🤖The Evolution of NLP: From RNNs to Transformers
 Tahmid Choudhury
Tahmid ChoudhuryTable of contents
- ☀️Setting the Stage: Early NLP Models and Their Limitations
- 🛑RNNs and Their Limitations: Understanding Sequential Data
- 🧠Attention Mechanism: A New Way to Focus on Important Information
- ✨Enter the Transformer: A Paradigm Shift in NLP
- 🛠️The Transformer Architecture: An In-Depth Overview
- 💡Why Transformers Revolutionized NLP

Natural Language Processing (NLP) has come a long way in recent years, with groundbreaking advancements in understanding and generating human language. From Recurrent Neural Networks (RNNs) to Transformer architectures like BERT and GPT, NLP models have evolved to handle complex tasks with high accuracy. This journey highlights key innovations that made these advancements possible. Let’s walk through this evolution, step by step.
☀️Setting the Stage: Early NLP Models and Their Limitations
Before the deep learning era, NLP relied on statistical methods like n-grams and Hidden Markov Models (HMMs). These models could process language but struggled with long-range dependencies, such as understanding the connection between words at the beginning and end of sentences. As a result, they fell short on tasks requiring nuanced language understanding.
The Need for Better Sequence Modeling
The introduction of neural networks marked a turning point.
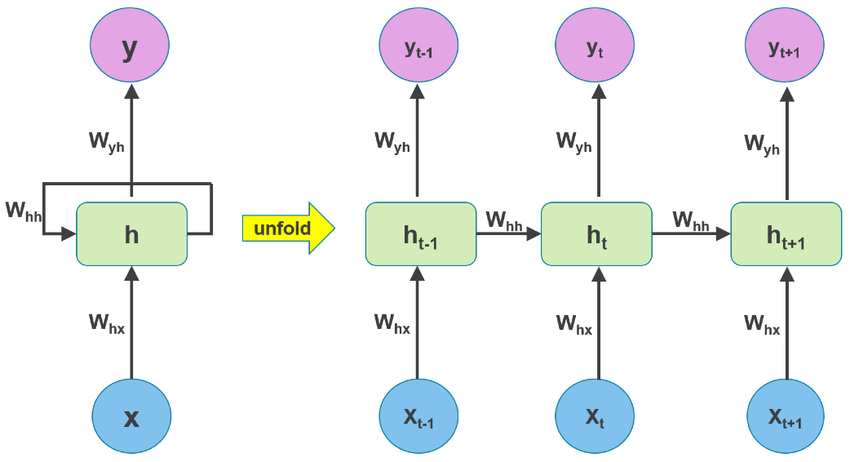
Recurrent Neural Networks (RNNs) were designed to handle sequences by maintaining an internal memory, allowing them to process language in a more context-aware manner. This was especially useful in tasks like sentiment analysis and sequence prediction.
🛑RNNs and Their Limitations: Understanding Sequential Data
RNNs were promising but had a significant limitation: they struggled with long-term dependencies due to the vanishing gradient problem. This limitation made it hard for RNNs to retain context in long sentences or paragraphs.
LSTM and GRU Architectures to the Rescue
To address this, researchers introduced advanced RNNs, like Long Short-Term Memory (LSTM) networks and Gated Recurrent Units (GRUs). These architectures were designed with memory cells and gates, allowing models to selectively remember or forget information. This enhancement enabled more robust language processing, but RNNs still lacked parallelization, making them slow for large datasets.
🧠Attention Mechanism: A New Way to Focus on Important Information
The attention mechanism, introduced in 2014, was a breakthrough that allowed NLP models to focus on key parts of a sentence or document. Rather than relying on sequential processing, attention could identify which words in a sentence were more relevant to each other.
Example: Translating “The cat sat on the mat”
In machine translation, attention helped the model focus on individual words and their contextual meanings in the sentence, making translations more accurate and natural-sounding.
✨Enter the Transformer: A Paradigm Shift in NLP
The Transformer model, introduced in 2017 by Google in the Attention is All You Need paper, discarded RNNs altogether and relied solely on the attention mechanism. This new architecture enabled simultaneous processing of words, resulting in a faster, more scalable model.
How Transformers Work: Key Components
Transformers consist of two main components:
Self-Attention Mechanism: Instead of sequential processing, self-attention allows Transformers to consider relationships between all words at once, capturing long-range dependencies easily.
