Loading files automatically to bronze lakehouse
 Kay Sauter
Kay Sauter
In my last post on LinkedIn, I explained how to export AdventureWorks2022 tables to csv files. If you don’t want to generate them, you can get them here, as stated in the last post (after my edit in which I realized I made a mistake). My actual blog https://kayondata.com is currently being moved to another place, hence not updated at the moment.
Certainly, it is best to avoid CSV files today. However, CSV files are still very common, so I am using this approach first, but I plan on writing other posts on other ways to do this. Another reason why I am using CSV files is the fact that this is also a very nice starting point to learn some basics and to exercise some data engineering stuff. Nevertheless, if you find yourself in a situation of choosing loading directly from a database without files, usually, this is the better route. If you have the possibility to use parquet instead of CSV, usually parquet should be the winner in the decision.
That said, let’s start with some code that I’ve written some months back on runtime 1.2 (Spark 3.4, Delta 2.4), but it should work on runtime 1.3 (Spark 3.5, Delta 3.2) as well, according to my test today. The code does quite some stuff, and it expects you to have an existing lakehouse that your notebook is attached to. Moreover it expects you to have a lakehouse called meta_lakehouse which is used to log the data loads and errors. You’ll see an output that returns some simple plausibility checks:
import os, time, datetime
from pyspark.sql.functions import monotonically_increasing_id, lit, current_timestamp, when, col, regexp_replace, array, concat_ws
from pyspark.sql import Row
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, TimestampType
from notebookutils import mssparkutils
# Specify the folder containing CSV files
csv_folder = "Files"
# Get a list of all files in the folder
files = notebookutils.fs.ls(csv_folder)
# Filter for CSV files
csv_files = [file.path for file in files if file.name.endswith(".csv")] # to test only one file, simply write the name before .csv
# Define the schema for the log DataFrame so it has have good column names
log_schema = StructType([
StructField("file_name", StringType(), True),
StructField("row_amount_file", IntegerType(), True),
StructField("row_amount_table", IntegerType(), True),
StructField("row_amount_diff", IntegerType(), True),
StructField("load_timestamp_utc_bronze", TimestampType(), True)
])
# Define the schema for the malformed records DataFrame so it has good column names
malformed_schema = StructType([
StructField("file_name", StringType(), True),
StructField("record_number", IntegerType(), True),
StructField("entire_record", StringType(), True),
StructField("explanation", StringType(), True),
StructField("timestamp", TimestampType(), True)
])
# Initialize an empty DataFrame for log entries with the defined schema
df_log = spark.createDataFrame([], schema=log_schema)
df_mal = spark.createDataFrame([], schema=malformed_schema)
df_mal_log = spark.createDataFrame([], schema=malformed_schema)
# Initialize a counter for warnings
warning_count = 0
# count files
csv_files_count = [file for file in files if file.name.endswith('.csv')]
csv_count = len(csv_files_count)
file_processed_count = 0
# Process each CSV file
for csv_file in csv_files:
file_processed_count += 1
table_name = os.path.splitext(os.path.basename(csv_file))[0] # Extract table name from the file name (remove ".csv" extension)
table_name = table_name.replace(".","_") # remove "." for database schema and replace it with "_"
print(f"{table_name}.csv is being processed. Remaining files to process: {csv_count - file_processed_count}")
# Get the number of lines in the CSV file
lines = spark.read.text(csv_file)
line_count = lines.count() - 1 # -1 to exclude the header
print(f"{table_name} has this amount of lines: {line_count:,}".replace(",", "'"))
# Read the CSV file with PERMISSIVE mode to get all records
df_all = spark.read.options(
delimiter=",",
header=True,
encoding="UTF-8",
inferSchema=True,
multiLine=True,
escapeQuotes=True,
mode="PERMISSIVE"
).csv(csv_file)
# Read the CSV file with DROPMALFORMED mode to get only valid records
df_well = spark.read.options(
delimiter=",",
header=True,
encoding="UTF-8",
inferSchema=True,
multiLine=True,
escapeQuotes=True,
mode="DROPMALFORMED"
).csv(csv_file)
# Identify malformed records by diff it
df_mal = df_all.subtract(df_well)
