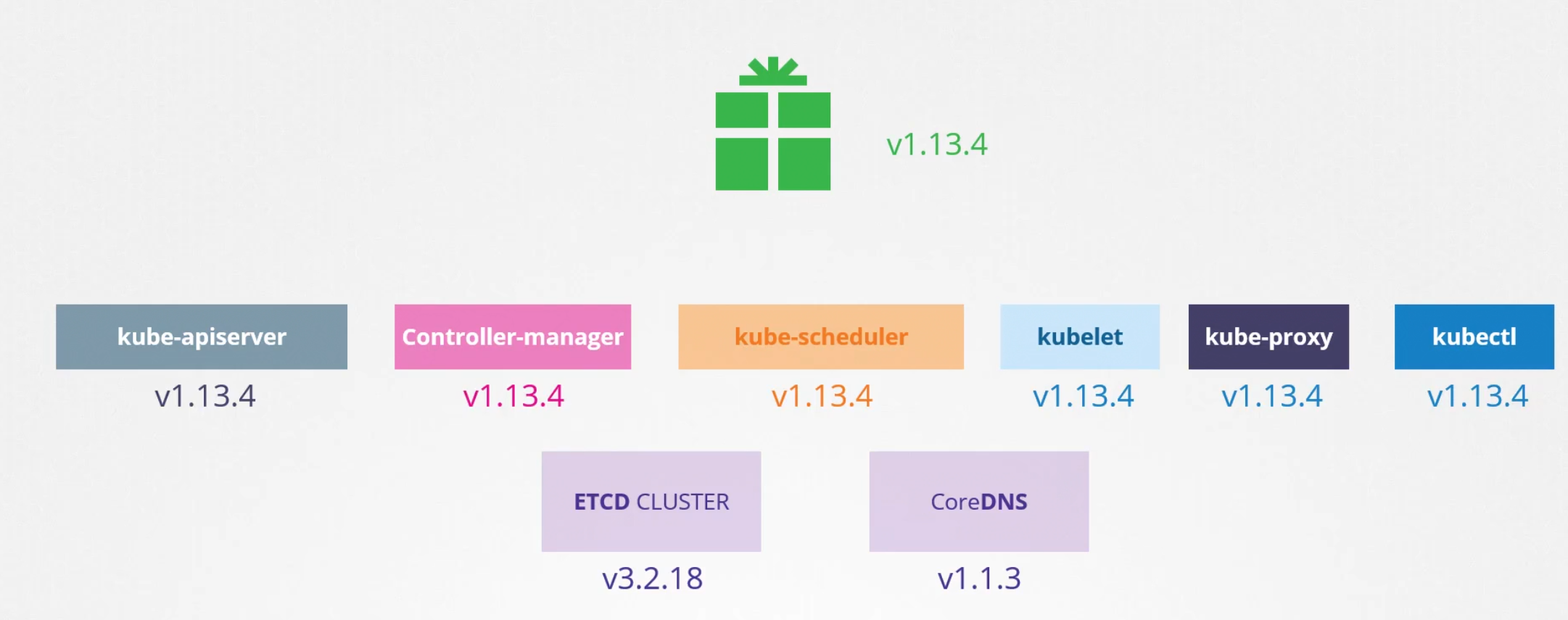
As the versions may be different, what’s the rule for it?
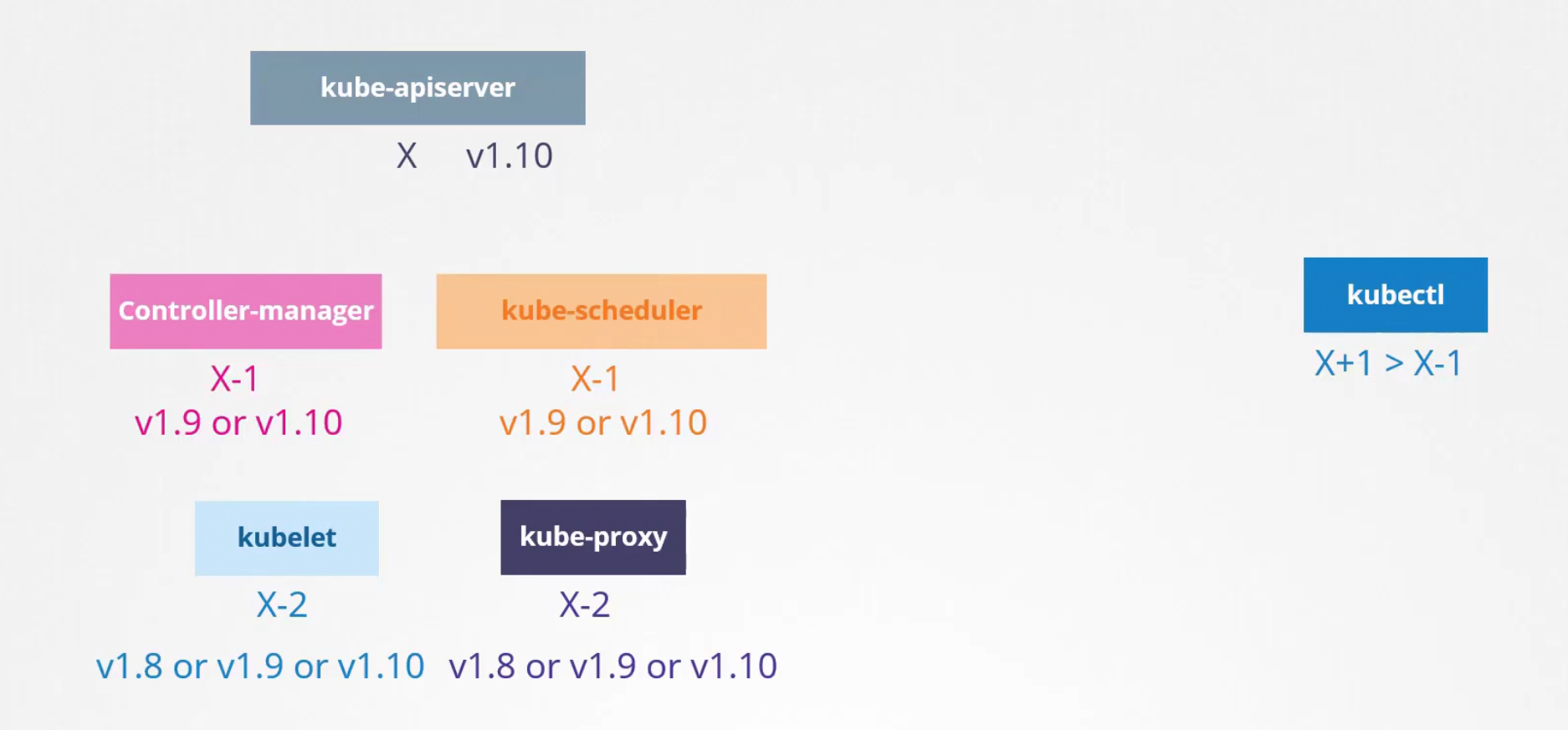
assuming kube-apiserver's version is X, controller manager and kube-scheduler can have X-1 versions but not less than that. kubelet and kube-proxy can be X-2 versions but not less than that.
But that’s different for kubectl. It can have X+1 or event X-1 versions.
Now, let’s see how it works! Assuming kubernetes launched v1.13 . Kubernetes supports 3 versions including the current one. So, v1.13,v1.12,v1.11 will get support but v1.10 will have no support.
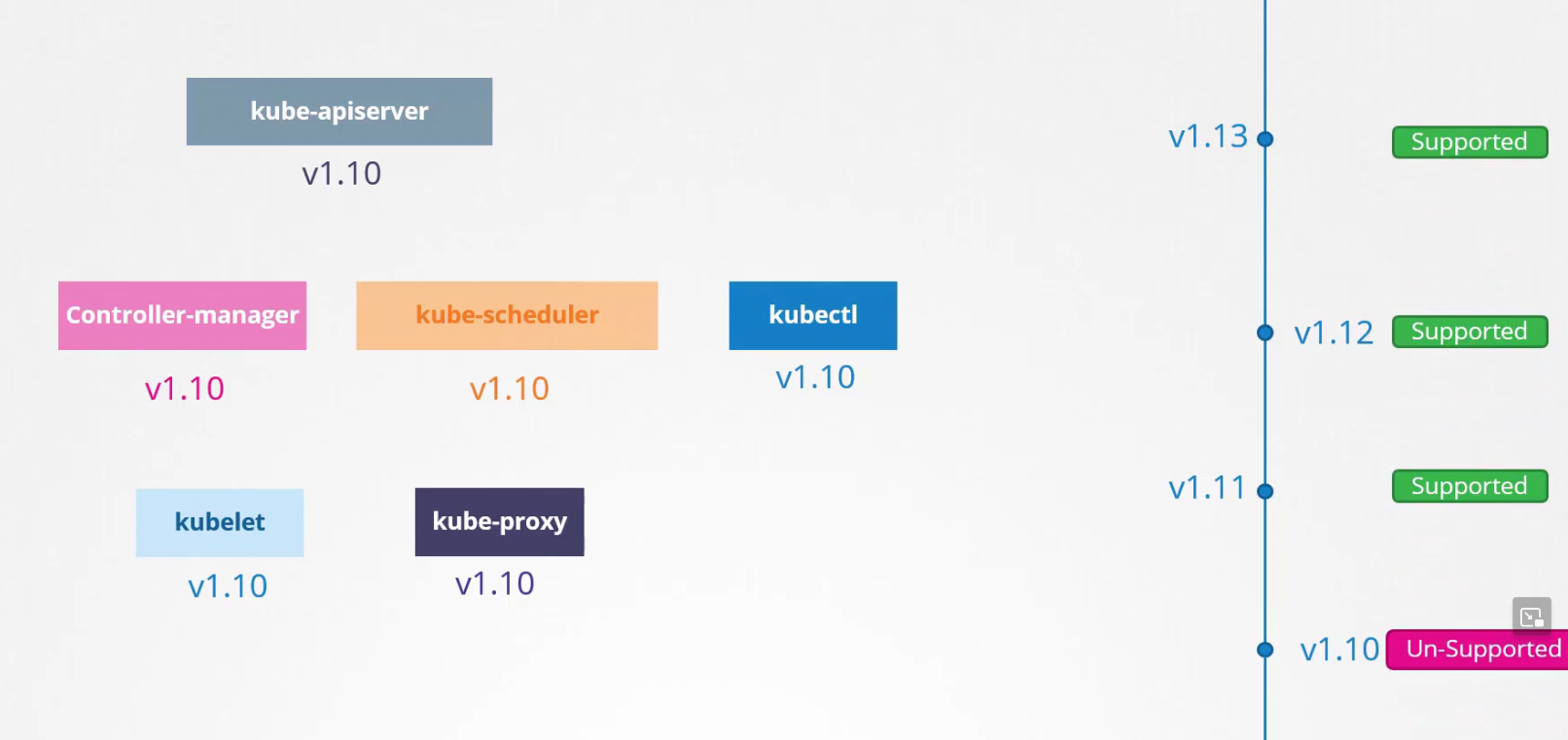
Now, you see our kube-apiserver and others are on version v1.10 which is not support. So, we need to update to the current version.
How to do that? Directly update from v1.10 to v1.13? Nope. Try one version update at a time.