Positional Encoding: Since Transformers process words in parallel, they use positional encoding to retain the order of words, which is essential for understanding the syntax and structure of language.
This design allowed Transformers to achieve parallelization, making them faster and more efficient, which was revolutionary for NLP tasks like translation and text summarization
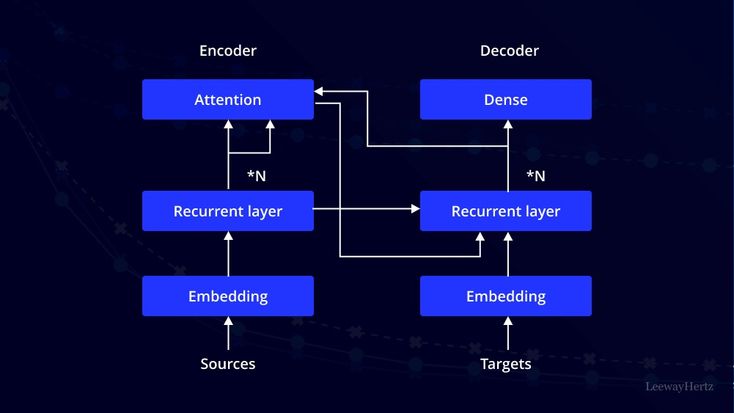
🛠️The Transformer Architecture: An In-Depth Overview
The Transformer architecture was originally devised for tasks like machine translation. It uses self-attention to convert input sequences into output sequences without needing RNNs or