# Add a record number to the malformed records dataFrame
df_mal = df_mal.withColumn("record_number", monotonically_increasing_id())
columns = ['record_number'] + [col for col in df_mal.columns if col != 'record_number']
df_mal = df_mal.select(columns)
# Show the malformed records with their record numbers
print(f"The amount of read well formed lines: {df_well.count():,}".replace(",","'"))
if df_mal.count() == 0:
print(f"\033[92mThe amount of read mal formed lines: {df_mal.count():,}\033[0m".replace(",","'"))
else:
print(f"\033[91mThe amount of read mal formed lines: {df_mal.count():,}\033[0m".replace(",","'"))
# display(df_mal)
# Add id column and put it into the front
df_well = df_well.withColumn("id", monotonically_increasing_id())
columns_ordered = ["id"] + [col for col in df_well.columns if col != "id"]
df_well = df_well.select(*columns_ordered)
# Add load_timestamp
df_well = df_well.withColumn('load_timestamp_utc_bronze', current_timestamp())
# Write to Delta table
df_well.write.format("delta").mode("overwrite").option("overwriteSchema", "true").saveAsTable(table_name)
# Check the number of rows in the Delta table
delta_table = spark.table(table_name)
delta_count = delta_table.count()
print(f"{table_name} has this amount of lines in the delta table: {delta_count:,}".replace(",", "'"))
# Create a dataframe for the current log entry
df_current_log = spark.createDataFrame([(
table_name,
line_count,
delta_count,
line_count - delta_count,
datetime.datetime.now() # Use current timestamp
)], schema=log_schema)
# Append the current log entry to the log DataFrame
df_log = df_log.union(df_current_log)
# Append the current malformed dataframe to a log dataframe
# display(df_mal)
# df_mal_log = df_mal_log.union(df_mal)
# Prepare the malformed records for logging
df_mal_log_entry = df_mal.withColumn("file_name", lit(table_name)) \
.withColumn("entire_record", concat_ws("|||", *df_mal.columns)) \
.withColumn("explanation", lit("malformed")) \
.withColumn("timestamp", current_timestamp()) \
.withColumn("record_number", monotonically_increasing_id())
# Select the columns in the desired order
df_mal_log_entry = df_mal_log_entry.select("file_name", "record_number", "entire_record", "explanation", "timestamp")
# Append the current malformed records to the log DataFrame
df_mal_log = df_mal_log.union(df_mal_log_entry)
# Compare the counts and print messages
if line_count == delta_count:
print(f"\033[92mSUCCESS: {table_name}.csv loaded into Delta table {table_name} with matching line counts\033[0m")
print(f"\n")
else:
print(f"\033[91mERROR: {table_name}.csv line count {line_count:,}".replace(",", "'") + f" does not match Delta table line count {delta_count:,}".replace(",", "'") + f" \033[0m")
print(f"\n")
warning_count += 1
# Write the log DataFrame to the lakehouse log table in the meta_lakehouse database
if not df_log.filter(df_log["row_amount_diff"] > 0).rdd.isEmpty():
df_log.write.format("delta").mode("append").saveAsTable("meta_lakehouse.load_log_bronze")
print(f"\n\033[93m ALL CSV files LOADED with WARNING into meta_lakehouse.load_log_bronze table.\033[0m")
else:
print(f"\n\033[92m ALL CSV files SUCCESSFULLY LOADED into meta_lakehouse.load_log_bronze table.\033[0m")
# Write the malformed records DataFrame to a new Delta table in the meta_lakehouse database
if not df_mal_log.rdd.isEmpty():
df_mal_log.write.format("delta").mode("append").saveAsTable("meta_lakehouse.bad_records")
print(f"\n\033[93m Malformed records have been written to the meta_lakehouse.bad_records table.\033[0m")
# Print the number of tables that gave warnings
if warning_count == 0:
print(f"\n\033[92m Number of tables with warnings: NONE - SUCCESS \033[0m")
else:
print(f"\n\033[91m Number of tables with warnings: {warning_count} → GO CHECK LOG! \033[0m")
So if you run this, you’ll see a lot outputs like this:
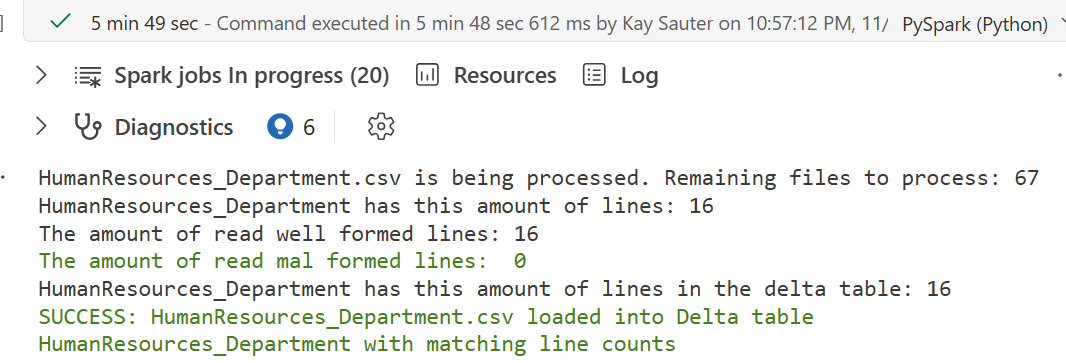
As you can see, it outputs some table names and csv names. The csv-names are not actually very correct here, because the actual csv name is HumanResources.Departement.csv, so there is a dot that derives from the database schema. In this case, I am using a lakehouse without schema (it is still in preview) and the lakehouse does not allow points in a table name, hence I replaced the point with an underscore in line 53 via table_name = table_name.replace(".","_"), as also the comment after the very code explains.
