Step-by-Step Guide to Creating an LLM-Based App for Chatting with PapersWithCode
 Spheron Network
Spheron Network
Staying updated with the latest in machine learning (ML) research can feel overwhelming. With the steady stream of papers on large language models (LLMs), vector databases, and retrieval-augmented generati on (RAG) systems, it’s easy to fall behind. But what if you could access and query this vast research library using natural language? In this guide, we’ll create an AI-powered assistant that mines and retrieves information from Papers With Code (PWC), providing answers based on the latest ML papers.
Our app will use a RAG framework for backend processing, incorporating a vector database, VertexAI’s embedding model, and an OpenAI LLM. The frontend will be built on Streamlit, making it simple to deploy and interact with.
Step 1: Data Collection from Papers With Code
Papers With Code is a valuable resource that aggregates the latest ML papers, source code, and datasets. To automate data retrieval from this site, we’ll use the PWC API. This allows us to collect papers related to specific keywords or topics.
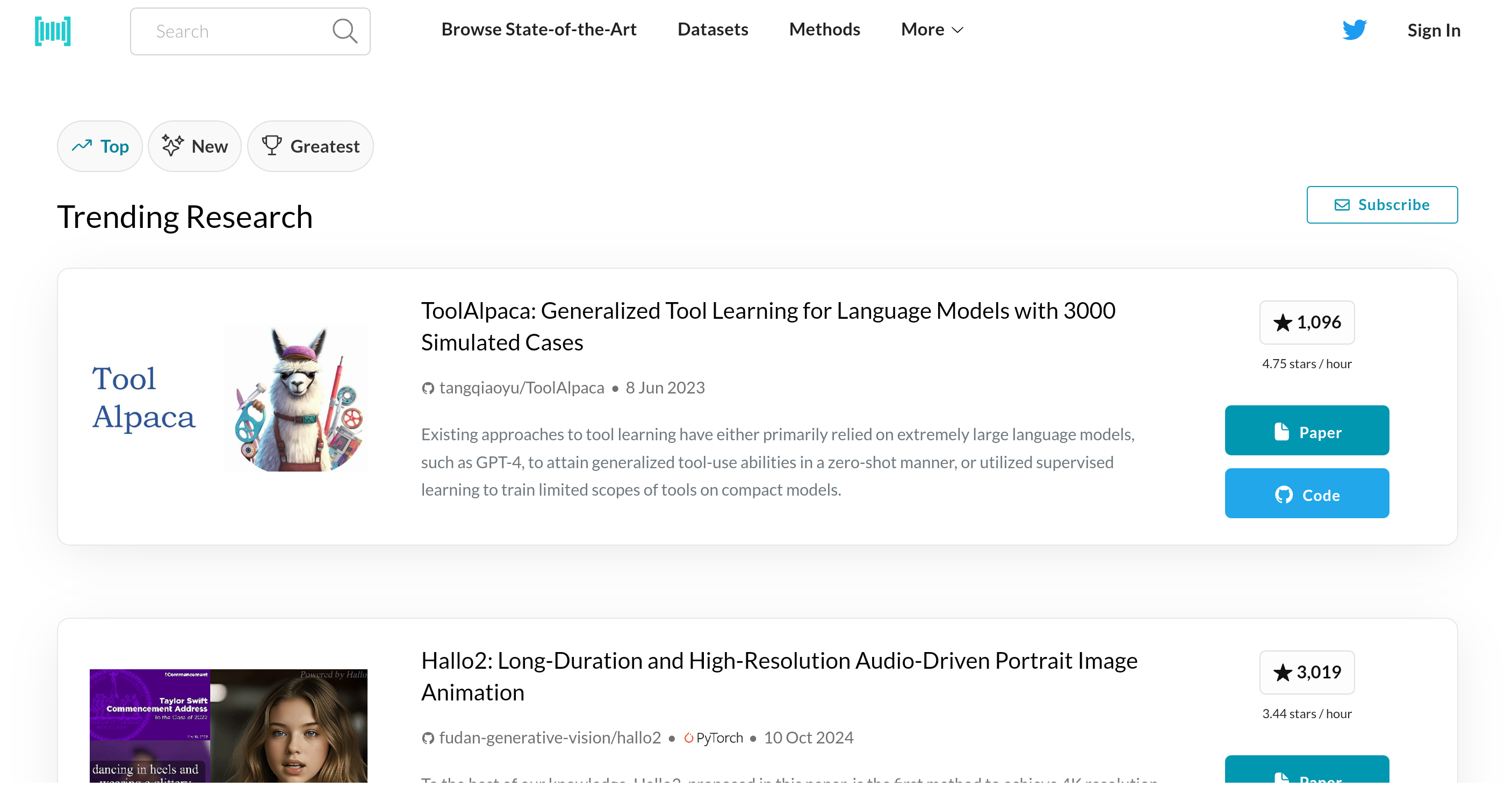
Retrieving Papers Using the API
To search for papers programmatically:
Access the PWC API Swagger UI and locate the
papers/endpoint.Use the
qparameter to enter keywords for the topic of interest.Execute the query to retrieve data.