convolutions. Transformers are structured around an encoder-decoder framework, allowing them to efficiently learn dependencies between tokens in a sequence.
Imagine a Transformer model as a black box for language translation: given an English sentence as input, it outputs a translation in another language, such as Spanish.
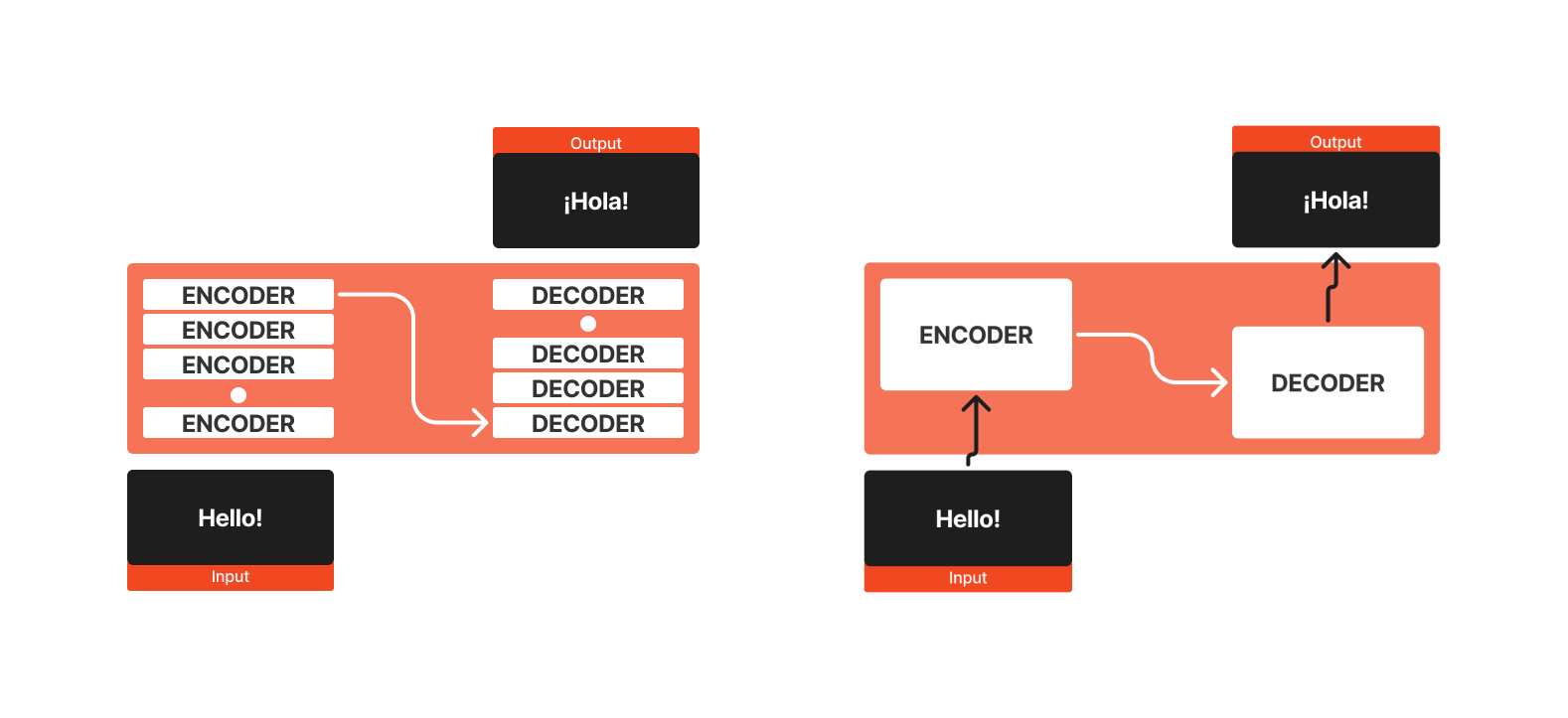
The Encoder-Decoder Structure
The encoder and decoder are both stacks of layers, each following the same structure. The original Transformer model includes 6 layers each for the encoder and decoder, but modern adaptations may vary. Here’s a breakdown of how each component works.
