Certified Kubernetes Administrator (CKA) - Phần 8: Networking
 Phan Văn Hoàng
Phan Văn HoàngSwitching Routing

Chúng ta kết nối chúng với một switch, và switch sẽ tạo ra một mạng chứa hai hệ thống này. Để kết nối chúng với switch, mỗi máy cần có một giao diện mạng (interface): có thể là vật lý hoặc ảo, tùy thuộc vào loại máy chủ.
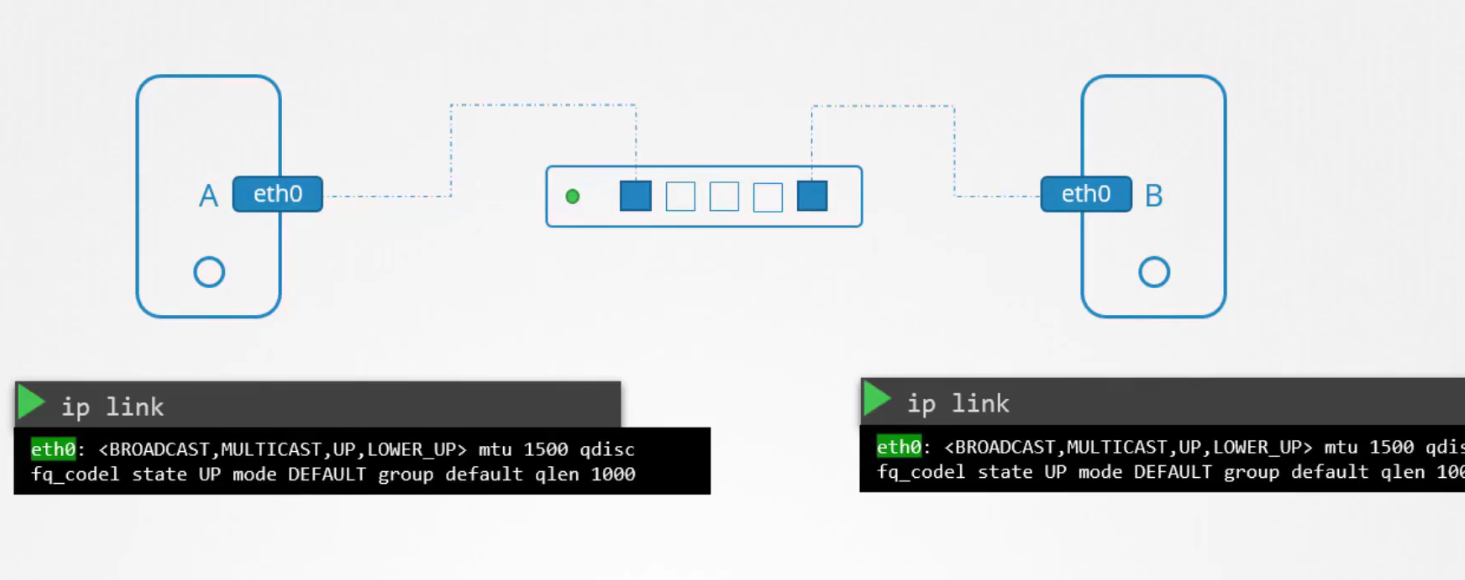
Để xem các giao diện mạng (interfaces) của máy chủ, chúng ta sử dụng lệnh ip link. Trong trường hợp này, chúng ta sẽ kiểm tra interface có tên eth0, interface này sẽ được sử dụng để kết nối với switch. Giả sử đây là một mạng có địa chỉ 192.168.1.0.
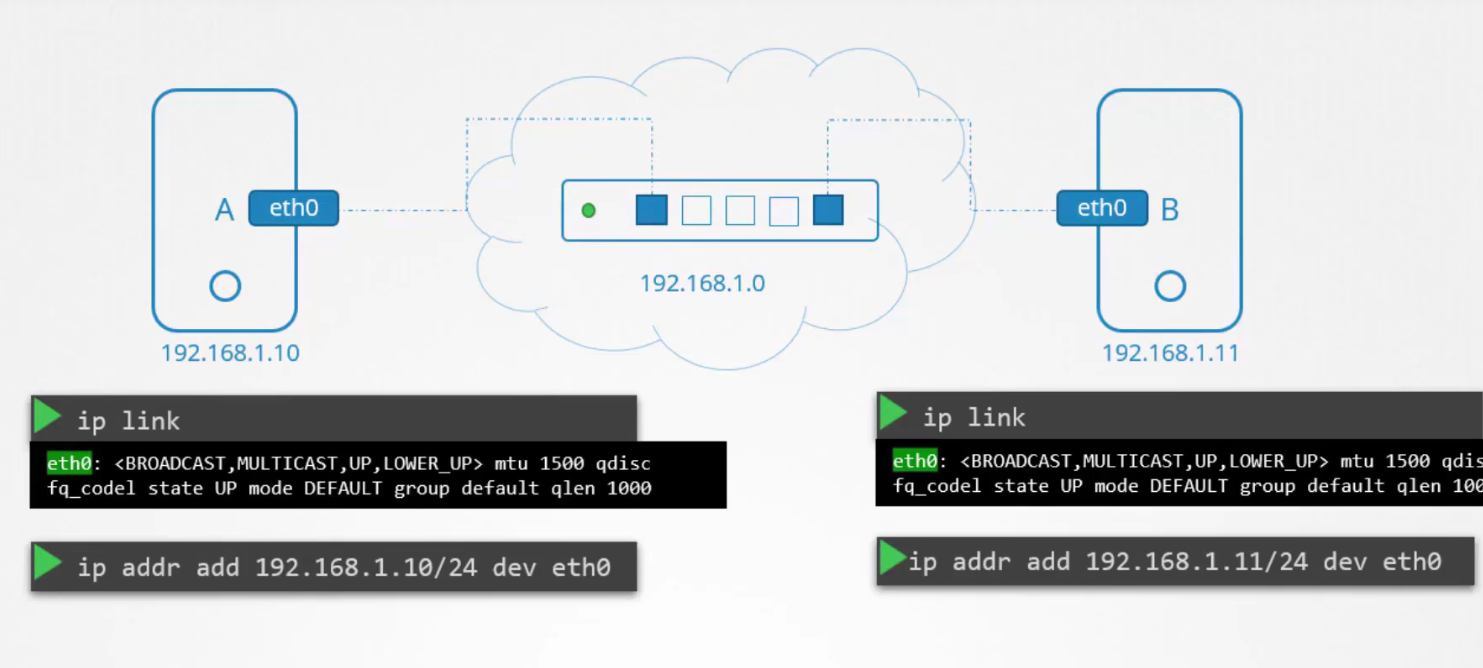
Sau đó, chúng ta gán địa chỉ IP cho các hệ thống trong cùng một mạng. Khi các liên kết đã được thiết lập và các địa chỉ IP đã được gán, các máy tính có thể giao tiếp với nhau thông qua switch. Switch chỉ cho phép giao tiếp trong cùng một mạng, nghĩa là nó có thể nhận các gói tin từ một máy trong mạng và chuyển chúng đến các hệ thống khác trong cùng mạng đó.
Giả sử chúng ta có một mạng khác chứa các hệ thống C và D với địa chỉ mạng 192.168.2.0. Các hệ thống này có địa chỉ IP lần lượt là 192.168.2.10 và 192.168.2.11.

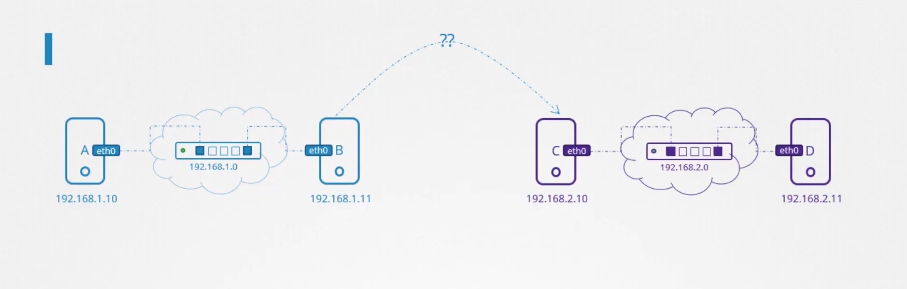
Đây chính là lúc router phát huy vai trò. Router giúp kết nối hai mạng lại với nhau. Nó là một thiết bị thông minh, vì vậy bạn có thể nghĩ về nó như một máy chủ khác với nhiều cổng mạng. Vì nó kết nối hai mạng riêng biệt, router sẽ nhận hai địa chỉ IP, mỗi địa chỉ thuộc về một mạng.
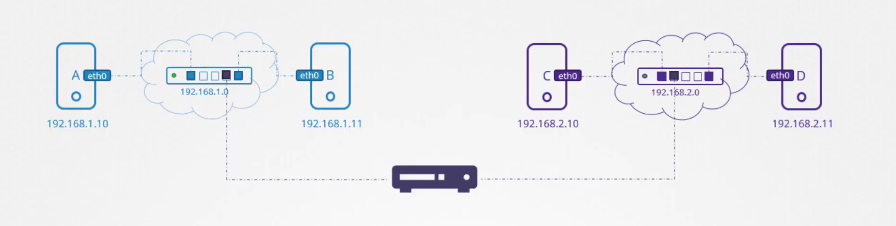
Trong mạng đầu tiên, chúng ta gán cho router một địa chỉ IP là 192.168.1.1. Trong mạng thứ hai, chúng ta gán cho router một địa chỉ IP là 192.168.2.1. Như vậy, router kết nối với hai mạng và có thể cho phép giao tiếp giữa chúng.
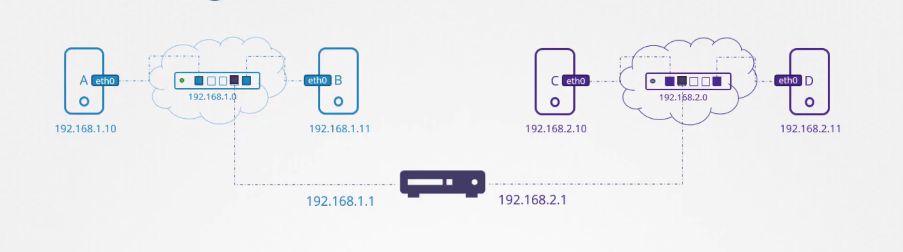
Khi hệ thống B cố gắng gửi một gói tin đến hệ thống C, làm sao hệ thống B biết router ở đâu trên mạng để gửi gói tin qua? Router chỉ là một thiết bị khác trên mạng. Có thể có nhiều thiết bị tương tự. Đây là lúc chúng ta cấu hình các hệ thống với gateway hoặc route.
Nếu mạng là một căn phòng, gateway là cánh cửa ra ngoài thế giới, đến các mạng khác hoặc ra Internet. Các hệ thống cần biết cửa đó ở đâu để có thể đi qua. Để xem cấu hình định tuyến hiện tại trên một hệ thống, ta sử dụng lệnh:
$ route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
Để cấu hình gateway trên hệ thống B để có thể kết nối đến các hệ thống trong mạng 192.168.2.0, sử dụng lệnh:
$ ip route add 192.168.2.0/24 via 192.168.1.1
$ route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
192.168.2.0 192.168.1.1 255.255.255.0 UG 0 0 0 eth0
Nếu hệ thống C muốn gửi một gói tin đến hệ thống B, thì bạn cần thêm một route:
$ ip route add 192.168.1.0/24 via 192.168.2.1
$ route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
192.168.1.0 192.168.2.1 255.255.255.0 UG 0 0 0 eth0
Bây giờ, giả sử các hệ thống này cần truy cập Internet. Ví dụ, chúng cần kết nối đến Google tại mạng 172.217.194.0 trên Internet. Khi đó, bạn kết nối router của mình với Internet và thêm một route mới vào bảng định tuyến để chuyển toàn bộ lưu lượng đến mạng 172.217.194.0 thông qua router của bạn.
$ ip route add 172.217.194.0/24 via 192.168.2.1
$ route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
192.168.1.0 192.168.2.1 255.255.255.0 UG 0 0 0 eth0
172.217.194.0 192.168.2.1 255.255.255.0 UG 0 0 0 eth0
Có rất nhiều trang web nằm trên các mạng khác nhau trên Internet. Thay vì thêm một mục vào bảng định tuyến cho từng mạng với cùng địa chỉ IP của router, bạn có thể cấu hình một cách đơn giản hơn: chỉ định rằng đối với bất kỳ mạng nào mà hệ thống không biết route, hãy sử dụng router này làm default gateway.
$ ip route add default via 192.168.2.1
$ route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
192.168.1.0 192.168.2.1 255.255.255.0 UG 0 0 0 eth0
172.217.194.0 192.168.2.1 255.255.255.0 UG 0 0 0 eth0
default 192.168.2.1 255.255.255.0 UG 0 0 0 eth0
0.0.0.0 192.168.2.1 255.255.255.0 UG 0 0 0 eth0
Bằng cách này, mọi yêu cầu đến bất kỳ mạng nào nằm ngoài mạng hiện tại của bạn sẽ được chuyển đến router này. Trong một cấu hình đơn giản như vậy, tất cả những gì bạn cần là một mục trong bảng định tuyến với default gateway được đặt thành địa chỉ IP của router.
Nhưng giả sử bạn có nhiều router trong mạng của mình: một router để kết nối Internet và một router khác cho mạng nội bộ riêng tư. Khi đó, bạn sẽ cần có hai mục riêng biệt trong bảng định tuyến: một mục dành cho mạng nội bộ riêng tư và một mục khác với default gateway cho tất cả các mạng khác, bao gồm cả mạng công cộng.
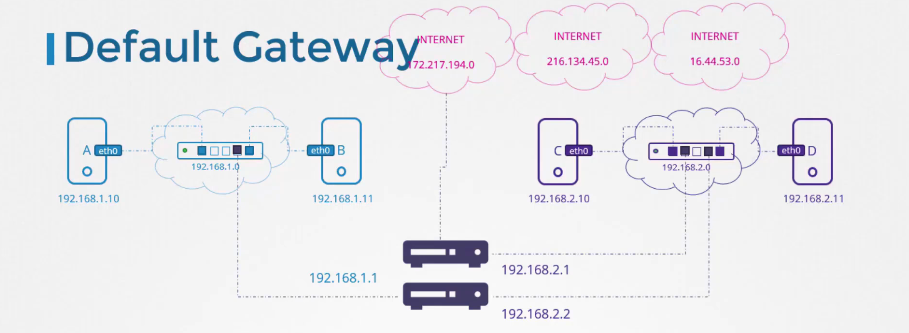
Vì vậy, nếu bạn gặp vấn đề khi kết nối Internet từ các hệ thống của mình, thì bảng định tuyến và cấu hình default gateway là nơi tốt để bắt đầu kiểm tra.
Tôi có ba máy chủ, A, B và C. A và B được kết nối với một mạng 192.168.1.0, trong khi B và C được kết nối với một mạng khác 192.168.2.0.
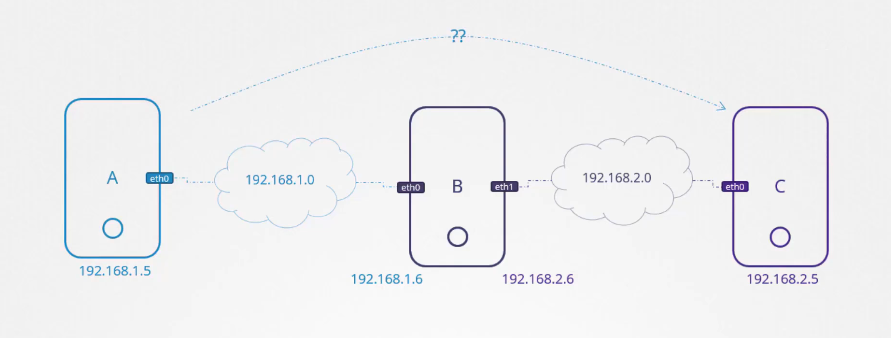
Làm thế nào để chúng ta làm cho A có thể giao tiếp với C? Cơ bản là, nếu tôi thử ping 2.5 từ A, nó sẽ báo "network is unreachable".
