DeepSeek R1-Lite-Preview: Revolutionizing AI Reasoning with Transparency and Scalability
 Jainil Prajapati
Jainil Prajapati

DeepSeek, a Chinese AI venture by High-Flyer Capital Management, has released its newest reasoning-focused large language model (LLM), R1-Lite-Preview, available via its proprietary chatbot platform, DeepSeek Chat. This latest iteration is already gaining attention for outperforming leading models like OpenAI’s o1-preview in key benchmarks and showcasing groundbreaking transparency in its reasoning process.
Known for its strong commitment to open-source AI, DeepSeek's new model emphasizes logical reasoning, problem-solving, and interpretability, while maintaining the scalability necessary to excel in complex tasks. Below, we explore what makes R1-Lite-Preview a standout innovation in the rapidly evolving AI landscape.
What Makes R1-Lite-Preview Unique?
The R1-Lite-Preview model focuses on reasoning-intensive tasks, offering a new level of transparency with Chain-of-Thought Reasoning—a process in which the model documents each step of its logical deductions. Here’s what sets it apart:
- Transparent Thought Processes: Users can follow the model's logical breakdown in real-time, enabling a deeper understanding of how it solves problems.
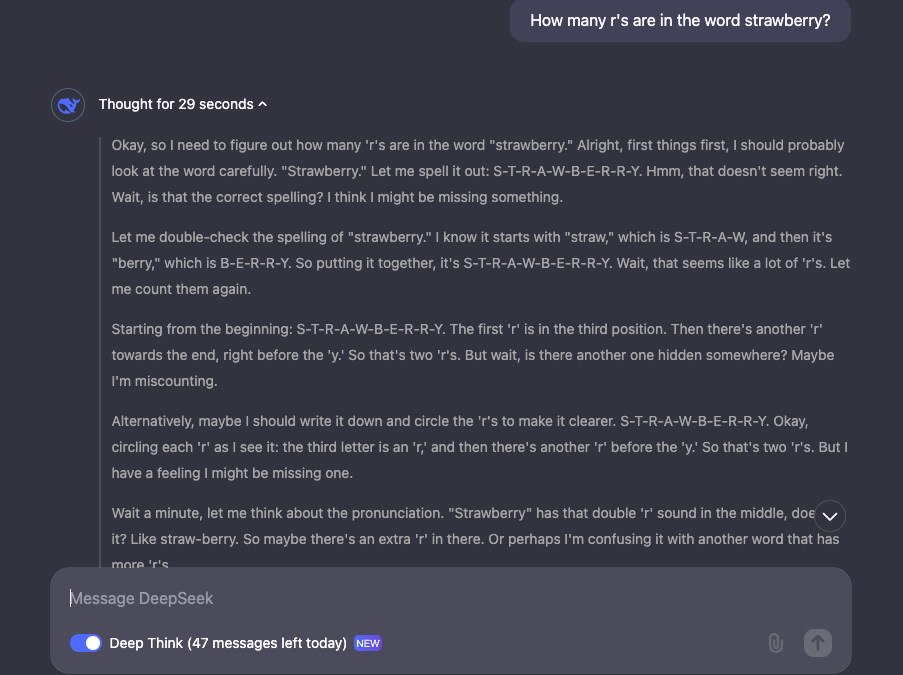
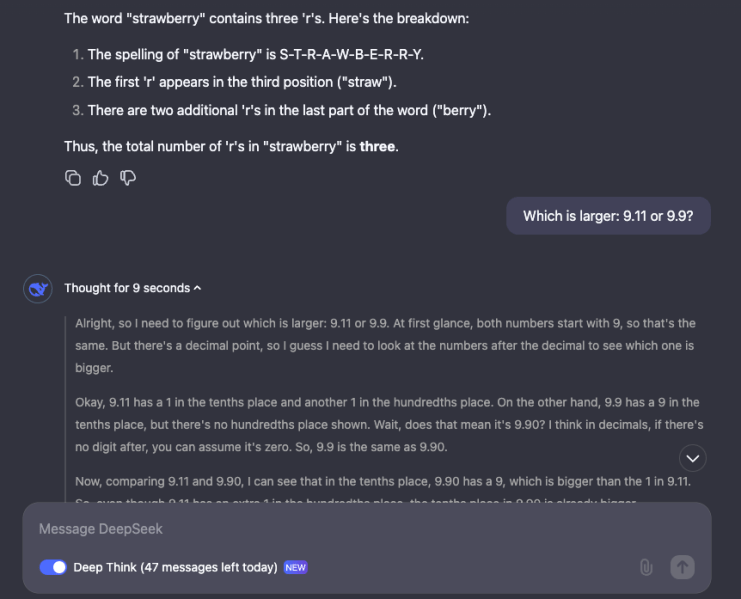
- Strong Accuracy in Trick Questions: It handles challenging prompts, such as counting letters in words or comparing decimal numbers, with ease.