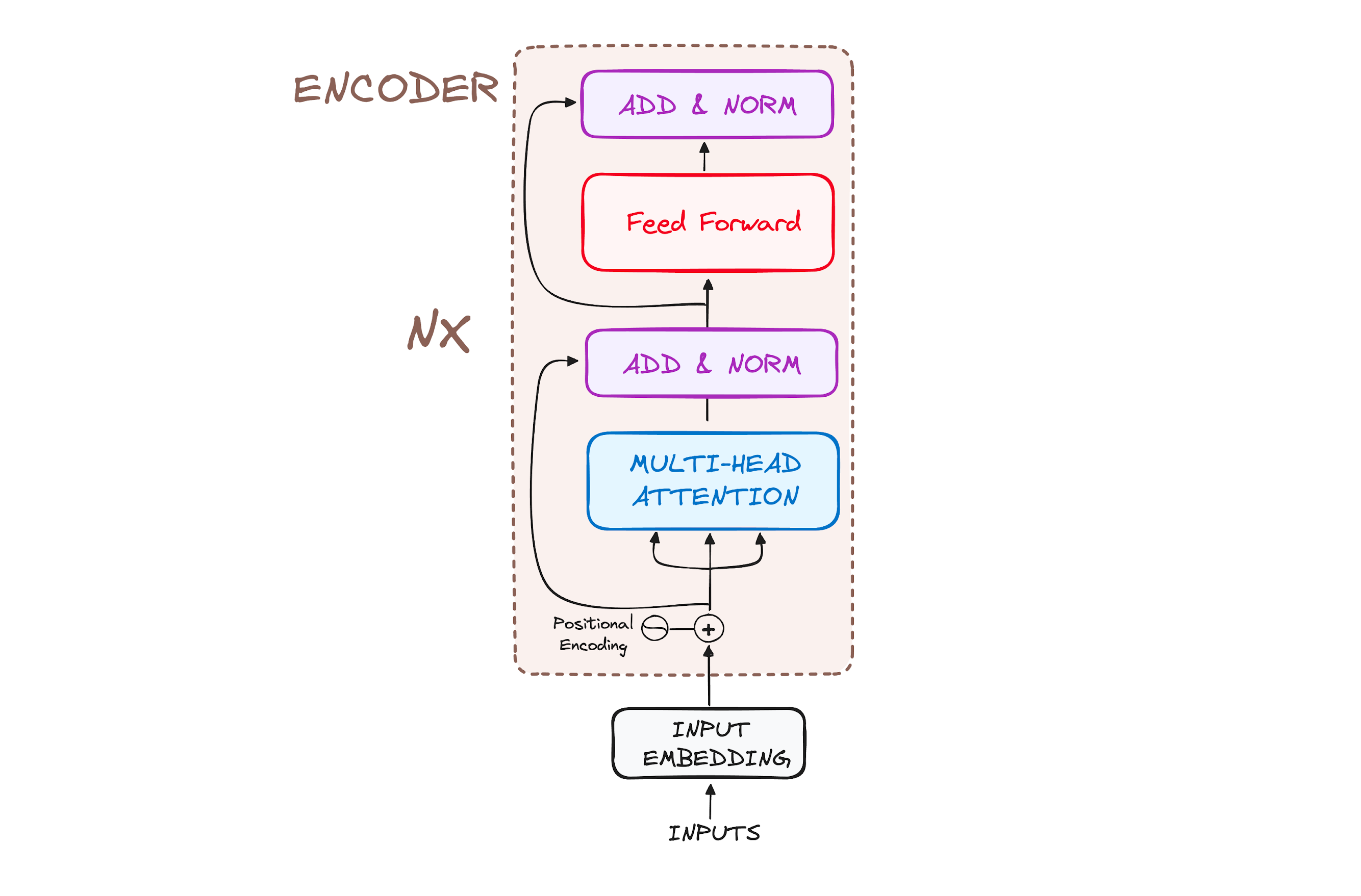
The Encoder Workflow
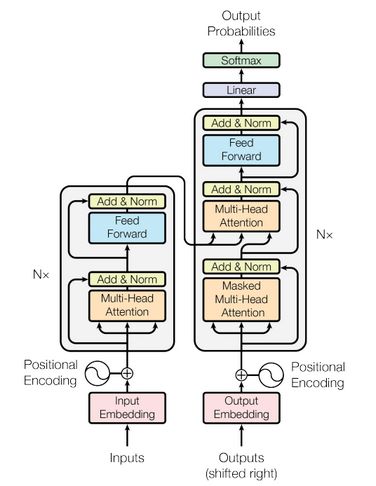
The encoder transforms input tokens into contextualized representations. Unlike earlier models that processed tokens one at a time, the encoder in Transformers captures the entire sequence context in one go. Each encoder layer has three primary steps: input embeddings, positional encoding, and stacked encoder layers with multi-head self-attention.
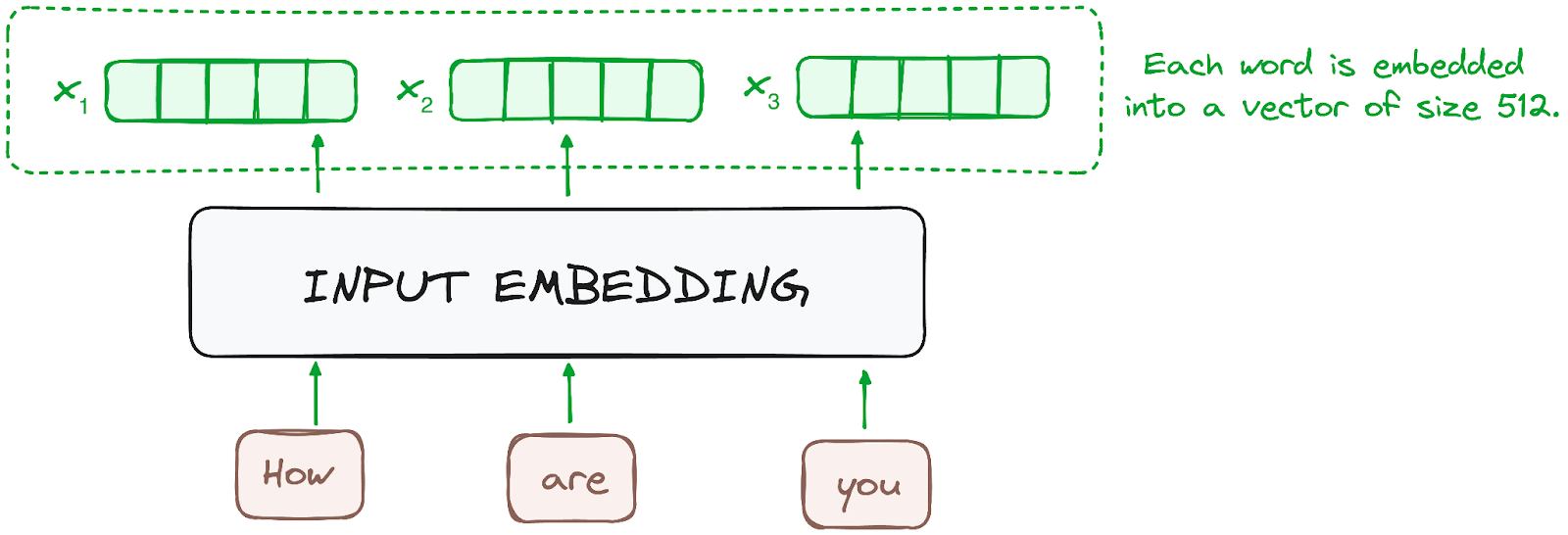
Step 1: Input Embeddings
Each token in the input sequence is converted into a vector via embedding layers. This process captures the semantic meaning of tokens as numerical vectors.