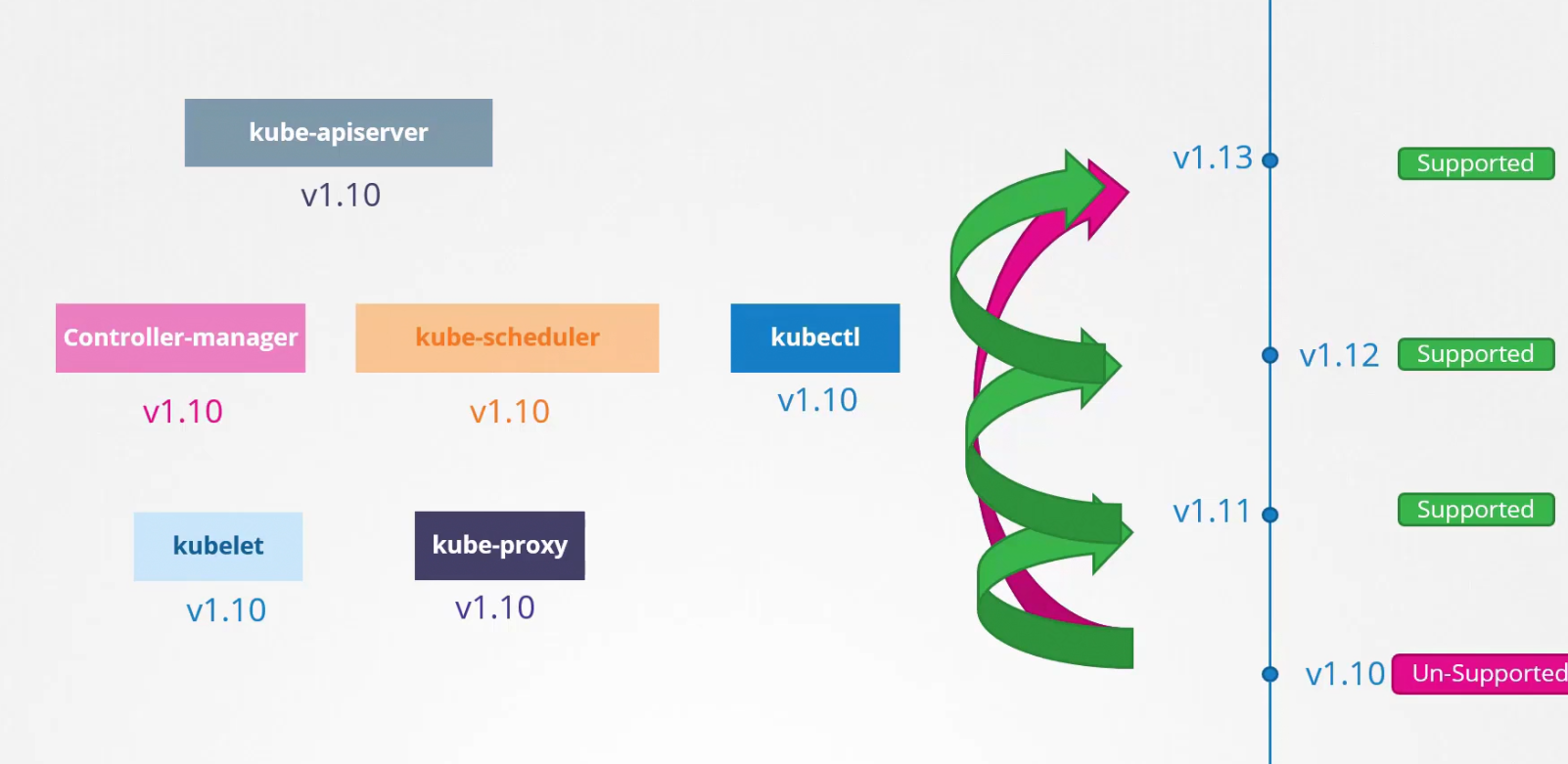
But how to update?
If you are using third party to manage cluster, it’s just a few clicks. If you use kubeadm, there is also commands. But if you use otherwise ways, you have to manually upgrade each one.
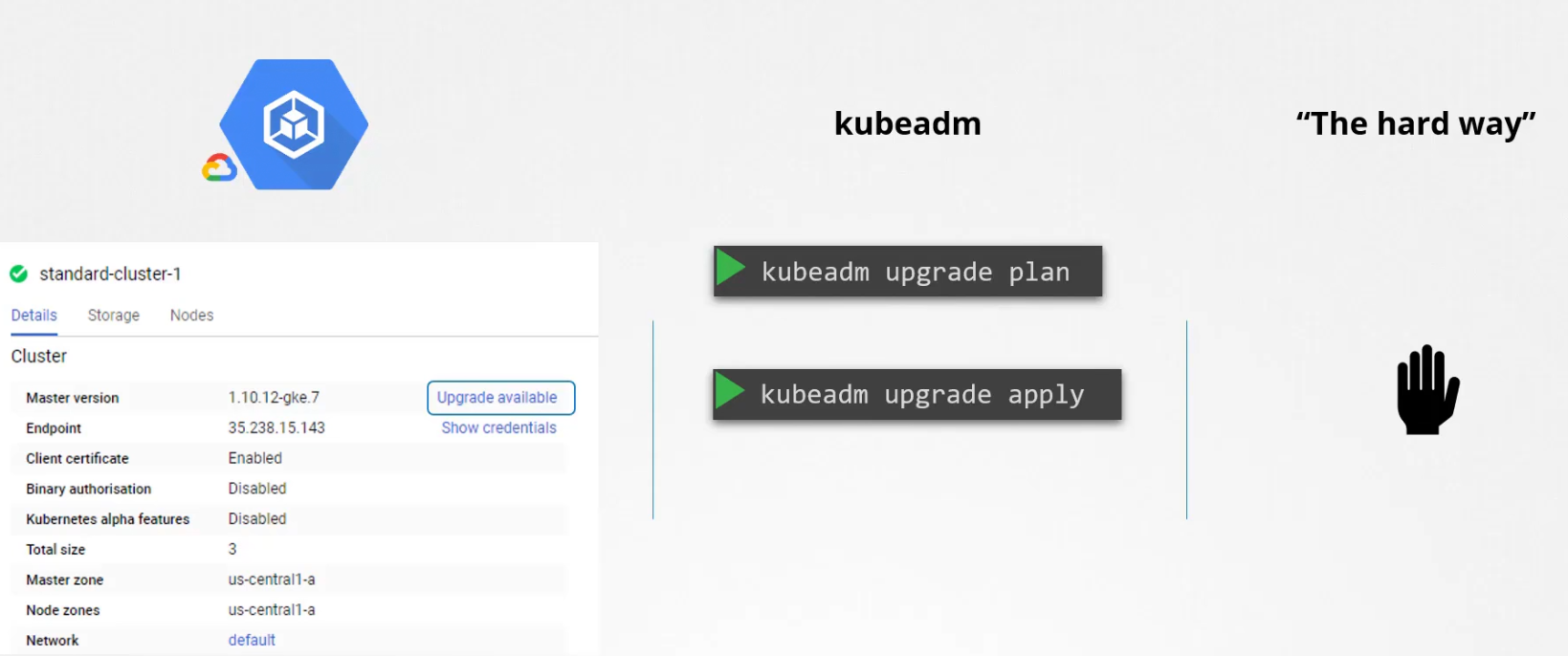
Let’s understand how can we do that using kubeadm:
Assuming master node and working node are in v1.10 which is unsupported now.
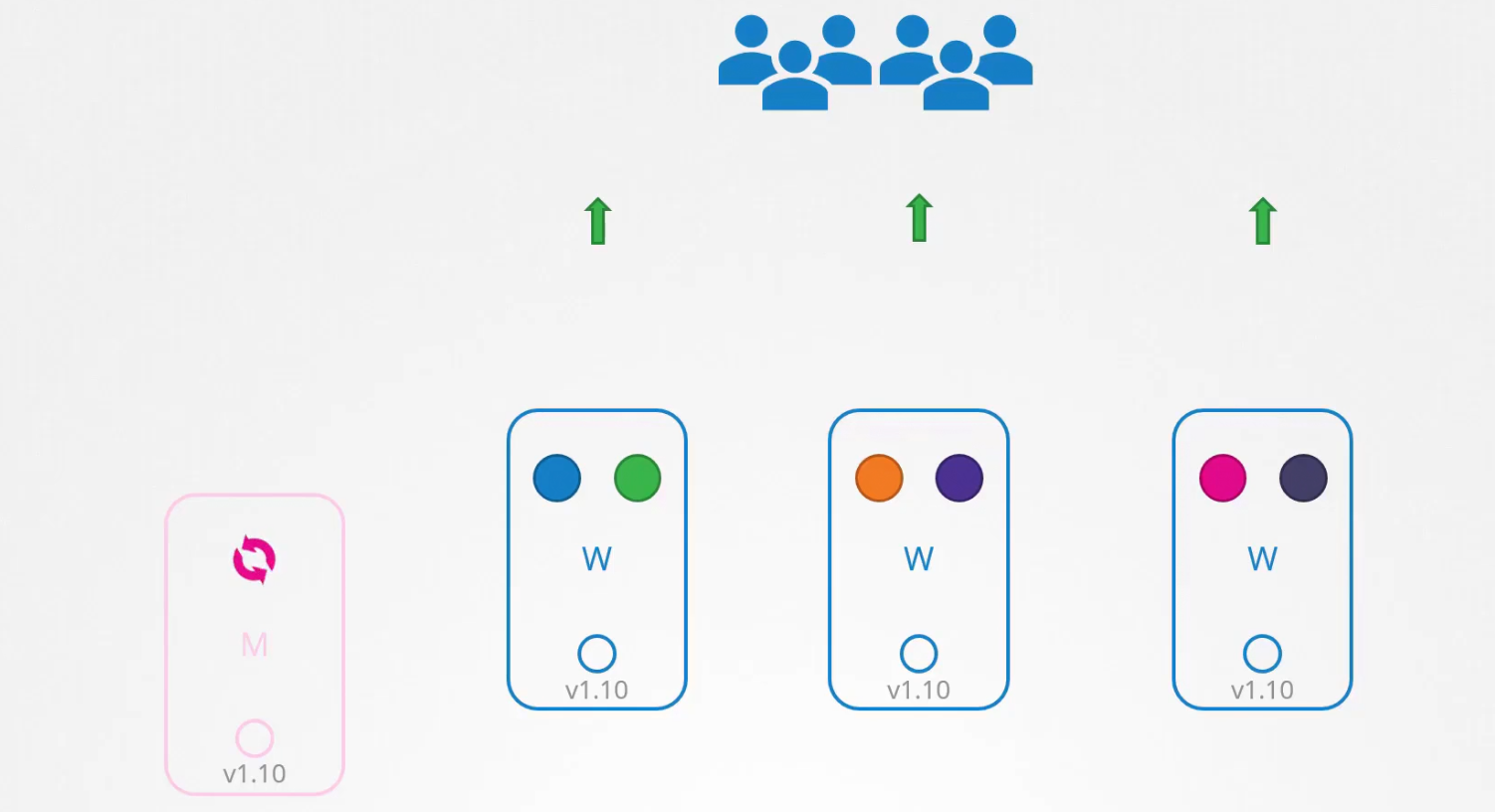
So, we can take down the master node and update it. The working node will be there and users can check them.
As soon as it’s updated, let’s update worker nodes
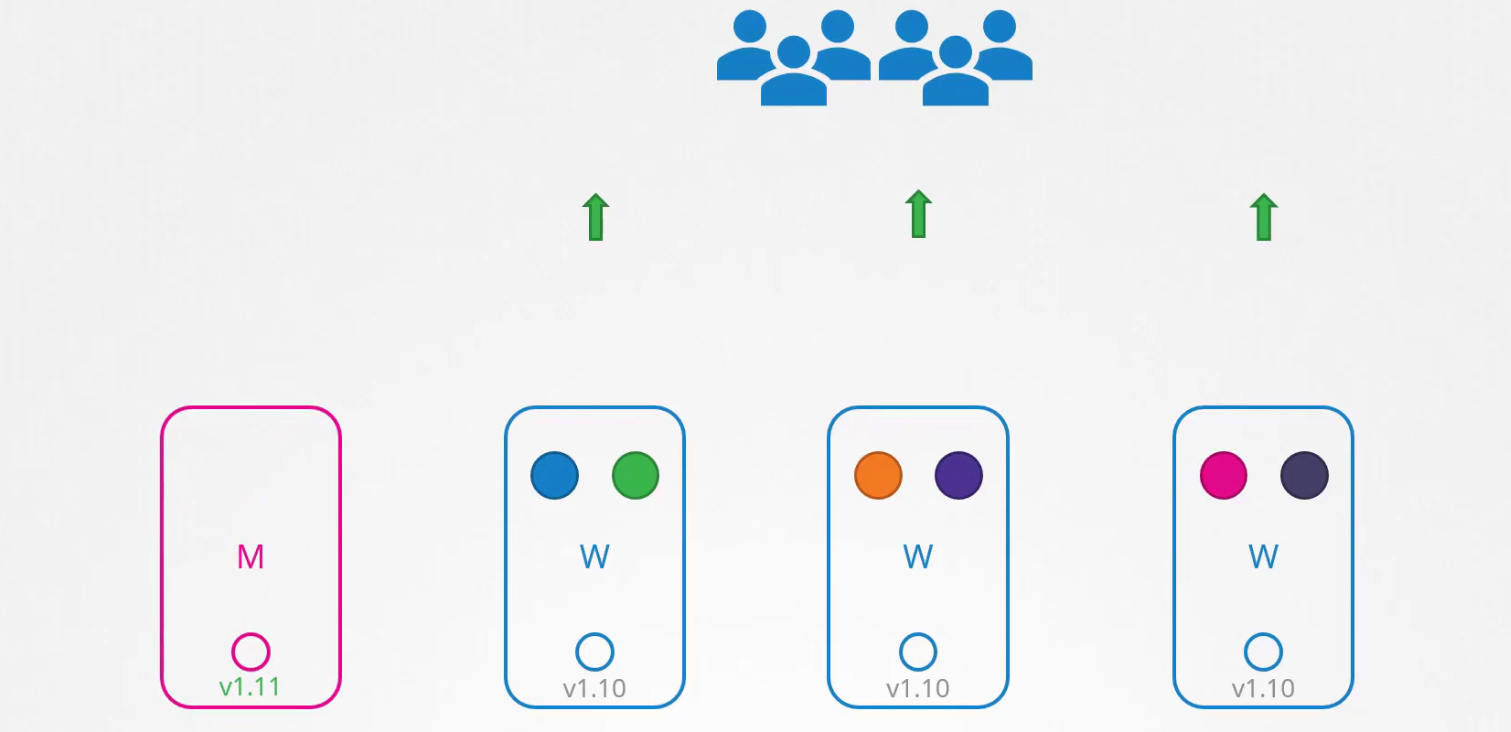
So, what we can do now is take down one node one at a time and if the pods are part of a deployment, they will go to different nodes.