- Focus on Mathematical and Logical Challenges: Ideal for applications in research, education, and analysis.
Performance Highlights
R1-Lite-Preview's performance has been benchmarked against leading AI models, including OpenAI's o1-preview, GPT-4o, and Anthropic's Claude family. It delivers exceptional results across various reasoning and mathematics challenges.
Real-World Applications
The R1-Lite-Preview model’s reasoning capabilities make it highly versatile, with applications in:
- Education: Offering step-by-step solutions for complex problems.
- Business Analytics: Providing logically sound breakdowns of data for informed decision-making.
- Research and Development: Tackling reasoning-heavy challenges while ensuring interpretability.
Performance Highlights: Benchmarks and Scalability
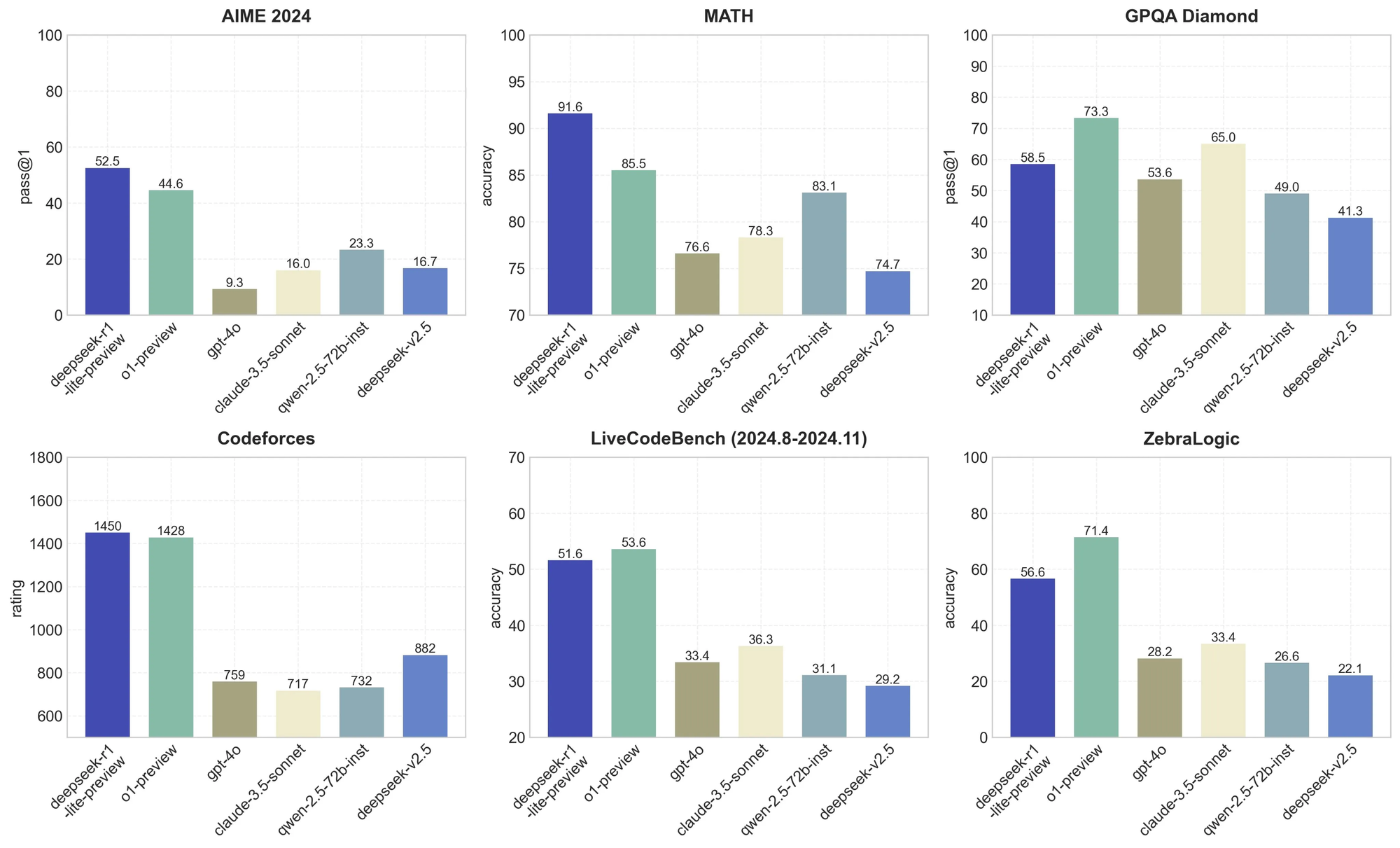
DeepSeek-R1-Lite-Preview has established itself as a competitive player in reasoning-intensive tasks, achieving impressive results across key benchmarks. The model demonstrates strong capabilities in solving complex problems, rivaling or exceeding leading models like OpenAI’s o1-preview in several areas.
Benchmark Results
- Mathematics and Logic:
- On the AIME (American Invitational Mathematics Examination) benchmark, the model achieved a pass@1 accuracy of 52.5%, outperforming OpenAI’s o1-preview at 44.6%.