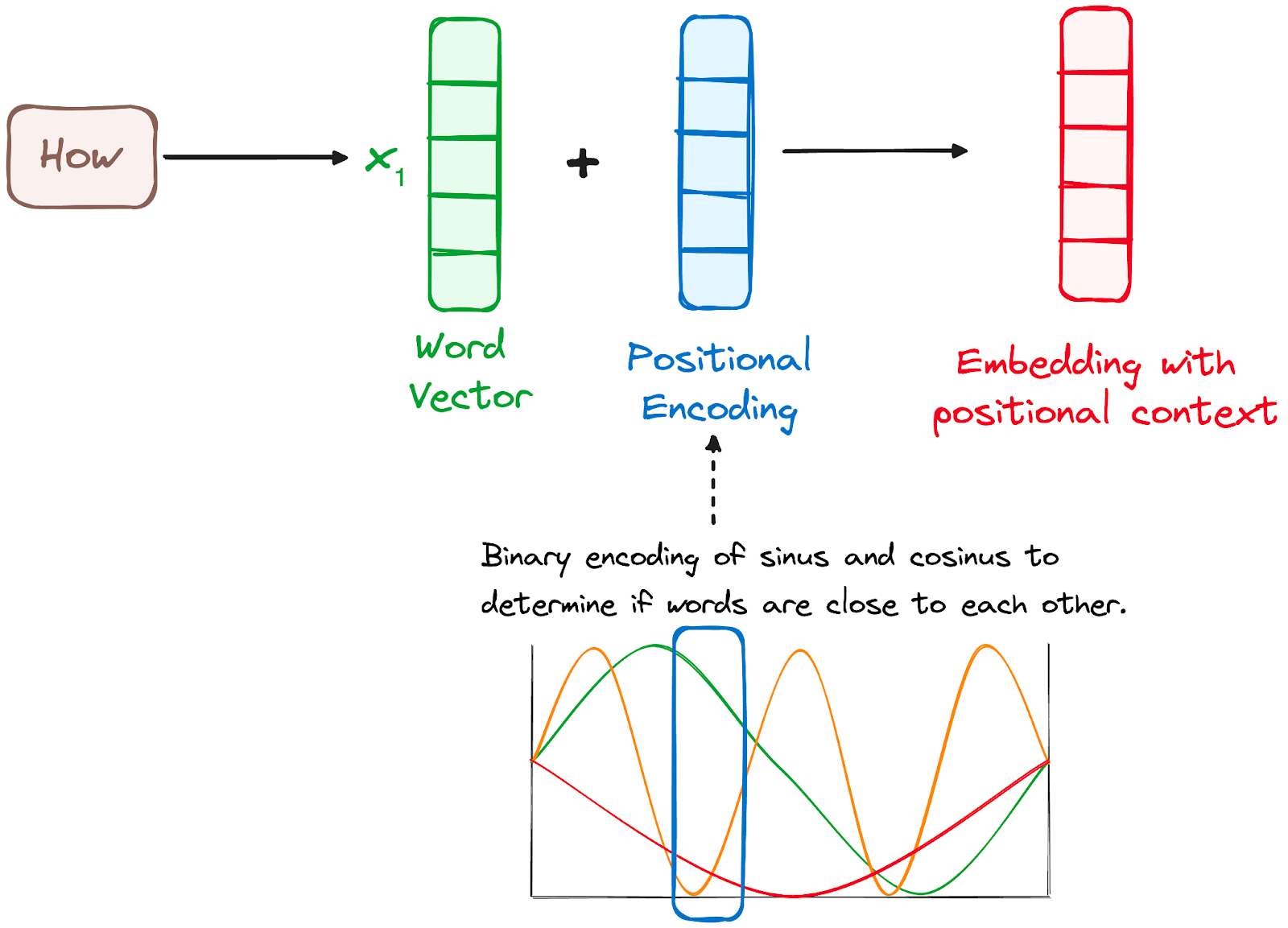
Step 2: Positional Encoding
Transformers have no inherent mechanism for understanding the order of tokens. Positional encoding addresses this by adding positional information to embeddings. Using a combination of sine and cosine functions, positional encodings are generated to provide sequence information for any length of input.