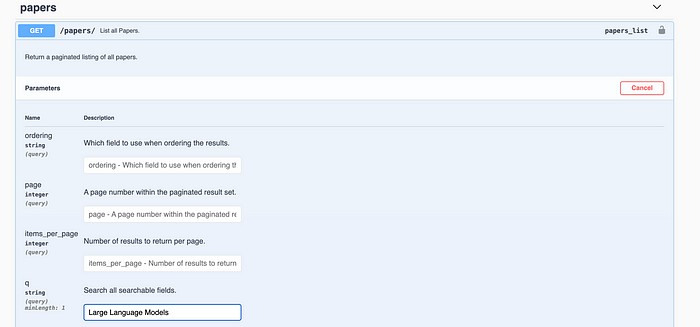
Each response includes the first set of results, with additional pages accessible via the next key. To retrieve multiple pages, you can set up a function that loops through all pages based on the initial result count. Here’s a Python script to automate this:
import requests
import urllib.parse
from tqdm import tqdm
def extract_papers(query: str):
query = urllib.parse.quote(query)
url = f"https://paperswithcode.com/api/v1/papers/?q={query}"
response = requests.get(url).json()
count = response["count"]
results = response["results"]
num_pages = count // 50
for page in tqdm(range(2, num_pages)):
url = f"https://paperswithcode.com/api/v1/papers/?page={page}&q={query}"
response = requests.get(url).json()
results.extend(response["results"])
return results
query = "Large Language Models"
results = extract_papers(query)
print(len(results)) # Expected output: 7200 (for example)
Formatting Results for LangChain Compatibility
Once extracted, convert the data to LangChain-compatible Document objects. Each document will contain:
page_content: stores the paper’s abstract.metadata: includes attributes likeid,arxiv_id,url_pdf,title,authors, andpublished.
from langchain.docstore.document import Document
documents = [
Document(
page_content=result["abstract"],
metadata={
"id": result.get("id", ""),
"arxiv_id": result.get("arxiv_id", ""),
"url_pdf": result.get("url_pdf", ""),
"title": result.get("title", ""),
"authors": result.get("authors", ""),
"published": result.get("published", "")
},
)
for result in results
]
Chunking for Efficient Retrieval
Since LLMs have token limitations, breaking down each document into chunks can improve retrieval and precision. Using LangChain’s RecursiveCharacterTextSplitter, set chunk_size to 1200 characters and chunk_overlap to 200. This will generate manageable text chunks for optimal LLM input.
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1200,
chunk_overlap=200,
separators=["."]
)
splits = text_splitter.split_documents(documents)
print(len(splits)) # Expected output: 11308 (for example)
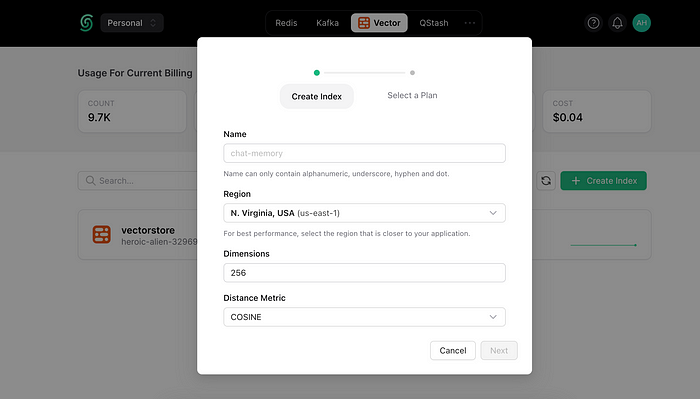
Step 2: Creating an Index with Upstash
To store embeddings and document metadata, set up an index in Upstash, a serverless database ideal for our project. After logging into Upstash, set your index parameters:
Region: closest to your location.
Dimensions: 768, matching VertexAI’s embedding dimension.
Distance Metric: cosine similarity.
Then, install the upstash-vector package:
pip install upstash-vector
Use the credentials generated by Upstash (URL and token) to connect to the index in your app.
from upstash_vector import Index
index = Index(
url="<UPSTASH_URL>",
token="<UPSTASH_TOKEN>"
)
Step 3: Embedding and Indexing Documents
To add documents to Upstash, we’ll create a class UpstashVectorStore which embeds document chunks and indexes them. This class will include methods to:
Add document embeddings in batches.