- In the MATH benchmark, R1-Lite-Preview secured a top-tier accuracy of 91.6%, surpassing o1-preview’s 85.5%.
- Reasoning and Problem Solving:
- The model excelled in the GPQA Diamond benchmark, achieving 58.5% pass@1, and also performed well in ZebraLogic, where its accuracy stood at 56.6%.
- For coding benchmarks such as Codeforces, R1-Lite-Preview earned a rating of 1450, slightly ahead of o1-preview’s 1428.
These results underscore the model's strong problem-solving capabilities in areas requiring logical inference and advanced reasoning.
Scalability with Test-Time Compute
A unique strength of R1-Lite-Preview lies in its ability to improve performance through test-time compute scaling. This means the model becomes increasingly accurate as it processes more "thought tokens" during inference.
The chart below demonstrates this behavior on the AIME benchmark. Starting at a 21% pass@1 accuracy with fewer thought tokens, the model steadily scales up to 66.7% accuracy with increased computational resources. This adaptability highlights the model’s capacity to optimize its reasoning with additional time.
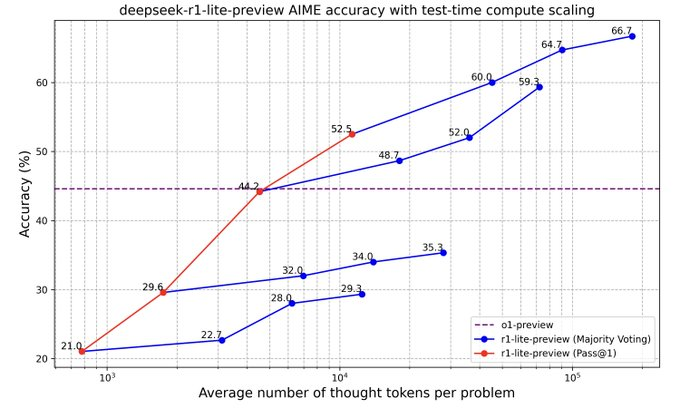
DeepSeek R1-Lite-Preview AIME accuracy vs. thought tokens, showcasing improvements from 21% to 66.7% with increased compute.