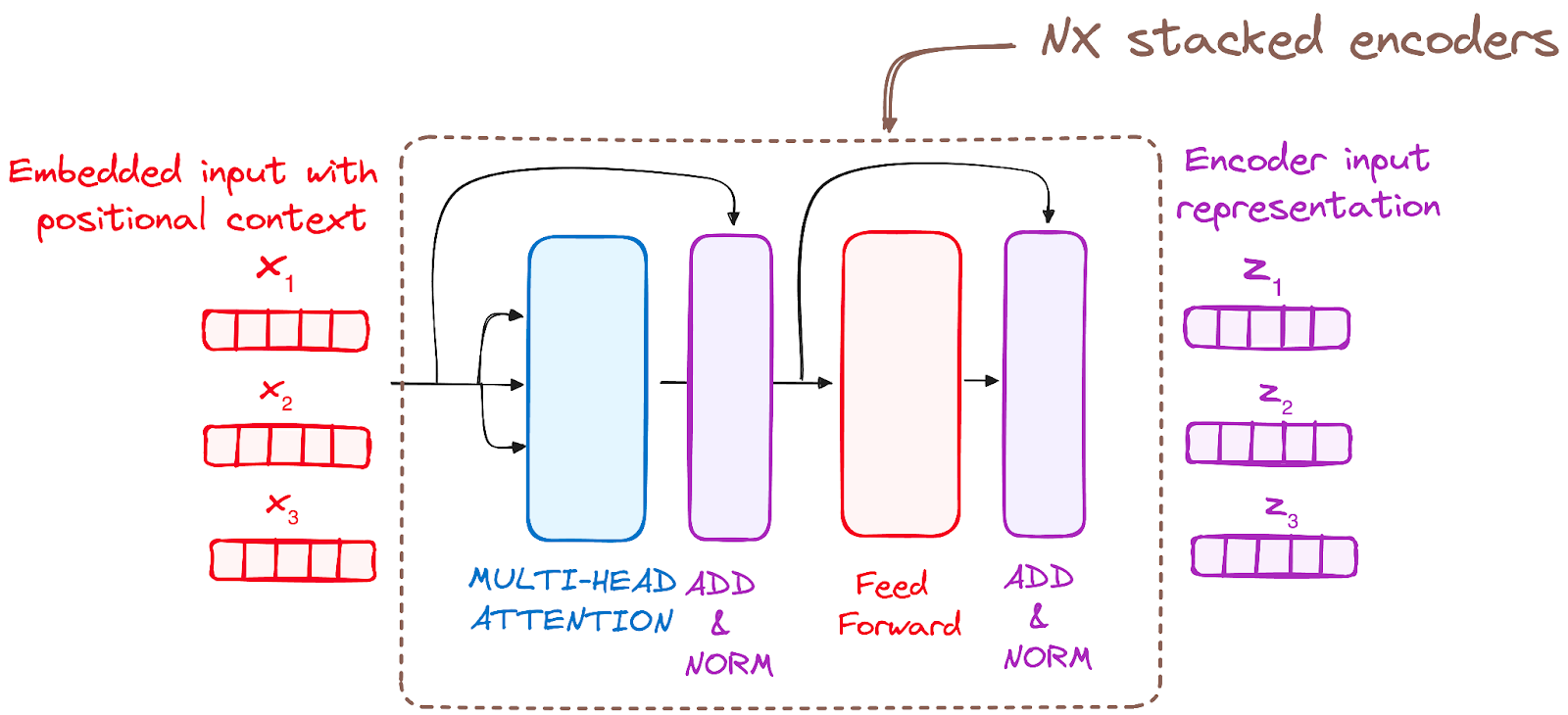
Step 3: Stack of Encoder Layers
The encoder stack consists of multiple identical layers, each containing two primary sub-modules:
Multi-Headed Self-Attention Mechanism
Feed-Forward Neural Network
Each sub-layer includes residual connections and layer normalization to improve model stability and prevent vanishing gradients.