Máy chủ A không biết cách để đến được mạng 192.168.2. Chúng ta cần thông báo cho máy chủ A rằng cổng (gateway) để đến mạng thứ hai là qua máy chủ B.
$ ip route add 192.168.2.0/24 via 192.168.1.6
Nếu các gói tin cần phải đi qua đến máy chủ C, thì máy chủ C sẽ phải gửi lại phản hồi cho máy chủ A. Khi máy chủ C cố gắng kết nối với máy chủ A trên mạng 192.168.1, nó sẽ gặp phải vấn đề tương tự. Vì vậy, chúng ta cần thông báo cho máy chủ C rằng nó có thể đến máy chủ A qua máy chủ B, máy chủ B đang hoạt động như một router.
$ ip route add 192.168.1.0/24 via 192.168.2.6
Khi chúng ta thử ping bây giờ, không còn nhận được thông báo lỗi "network unreachable" nữa. Điều này có nghĩa là các mục định tuyến của chúng ta đã chính xác. Tuy nhiên, chúng ta vẫn không nhận được phản hồi.
Theo mặc định, trong Linux, các gói tin không được chuyển tiếp từ interface này sang interface khác. Các gói tin nhận được trên Eth0 của máy chủ B không được chuyển tiếp sang interface khác thông qua Eth1. Điều này được thiết lập như vậy vì lý do bảo mật.
Ví dụ:
Nếu bạn có Eth0 kết nối với mạng nội bộ và Eth1 kết nối với mạng công cộng, chúng ta không muốn ai đó từ mạng công cộng có thể dễ dàng gửi tin nhắn tới mạng nội bộ trừ khi bạn cho phép rõ ràng điều đó. Nhưng trong trường hợp này, vì chúng ta biết rằng cả hai đều là mạng riêng và việc cho phép giao tiếp giữa chúng là an toàn, chúng ta có thể cho phép máy chủ B chuyển tiếp các gói tin từ mạng này sang mạng kia.
Việc một máy chủ có thể chuyển tiếp các gói tin giữa các giao diện hay không được quản lý bởi một cài đặt trong hệ thống này.
$ cat /proc/sys/net/ipv4/
0
Mặc định, giá trị trong tệp này được thiết lập là 0, có nghĩa là không có việc chuyển tiếp. Hãy thay đổi giá trị này thành 1, và bạn sẽ thấy các gói ping có thể đi qua.
DNS
Chúng ta có hai máy tính, A và B, đều thuộc cùng một mạng, và chúng đã được gán các địa chỉ IP 192.168.1.10 và 192.168.1.11.
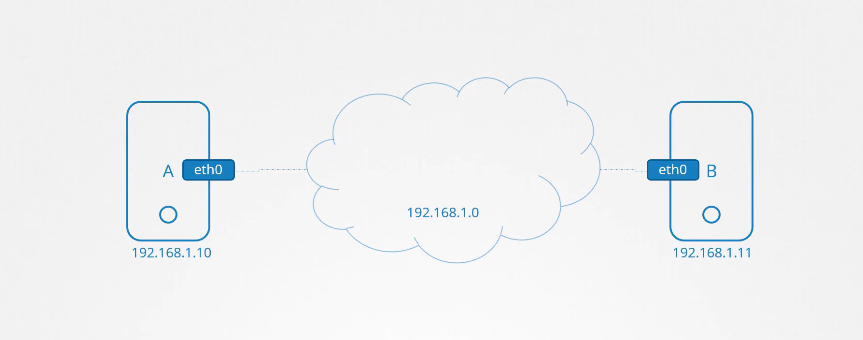
Bạn có thể ping một máy tính từ máy tính kia bằng cách sử dụng địa chỉ IP của máy tính còn lại.
$ ping 192.168.1.11
Reply from 192.168.1.11: bytes=32 time=4ms TTL=117
Reply from 192.168.1.11: bytes=32 time=4ms TTL=117
Bạn biết rằng hệ thống B có các dịch vụ cơ sở dữ liệu. Vì vậy, thay vì phải nhớ địa chỉ IP của hệ thống B, bạn quyết định đặt tên cho nó là db. Bạn muốn ping hệ thống B bằng tên db thay vì sử dụng địa chỉ IP của nó.
$ ping db
ping: unknown host db
Cơ bản, bạn muốn thông báo cho hệ thống A rằng hệ thống B với địa chỉ IP 192.168.1.11 có tên là db. Bạn muốn hệ thống A hiểu rằng khi bạn nói db, bạn đang ám chỉ địa chỉ IP 192.168.1.11. Bạn có thể làm điều đó bằng cách thêm một mục nhập vào:
$ cat >> /etc/hosts
192.168.1.11 db
Kể từ bây giờ, các lệnh ping đến db sẽ được gửi đến địa chỉ IP chính xác.
$ ping db
PING db (192.168.1.11) 56(84) bytes of data.
64 bytes from db (192.168.1.11): icmp_seq=1 ttl=64 time=0.052 ms
64 bytes from db (192.168.1.11): icmp_seq=2 ttl=64 time=0.079 ms
Chúng ta đã thông báo cho hệ thống A rằng địa chỉ IP 192.168.1.11 là của một máy chủ có tên là db. Hệ thống A coi đó là sự thật. Bất kỳ thông tin nào được đặt trong tệp /etc/hosts là nguồn thông tin chính xác đối với hệ thống A, nhưng điều đó có thể không phải là sự thật. Hệ thống A không kiểm tra để đảm bảo rằng tên thực sự của hệ thống B là db.
Quá trình chuyển đổi tên máy chủ (hostname) thành địa chỉ IP theo cách này được gọi là phân giải tên (name resolution).
Trong một mạng nhỏ với vài hệ thống, bạn có thể dễ dàng sử dụng các mục nhập trong tệp /etc/hosts. Trên mỗi hệ thống, tôi chỉ định các hệ thống khác trong môi trường, và đó là cách mà việc này được thực hiện trong quá khứ.
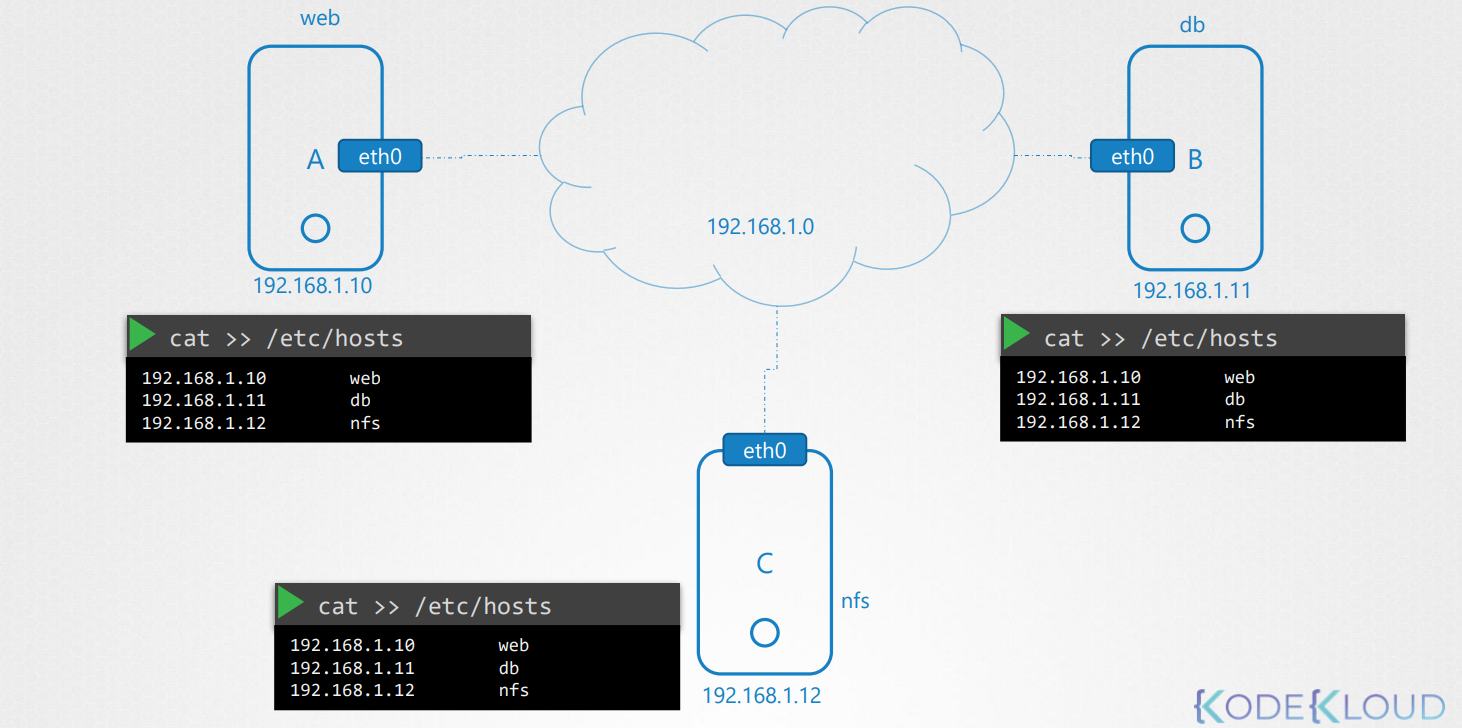
Cho đến khi môi trường phát triển và các tệp này bị đầy với quá nhiều mục nhập, việc quản lý chúng trở nên rất khó khăn. Nếu một trong các máy chủ thay đổi địa chỉ IP, bạn sẽ cần phải chỉnh sửa các mục nhập trên tất cả các máy chủ này.
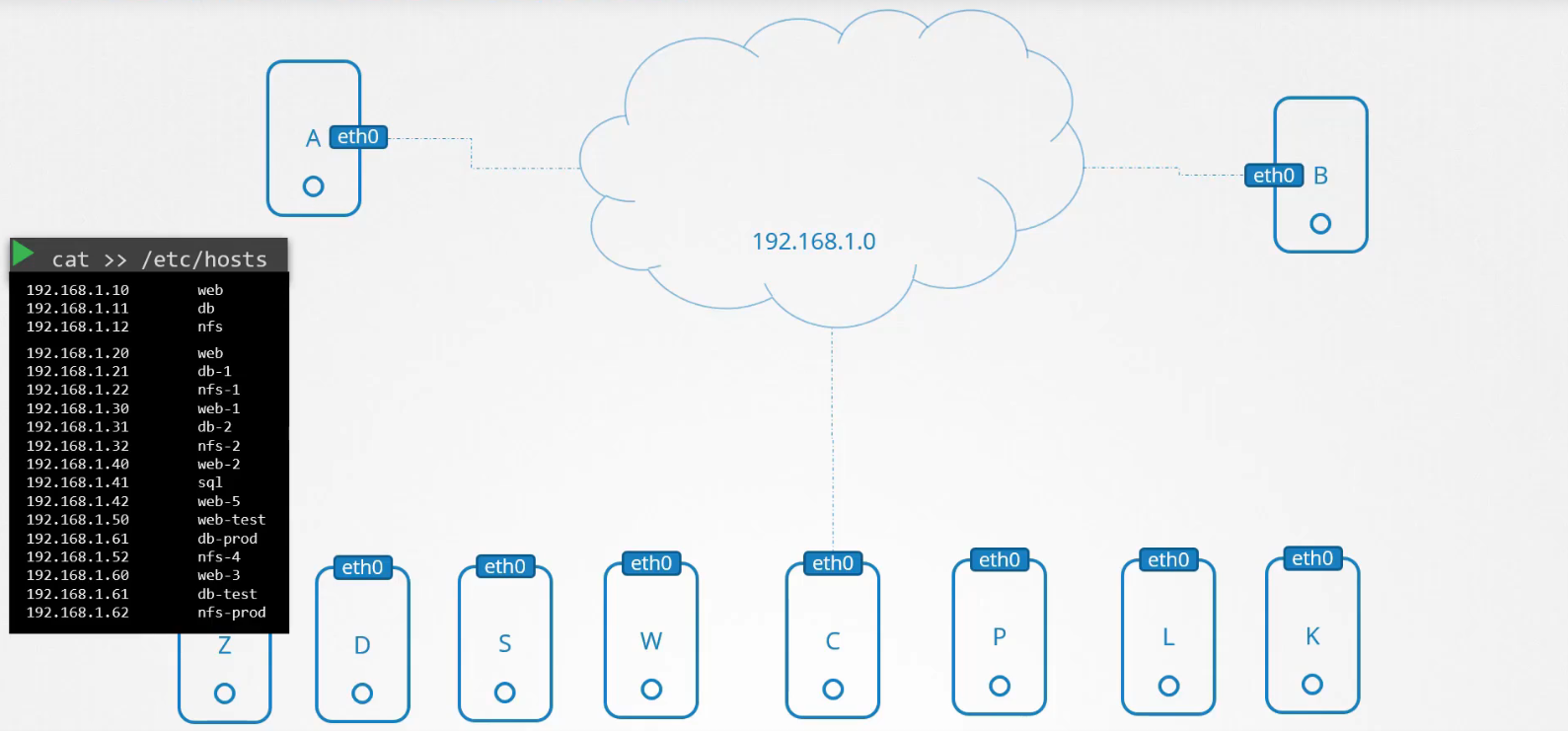
Và đó là lý do chúng ta quyết định chuyển tất cả các mục nhập này vào một máy chủ duy nhất. Máy chủ sẽ quản lý việc này một cách tập trung. Chúng ta gọi đó là máy chủ DNS. Sau đó, chúng ta chỉ định tất cả các máy chủ hướng đến việc tra cứu máy chủ đó nếu chúng cần phân giải tên máy chủ thành địa chỉ IP thay vì sử dụng các tệp /etc/hosts của chính mình.
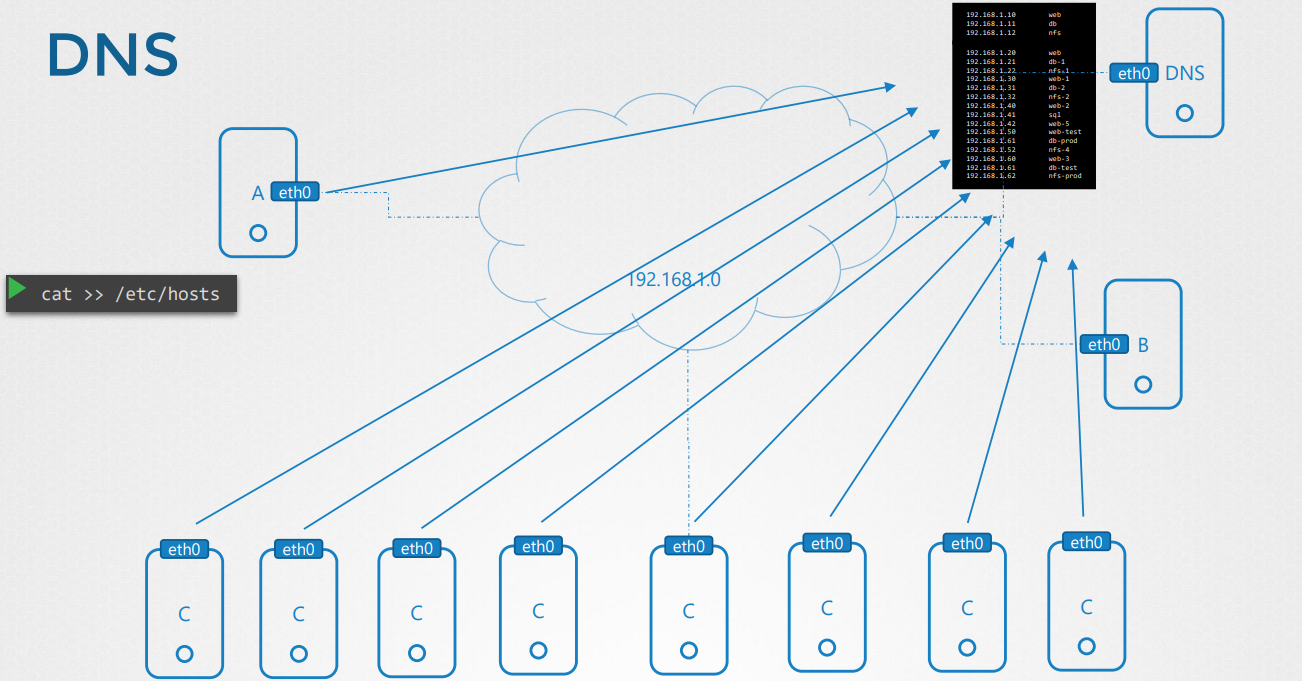
Máy chủ DNS của chúng ta có địa chỉ IP là 192.168.1.100. Mỗi hệ thống đều có một tệp cấu hình phân giải DNS tại /etc/resolv.conf. Bạn thêm một mục vào tệp này để chỉ định địa chỉ của máy chủ DNS.