Once updated to v1.11 , we will make node-1 schedulable.
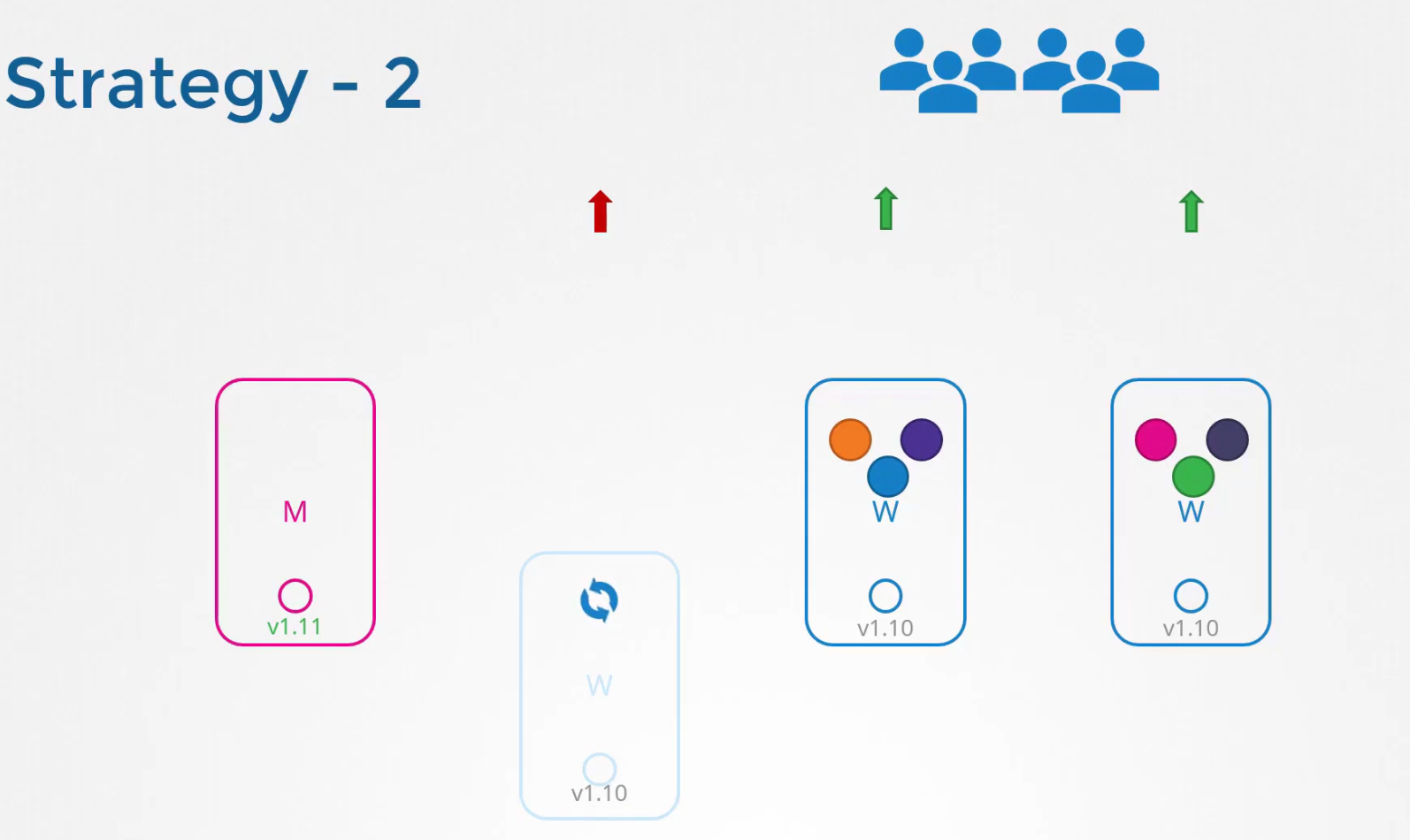
Then we will take down node -2 and thus all the pods if part of replicaset, will be distributed to other nodes.
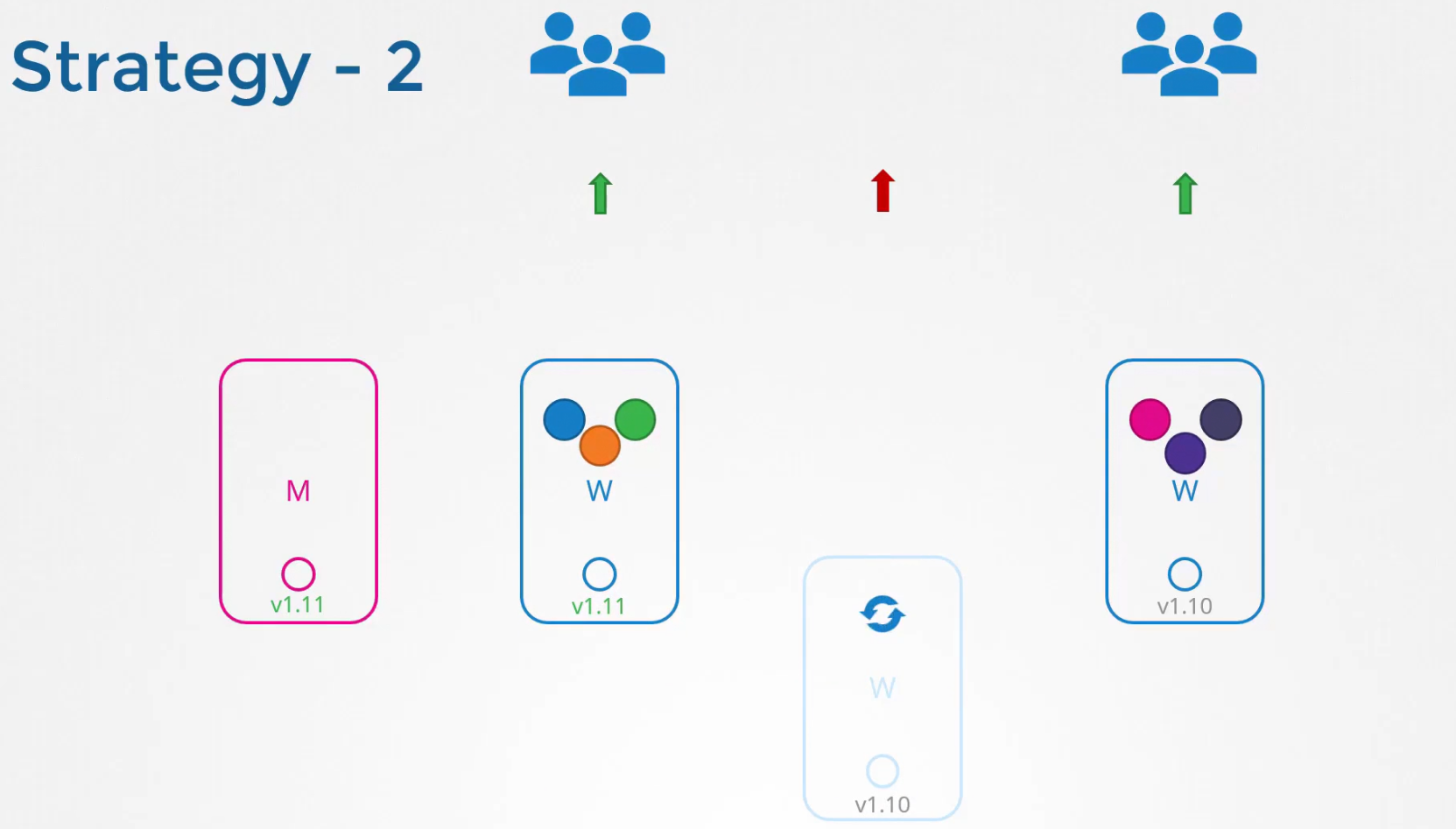
We will repeat this process for node-3
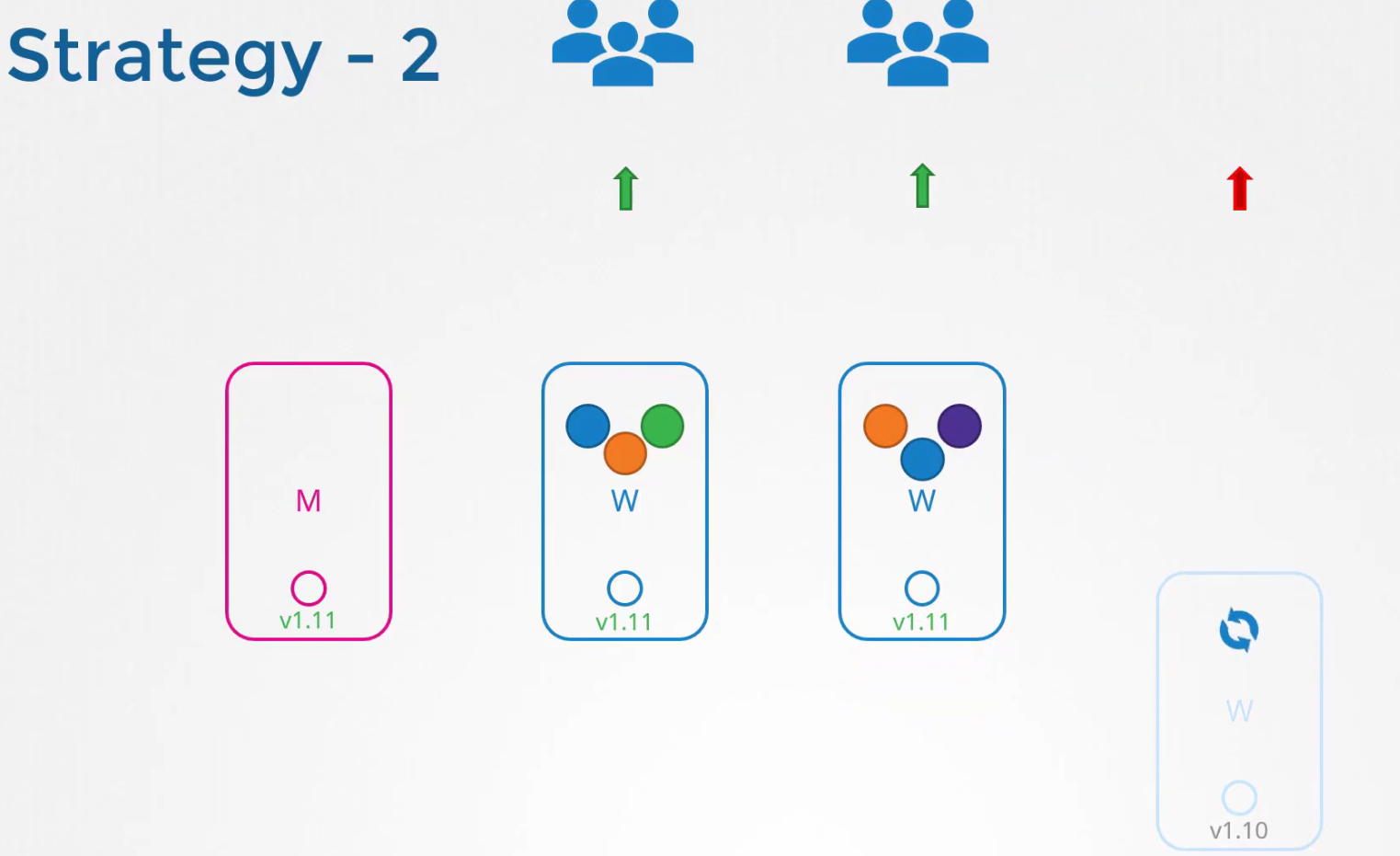
Or, there are other ways, like creating new updated pods and distribute the pods on them.