Perform similarity searches with scoring.
from typing import List, Optional, Tuple, Union
from uuid import uuid4
from langchain.docstore.document import Document
from langchain.embeddings.base import Embeddings
from tqdm import tqdm
from upstash_vector import Index
class UpstashVectorStore:
def __init__(self, index: Index, embeddings: Embeddings):
self.index = index
self.embeddings = embeddings
def add_documents(
self,
documents: List[Document],
batch_size: int = 32
):
texts, metadatas, all_ids = [], [], []
for document in tqdm(documents):
texts.append(document.page_content)
metadatas.append({"context": document.page_content, **document.metadata})
if len(texts) >= batch_size:
ids = [str(uuid4()) for _ in texts]
all_ids += ids
embeddings = self.embeddings.embed_documents(texts)
self.index.upsert(vectors=zip(ids, embeddings, metadatas))
texts, metadatas = [], []
if texts:
ids = [str(uuid4()) for _ in texts]
all_ids += ids
embeddings = self.embeddings.embed_documents(texts)
self.index.upsert(vectors=zip(ids, embeddings, metadatas))
print(f"Indexed {len(all_ids)} vectors.")
return all_ids
def similarity_search_with_score(
self, query: str, k: int = 4
) -> List[Tuple[Document, float]]:
query_embedding = self.embeddings.embed_query(query)
results = self.index.query(query_embedding, top_k=k, include_metadata=True)
return [(Document(page_content=metadata.pop("context"), metadata=metadata), score)
for metadata, score in results]
To execute this indexing:
from langchain.embeddings import VertexAIEmbeddings
embeddings = VertexAIEmbeddings(model_name="textembedding-gecko@003")
upstash_vector_store = UpstashVectorStore(index, embeddings)
ids = upstash_vector_store.add_documents(splits, batch_size=25)
Step 4: Querying Indexed Papers
With the abstracts indexed in Upstash, querying becomes straightforward. We’ll define functions to:
Retrieve relevant documents.
Build a prompt using these documents for LLM responses.
def get_context(query, vector_store):
results = vector_store.similarity_search_with_score(query)
return "\n===\n".join([doc.page_content for doc, _ in results])
def get_prompt(question, context):
template = """
Use the provided context to answer the question accurately.
%CONTEXT%
{context}
%Question%
{question}
Answer:
"""
return template.format(question=question, context=context)
For example, if you ask about the limitations of RAG frameworks:
query = "What are the limitations of the Retrieval Augmented Generation framework?"
context = get_context(query, upstash_vector_store)
prompt = get_prompt(query, context)
Step 5: Building the Application with Streamlit
To make our app user-friendly, we’ll use Streamlit for a simple, interactive UI. Streamlit makes it easy to deploy ML-powered web apps with minimal code.
import streamlit as st
from langchain.chat_models import AzureChatOpenAI
# Streamlit Setup
st.title("Chat with ML Research Papers")
query = st.text_input("Ask a question about ML research:")
if st.button("Submit"):
if query:
context = get_context(query, upstash_vector_store)
prompt = get_prompt(query, context)
llm = AzureChatOpenAI(model_name="<MODEL_NAME>")
answer = llm.predict(prompt)
st.write(answer)
Benefits and Limitations of Retrieval-Augmented Generation (RAG)

RAG systems offer unique advantages, especially for ML researchers:
Access to Up-to-Date Information: RAG lets you pull information from the latest sources.
Enhanced Trust: Answers grounded in source documents make results more reliable.
Easy Setup: RAGs are relatively straightforward to implement without needing extensive computing resources.
However, RAG isn’t perfect:
Data Dependence: RAG accuracy hinges on the data fed into it.
Not Always Optimal for Complex Queries: While fine for demos, real-world applications may need extensive tuning.
Limited Context: RAG systems are still limited by the LLM’s context size.
Conclusion
Building a conversational assistant for machine learning research using LLMs and RAG frameworks is achievable with the right tools. By using Papers With Code data, Upstash for vector storage, and Streamlit
for a user interface, you can create a robust application for querying recent research.
Further Exploration Ideas:
Use the full paper text rather than just abstracts.
Experiment with metadata filtering to improve precision.
Explore hybrid retrieval techniques and re-ranking for more relevant results.
Whether you’re an ML enthusiast or a researcher, this approach to interacting with research papers can save time and streamline the learning process.
Subscribe to my newsletter
Read articles from Spheron Network directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Spheron Network
Spheron Network
On-demand DePIN for GPU Compute