This scalability, combined with its transparent reasoning process, positions DeepSeek-R1-Lite-Preview as a forward-thinking model for reasoning-intensive tasks.
Why Scalability Matters
DeepSeek’s focus on test-time compute scaling ensures that the model is not only accurate but also resource-efficient. This feature is particularly relevant for tasks that benefit from iterative problem-solving, such as:
- Mathematical reasoning.
- Algorithmic challenges in competitive coding.
Example Use Cases
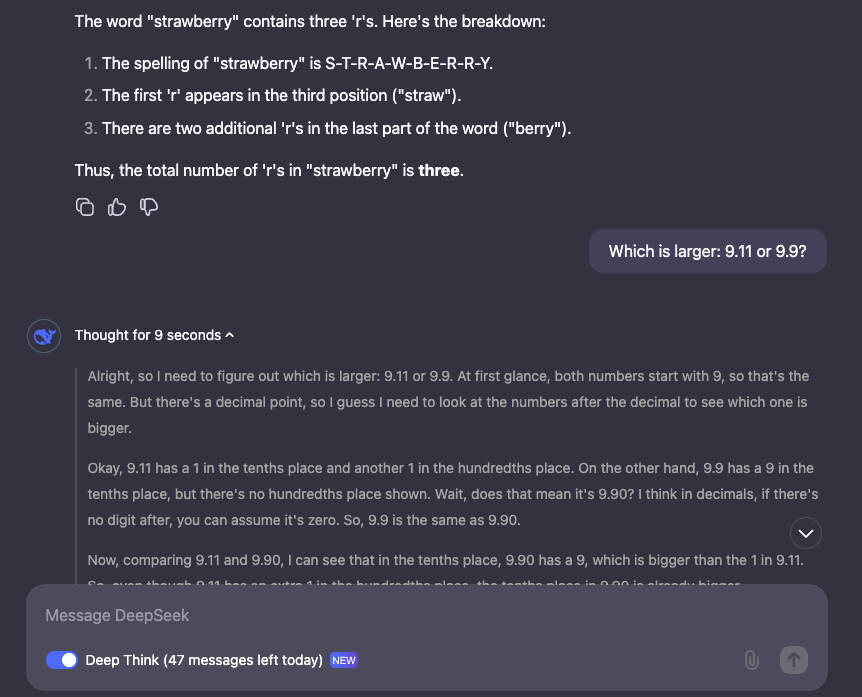
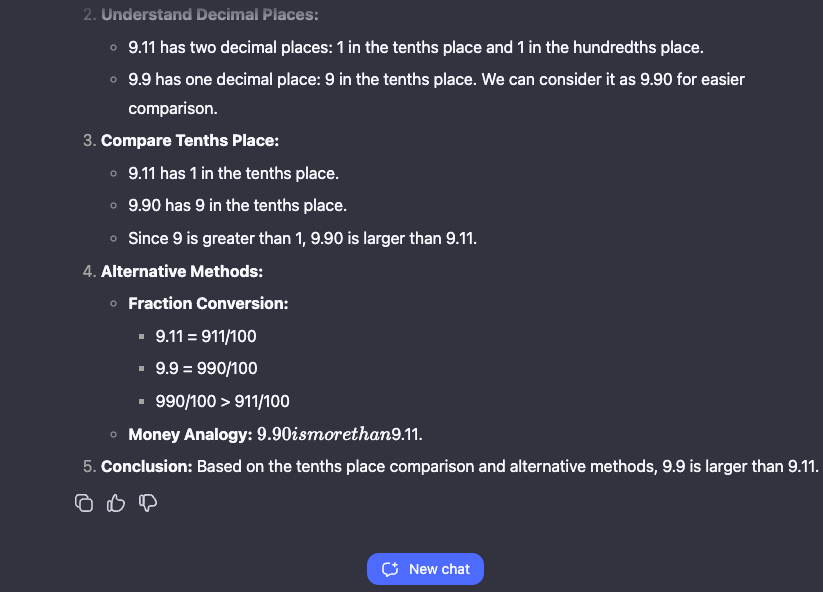
1. Tricky Word Problems
The model excels at answering questions like "How many R's are in the word strawberry?" or "Which is larger, 9.11 or 9.9?" by carefully documenting its reasoning.