$ cat /etc/resolv.conf
nameserver 192.168.1.100
Khi cấu hình này được thiết lập trên tất cả các máy chủ, mỗi khi một máy chủ gặp phải một tên máy chủ mà nó không biết, nó sẽ tra cứu tên đó từ máy chủ DNS.
Giả sử bạn muốn cung cấp một máy chủ thử nghiệm cho nhu cầu của riêng bạn. Bạn không nghĩ rằng những người khác cần phải phân giải máy chủ này bằng tên của nó, vì vậy nó có thể không được thêm vào máy chủ DNS.
$ cat >> /etc/hosts
192.168.1.115 test
Trong trường hợp này, bạn có thể thêm một mục vào tệp /etc/hosts của máy chủ của mình để phân giải máy chủ này. Bạn giờ đây có thể phân giải máy chủ đó. Tuy nhiên, không hệ thống nào khác sẽ có thể làm được điều đó.
Nếu bạn có một mục trong cả hai vị trí, một trong tệp /etc/hosts và một trong DNS, hệ thống sẽ ưu tiên sử dụng tệp /etc/hosts trước. Điều này có nghĩa là khi hệ thống cần phân giải tên máy chủ, nó sẽ kiểm tra tệp /etc/hosts trước, và nếu tìm thấy mục khớp, nó sẽ sử dụng thông tin đó mà không thực hiện tìm kiếm qua DNS. Nếu không tìm thấy mục trong /etc/hosts, hệ thống sẽ tiếp tục tìm kiếm trong DNS.
Ví dụ**:**
Tôi thử ping www.facebook.com, tôi không có facebook.com trong tệp /etc/hosts và cũng không có nó trong máy chủ DNS của mình. Vậy trong trường hợp đó, nó sẽ thất bại.
$ ping www.facebook.com
ping: www.facebook.com: Temporary failure in name resolution
Bạn có thể thêm một mục khác vào tệp resolv.conf của mình để trỏ đến một máy chủ tên (name server) biết về Facebook.
$ cat >> /etc/resolv.conf
nameserver 192.168.1.100
nameserver 8.8.8.8
8.8.8.8 là một máy chủ tên công cộng nổi tiếng do Google cung cấp trên internet, biết về tất cả các trang web trên internet. Bạn có thể cấu hình nhiều máy chủ tên như vậy trên máy chủ của mình, nhưng bạn sẽ phải cấu hình điều đó trên tất cả các máy chủ trong mạng của bạn.
$ ping www.facebook.com
PING star-mini.c10r.facebook.com (157.240.13.35) 56(84) bytes of data.
64 bytes from edge-star-mini-shv-02-sin6.facebook.com (157.240.13.35):
icmp_seq=1 ttl=50 time=5.70 ms
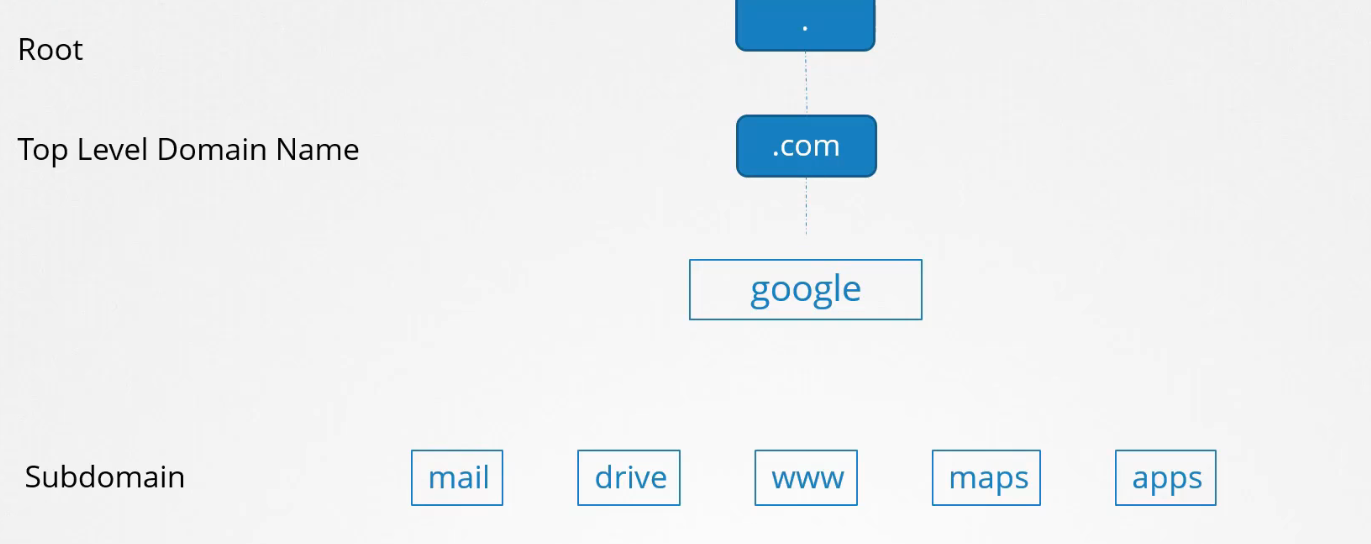
Chúng ta vừa thử ping Facebook tại www.facebook.com. Tên này là gì? Với một "www" và phần mở rộng ".com" ở cuối, nó được gọi là tên miền.

Và đây là cách các địa chỉ IP chuyển thành các tên mà chúng ta có thể nhớ trên internet công cộng, giống như cách chúng ta đã làm với các máy chủ của mình.
Bây giờ, lý do chúng xuất hiện dưới dạng này, cách nhau bằng dấu chấm, là để nhóm các thành phần tương tự lại với nhau. Phần cuối cùng của tên miền như .com, .net v.v.,

Trong trường hợp Google:
Chúng ta đã giới thiệu thêm các tên miền chuẩn như web.mycompany.com, db.mycompany.com, v.v.
192.168.1.10 web.mycompany.com
192.168.1.11 db.mycompany.com
192.168.1.12 nfs.mycompany.com
192.168.1.13 web-1.mycompany.com
192.168.1.14 sql.mycompany.com
Bây giờ, khi bạn thử ping web, bạn sẽ không nhận được phản hồi. Dĩ nhiên, lý do là chúng ta đang cố gắng ping "web", nhưng không có bản ghi nào với tên "web" trên máy chủ DNS của tôi. Thay vào đó, đó là "web.mycompany.com". Vì vậy, bạn cần sử dụng "web.mycompany.com".
$ ping web
ping: web: Temporary failure in name resolution
$ ping web.mycompany.com
PING web.mycompany.com (192.168.1.10) 56(84) bytes of data.
64 bytes from web.mycompany.com (192.168.1.10): ttl=64 time=0.052 ms
Bây giờ tôi có thể hiểu rằng nếu ai đó ngoài công ty chúng ta muốn truy cập vào máy chủ web của chúng ta, họ sẽ phải sử dụng "web.mycompany.com", nhưng trong công ty của chúng ta, bạn muốn chỉ đơn giản gọi máy chủ web bằng tên gọi đầu tiên "web", giống như cách bạn gọi những thành viên trong gia đình chỉ bằng tên gọi đầu tiên của họ.
$ cat >> /etc/resolv.conf
nameserver 192.168.1.100
search mycompany.com
Docker Networking
Khi bạn chạy một container, bạn có các tùy chọn mạng khác nhau để lựa chọn.
Đầu tiên, hãy xem mạng "none". Với mạng "none", container Docker không được kết nối với bất kỳ mạng nào. Container không thể truy cập vào thế giới bên ngoài và không ai từ bên ngoài có thể truy cập vào container. Nếu bạn có nhiều container, chúng sẽ được tạo ra mà không thuộc bất kỳ mạng nào và không thể giao tiếp với nhau hoặc với thế giới bên ngoài.
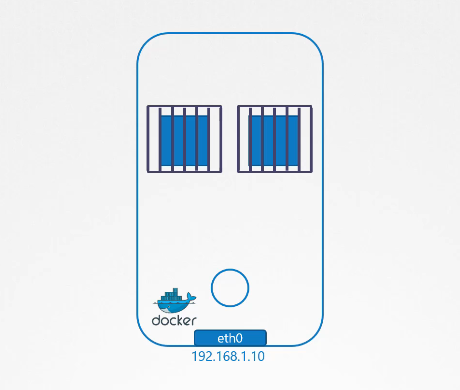
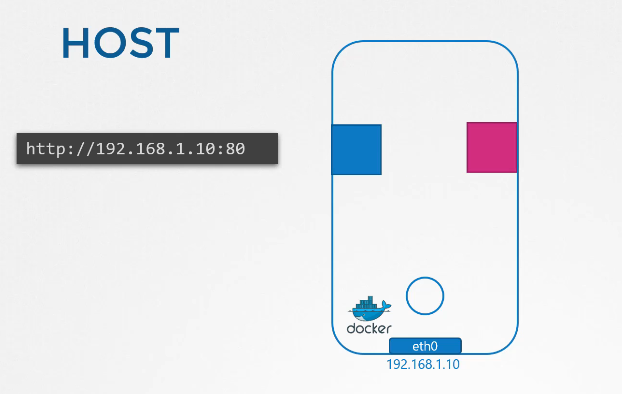
Tiếp theo là mạng "host". Với mạng "host", container được kết nối trực tiếp với mạng của host. Không có sự phân tách mạng giữa host và container. Nếu bạn triển khai một ứng dụng web nghe trên cổng 80 trong container, thì ứng dụng web sẽ có sẵn trên cổng 80 của host mà không cần thực hiện thêm bất kỳ ánh xạ cổng nào. Nếu bạn thử chạy một phiên bản khác của container cùng loại nghe trên cùng một cổng, điều đó sẽ không hoạt động vì chúng chia sẻ mạng của host, và hai tiến trình không thể nghe trên cùng một cổng cùng lúc.
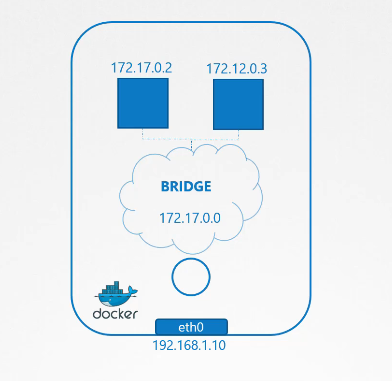
Tùy chọn mạng thứ ba là "bridge". Trong trường hợp này, một mạng riêng tư nội bộ được tạo ra mà host Docker và các container sẽ kết nối vào. Mạng này mặc định có địa chỉ 172.17.0.0, và mỗi thiết bị kết nối vào mạng này sẽ nhận được một địa chỉ mạng riêng tư nội bộ trên mạng đó.
Khi Docker được cài đặt trên host, nó tạo ra một mạng riêng tư nội bộ gọi là "Bridge" theo mặc định. Bạn có thể thấy điều này khi sử dụng lệnh:
$ docker network ls
NETWORK ID NAME DRIVER SCOPE
2b60087261b2 bridge bridge local
0beb4870b093 host host local
99035e02694f none null local
Bây giờ, Docker gọi mạng này là "Bridge", nhưng trên host, mạng này được tạo ra với tên "docker0". Bạn có thể thấy điều này trong kết quả của lệnh:
$ ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN
mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc
fq_codel state UP mode DEFAULT group default qlen 1000
link/ether 02:42:ac:11:00:08 brd ff:ff:ff:ff:ff:ff
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc
noqueue state DOWN mode DEFAULT group default
link/ether 02:42:88:56:50:83 brd ff:ff:ff:ff:ff:ff
Bây giờ, nhớ lại rằng chúng ta đã nói rằng mạng bridge giống như một giao diện của host nhưng lại như một switch đối với các namespace hoặc container trong host. Vì vậy, giao diện Docker0 trên host được gán một địa chỉ IP là 172.17.0.1.
$ ip addr
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc
noqueue state DOWN group default
link/ether 02:42:88:56:50:83 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/24 brd 172.17.0.255 scope global docker0
valid_lft forever preferred_lft forever
Mỗi khi một container được tạo ra, Docker tạo ra một network namespace cho nó.
$ ip netns
b3165c10a92b
Nếu bạn chạy lệnh IP link trên máy chủ Docker, bạn sẽ thấy một đầu của giao diện được kết nối với bridge nội bộ, Docker0.
$ ip link
4: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500
qdisc noqueue state UP mode DEFAULT group default
link/ether 02:42:9b:5f:d6:21 brd ff:ff:ff:ff:ff:ff
8: vethbb1c343@if7: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500
qdisc noqueue master docker0 state UP mode DEFAULT group default
link/ether 9e:71:37:83:9f:50 brd ff:ff:ff:ff:ff:ff link-netnsid
Nếu bạn chạy lại cùng lệnh đó, lần này với tùy chọn -n kèm theo tên namespace, lệnh sẽ liệt kê đầu còn lại của giao diện trong namespace của container.
$ ip -n b3165c10a92b link
...
9: eth0@if10: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500
qdisc noqueue state UP mode DEFAULT group default
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff link-netnsid 0
Giao diện này cũng sẽ được gán một địa chỉ IP trong mạng. Bạn có thể xem địa chỉ này bằng cách chạy lệnh ip addr, nhưng trong namespace của container. Container sẽ được gán địa chỉ 172.17.0.3. Bạn cũng có thể xem địa chỉ này bằng cách gắn kết vào container và kiểm tra địa chỉ IP được gán cho nó theo cách đó.
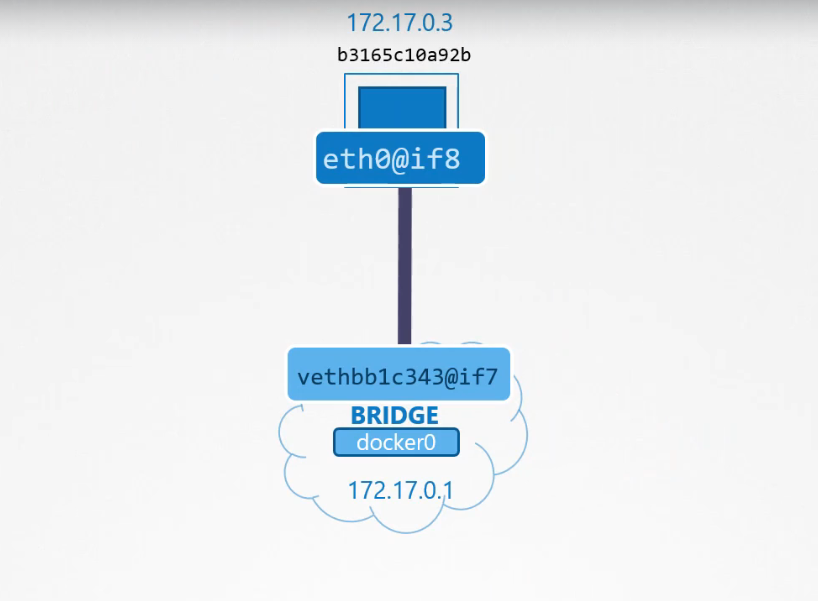
Mỗi lần một container mới được tạo ra, Docker sẽ tạo một namespace, tạo một cặp giao diện và gắn một đầu vào container, một đầu vào mạng bridge. Các cặp giao diện có thể được xác định thông qua các số của chúng. Các số lẻ và số chẵn tạo thành một cặp.