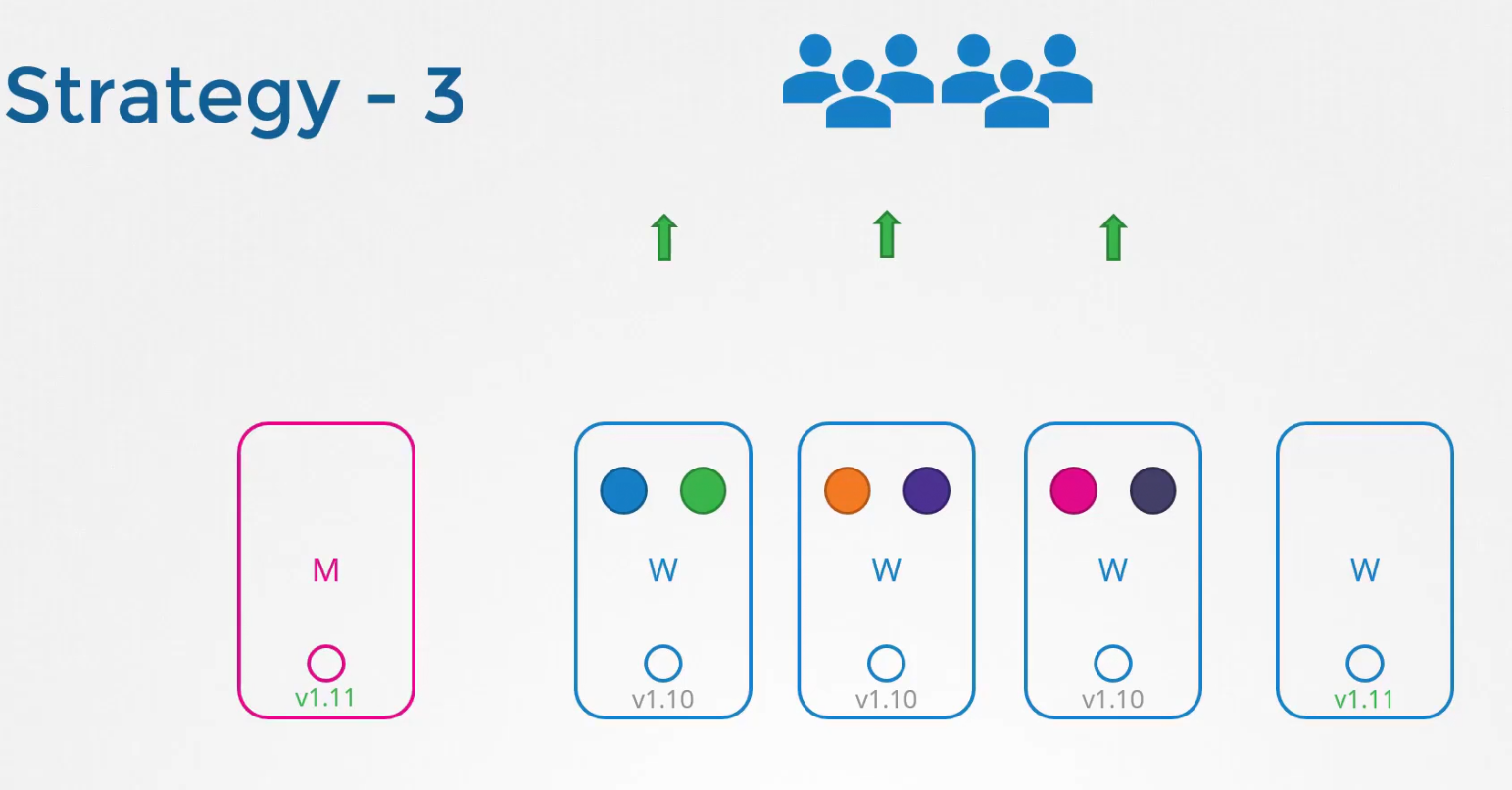
This way is seen cloud services mostly. So, we can do this, one at a time to get all updated nodes.
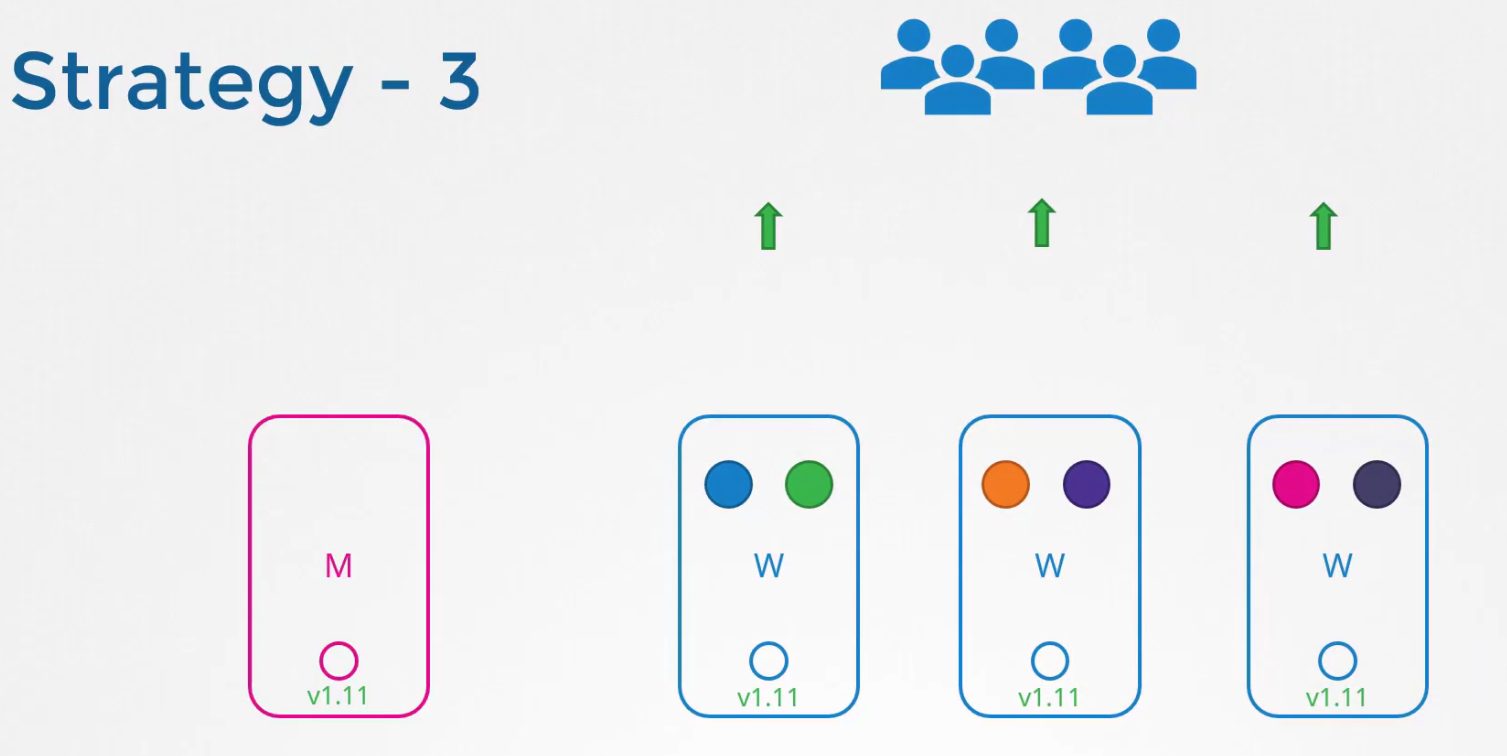
Let’s update using kubeadm
Assuming we already have v1.11 and we want to udgrade to v1.12, we have to first upgrade the kubeadm version to v1.12,
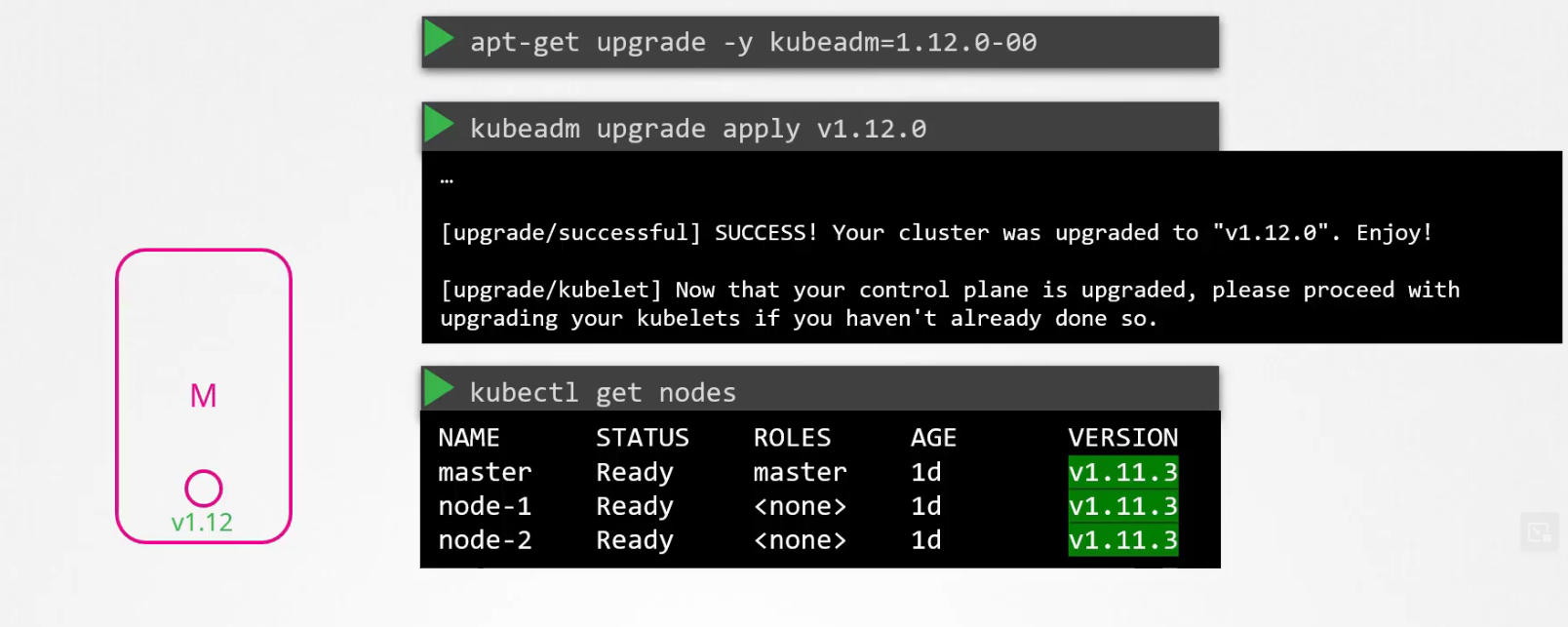
then update existing kubelet out there in the master node.
