Introduction to Natural Language Processing (NLP)
 Ibraheem K
Ibraheem K
What is NLP?
Have you ever wondered how Siri understands your voice commands or how Google Translate works? This is where NLP comes in. NLP is a field of Artificial Intelligence focused on enabling computers to understand, interpret, and generate human language. Basically, NLP sits at the crossroads between computer science and computational linguistics.[1]
The goal of NLP is to bridge the gap between human communication and computer understanding, making it possible for machines to work with language data as humans do. By tackling challenges such as language ambiguity, contextual interpretation, and varied linguistic structures, NLP aims to develop systems that can respond appropriately to human language, whether in written text or spoken language.
History of NLP
NLP’s journey began in the 1950s, with initial efforts focusing on machine translation (using computers to translate languages) based on simple rule-based systems inspired by early AI concepts.[2] However, these systems faced limitations with complex language patterns which slowed progress until the 1960s and 70s, when research turned toward understanding meaning within narrow contexts. This semantic approach was useful, however, wider applications still proved challenging.
In the 1980s, NLP underwent a revival, pivoting to a structured approach where grammar-driven models and logical frameworks helped computers interpret language more predictably and effectively. The era also saw the rise of data-driven methods, supported by increasing computational power and large digital text corpora (collections of written texts). Statistical models and probabilistic approaches enabled practical applications like speech recognition and information retrieval.
The late 1980s marked the introduction of machine learning algorithms that enhanced language understanding further.[2] These advancements set the stage for modern NLP innovations, from voice assistants to real-time language translation, and continue to shape the field today.
Challenges of NLP
As promising as NLP is, it faces several key challenges that make the task of enabling machines to fully understand and generate human language very complex.
Ambiguity: One of the biggest hurdles is ambiguity. Language is inherently ambiguous, with words and phrases often having multiple meanings depending on context. For example, the word “novel” could refer to a fictional book or something that is “new and original”. Resolving this ambiguity requires NLP systems to grasp context, which can vary greatly across different situations.
Contextual Understanding: Another significant challenge is contextual understanding. Unlike mathematical formulas, human language is rich in nuance, emotion, and cultural references. A sentence like "I can’t believe she did that!" could mean many things depending on the speaker’s tone, their relationship with the subject, and the situation. Understanding these subtle cues requires machines to analyze not just the words, but the context in which they are used, which can be difficult for algorithms to capture.
Other challenges include: syntax and grammar variations, cultural and social factors, and computational limitations.
Despite these challenges, advancements in machine learning, deep learning, and increased access to big data are continuously improving NLP’s ability to understand and generate human language, making systems more intelligent and versatile over time.
Core NLP Techniques
Rule-Based Approaches
Early NLP relied heavily on rule-based methods, where linguists and programmers manually defined language rules to guide the system’s understanding of text. These systems used grammar rules, syntax trees, and dictionaries to process language. For instance, in machine translation, rule-based systems would translate words or phrases based on a set of predefined linguistic rules and lookup tables, which were carefully crafted for accuracy. This approach allowed for clear, structured interpretations of sentences and gave systems a solid foundation for handling simpler tasks within highly controlled environments.
However, rule-based systems had significant limitations. The rigidity of predefined rules meant that the systems struggled with the flexibility and nuance of natural language. Handling idioms, slang, and evolving language use was nearly impossible without updating rules, which made scaling rule-based systems across domains or languages difficult. Additionally, rule-based NLP was highly resource-intensive meaning that each new application or language required developing a fresh set of grammar and vocabulary rules from scratch, making these systems relatively inefficient and costly for broad use.
Statistical and Machine Learning Methods
In the late 1980s, NLP made a significant shift with the introduction of statistical models and machine learning approaches[3]. These methods used probability and statistics, leveraging large datasets to teach machines how language elements occur and co-occur in real-world text. Probabilistic tagging, one of the foundational techniques, allowed systems to predict the part of speech for each word based on its surrounding words. For example, statistical models like probabilistic tagging could determine whether 'bank' refers to a financial institution or the side of a river by analyzing surrounding words.
Statistical methods opened the door for machine learning algorithms that could automatically learn patterns from data rather than relying on hand-coded rules. By analyzing massive amounts of text data, these algorithms learned from examples, enabling them to generalize better and adapt to new words and structures more easily than rule-based methods. While these methods improved flexibility and accuracy, they still had limits, especially in complex language tasks where deep contextual understanding was required. Statistical models had a relatively shallow grasp of language, capturing patterns and co-occurrences but often missing the deeper meanings within nuanced sentences.
Deep Learning and Transformers
The development of deep learning and in particular, Transformer models has transformed NLP into a highly sophisticated field, allowing systems to understand language with unprecedented depth. Transformers, like BERT (Bidirectional Encoder Representations from Transformers) and GPT (Generative Pretrained Transformer), use neural networks designed to handle sequential data and to capture contextual relationships between words in complex ways. Transformers excel at understanding language because they learn context by processing entire sentences simultaneously rather than word-by-word, enabling systems to interpret words based on their full context within a text.