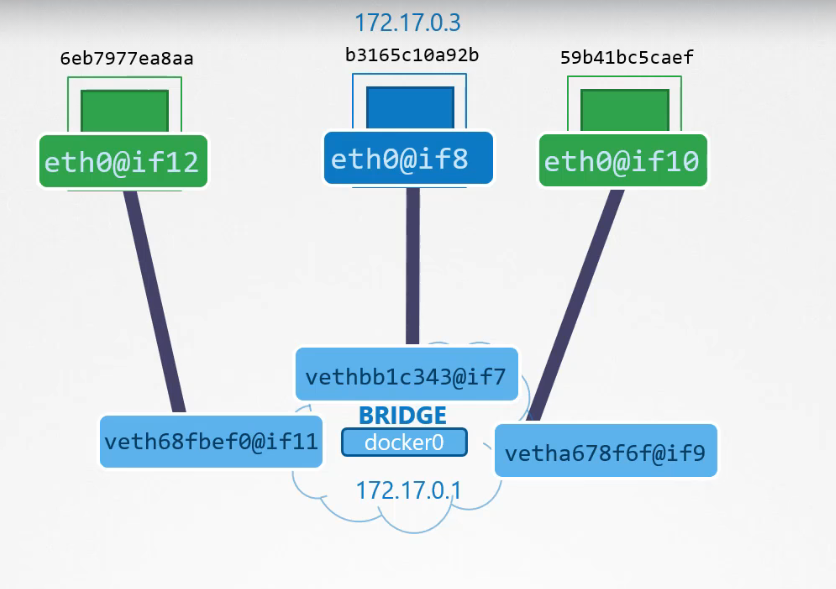
Các container hiện tại đã là một phần của mạng và chúng có thể giao tiếp với nhau. Bây giờ chúng ta sẽ xem xét việc ánh xạ cổng. Container mà chúng ta tạo ra là Nginx, vì vậy nó là một ứng dụng web phục vụ trang web trên cổng 80. Vì container của chúng ta nằm trong một mạng riêng bên trong máy chủ, chỉ những container khác trong cùng một mạng hoặc chính máy chủ mới có thể truy cập trang web này.
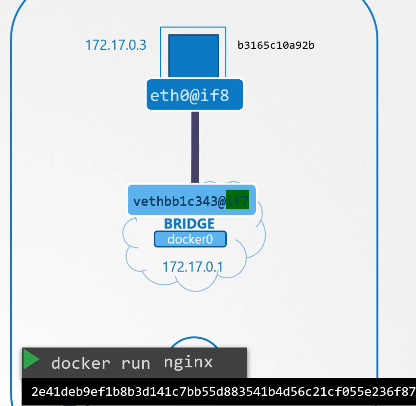
Nếu bạn thử truy cập trang web bằng cách sử dụng lệnh curl với địa chỉ IP của container từ bên trong máy chủ Docker trên cổng 80, bạn sẽ thấy trang web.
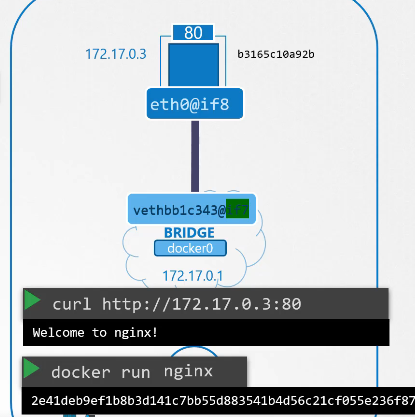
Nếu bạn thử làm điều tương tự từ bên ngoài máy chủ, bạn sẽ không thể xem trang web.
$ curl http://172.17.0.3:80
curl: (7) Failed to connect... No route to host
Để cho phép người dùng bên ngoài truy cập các ứng dụng được lưu trữ trên các container, Docker cung cấp tùy chọn xuất bản cổng (port publishing) hoặc ánh xạ cổng (port mapping). Khi bạn chạy các container, bạn yêu cầu Docker ánh xạ cổng 8080 trên máy chủ Docker với cổng 80 trên container.
$ docker run -p 8080:80 nginx
2e41deb9ef1b8b3d141c7bb55d883541b4d56c21cf055e236f870bd0f274e52b
Sau khi thực hiện điều này, bạn có thể truy cập ứng dụng web bằng cách sử dụng địa chỉ IP của máy chủ Docker và cổng 8080.
Bất kỳ lưu lượng truy cập nào tới cổng 8080 trên máy chủ Docker sẽ được chuyển tiếp đến cổng 80 trên container. Bây giờ, tất cả người dùng bên ngoài và các ứng dụng hoặc máy chủ khác có thể sử dụng URL này để truy cập ứng dụng đã được triển khai trên máy chủ.
$ curl http://192.168.1.10:8080
Welcome to nginx!
Cluster Networking
Mỗi node phải có ít nhất một interface được kết nối với một mạng. Mỗi interface phải được cấu hình một địa chỉ. Các máy chủ phải có một tên máy chủ (hostname) duy nhất và một địa chỉ MAC duy nhất. Bạn cần lưu ý điều này, đặc biệt nếu bạn đã tạo các máy ảo (VMs) bằng cách nhân bản từ các máy ảo hiện có.
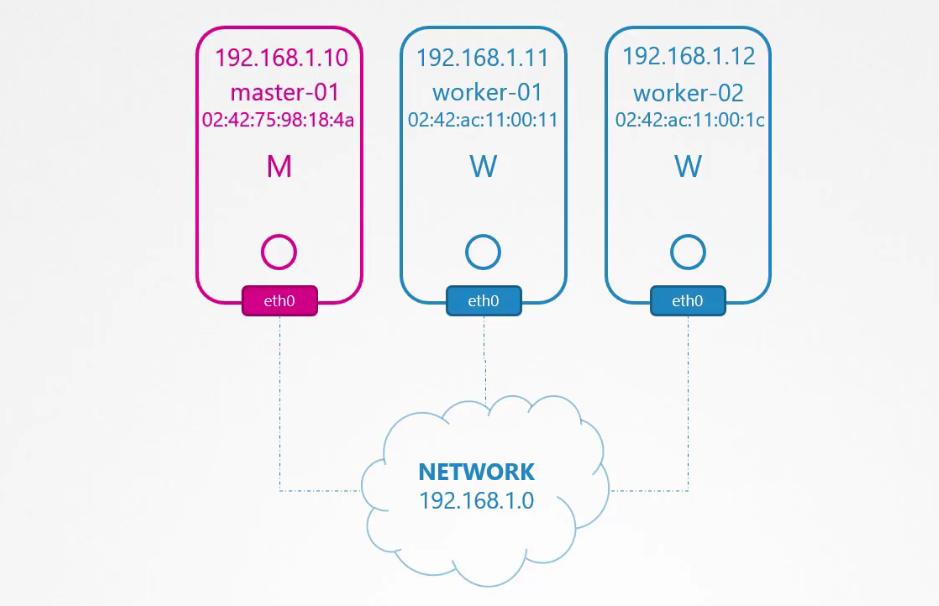
Có một số cổng cần được mở. Các cổng này được sử dụng bởi các thành phần khác nhau trong control plane. Master cần chấp nhận kết nối trên cổng 6443 cho API server. Các node worker, công cụ kube control, người dùng bên ngoài và tất cả các thành phần khác của control plane truy cập kube API server thông qua cổng này.
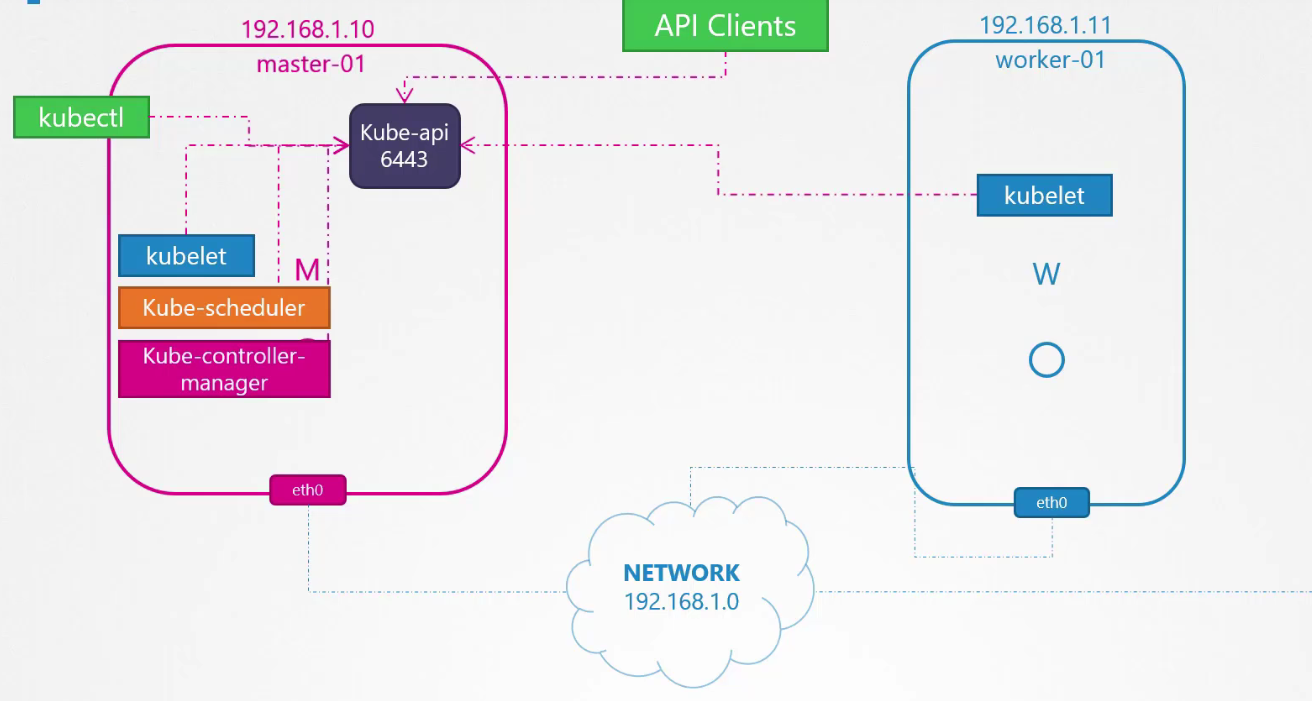
Các kubelet trên các node master và worker lắng nghe trên cổng 10250. Kubelet cũng có thể tồn tại trên node master. Kube scheduler yêu cầu mở cổng 10259. Kube controller manager yêu cầu mở cổng 10257.
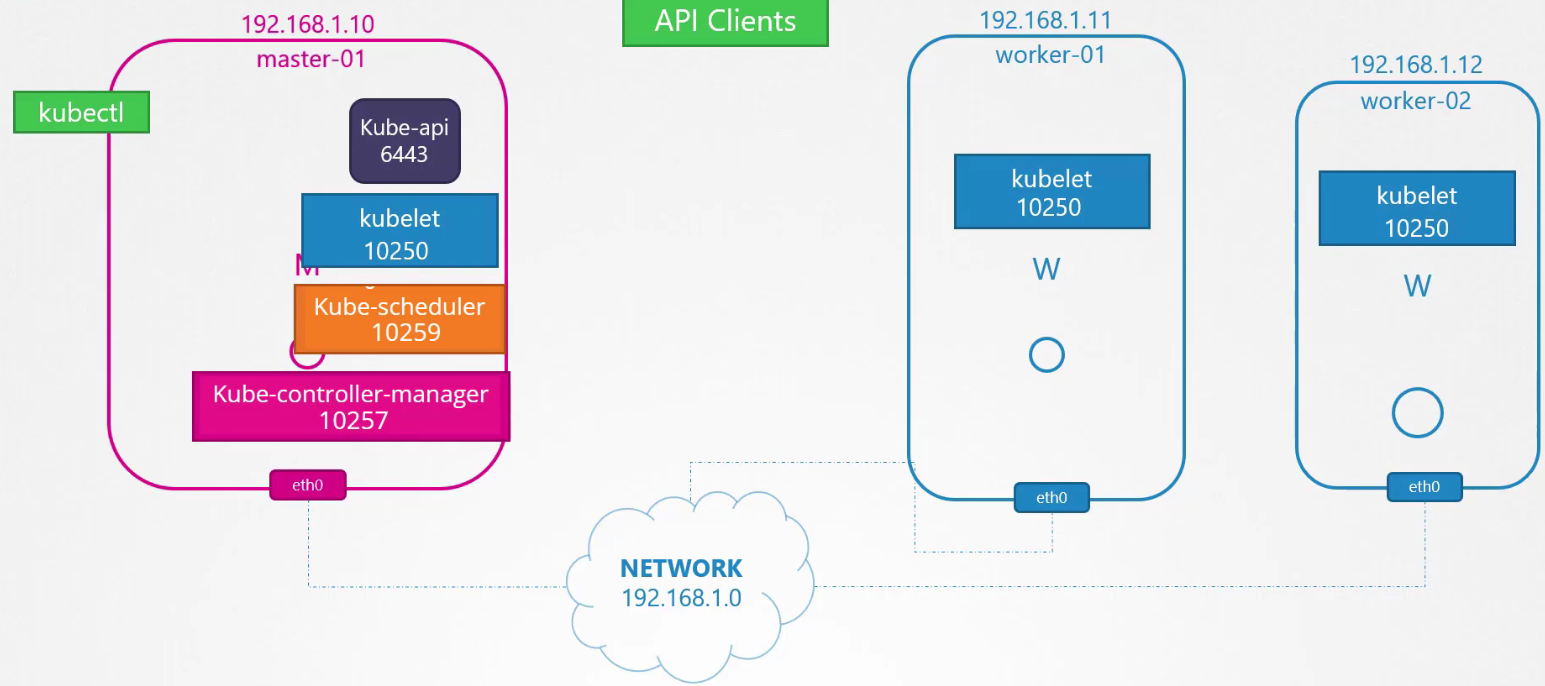
Các node worker cung cấp dịch vụ cho truy cập từ bên ngoài trên các cổng từ 30000 đến 32767. Máy chủ ETCD lắng nghe trên cổng 2379.
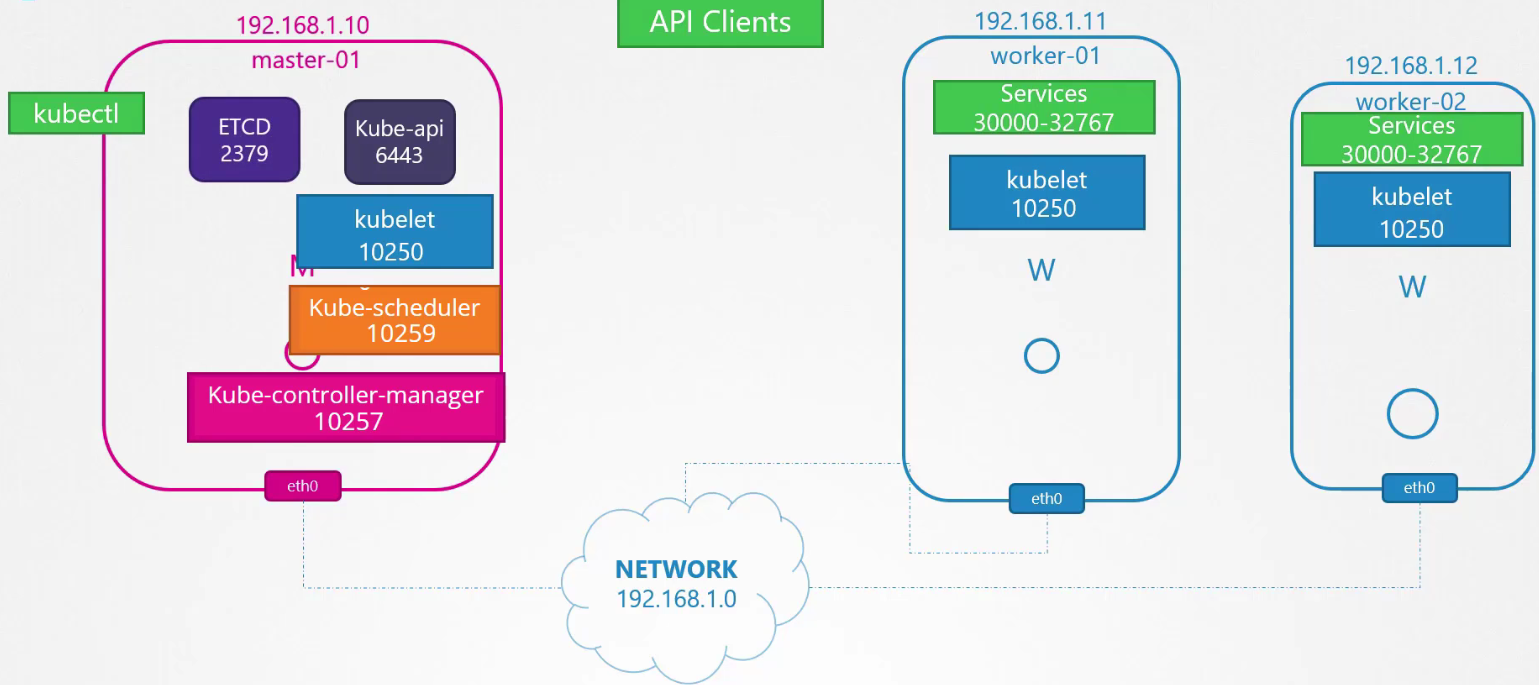
Nếu bạn có nhiều node master, tất cả các cổng này cũng cần được mở trên các node đó và bạn cần mở thêm cổng 2380 để các client ETCD có thể giao tiếp với nhau.