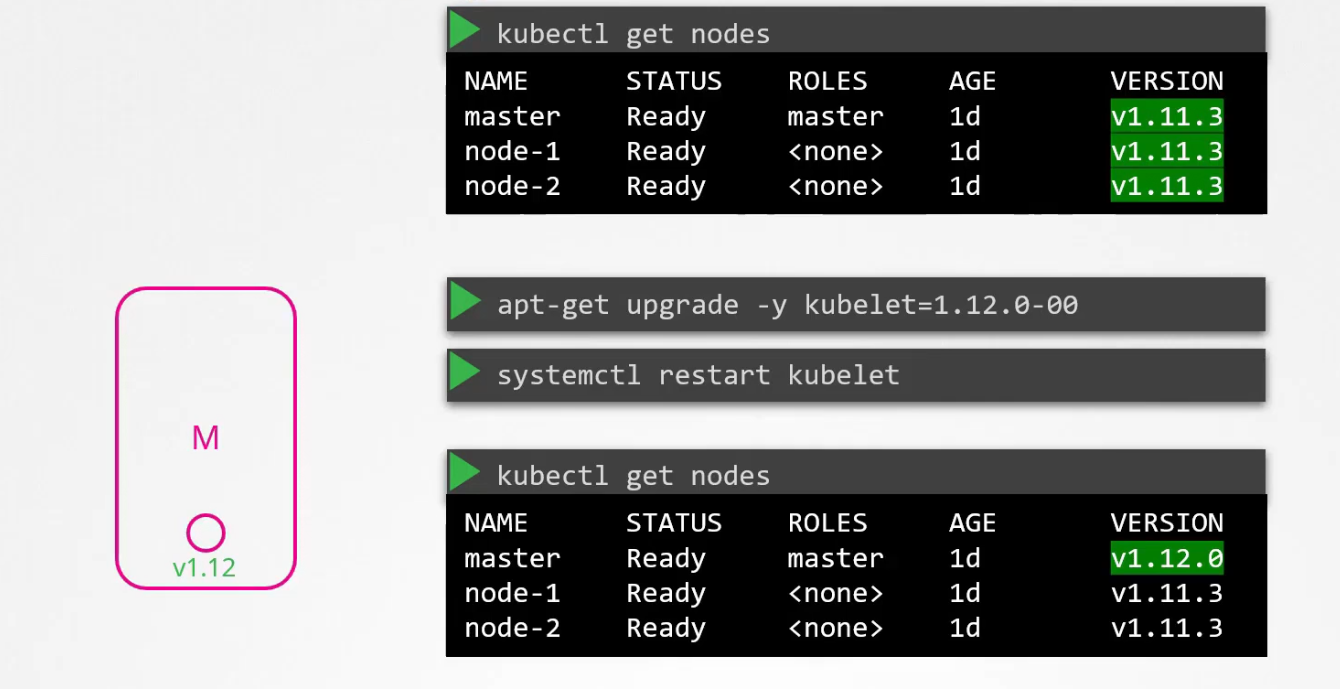
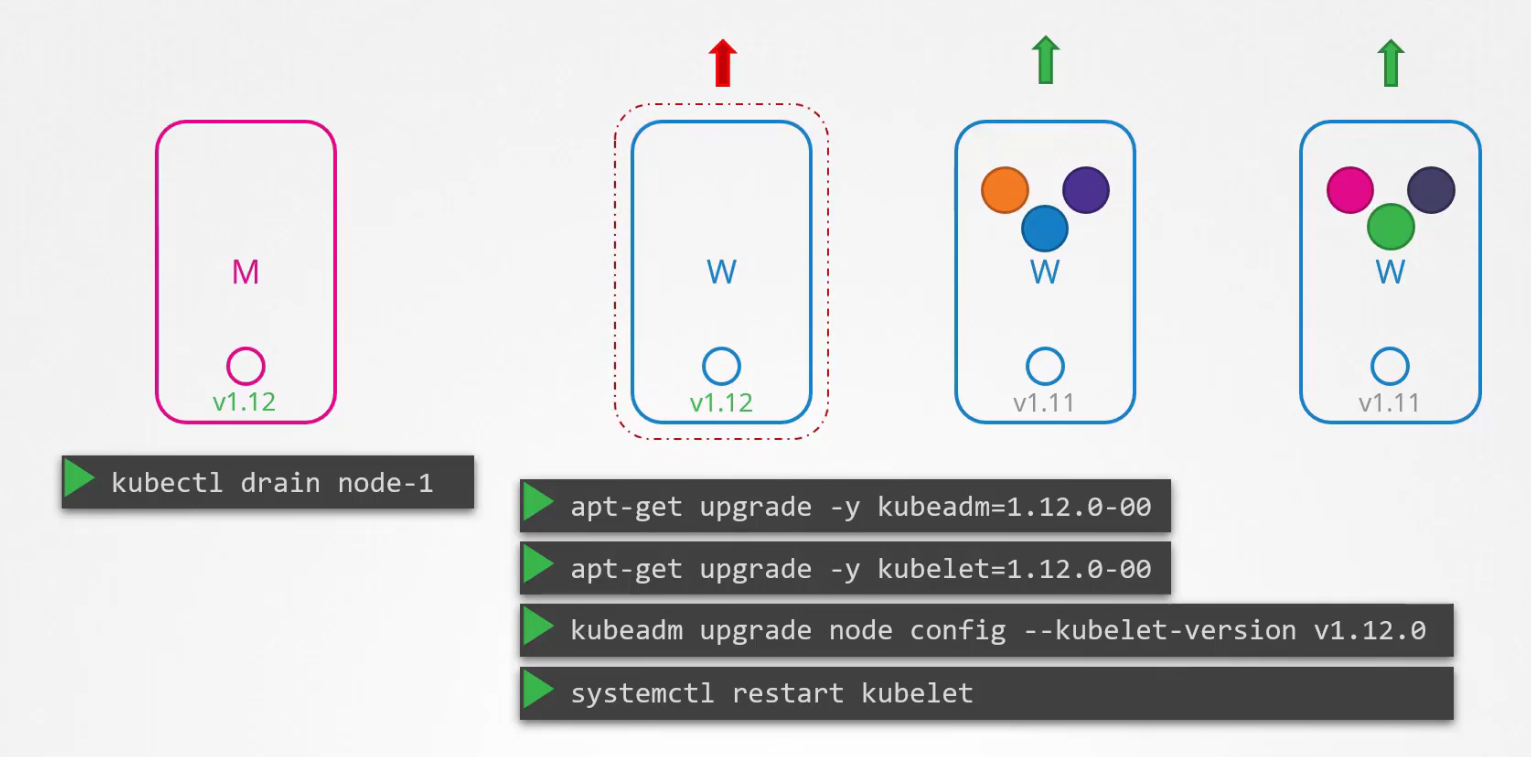
Now the master node is updated properly. Now update node-1, by draining it, then upgrade kubeadm for the node, upgrade the kubelet kept in the node, then upgrade config, restart it.
Now, it’s still unschedulable. We have to uncordon that
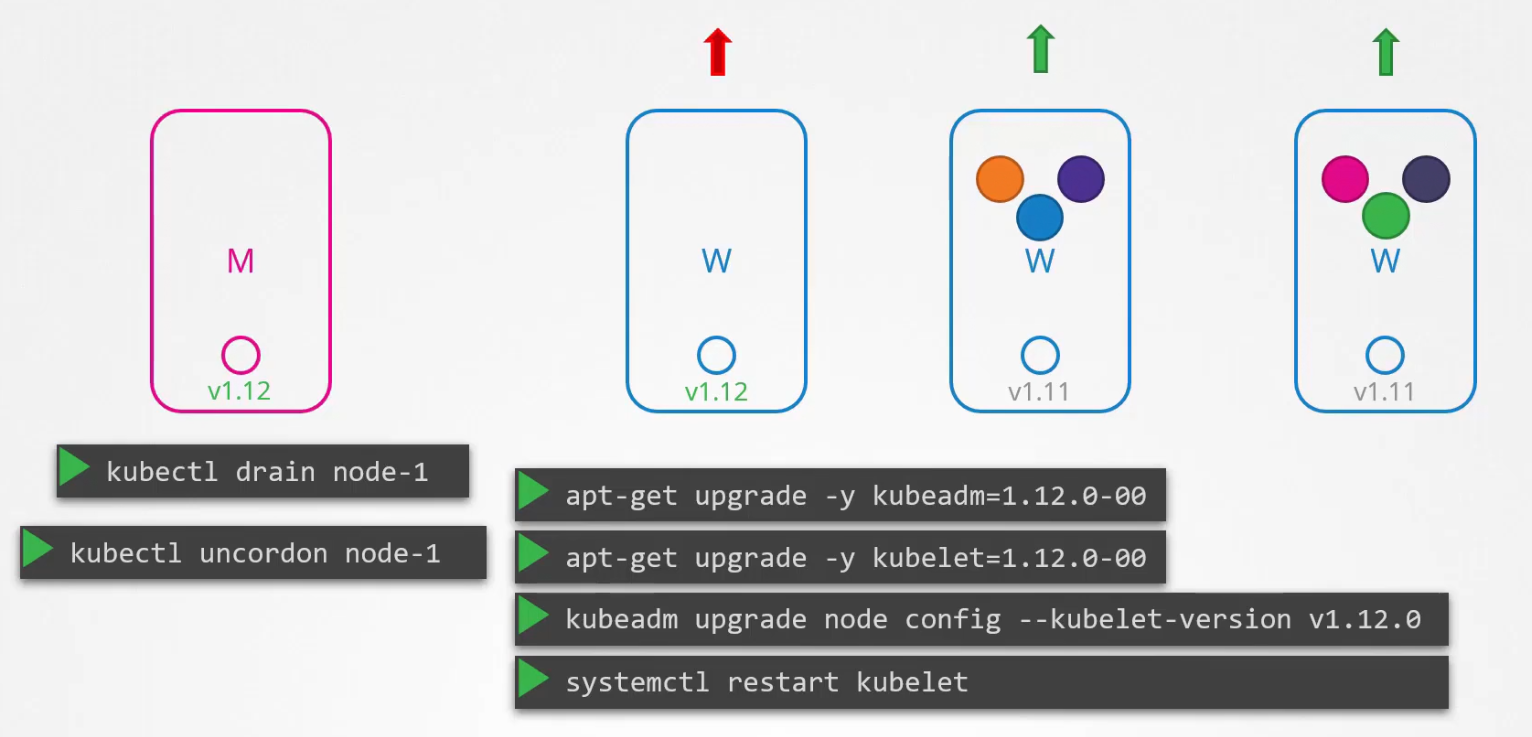
We do it for node-2 and rest nodes!
Done! Check out how to Update kubeadm clusters
Hands-on:
Our cluster is on v1.30.0 Let’s see how can we upgrade using kubeadm
You can check the latest versions by this command
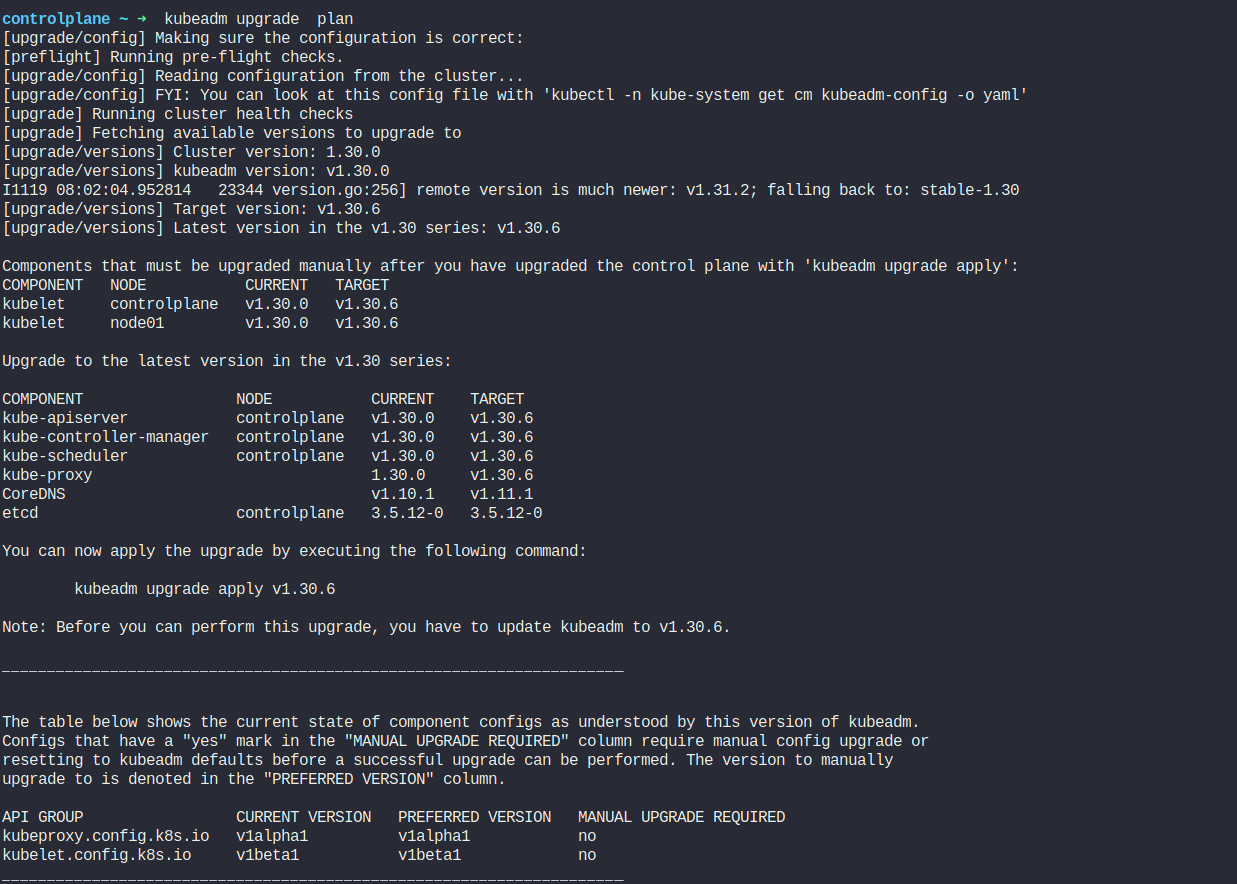
Here you can see “Latest version in the v1.30 series: v1.30.6”. So, we need to upgrade to this version.