BERT and GPT revolutionized NLP by introducing self-attention mechanisms, which allow the model to weigh the importance of each word in relation to others, capturing subtle dependencies in language such as understanding that 'bank' in “She went to the bank” refers to a financial institution.
Deep learning and Transformers have also driven breakthroughs in language generation, enabling chatbots, translation systems, and voice assistants to produce human-like text responses with contextual awareness and fluency.
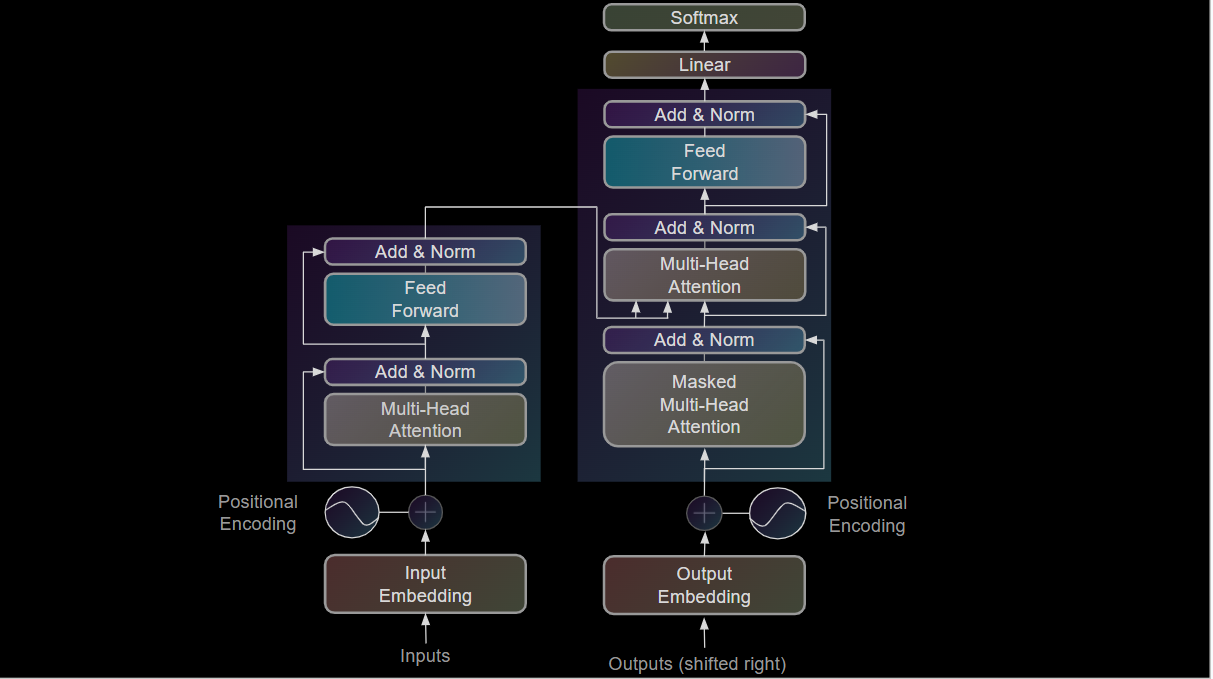
Figure 1: The Transformer Architecture
Applications of NLP
NLP powers a wide range of tasks that enable machines to understand, process, and interact with human language effectively. These tasks fall into some of these major categories:
Language Understanding: (e.g., sentiment analysis, information extraction)
Human-Computer Interaction: (e.g., dialogue systems, question answering)
Speech and Language Processing: (e.g., speech recognition, text-to-speech)
Let’s take a look at some of these applications in detail.
Sentiment Analysis
Sentiment analysis detects the emotional tone behind a piece of text. Businesses use it to analyze customer reviews, social media posts, or survey responses to gauge public sentiment about their products, services, or brands. For example, a company can identify whether tweets about their new product are positive, negative, or neutral.
Information Extraction
Information extraction systems identify and retrieve key details from unstructured text, such as names, dates, locations, or relationships. For example, these systems can process news articles to extract the names of individuals and companies involved in a story or identify important facts from medical records.
Dialogue Systems
Dialogue systems, or conversational agents, include chatbots and virtual assistants like Siri, Alexa, and Google Assistant. These systems are designed to understand user queries and provide relevant, conversational responses. They’re used in customer support, home automation, and as personal productivity tools, among other applications.
Question Answering Systems
These systems process user queries to provide direct, concise answers. Search engines use question answering to return highlighted snippets for questions like "What is the capital of Nigeria?" or "How does photosynthesis work?"