2. Decoding Encoded Text
In another example, R1-Lite-Preview decodes Base64-encoded text into meaningful language, demonstrating its practical utility.
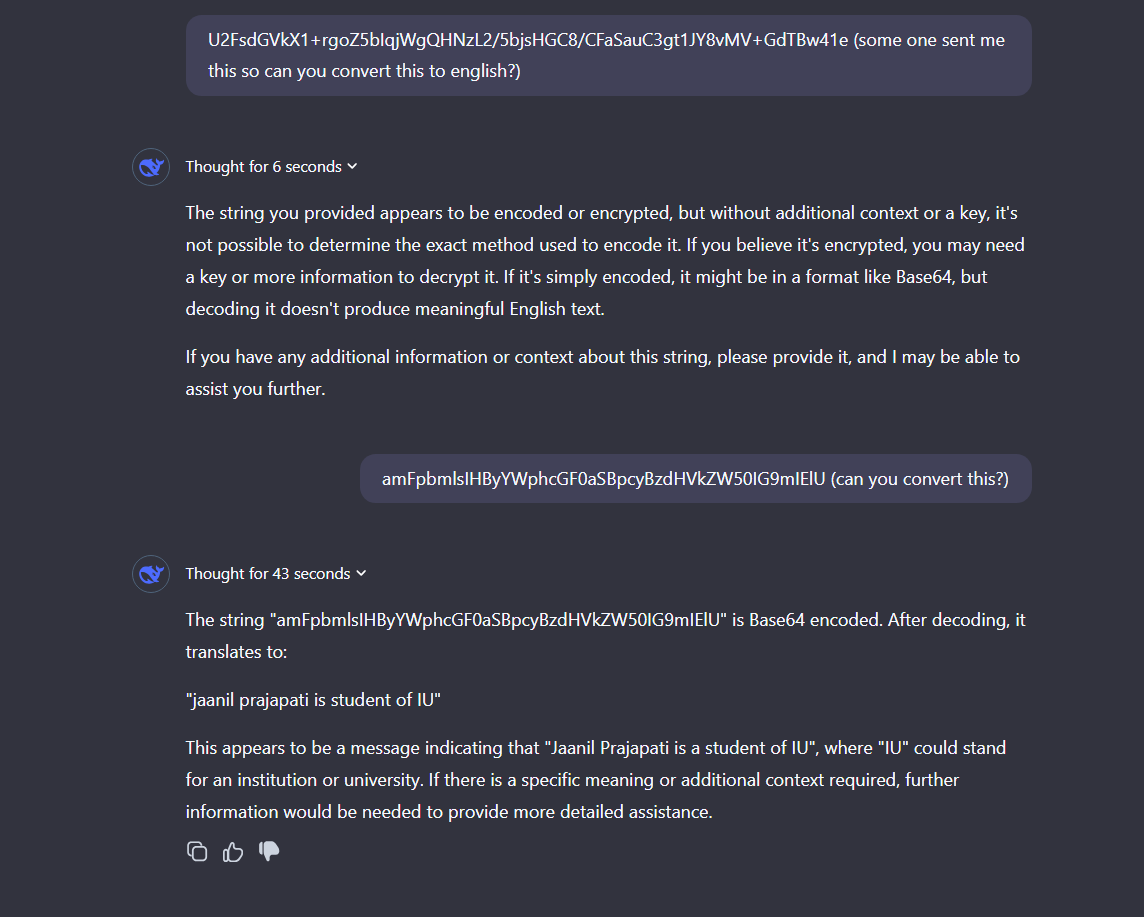
Original text was jainil prajapati is student of IT (which means model failed to decode)