Now, you could ask why I didn’t want to use shortcuts to load the data - I could have done this and it is a neat trick for many occasions. In this case, I not only wanted to showcase the possibility to use a meta_lakehouse, but also the possibility to have more control in the data that gets loaded here. For example, I get the possiblity to have some simple plausibility checks that certainly could be done much more sophisticated. This is going to be another blog in future.
An interesting code block is here (line 62):
# Read the CSV file with PERMISSIVE mode to get all records
df_all = spark.read.options(
delimiter=",",
header=True,
encoding="UTF-8",
inferSchema=True,
multiLine=True,
escapeQuotes=True,
mode="PERMISSIVE"
).csv(csv_file)
# Read the CSV file with DROPMALFORMED mode to get only valid records
df_well = spark.read.options(
delimiter=",",
header=True,
encoding="UTF-8",
inferSchema=True,
multiLine=True,
escapeQuotes=True,
mode="DROPMALFORMED"
).csv(csv_file)
Firstly, we get to give pySpark the possiblity to load all data and to try to figure out what datatypes the fields are. delimiter=”,” tells pySpark that it should use commatas, but you could use semicolon if needed, or another character. inferSchema=True is actually superfluous here as the spark.read.options uses this per default, but I think it is always a good idea to be explicit. In this case, the code reads the whole file, and for other file formats other than csv, you can tweak this with samplingRatio. There are many other options you can use here, and there’s a quite comprehensive documentation here. Be aware that inferring a schema based on a whole file isn’t what you want in all cases, especially if your file is too big. If you are aiming for speedy loads, then you should not using inferring schema, but define the targeted schema from the start. In this case, with relatively small amount of data of an AdventureWorks2022 sample data, I think this is a good showcase. By the way, with this you will also be able to get the schema pretty easy.
Another trick I am showcasing here is the possiblity to get the data that were malformed reads with a diff (line 84):
# Identify malformed records by diff it
df_mal = df_all.subtract(df_well)
Last thing I want to point out for today is the possiblity to write out statements in colors (line 154):
# Write the log DataFrame to the lakehouse log table in the meta_lakehouse database
if not df_log.filter(df_log["row_amount_diff"] > 0).rdd.isEmpty():
df_log.write.format("delta").mode("append").saveAsTable("meta_lakehouse.load_log_bronze")
print(f"\n\033[93m ALL CSV files LOADED with WARNING into meta_lakehouse.load_log_bronze table.\033[0m")
else:
print(f"\n\033[92m ALL CSV files SUCCESSFULLY LOADED into meta_lakehouse.load_log_bronze table.\033[0m")
The strange code within print(f” ) is a code for coloring text. The difference we see in the warning output and the success output is [93m (yellow) and [92m (green)
At the very end, there’s an output like this:

The last line hints that the next blog post will be about how to find the issues easily and how to fix them. Notebooks are great to instruct people on what to do, especially if they have links to the next notebook!
Do you have any improvements I could have made in my code? Or do you have a question you want to discuss? Even better, found any mistake? Let me know in the comments!
This post was first published on Fabric community blogs for data engineering. Credit: Cover image was created by DALL-E by Microsoft CoPilot.
Subscribe to my newsletter
Read articles from Kay Sauter directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Kay Sauter
Kay Sauter
Kay Sauter has been working with SQL Server since 2013. His expertise covers SQL Server, Azure, Data Visualization, and Power BI. He is a Microsoft Data Platform MVP. Kay blogs on kayondata.com and is actively involved in various community projects like Data TGIF, databash.live, data-conference.ch, and Data Platform Data Platform DEI Virtual Group. He is based in Zurich, Switzerland and in his free time, together with his wife, he loves to travel to discover new cultures and perspectives.