Machine Translation
Machine translation enables computers to translate text from one language to another. Tools like Google Translate use advanced algorithms to capture the meaning of a sentence in the source language and produce an equivalent in the target language. This application is widely used in breaking language barriers, from casual conversations to international business communication.
Text Summarization
Text summarization involves condensing large pieces of text into shorter summaries while retaining the most critical information. It’s useful for generating concise versions of news articles, research papers, or legal documents, saving time for readers. Automatic summarization tools can create both extractive summaries (picking key sentences from the original text) and abstractive summaries (creating new sentences to convey the main points).
Other applications include:
Speech Recognition: Converting spoken language into text.
Text-to-Speech Systems: Converting written text into spoken words (Reverse of speech recognition).
Email Filtering and many more.
Before wrapping up, let’s dive into a trending topic: Large Language Models (LLMs) and their transformative role in the field of NLP.
Large Language Models (LLMs)
With the popularity of systems like ChatGPT and Gemini, this term has become very popular. Large Language Models (LLMs) are a specialized subset of NLP systems. They are trained on enormous amounts of text data to understand, generate, and manipulate human language. Examples like GPT (Generative Pre-trained Transformers) have transformed tasks such as text generation, summarization, question-answering, and more. They use deep learning, specifically the Transformer architecture, to grasp language in nuanced and contextually aware ways.
Important Features of LLMs
Scale: Trained on billions of parameters and large datasets, making them highly generalizable.
Context-Awareness: LLMs use attention mechanisms to capture dependencies between words across large chunks of text, allowing them to understand language in context.
Versatility: They are pre-trained on a broad corpus of text and fine-tuned for specific applications, enabling adaptability to diverse tasks.
How LLMs Differ from Traditional NLP Approaches
1. Context Window
NLP Models: Early NLP systems, such as rule-based and statistical models, could only process a limited amount of text at a time, often focusing on sentence-level context. This led to challenges in understanding complex relationships across longer documents.
LLMs: With a larger context window, LLMs can process hundreds or thousands of tokens (a unit of text that is broken down from a larger piece of text) at once. This allows them to analyze and generate language that accounts for broader context, such as entire paragraphs or sections of text.
2. Perplexity Score
NLP Models: Perplexity is like the confidence score of a language model. Lower perplexity means it’s better at predicting the next word or phrase. Perplexity was often higher for traditional NLP systems, indicating less accurate predictions. Early models struggled with linguistic variability and ambiguity, leading to less coherent outputs.
LLMs: LLMs achieve much lower perplexity scores due to their ability to generalize across massive datasets. The Transformer architecture, combined with extensive pre-training, allows them to make predictions that are more accurate and contextually appropriate.
3. Understanding and Generation
NLP Models: Traditional models were designed for specific tasks, such as named entity recognition (NER) or part-of-speech tagging. They lacked the ability to generalize across multiple tasks without retraining.
LLMs: LLMs are multi-task learners. Once pre-trained, they can be fine-tuned for various applications, from writing essays to answering questions, without requiring complete retraining for each task.
4. Handling Ambiguity
NLP Models: Rule-based systems struggled with ambiguous words and phrases, as they lacked nuanced semantic understanding.
LLMs: Through pre-training on diverse datasets, LLMs can infer meaning based on context, making them better at resolving ambiguities and handling idiomatic expressions.
LLMs have redefined NLP by addressing its limitations in context-awareness, prediction accuracy, and task generalization. Their expansive context windows and superior perplexity scores allow them to handle complex, real-world language challenges, setting them apart as a groundbreaking evolution in language technology.
As NLP continues to evolve, it is reshaping how we interact with technology and breaking barriers in communication. With advancements in LLMs and AI, the future of language understanding is limitless.
Thank you for taking the time to read this article to the end! I hope you found it insightful and engaging. If you enjoyed it, please consider liking, commenting with your thoughts or questions, and sharing it with others who might find it interesting. Your support means a lot and helps more people discover this content!
References
Fanni, S.C., Febi, M., Aghakhanyan, G., & Neri, E. (2023). Natural Language Processing. In: Klontzas, M.E., Fanni, S.C., & Neri, E. (Eds.), Introduction to Artificial Intelligence: Imaging Informatics for Healthcare Professionals. Springer, Cham. Available at: https://doi.org/10.1007/978-3-031-25928-9_5.
Keith D. Foote, "A Brief History of Natural Language Processing," , Dataversity, [Online]. Available: https://www.dataversity.net/a-brief-history-of-natural-language-processing-nlp.
Wikipedia, "Natural language processing," Wikipedia, [Online]. Available: https://en.wikipedia.org/wiki/Natural_language_processing#Statistical_approach.
Subscribe to my newsletter
Read articles from Ibraheem K directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Ibraheem K
Ibraheem K
Aspiring machine learning engineer