Now, we have 2 nodes in our default namespace with version v1.30.0

Let’s update controlplane node:
First drain the node
kubectl drain controlplane --ignore-daemonsets
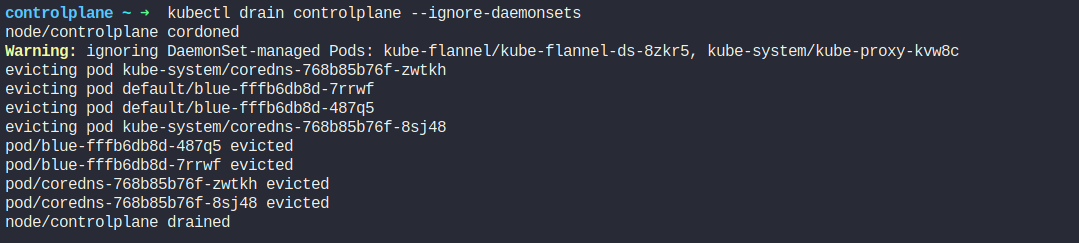
Previously we had pods on controlplane which has moved to rest nodes(node01)

Updated pods list

Now as it’s drained and out of service, we can upgrade it.
Task: Upgrade the controlplane components to exact version v1.31.0
Upgrade the kubeadm tool (if not already), then the controlplane components, and finally the kubelet.
To seamlessly transition from Kubernetes v1.30 to v1.31 and gain access to the packages specific to the desired Kubernetes minor version, follow these essential steps during the upgrade process. This ensures that your environment is appropriately configured and aligned with the features and improvements introduced in Kubernetes v1.31.
On the controlplane node:
Use any text editor you prefer to open the file that defines the Kubernetes apt repository.
vim /etc/apt/sources.list.d/kubernetes.list
Update the version in the URL to the next available minor release, i.e v1.31.

deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.31/deb/ /

After making changes, save the file and exit from your text editor. Proceed with the next instruction.
apt update
apt-cache madison kubeadm
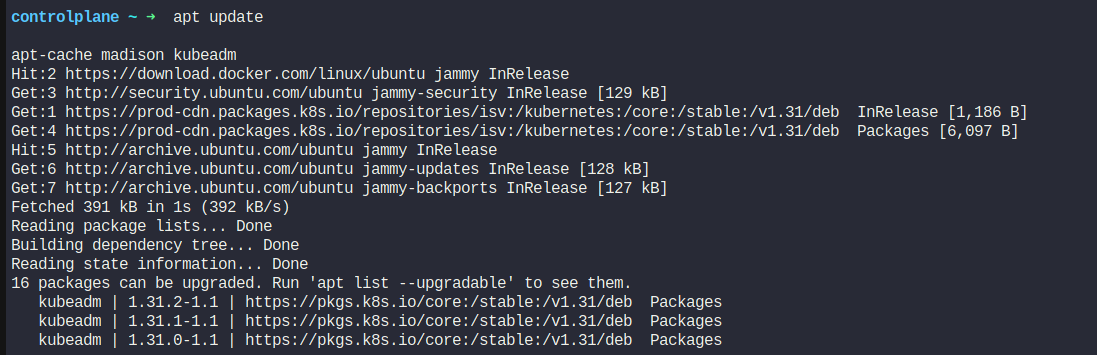
Based on the version information displayed by apt-cache madison, it indicates that for Kubernetes version 1.31.0, the available package version is 1.31.0-1.1. Therefore, to install kubeadm for Kubernetes v1.31.0, use the following command:
apt-get install kubeadm=1.31.0-1.1
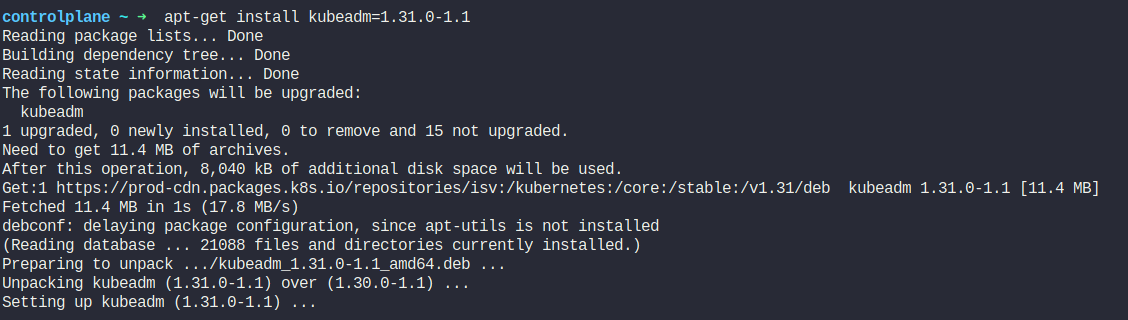
Once the kubeadm is updated, update the kubernetes cluster:
Run the following command to upgrade the Kubernetes cluster.
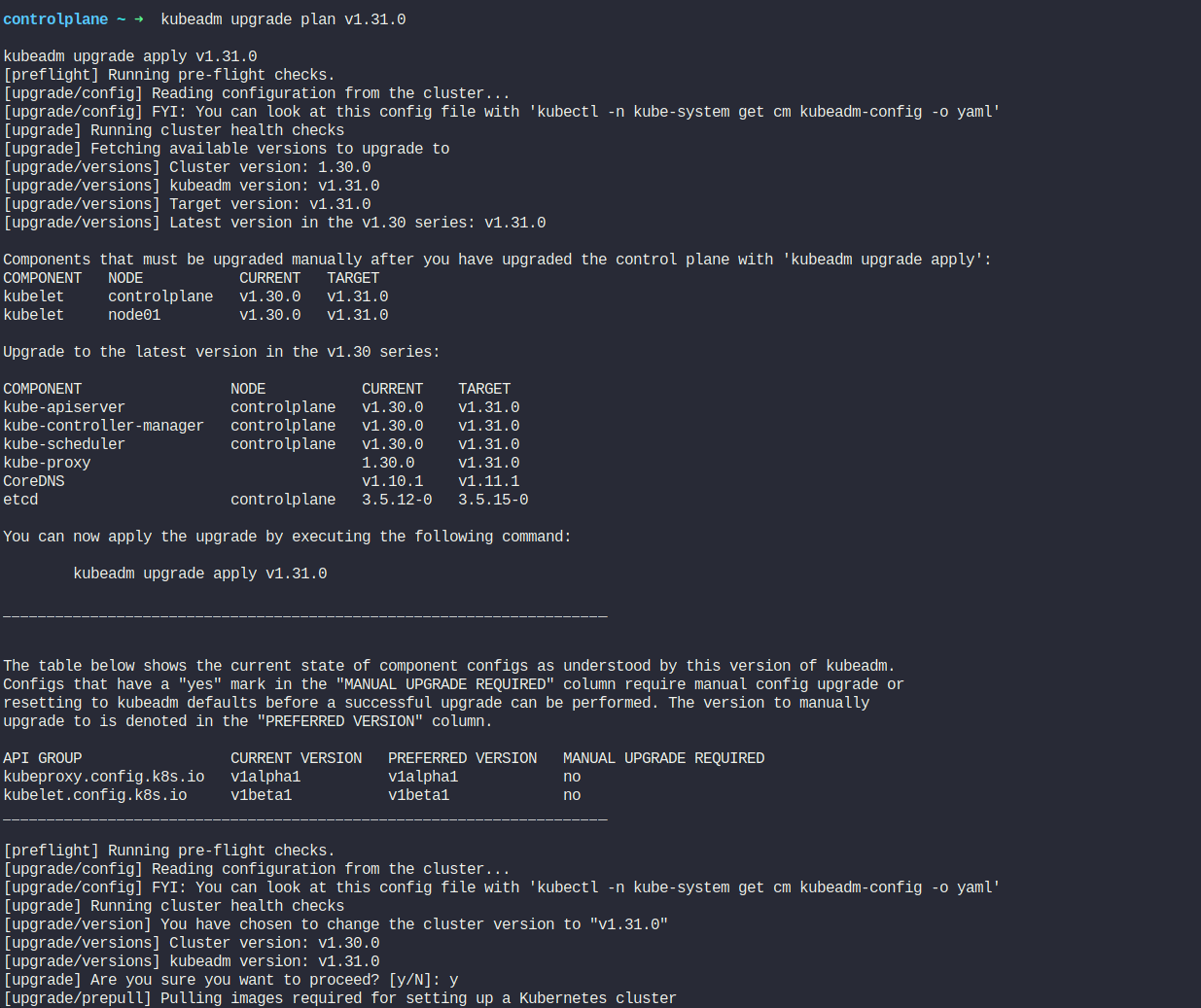
kubeadm upgrade plan v1.31.0
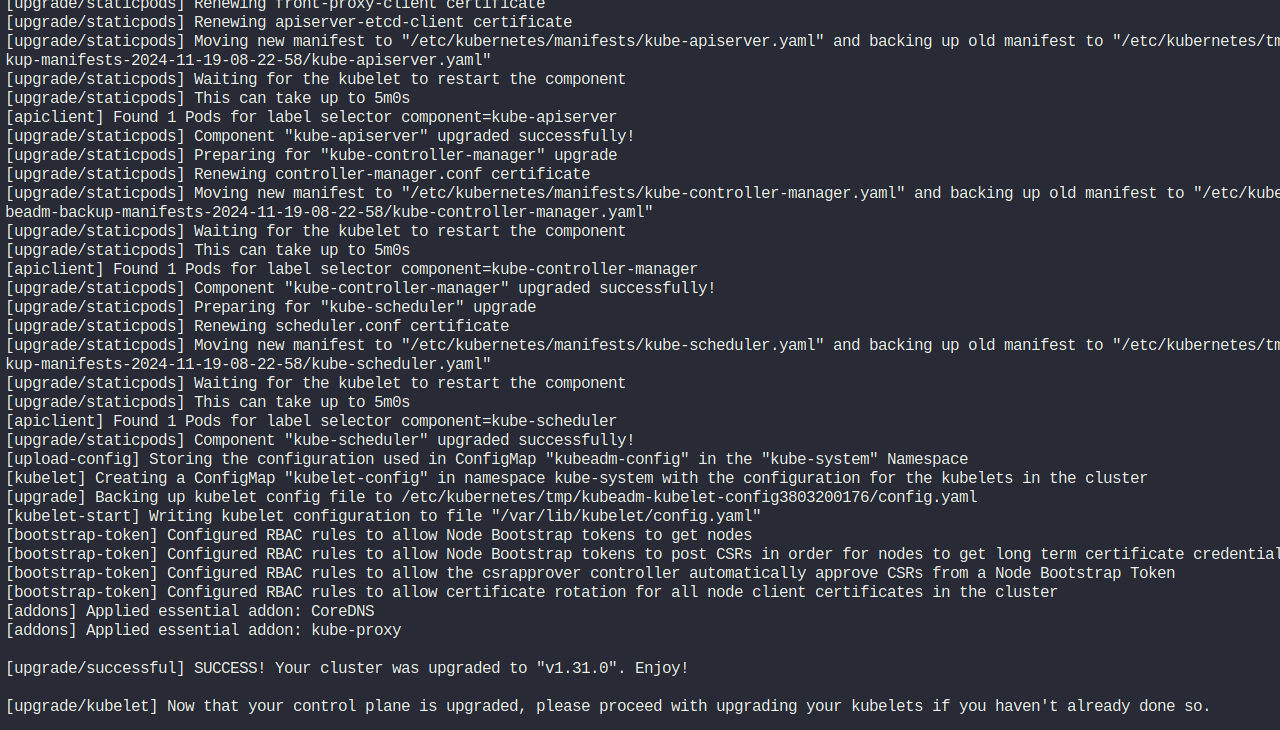
kubeadm upgrade apply v1.31.0
Note that the above steps can take a few minutes to complete.