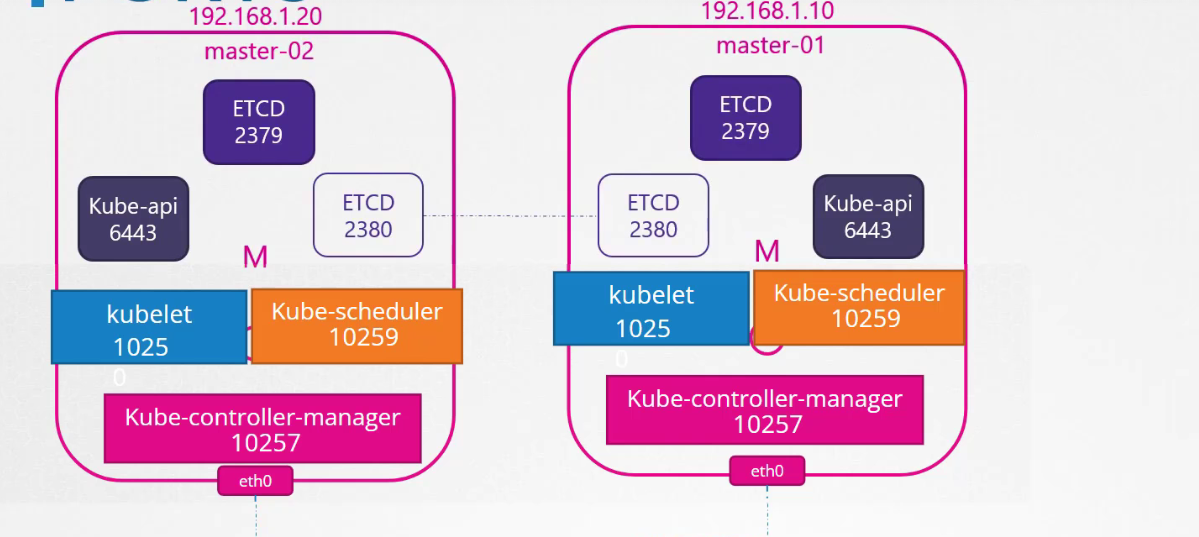
Network interface được cấu hình trên node Control Plane thường là interface được sử dụng để thực hiện giao tiếp giữa các node (node-to-node communication). Đây là interface chịu trách nhiệm kết nối và trao đổi dữ liệu giữa các thành phần của Control Plane và các node Worker trong cụm Kubernetes.
$ ip a | grep -B2 <INTERNAL-IP>
3: eth0@if1143: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1410 qdisc noqueue state UP group default
link/ether 86:6f:d5:35:ed:0a brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 192.168.219.142/32 scope global eth0
Pod Networking
Chúng ta có 1 cụm Kubernetes gồm các pod và service chạy trên đó.
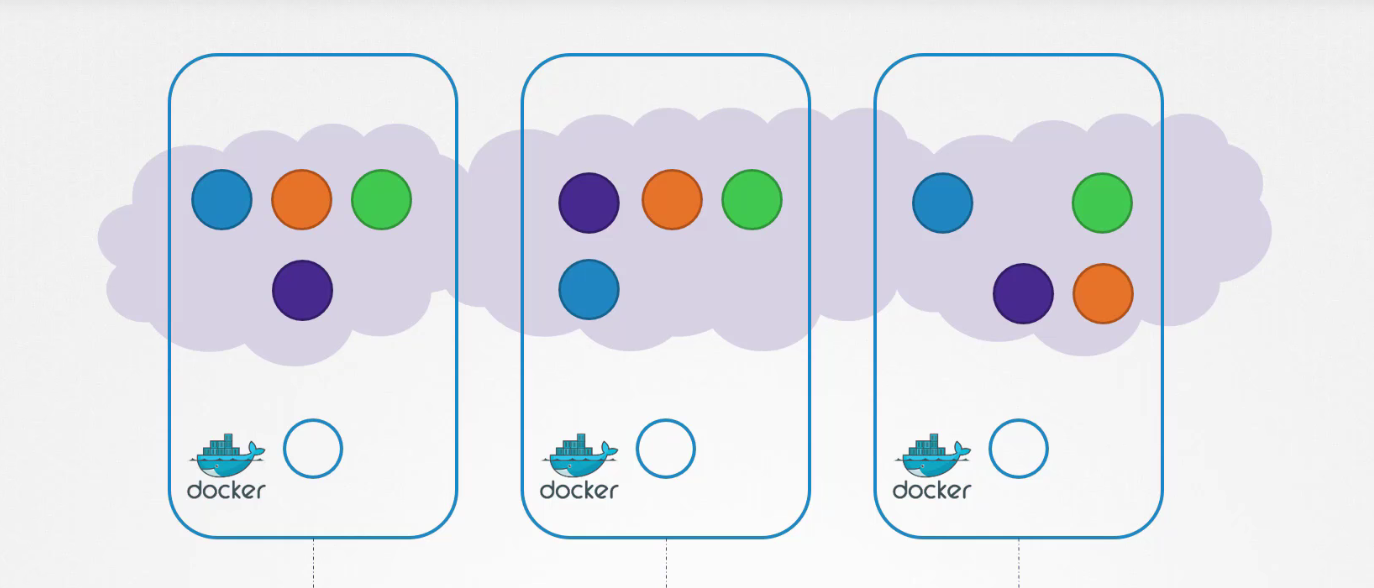
Kubernetes yêu cầu:
Mỗi pod phải có một địa chỉ IP duy nhất.
Mỗi pod phải có khả năng kết nối với mọi pod khác trong cùng một node bằng địa chỉ IP đó.
Mỗi pod cũng phải có khả năng kết nối với mọi pod khác trên các node khác, sử dụng cùng một địa chỉ IP.
Kubernetes không quan tâm địa chỉ IP đó là gì và nó thuộc phạm vi hay subnet nào. Miễn là bạn có thể triển khai một giải pháp tự động gán địa chỉ IP và thiết lập kết nối giữa các pod trong một nodecũng như giữa các pod trên các node khác, thì hệ thống sẽ hoạt động tốt mà không cần cấu hình bất kỳ quy tắc mạng tự nhiên nào.
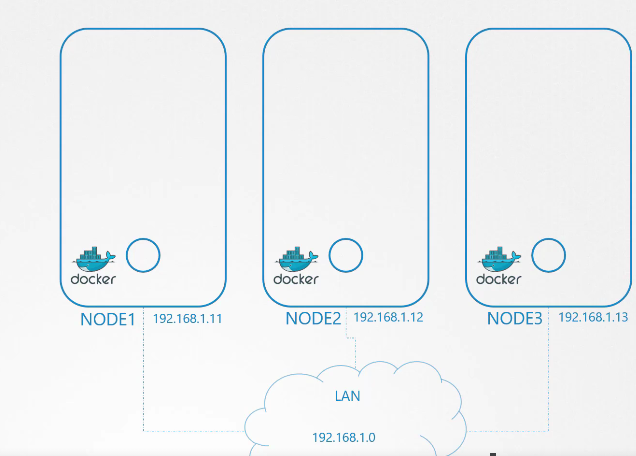
Vậy chúng ta có một cụm ba node. Tất cả chúng đều chạy các pod, có thể cho mục đích quản lý hoặc công việc (workload).
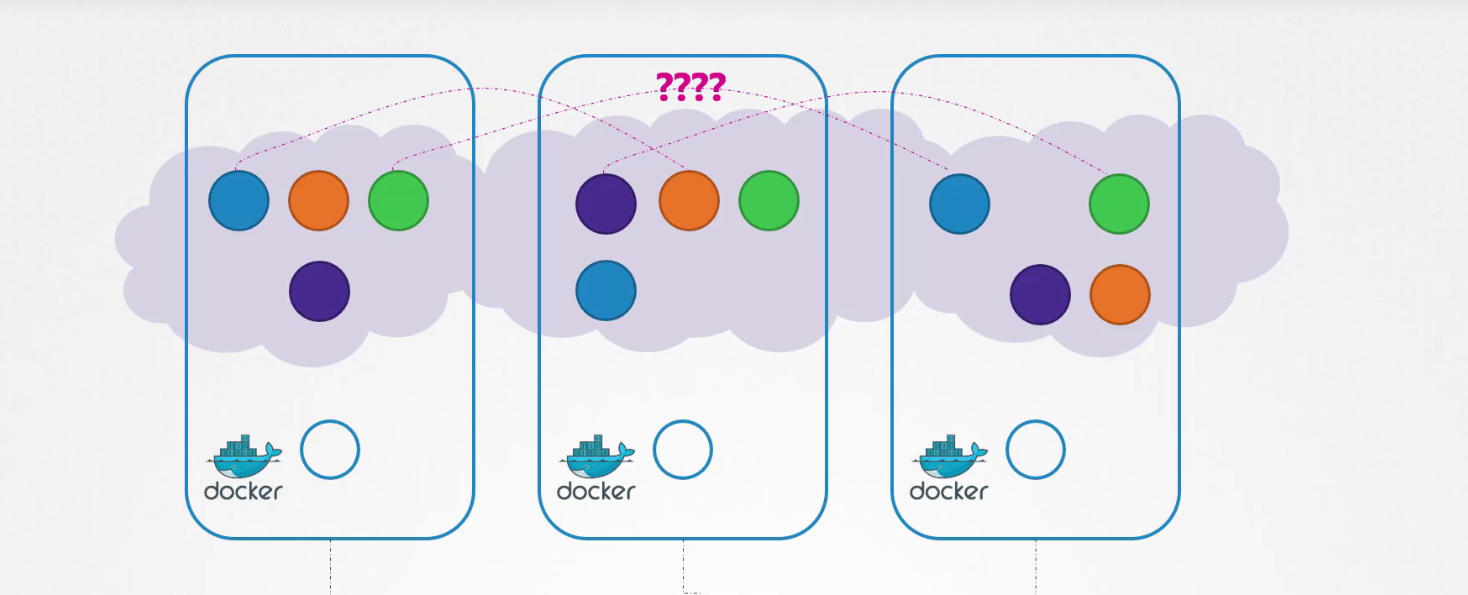
Bước tiếp theo, khi các container được tạo ra, Kubernetes sẽ tạo các không gian tên mạng (network namespaces) cho chúng. Để cho phép giao tiếp giữa chúng, chúng ta gắn các không gian tên này vào một mạng, nhưng mạng nào?
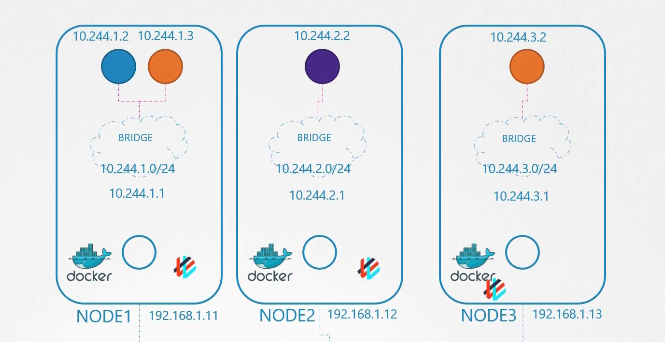
Vậy, chúng ta tạo một mạng cầu (bridge network) trên mỗi node.
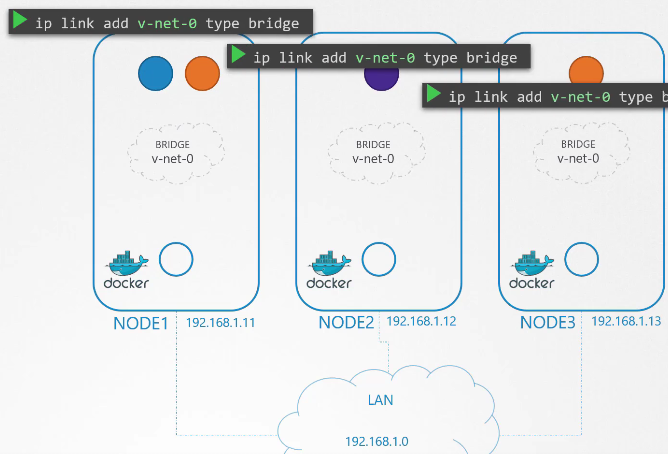
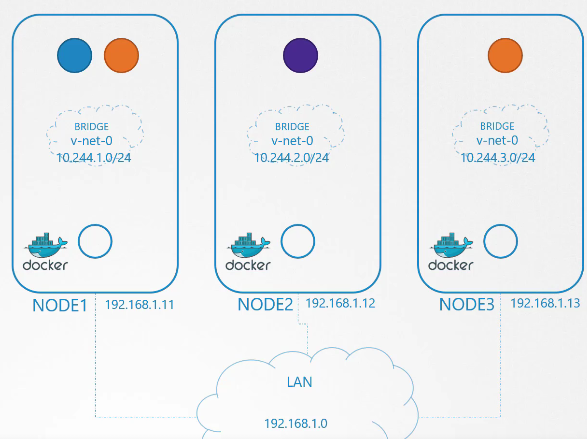
Sau đó, chúng ta kích hoạt chúng. Đến lúc gán một địa chỉ IP cho các giao diện cầu (bridge interfaces) hoặc mạng. Chúng ta quyết định rằng mỗi mạng cầu (bridge network) sẽ thuộc một subnet riêng biệt. Chọn bất kỳ dải địa chỉ riêng nào, ví dụ như 10.240.1, 10.240.2 và 10.240.3.
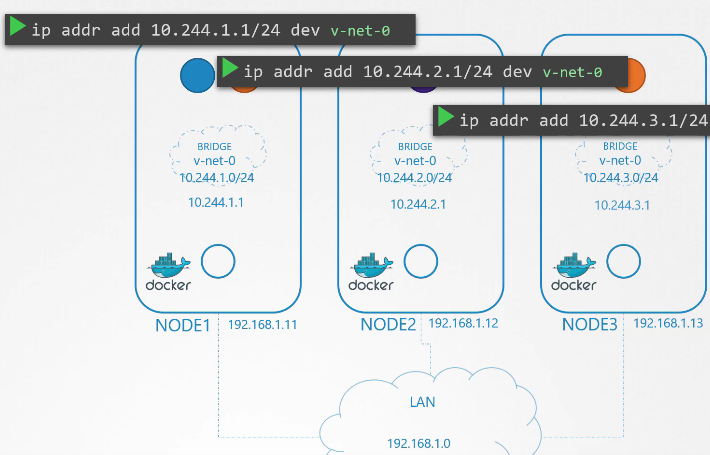
Tiếp theo, chúng ta thiết lập địa chỉ IP cho giao diện cầu (bridge interface).
Các bước còn lại sẽ được thực hiện cho mỗi container và mỗi khi một container mới được tạo ra.
Để gắn một container vào mạng, chúng ta cần một ống dẫn (pipe) hoặc một cáp mạng ảo.