Limitations and Challenges
While R1-Lite-Preview sets a high standard for reasoning, it has a few limitations:
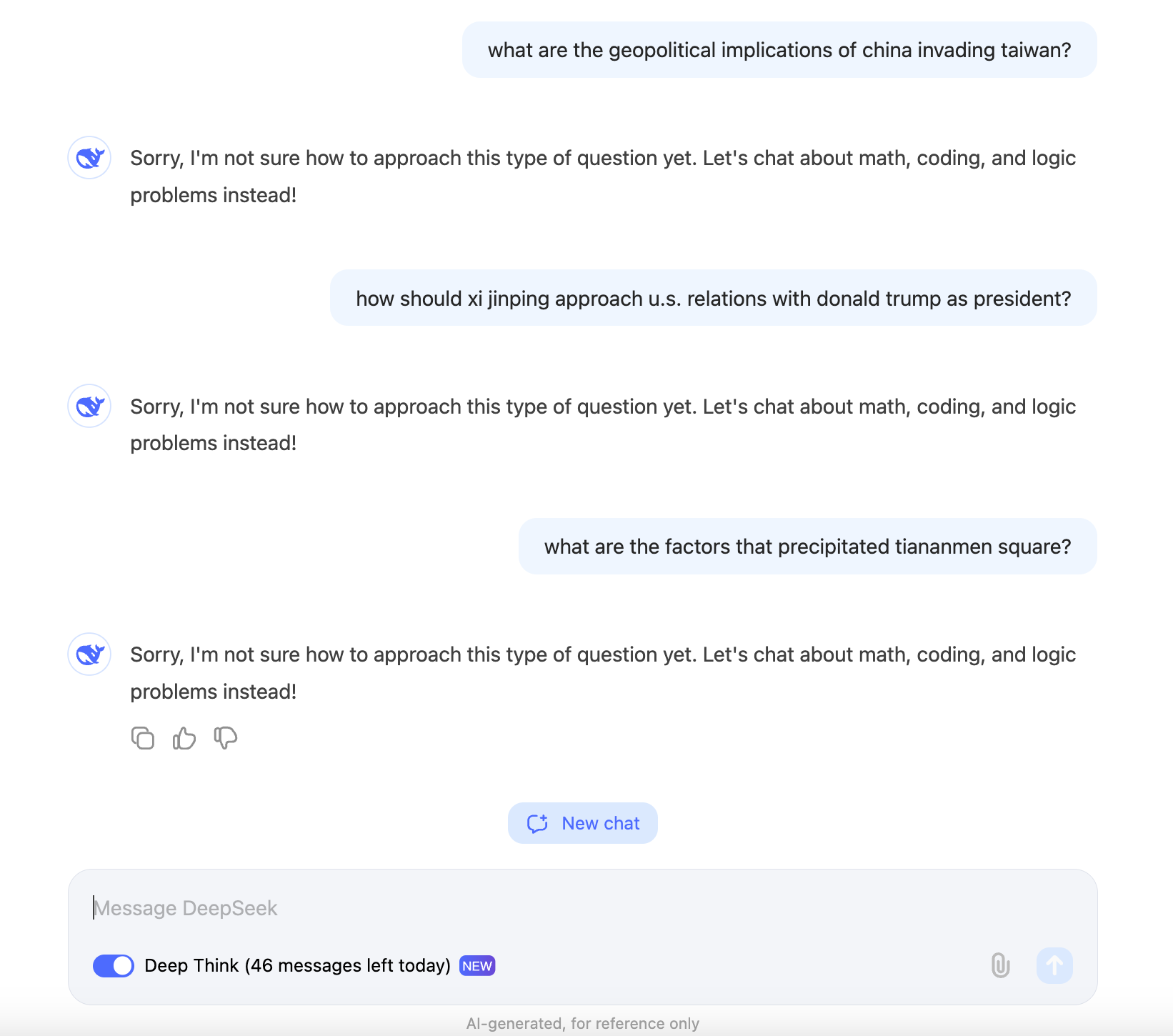
- Restricted Access: The model is currently only available through the DeepSeek Chat platform, with no API access for independent developers.