Now, upgrade the Kubelet version. Also, mark the node (in this case, the "controlplane" node) as schedulable.
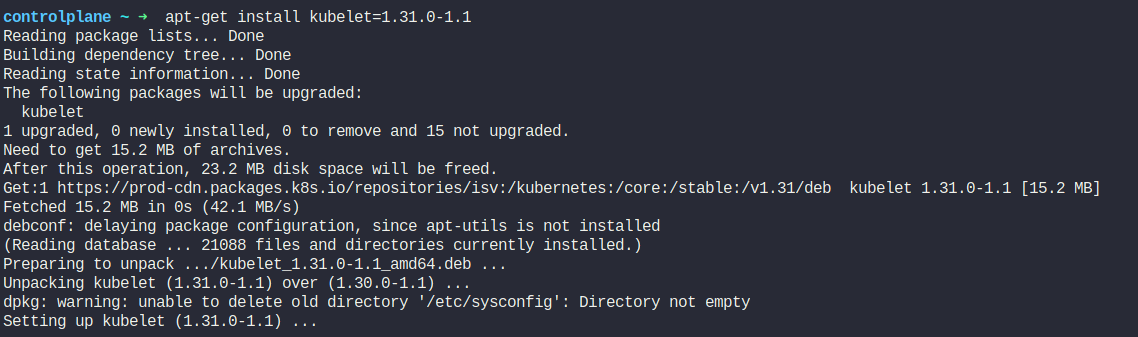
apt-get install kubelet=1.31.0-1.1
Run the following commands to refresh the systemd configuration and apply changes to the Kubelet service:
systemctl daemon-reload
systemctl restart kubelet

Then we make the node schedulable again
kubectl uncordon controlplane
Then we can update the node01 following the same process. We need to drain it
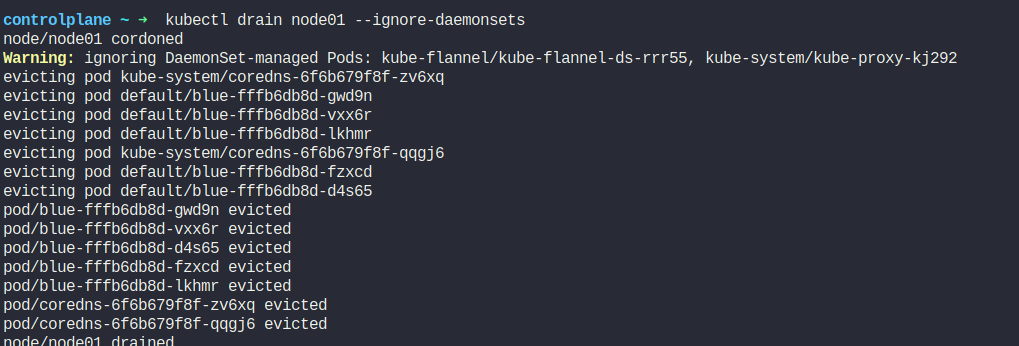
Then we move to node01

and follow all the process we have done for controlplane node earlier.
Backup and restore methods
We may have lots of pods, cluster etc. One way to keep them safe is Github Repo

Another way is, you can save all info in a yaml file
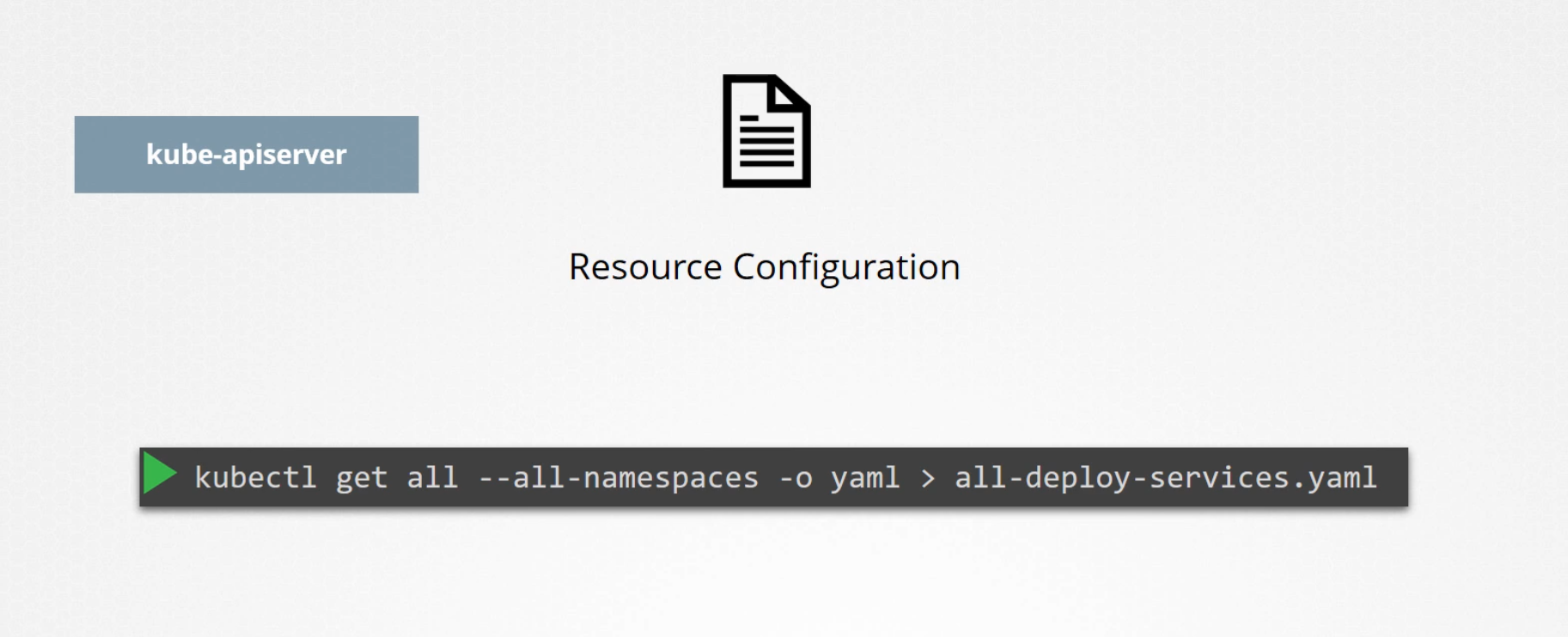
There are tools like VELERO, which can also save our cluster info using kubernetes API

But we need to keep in mind that ETCD Cluster saves all node, pod etc info. So, rather than saving whole kubernetes information, we can save and backup ETCD Cluster info.
We know that every master node has etcd cluster and if we inspect, we can see —data-dir folder which we can back up to backup ETCD Cluster

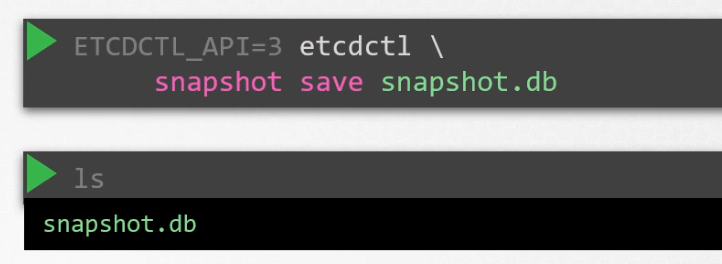
You can also save it as a snapshot. Here a snapshot with name snapshot.db is created
Later when we want to restore, we have to stop the kubeapiserver.
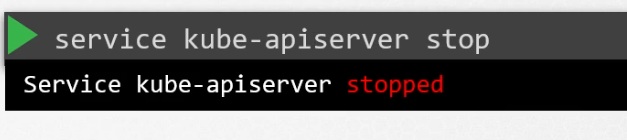
Surely you know kubeapi server depends on etcd. And then , restore the backup mentioning it’s path (where you have saved the backup)
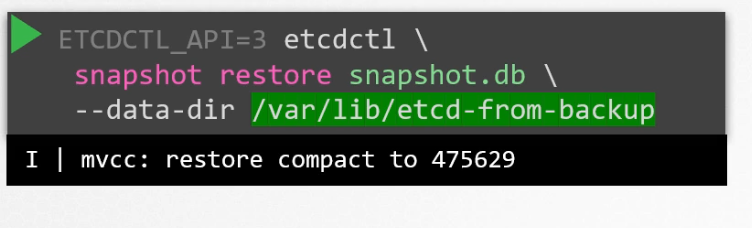
Then we provide the correct path (—data-dir=path where you kept the restored etcd) to the etcd service
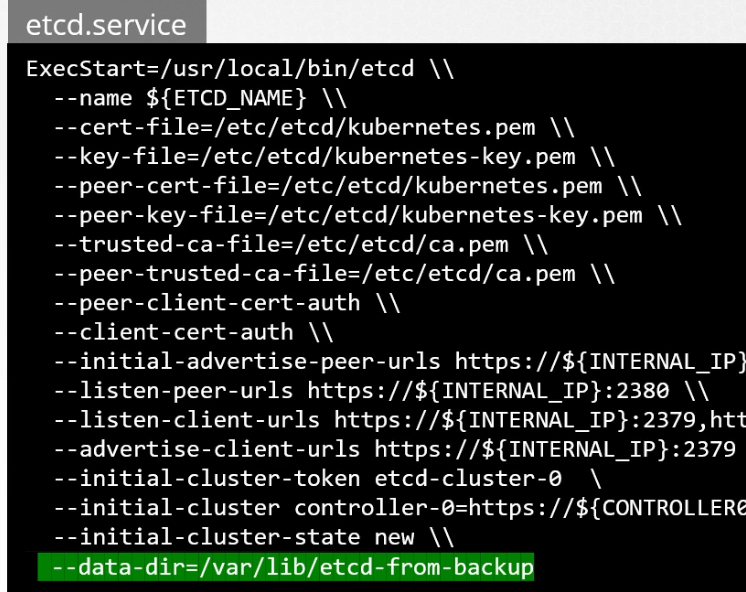
Finally reload and restart
Finally, start the kubeapi server
Hands-on:
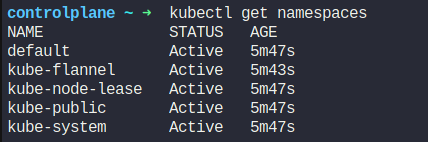
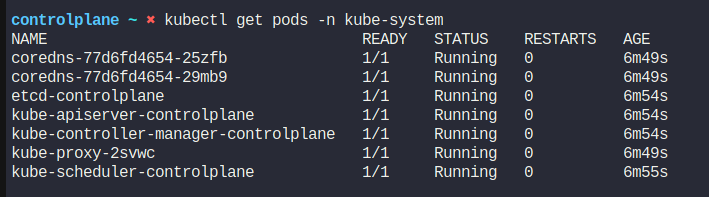
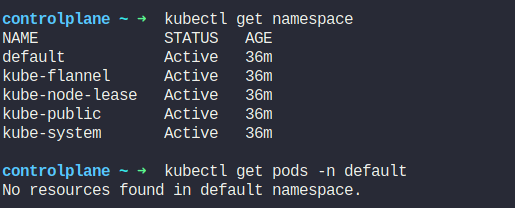
Let’s check the running ETCD on the cluster.