# Create veth pair
ip link add ...
Sau đó, chúng ta gắn một đầu vào container và đầu còn lại vào cầu (bridge) bằng lệnh:
# Attach veth pair
ip link set ...
ip link set ...
Sau đó, chúng ta gán địa chỉ IP và thêm một tuyến đường (route) đến cổng mặc định (default gateway).:
# Assign IP Address
ip -n <namespace> addr add ...
ip -n <namespace> route add ...
Chúng ta có thể tự quản lý việc đó hoặc lưu trữ thông tin đó trong một loại cơ sở dữ liệu nào đó. Hiện tại, chúng ta giả sử nó là 10.244.1.2, một địa chỉ IP còn trống trong dải subnet.
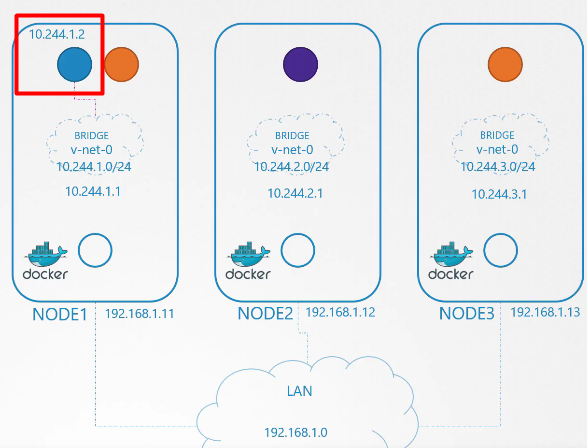
Cuối cùng, chúng ta kích hoạt interface:
# Bring Up Interface
ip -n <namespace> link set ...
Sau đó, chúng ta chạy cùng một script, lần này cho container thứ hai với thông tin của nó và kết nối container đó vào mạng. Hai container giờ đây có thể giao tiếp với nhau.
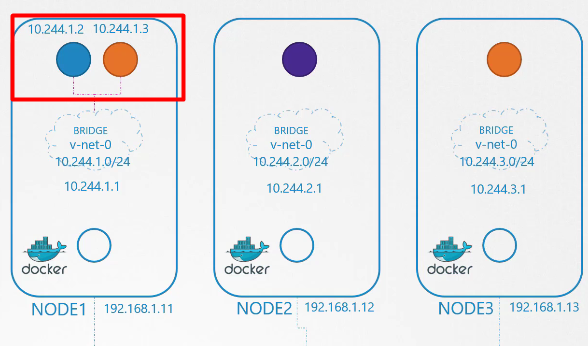
Chúng ta sao chép script vào các node (nodes) khác và chạy script trên chúng để gán địa chỉ IP và kết nối các container đó vào mạng nội bộ của chúng.
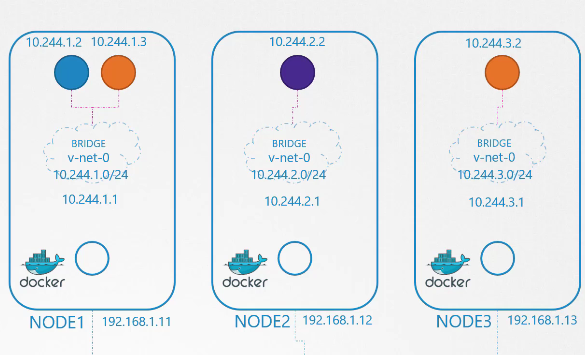
Tiếp theo là cho phép chúng có thể truy cập các pod trên các nodes khác.
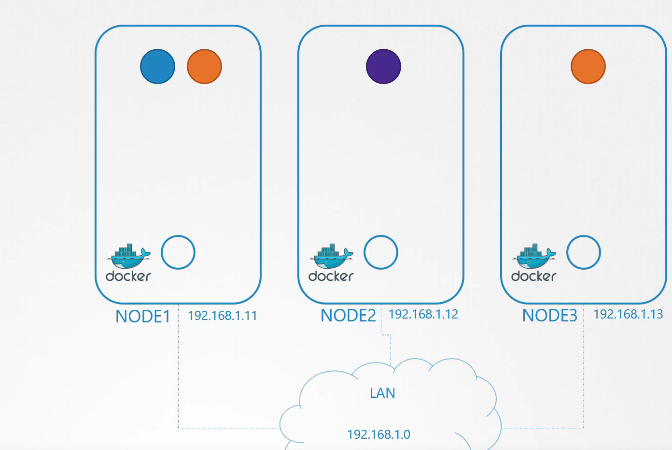
Ví dụ:
Pod tại địa chỉ 10.244.1.2 trên node1 muốn ping pod 10.244.2.2 trên node2. Hiện tại, pod đầu tiên không biết địa chỉ 10.244.2 là ở đâu vì nó thuộc một mạng khác so với mạng của chính nó.
$ ping 10.244.2.2
Connect: Network is unreachable
Để thêm một tuyến đường (route) vào bảng định tuyến (routing table) của node1 nhằm chuyển tiếp lưu lượng đến 10.244.2.2, nơi địa chỉ IP của node2 là 192.168.1.12
node1$ ip route add 10.244.2.2 via 192.168.1.12
Khi tuyến đường được thêm vào, pod trong node 1 có thể ping qua lại.
$ ping 10.244.2.2
64 bytes from 8.8.8.8: icmp_seq=1 ttl=63 time=0.587 ms
64 bytes from 8.8.8.8: icmp_seq=2 ttl=63 time=0.466 ms
Tương tự, chúng ta cấu hình tuyến đường trên tất cả các máy chủ (hosts) đến tất cả các máy chủ khác với thông tin về các mạng tương ứng trong mỗi máy chủ.
node1$ ip route add 10.244.3.2 via 192.168.1.13
node2$ ip route add 10.244.1.2 via 192.168.1.11
node2$ ip route add 10.244.3.2 via 192.168.1.13
node3$ ip route add 10.244.1.2 via 192.168.1.11
node2$ ip route add 10.244.2.2 via 192.168.1.12
Thay vì phải cấu hình tuyến đường trên mỗi máy chủ, một giải pháp tốt hơn là thực hiện việc đó trên một bộ định tuyến (router) nếu bạn có trong mạng của mình và chỉ định tất cả các máy chủ sử dụng nó làm cổng mặc định (default gateway). Bằng cách này, bạn có thể dễ dàng quản lý các tuyến đường đến tất cả các mạng trong bảng định tuyến của bộ định tuyến.
| NETWORK | GATEWAY |
| 10.244.1.0/24 | 192.168.1.11 |
| 10.244.2.0/24 | 192.168.1.12 |
| 10.244.3.0/24 | 192.168.1.13 |
Với cách làm đó, các mạng ảo riêng biệt mà chúng ta tạo ra với địa chỉ 10.244.1.0/24 trên mỗi node, giờ đây sẽ tạo thành một mạng lớn duy nhất với địa chỉ 10.244.0.0/16.
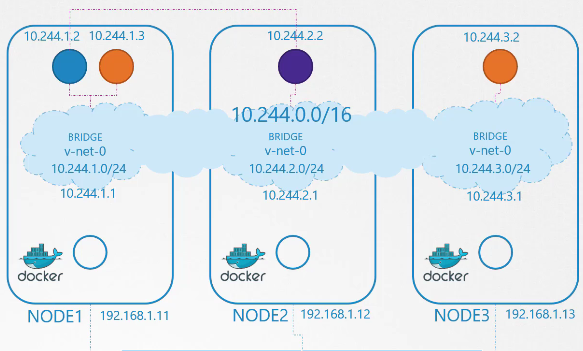
Đến lúc kết nối mọi thứ lại với nhau. Chúng ta đã thực hiện một số bước thủ công để chuẩn bị môi trường với các mạng cầu (bridge networks) và bảng định tuyến (routing tables). Sau đó, chúng ta viết một script có thể chạy cho mỗi container, thực hiện các bước cần thiết để kết nối mỗi container vào mạng.
Tất nhiên, chúng ta không muốn làm điều đó thủ công, đặc biệt là trong các môi trường lớn, nơi hàng nghìn pod được tạo ra mỗi phút.
Đó là lúc CNI (Container Network Interface) phát huy vai trò như một trung gian.
Môi trường container runtime trên mỗi node chịu trách nhiệm tạo các container. Mỗi khi một container được tạo ra, container runtime sẽ xem cấu hình CNI được truyền dưới dạng tham số dòng lệnh khi nó được chạy và xác định tên của script của chúng ta. Sau đó, nó sẽ tìm trong thư mục bin của CNI để tìm script của chúng ta và thực thi script đó với lệnh add, kèm theo tên và ID không gian tên (namespace ID) của container.

CNI in kubernetes
Thành phần chịu trách nhiệm tạo các container là container runtime. Hai ví dụ điển hình là Containerd và CRI-O.

Trước hết, các plugin mạng (network plugins) đều được cài đặt trong thư mục /opt/cni/bin và đó là nơi các container runtimes tìm thấy các plugin.

Tuy nhiên, việc sử dụng plugin nào và cách sử dụng nó được cấu hình trong thư mục /etc/cni/net.d. Trong thư mục này có thể có nhiều tệp cấu hình, mỗi tệp chịu trách nhiệm cấu hình cho từng plugin.

Nếu bạn nhìn vào thư mục cni/bin, bạn sẽ thấy nó chứa tất cả các plugin CNI hỗ trợ dưới dạng các tệp thực thi, chẳng hạn như bridge, DHCP, flannel, v.v.
$ ls /opt/cni/bin
bridge dhcp flannel host-local ipvlan loopback macvlan portmap ptp sample
tuning vlan weave-ipam weave-net weave-plugin-2.2.1
Thư mục cấu hình CNI (/etc/cni/net.d) có một bộ các tệp cấu hình. Đây là nơi container runtime tìm kiếm để xác định plugin nào cần được sử dụng. Trong trường hợp này, nó sẽ tìm thấy tệp cấu hình bridge. Nếu có nhiều tệp trong thư mục này, container runtime sẽ chọn tệp theo thứ tự bảng chữ cái.
$ ls /etc/cni/net.d
10-bridge.conf
$ cat /etc/cni/net.d/10-bridge.conf
{
"cniVersion": "0.2.0",
"name": "mynet",
"type": "bridge",
"bridge": "cni0",
"isGateway": true,
"ipMasq": true,
"ipam": {
"type": "host-local",
"subnet": "10.22.0.0/16",
"routes": [
{ "dst": "0.0.0.0/0" }
]
}
}
isGatewayxác định liệu giao diện bridge có nên nhận một địa chỉ IP được cấp để nó có thể hoạt động như một cổng (gateway) hay không.ipMasqxác định liệu có nên thêm một quy tắc NAT cho việc ẩn địa chỉ IP (IP masquerading) hay không.Phần
IPAM(IP Address Management) định nghĩa cấu hình quản lý địa chỉ IP. Đây là nơi bạn chỉ định subnet hoặc phạm vi địa chỉ IP sẽ được cấp cho các pod và các tuyến đường cần thiết.- Loại
host-localchỉ ra rằng các địa chỉ IP được quản lý cục bộ trên máy chủ này. Khác với một máy chủ DHCP, việc duy trì địa chỉ IP từ xa, loại này cũng có thể được đặt thànhDHCPđể cấu hình một máy chủ DHCP bên ngoài.
- Loại
CNI weave
Giải pháp mạng mà chúng ta thiết lập thủ công có một bảng định tuyến, bảng này ánh xạ các mạng nào nằm trên các máy chủ nào. Vì vậy, khi một gói tin được gửi từ một pod đến pod khác, nó sẽ ra ngoài mạng, đến bộ định tuyến (router), và tìm đường đến node chứa pod đó.
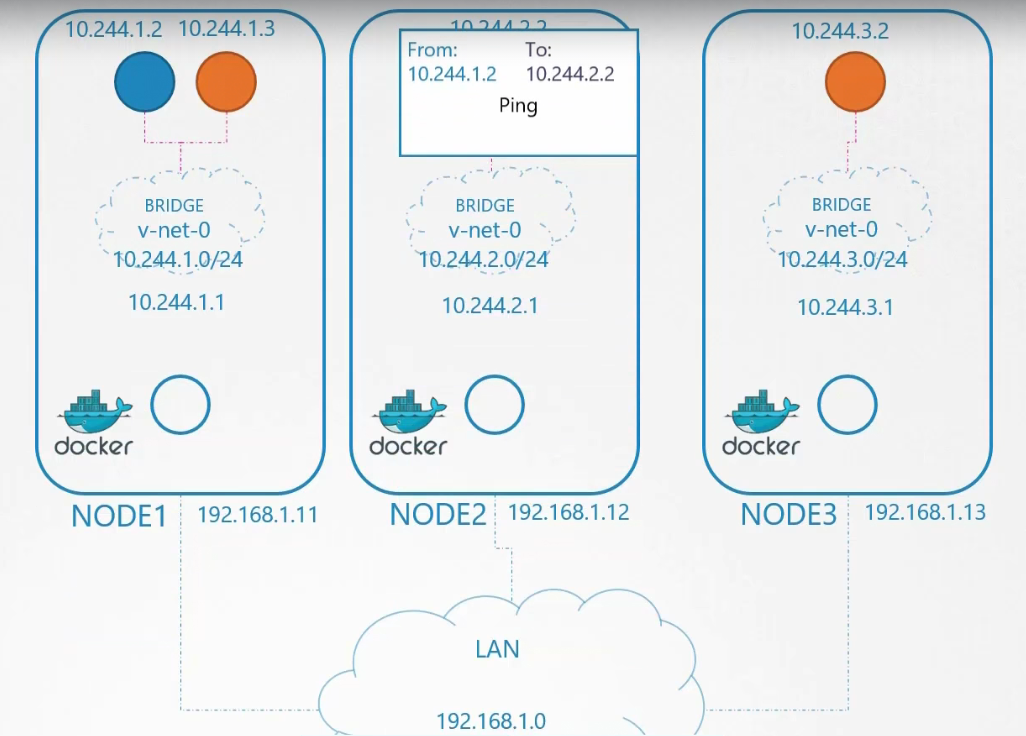
Điều này hoạt động tốt cho một môi trường nhỏ và trong một mạng đơn giản, nhưng trong các môi trường lớn với hàng trăm nodes, trong một cluster và hàng trăm pod trên mỗi node, điều này là không thực tế.
Hãy tưởng tượng cụm Kubernetes như công ty của chúng ta và các nodes như các văn phòng ở các địa điểm khác nhau. Mỗi văn phòng có các phòng ban khác nhau, và trong mỗi phòng ban có các văn phòng nhỏ.
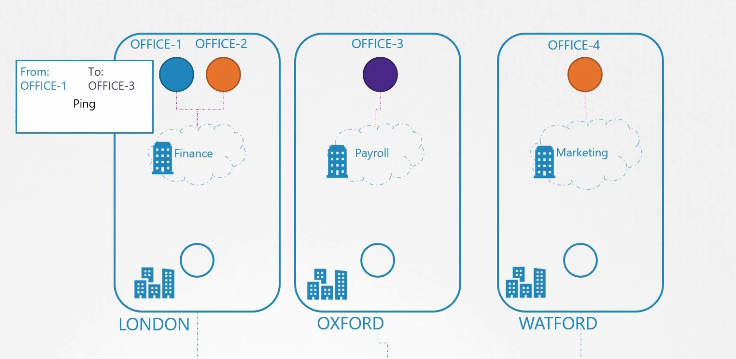
Ai đó trong văn phòng một muốn gửi một gói tin đến văn phòng ba và giao cho người đưa thư, tất cả những gì anh ta biết là nó cần phải đến văn phòng ba, và anh ta không quan tâm ai hay bằng cách nào nó sẽ được vận chuyển. Người đưa thư nhận gói, lên xe, tra cứu địa chỉ của văn phòng đích trong GPS, sử dụng chỉ dẫn trên các con phố và tìm đường đến địa điểm đó, giao gói hàng cho bộ phận nhân sự, và bộ phận nhân sự sẽ chuyển tiếp gói hàng đến văn phòng ba.