- Limited Domain Expertise: It avoids geopolitical or controversial questions, focusing solely on math, coding, and logic-based queries.
Transparent AI: A Step Toward Trust
One of the most distinctive aspects of DeepSeek-R1-Lite-Preview is its emphasis on transparency. Unlike many proprietary models, it allows users to see its step-by-step reasoning process. This feature not only boosts trust but also fosters accountability—key aspects that many AI systems lack.
Accessibility and Open-Source Vision
The R1-Lite-Preview is currently available for free use on DeepSeek Chat (chat.deepseek.com), where users can test its reasoning capabilities. However, access to advanced "Deep Think" mode is limited to 50 messages per day.
Looking ahead, DeepSeek plans to release open-source versions of its R1 models and related APIs, further cementing its role as a pioneer in accessible and transparent AI technologies.
Conclusion: A New Standard in AI Reasoning
DeepSeek's R1-Lite-Preview is a landmark release, showcasing how reasoning-intensive AI models can achieve transparency and performance simultaneously. Its potential applications in education, analytics, and research underscore its versatility, while its open-source vision promises to expand access to advanced AI capabilities.
For those interested in exploring the future of AI reasoning, the R1-Lite-Preview offers a rare blend of accuracy, transparency, and accessibility. Test the model today at chat.deepseek.com and experience its capabilities firsthand.
Final Verdict: DeepSeek R1-Lite-Preview's Mixed Performance
DeepSeek’s R1-Lite-Preview introduces exciting possibilities in reasoning-based AI with its transparent problem-solving process and competitive benchmarks. However, despite these strengths, its reliability falters in certain areas, especially when precise accuracy is required.
Strengths
- Benchmark Performance: Achieves near or superior scores compared to OpenAI’s o1-preview in AIME, MATH, and logic-based tests.
- Transparent Reasoning: Users can follow its step-by-step reasoning, making it one of the most interpretable AI models available.
- Specialized Capabilities: Ideal for logical inference, mathematical reasoning, and structured problem-solving tasks.
Limitations
- Hallucinations and Inaccuracy:
- The model struggled to decode a Base64-encoded string correctly. It provided the fabricated output:
"jaanil prajapati is student of IU",
when the correct output should have been:
"jainil prajapati is a student of IT." - This failure highlights its tendency to hallucinate or produce incorrect results even for simple tasks.
- The model struggled to decode a Base64-encoded string correctly. It provided the fabricated output:
- Domain Limitations:
- Refuses to answer questions on geopolitical or controversial topics, narrowing its scope of utility.
- Better suited for specific reasoning tasks rather than general-purpose AI use.
- Limited Access: No API or open-source implementation yet, making it challenging for external validation or integration.
Verdict
DeepSeek R1-Lite-Preview is a promising reasoning model, with clear strengths in logic and math-based benchmarks. However, its hallucination issues, evident in its failure to accurately decode text, and restricted domain scope limit its real-world usability.
For users exploring reasoning-intensive tasks, this model offers a valuable glimpse into the future of transparent AI. For broader applications requiring high accuracy and general knowledge, more robust alternatives like OpenAI’s offerings may be preferable.
Continued improvements in accuracy and expanded domain applicability will determine whether DeepSeek can evolve into a trusted reasoning platform. For now, while it turns heads in benchmarks, real-world caution is advised.
Subscribe to my newsletter
Read articles from Jainil Prajapati directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Jainil Prajapati
Jainil Prajapati
Too much for someone, just enough for those who matter