Here we have these namespaces
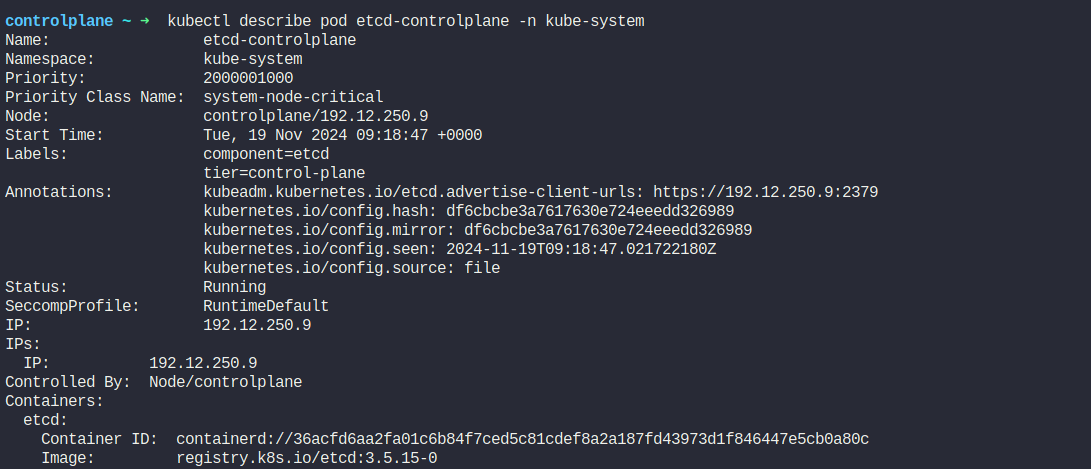
We can see that, it has a pod named etcd-controlplane
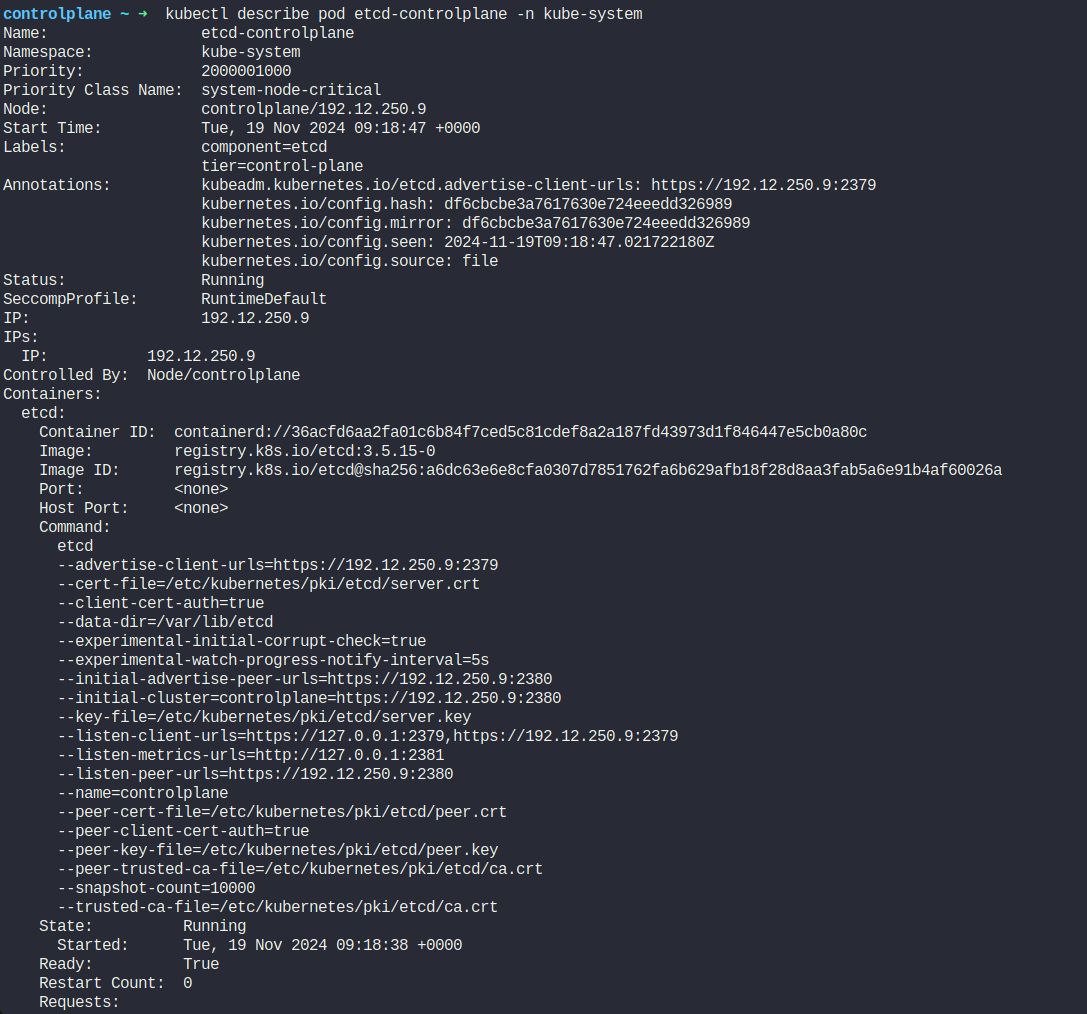
Here we can see the image version
Assuming our master node will have an update today. So, lets back up the etcd on location /opt/snapshot-pre-boot.db
We will use ETCDCTL which has to use API version 3
ETCDCTL_API=3 etcdctl --endpoints=https://[127.0.0.1]:2379 --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key snapshot save /opt/snapshot-pre-boot.db
We need to provide endpoints, ca certificate path, key fie, path to save . You may ask , where did you find these information? Previously we saw all of these path information here. So, we just used them while creating the snapshot
Ok, now assume the master node (default) is under maintenance.
Wake up! We have a conference call! After the reboot the master nodes came back online, but none of our applications are accessible. Check the status of the applications on the cluster. What's wrong?
Because nothing is present there. But etcd cluster saves all of these information and we have backed that up earlier. Let’s get back all of the pods and others using etcd snapshot.
Firstly, save the restored file in /var/lib/etcd-from-backup
Then we will modify the etcd.yaml file and update the volume’s hostPath to new address
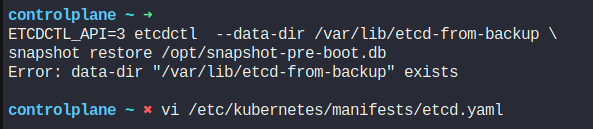
Once we open the yaml file, we can see this
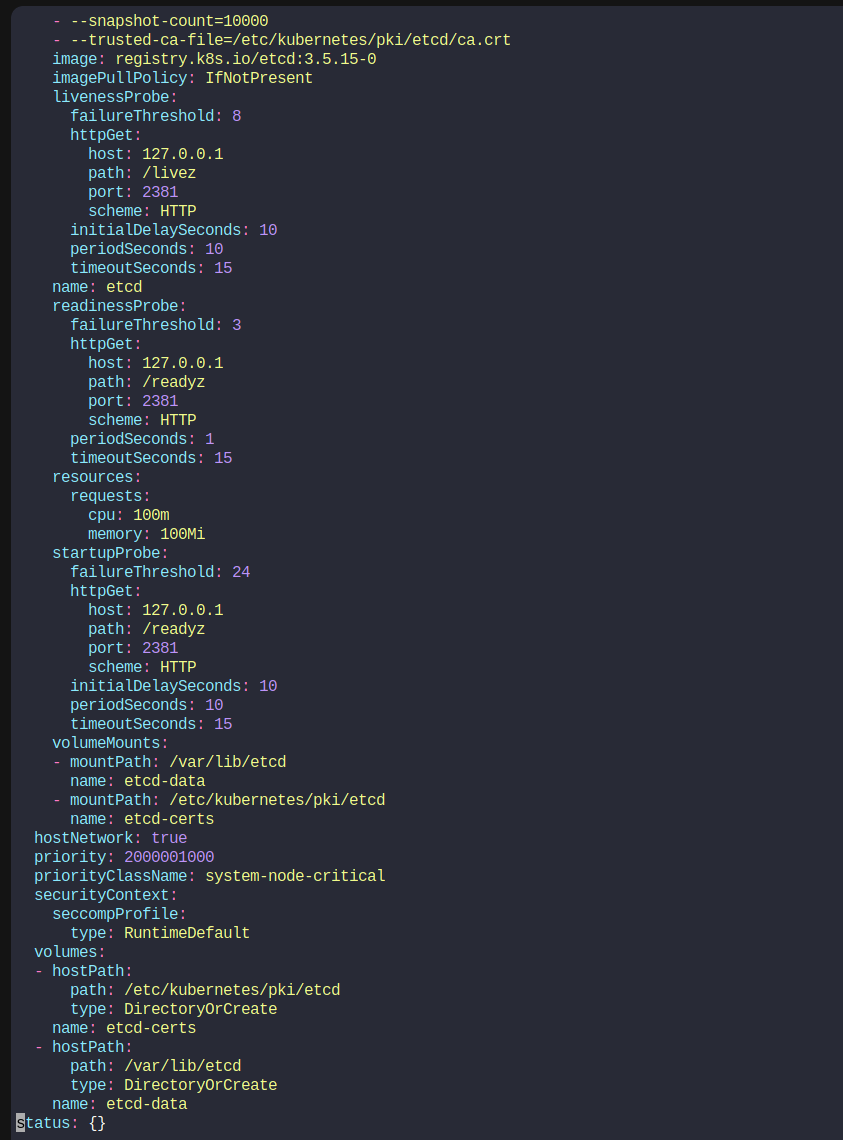
We have updated the path : old directory (/var/lib/etcd) to the new directory (/var/lib/etcd-from-backup).
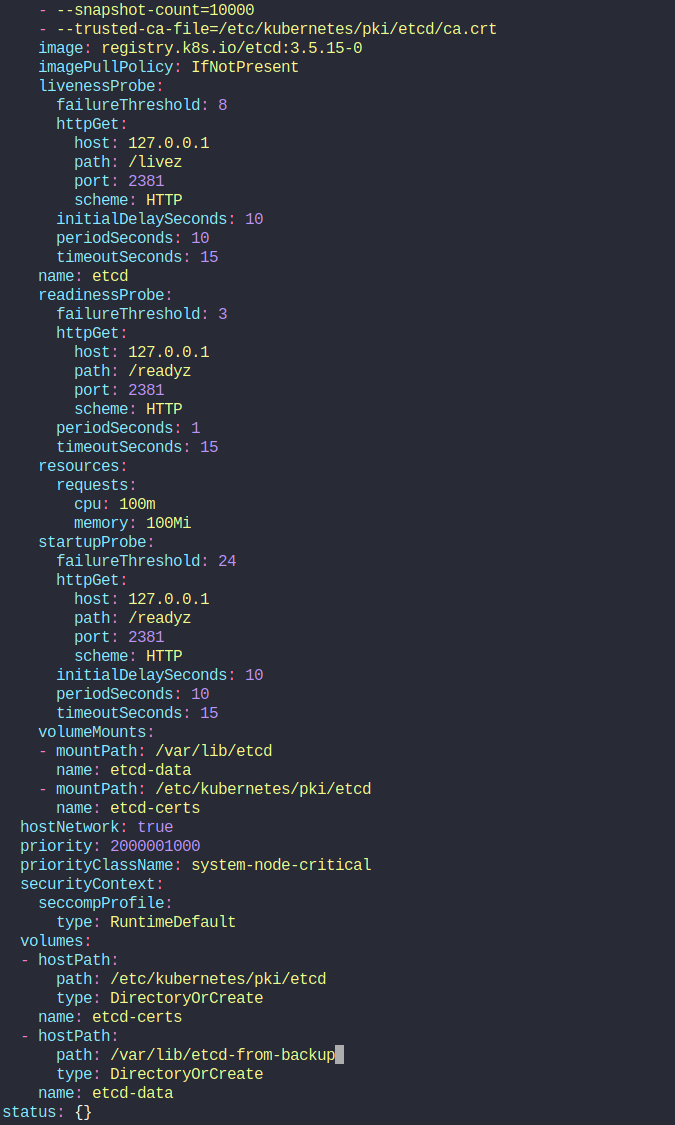
When this file is updated, the ETCD pod is automatically re-created as this is a static pod placed under the /etc/kubernetes/manifests directory
Follow this for more
Subscribe to my newsletter
Read articles from Md Shahriyar Al Mustakim Mitul directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by