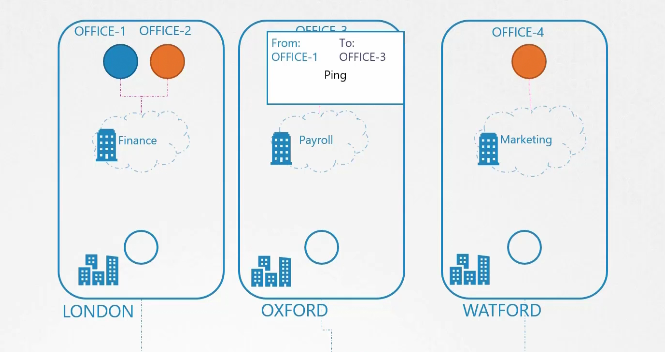
Chúng ta sớm mở rộng sang các khu vực và quốc gia khác, và quá trình này không còn hiệu quả nữa. Người đưa thư khó có thể theo dõi tất cả các tuyến đường đến một số lượng lớn các văn phòng ở các quốc gia khác nhau. Và tất nhiên, anh ta không thể tự mình lái xe đến những văn phòng đó. Chính vì vậy, chúng ta quyết định thuê một công ty chuyên nghiệp để xử lý tất cả các hoạt động gửi thư và vận chuyển, vì họ là những người làm tốt nhất công việc này.
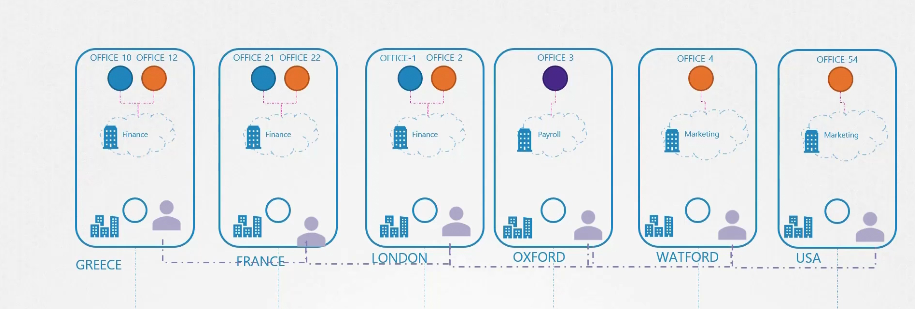
Khi công ty vận chuyển được thuê, điều đầu tiên họ làm là cử các đại lý đến từng văn phòng của công ty chúng ta. Những đại lý này chịu trách nhiệm quản lý tất cả các hoạt động vận chuyển giữa các văn phòng. Họ cũng liên tục giao tiếp với nhau và kết nối rất tốt. Vì vậy, họ đều biết về các văn phòng của nhau, các phòng ban trong đó và các văn phòng làm việc ở mỗi khu vực.
Vì vậy, khi một gói hàng được gửi từ văn phòng 10 đến văn phòng 3, đại lý vận chuyển tại văn phòng đó sẽ chặn gói hàng và xem tên văn phòng đích.
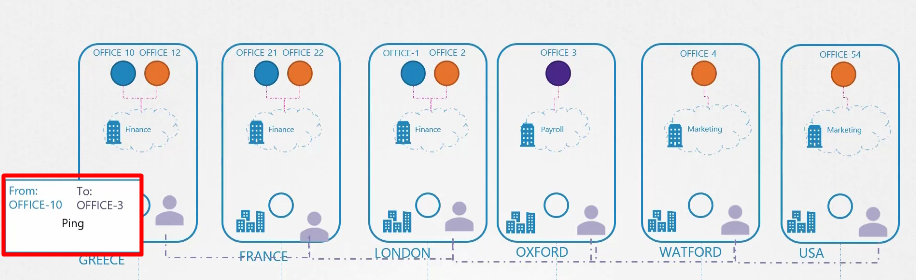
Anh ta biết chính xác văn phòng đó ở đâu trong site và phòng ban nào thông qua mạng lưới nội bộ với các đồng nghiệp của mình tại các site khác. Sau đó, anh ta sẽ đóng gói lại gói hàng này vào một gói mới với địa chỉ đích là vị trí của site mục tiêu.
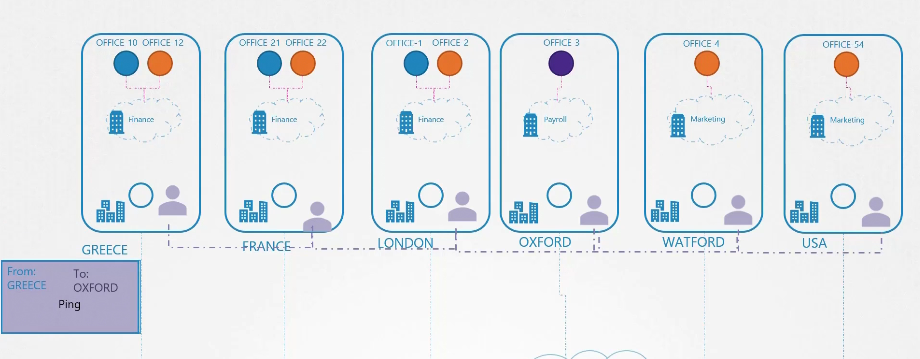
Sau đó, anh ta gửi gói hàng đi. Khi gói hàng đến nơi, nó lại được tiếp nhận bởi đại lý tại site đó. Anh ta mở gói hàng, lấy lại gói hàng ban đầu và chuyển nó đến phòng ban đúng.
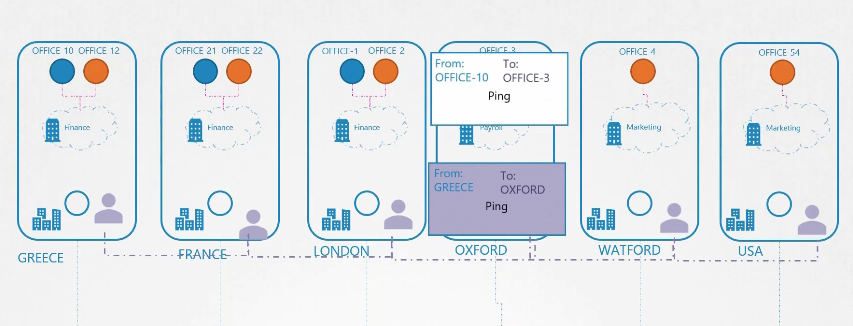
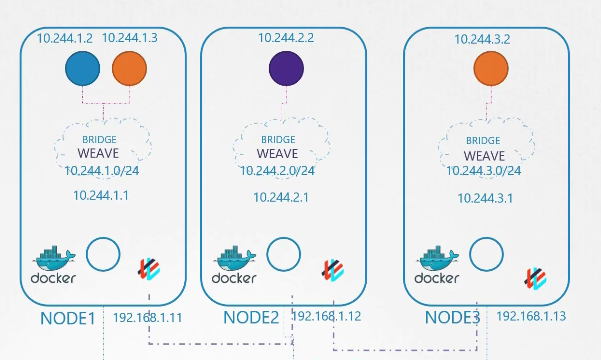
Trở lại với Kubernetes, khi plugin Weave CNI được triển khai trên một cluster, nó triển khai một agent hoặc dịch vụ trên mỗi node.
Chúng giao tiếp với nhau để trao đổi thông tin về các node, mạng và pod trong các node đó. Mỗi agent hoặc peer lưu trữ một bản đồ cấu trúc của toàn bộ hệ thống. Bằng cách này, chúng biết các pod và địa chỉ IP của chúng trên các node khác. Weave tạo ra cầu (bridge) riêng trên các node và đặt tên là "Weave", sau đó gán địa chỉ IP cho mỗi mạng.
Service Networking
Bây giờ, bạn hiếm khi cấu hình các pod của mình để giao tiếp trực tiếp với nhau. Nếu bạn muốn một pod truy cập các dịch vụ được lưu trữ trên một pod khác, bạn sẽ luôn sử dụng một service.
Để làm cho pod màu cam có thể truy cập được từ pod màu xanh dương, chúng ta tạo một service cho pod màu cam. Service này sẽ được gán một địa chỉ IP và một tên. Pod màu xanh dương bây giờ có thể truy cập pod màu cam thông qua địa chỉ IP hoặc tên của service màu cam.
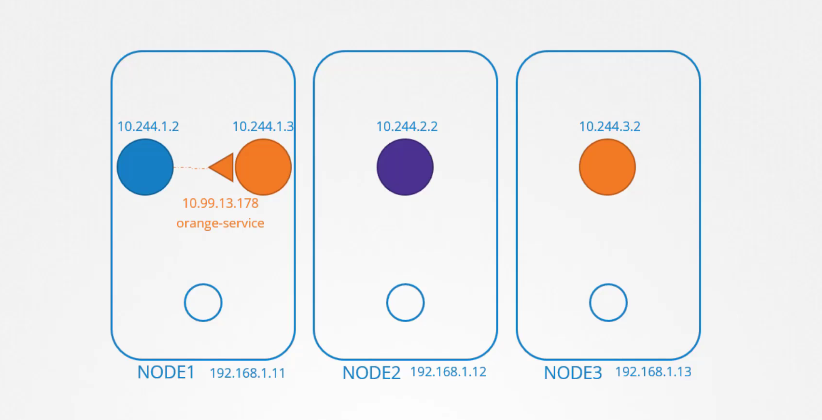
Khi một service được tạo, nó có thể được truy cập từ tất cả các pod trong cluster, bất kể các pod nằm trên node nào. Trong khi một pod được lưu trữ trên một node, thì một service được lưu trữ trên toàn bộ cluster.
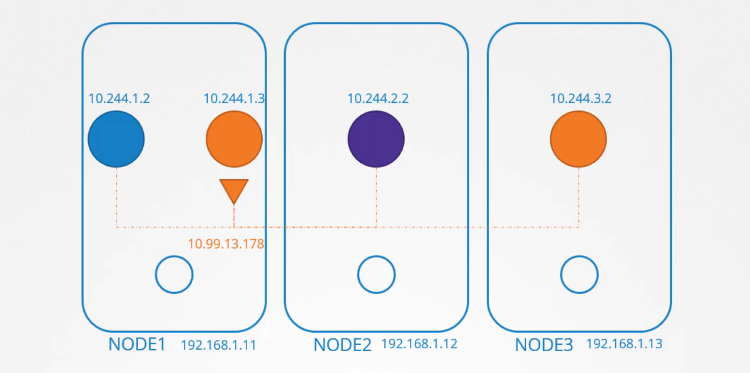
Nó không bị ràng buộc với một node cụ thể, nhưng hãy nhớ rằng service chỉ có thể được truy cập từ bên trong cluster. Loại service này được gọi là ClusterIP. Nếu pod orange đang chạy một ứng dụng cơ sở dữ liệu và chỉ cần được truy cập từ bên trong cluster, thì loại service này hoàn toàn phù hợp.
Nếu pod purple đang chạy một ứng dụng web và cần được truy cập từ bên ngoài cluster, chúng ta sẽ tạo một service khác với loại NodePort. Service này cũng được gán một địa chỉ IP và hoạt động tương tự như ClusterIP, nghĩa là tất cả các pod khác trong cluster có thể truy cập vào service này bằng địa chỉ IP của nó. Tuy nhiên, ngoài ra, service này còn mở ứng dụng ra một cổng (port) trên tất cả các node trong cluster.
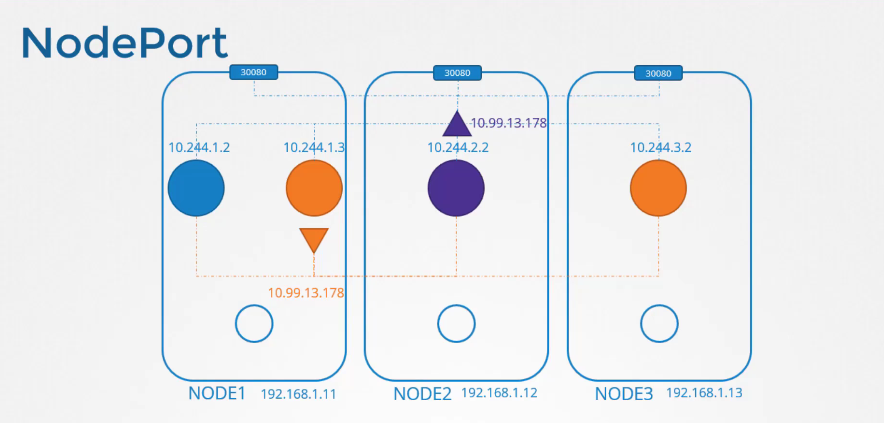
Bằng cách đó, người dùng hoặc ứng dụng bên ngoài có thể truy cập vào service.
Chúng ta có một cụm ba node, hiện tại chưa có pod hoặc service nào.
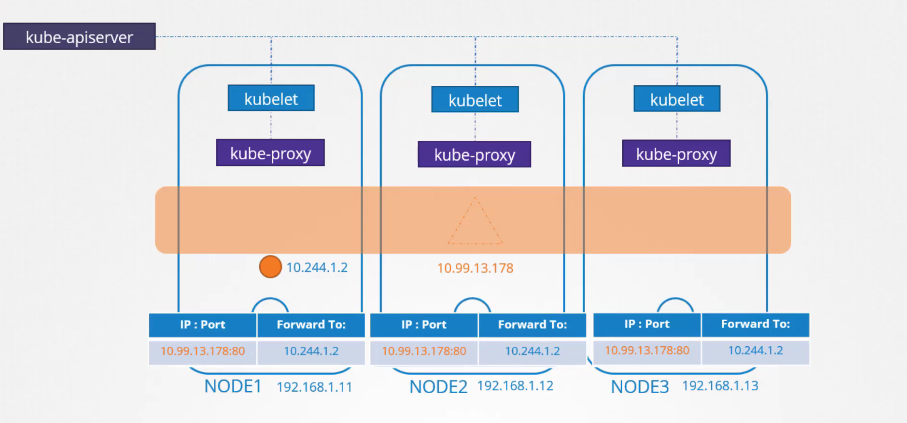
Chúng ta biết rằng mỗi node trong Kubernetes chạy một tiến trình kubelet, có nhiệm vụ tạo các pod. Mỗi dịch vụ kubelet trên từng node sẽ theo dõi các thay đổi trong cụm thông qua Kube API server.
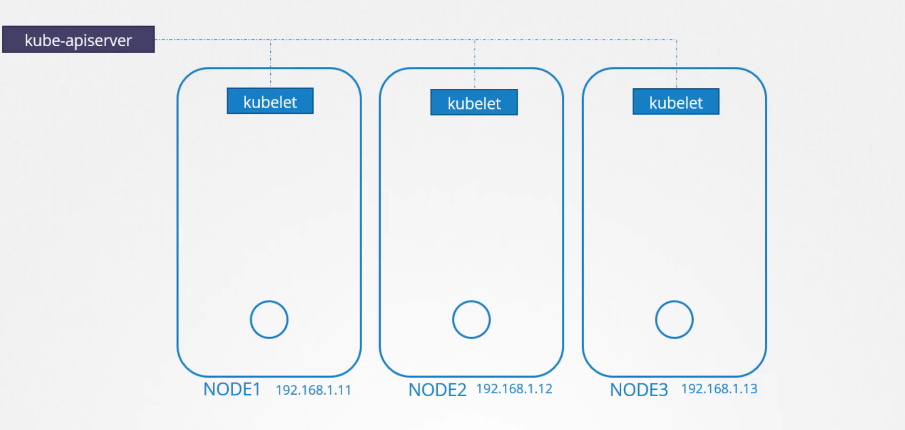
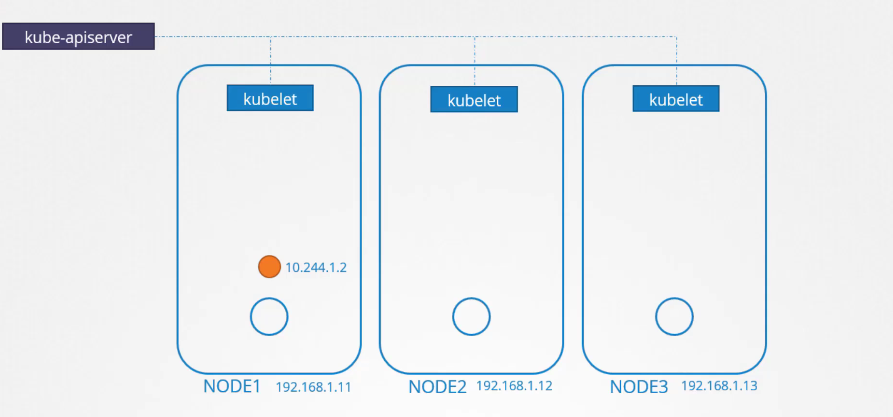
Mỗi khi một pod mới được tạo, kubelet sẽ tạo pod trên các node. Sau đó, nó gọi CNI plugin để cấu hình mạng cho pod đó.
Tương tự, mỗi node cũng chạy một thành phần khác được gọi là kube-proxy. Kube-proxy theo dõi các thay đổi trong cụm thông qua Kube API server, và mỗi khi một dịch vụ mới được tạo, kube-proxy sẽ kích hoạt. Khác với các pod, dịch vụ không được tạo trên mỗi node hay gán cho mỗi node. Dịch vụ là một khái niệm toàn cụm.
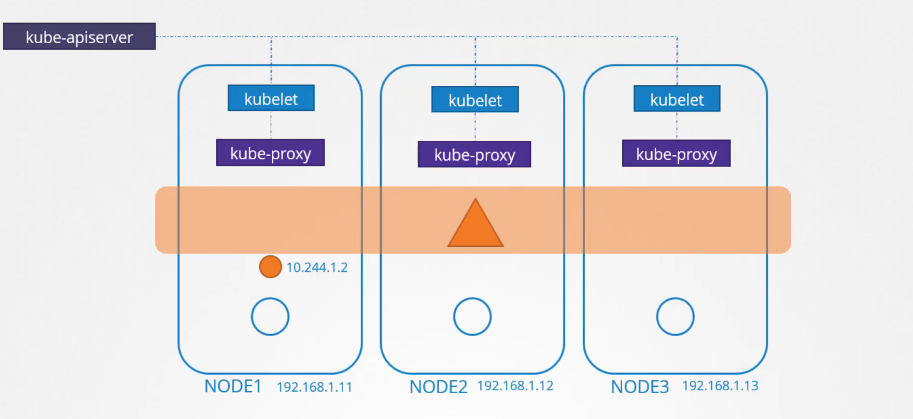
Chúng tồn tại trên tất cả các node trong cụm. Thực tế, chúng không tồn tại thực sự. Không có máy chủ hay dịch vụ nào thực sự lắng nghe trên IP của dịch vụ. Chúng ta đã thấy rằng các pod có các container, và các container có các không gian tên (namespaces) với các giao diện (interfaces) và các địa chỉ IP được gán cho các giao diện đó. Với các dịch vụ, không có thứ gì giống như vậy. Nó chỉ là một đối tượng ảo.
Khi chúng ta tạo một đối tượng dịch vụ trong Kubernetes, nó sẽ được gán một địa chỉ IP từ một dải đã được định nghĩa sẵn. Các thành phần kube-proxy chạy trên mỗi node sẽ nhận địa chỉ IP đó và tạo các rules forward trên mỗi node trong cluster.
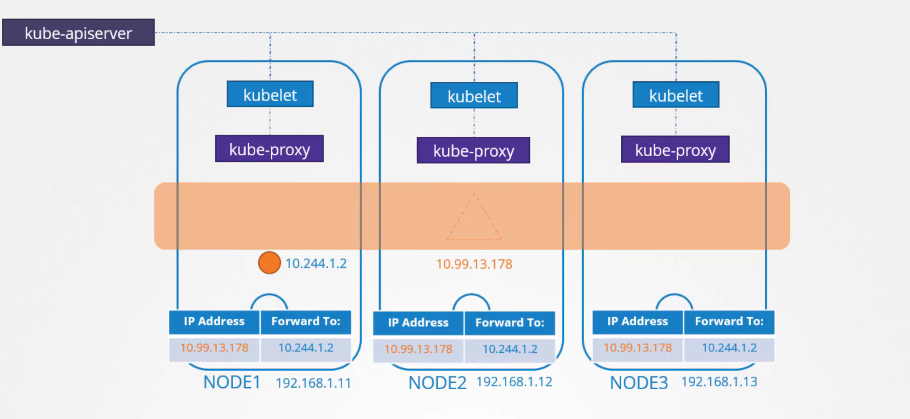
Khi điều này được thiết lập, bất kỳ khi nào một pod cố gắng truy cập vào địa chỉ IP của dịch vụ, nó sẽ được chuyển tiếp đến địa chỉ IP của pod, mà có thể truy cập từ bất kỳ node nào trong cluster. Đó không chỉ là địa chỉ IP, mà là sự kết hợp giữa địa chỉ IP và cổng. Mỗi khi dịch vụ được tạo hoặc xóa, thành phần kube-proxy sẽ tạo hoặc xóa các quy tắc này.
Kube-proxy hỗ trợ các cách khác nhau, chẳng hạn như userspace, nơi kube-proxy lắng nghe trên một cổng cho mỗi dịch vụ và chuyển tiếp các kết nối đến các pod bằng cách tạo các quy tắc IPVS. Hoặc tùy chọn thứ ba và mặc định, và là tùy chọn quen thuộc với chúng ta, là sử dụng iptables.
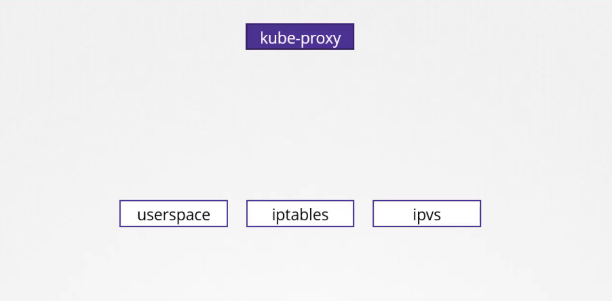
Chế độ proxy có thể được thiết lập bằng cách sử dụng tùy chọn proxy mode khi cấu hình dịch vụ kube-proxy. Nếu không thiết lập, nó sẽ mặc định sử dụng iptables.
$ kube-proxy --proxy-mode [userspace | iptables | ipvs ] ...
Vậy chúng ta sẽ xem cách kube-proxy cấu hình iptables và cách bạn có thể xem chúng trên các node.
Chúng ta có một pod tên là db được triển khai trên node-1, nó có địa chỉ IP là 10.244.1.2
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE
db 1/1 Running 0 14h 10.244.1.2 node-1
Chúng ta tạo một service với kiểu ClusterIP để làm cho pod này có sẵn trong cụm. Khi service được tạo, Kubernetes sẽ gán cho nó một địa chỉ IP. Địa chỉ IP này được gán là 10.103.132.104.
$ kubectl get service
NAME TYPE CLUSTER-IP PORT(S) AGE
db-service ClusterIP 10.103.132.104 3306/TCP 12h
Dải địa chỉ này được chỉ định trong tùy chọn của Kube API server gọi là service-cluster-ip-range, theo mặc định được đặt thành 10.0.0.0/24.
$ kube-api-server --service-cluster-ip-range ipNet (Default: 10.0.0.0/24)
Trong trường hợp của tôi, nếu tôi nhìn vào tùy chọn Kube API server, tôi thấy nó được thiết lập thành 10.96.0.0/12.
$ ps aux | grep kube-api-server
kube-apiserver --authorization-mode=Node,RBAC
--service-cluster-ip-range 10.96.0.0/12
Điều đó cấp cho các dịch vụ của tôi một dải IP từ 10.96.0.0 đến 10.111.255.255. Khi tôi thiết lập mạng pod, tôi đã cung cấp một dải CIDR mạng pod là 10.244.0.0/16, điều này cấp cho các pod của tôi địa chỉ IP từ 10.244.0.0 đến 10.244.255.255. Nên không có trường hợp nào mà một pod và một dịch vụ được gán cùng một địa chỉ IP.
Bạn có thể xem các quy tắc được tạo ra bởi kube-proxy trong bảng NAT của iptables.
$ iptables –L –t net | grep db-service
KUBE-SVC-XA5OGUC7YRHOS3PU tcp -- anywhere 10.103.132.104
/* default/db-service: cluster IP */ tcp dpt:3306
DNAT tcp -- anywhere anywhere
/* default/db-service: */ tcp to:10.244.1.2:3306
KUBE-SEP-JBWCWHHQM57V2WN7 all -- anywhere anywhere
/* default/db-service: */
KUBE-SVC-XA5OGUC7YRHOS3PU tcp -- anywhere 10.103.132.104
/* default/db-service: cluster IP */ tcp dpt:3306
DNAT tcp -- anywhere anywhere
/* default/db-service: */ tcp to:10.244.1.2:3306
KUBE-SEP-JBWCWHHQM57V2WN7 all -- anywhere anywhere
/* default/db-service: */
DNS in kubernetes
chúng ta có một cluster Kubernetes ba node, với một số pods và services đã được triển khai trên chúng. Mỗi node có tên node và địa chỉ IP được gán cho nó. Các tên node và địa chỉ IP của cluster có thể đã được đăng ký trong một máy chủ DNS trong tổ chức của bạn.
Kubernetes triển khai một máy chủ DNS tích hợp mặc định khi bạn thiết lập một cluster. Nếu bạn thiết lập Kubernetes thủ công, thì bạn sẽ phải làm điều đó bằng chính tay mình.
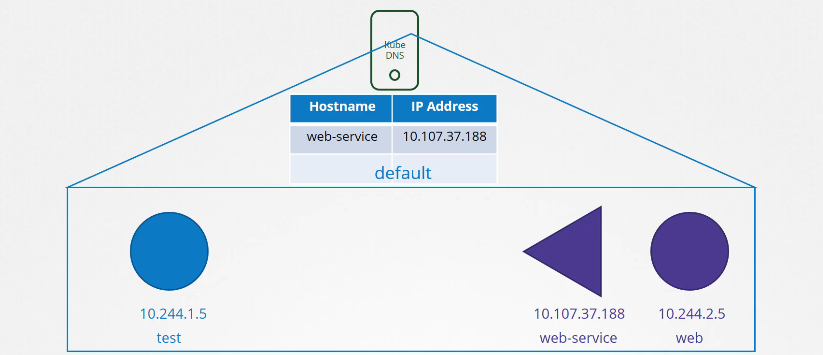
Tôi có một pod kiểm tra bên trái với địa chỉ IP được thiết lập là 10.2.44.105 và tôi có một pod web bên phải với địa chỉ IP được thiết lập là 10.2.44.2.5. Để làm cho máy chủ web có thể truy cập được từ pod kiểm tra, chúng ta tạo một dịch vụ và đặt tên cho nó là "web service". Dịch vụ này sẽ có một địa chỉ IP là 10.107.37.188.

Mỗi khi một service được tạo ra, service DNS của Kubernetes sẽ tạo một bản ghi cho service đó. Nó ánh xạ tên service với địa chỉ IP của service.
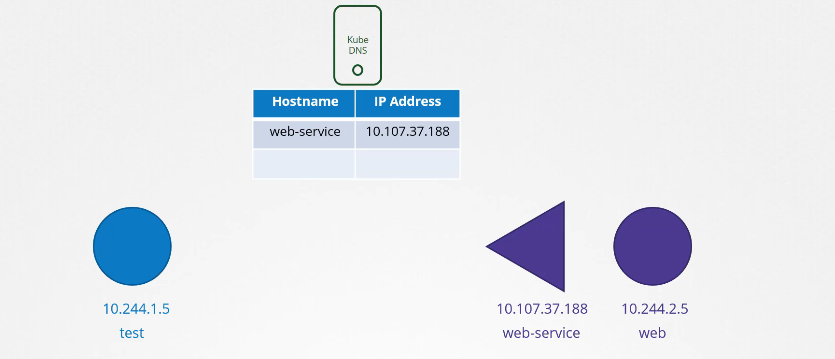
Vì vậy, trong cụm (cluster), bất kỳ pod nào cũng có thể truy cập service này bằng cách sử dụng tên service.
$ curl http://web-service
Welcome to NGINX!
Trong trường hợp này, vì pod test và pod web, cùng với dịch vụ liên quan, đều ở trong cùng một không gian tên (namespace), là không gian tên mặc định (default namespace), bạn có thể dễ dàng truy cập dịch vụ web từ pod test chỉ bằng cách sử dụng tên dịch vụ "Web-Service".
Giả sử dịch vụ web nằm trong một không gian tên riêng biệt có tên là "Apps". Khi đó, để tham chiếu đến dịch vụ này từ không gian tên mặc định (default namespace), bạn sẽ phải sử dụng cú pháp web-service.apps.
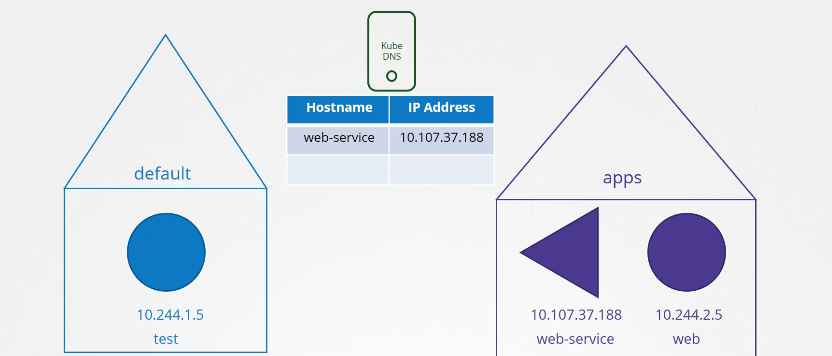
$ curl http://web-service.apps
Welcome to NGINX!
"Web service" là tên của service và "Apps" là tên của không gian tên (namespace). Đối với mỗi không gian tên, máy chủ DNS sẽ tạo một tên miền con (subdomain) với tên của nó. Tất cả các pod và service của một không gian tên sẽ được nhóm lại trong một tên miền con có tên là không gian tên đó. Tất cả các service sẽ được nhóm lại trong một tên miền con khác gọi là svc. Do đó, bạn có thể truy cập ứng dụng của mình bằng tên webservice.apps.svc.

$ curl http://web-service.apps.svc
Welcome to NGINX!
Cuối cùng, tất cả các dịch vụ và pod được nhóm lại vào một tên miền (domain) định tuyến cho cụm (cluster), và tên miền này mặc định được thiết lập là cluster.local.
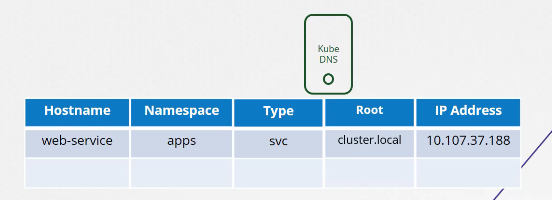
$ curl http://web-service.apps.svc.cluster.local
Welcome to NGINX!
Các bản ghi cho các pod không được tạo mặc định, nhưng chúng ta có thể bật tính năng này một cách rõ ràng. Khi tính năng này được bật, các bản ghi cho pod cũng sẽ được tạo. Tuy nhiên, chúng không sử dụng tên pod mà Kubernetes tạo ra một tên cho mỗi pod bằng cách thay thế dấu chấm trong địa chỉ IP của pod bằng dấu gạch ngang. Tên không gian tên (namespace) vẫn giữ nguyên và loại (type) được đặt là pod. Tên miền định tuyến luôn là cluster.local.
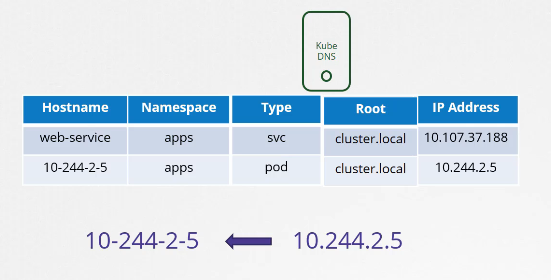
$ curl http://10-244-2-5.apps.pod.cluster.local
Welcome to NGINX!
Subscribe to my newsletter
Read articles from Phan Văn Hoàng directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by