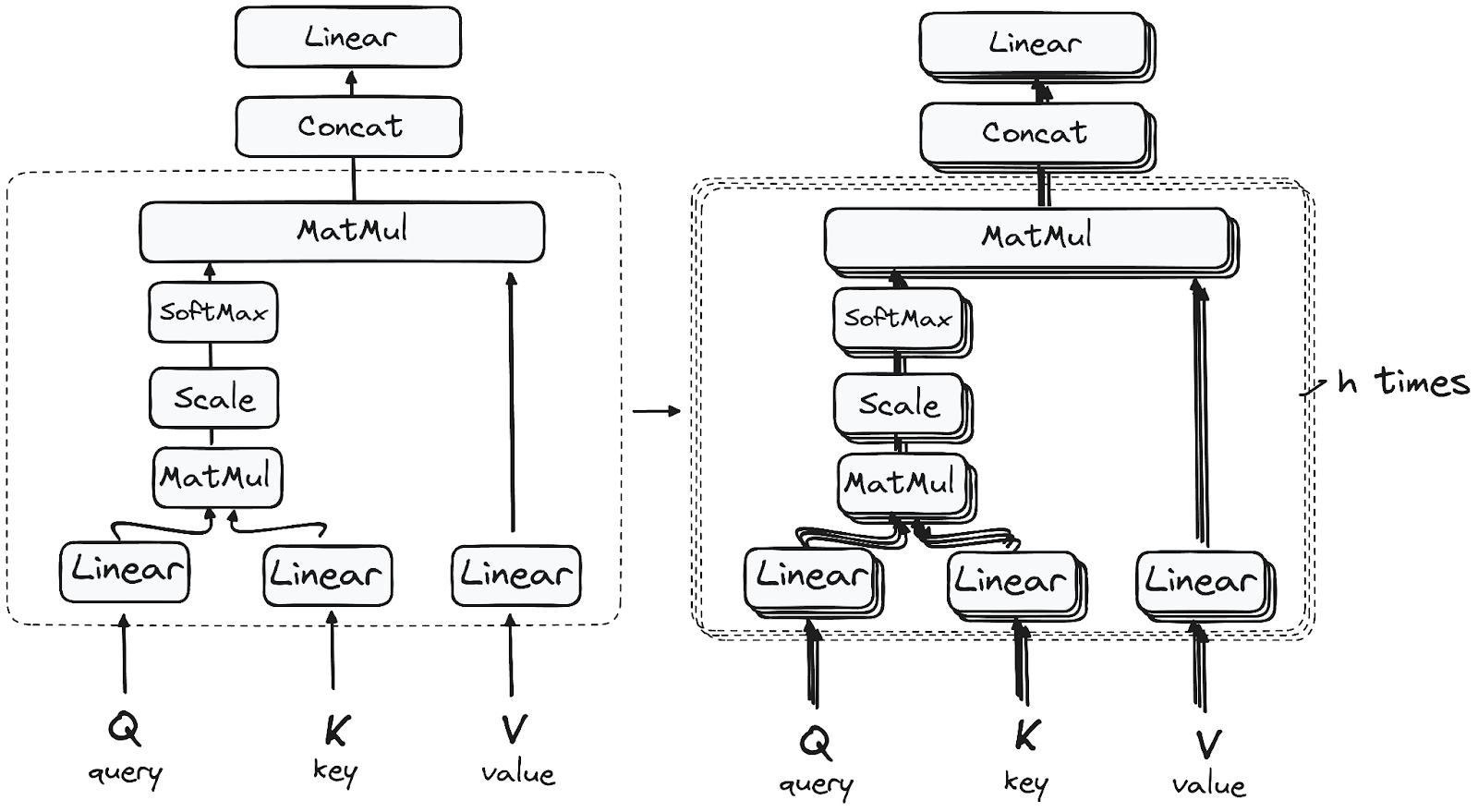
Step 3.1: Multi-Headed Self-Attention Mechanism
Self-attention allows each word to relate to every other word in the sequence, creating a context-rich representation. Here’s a closer look at how it works:
Queries, Keys, and Values: The model assigns three vectors—query, key, and value—to each token in the input sequence.
Matrix Multiplication: The query and key vectors are multiplied to produce a score matrix, which determines the relevance of tokens to each other.
Scaling and Softmax: The score matrix is scaled down for stability and passed through a softmax layer to generate attention weights.
Weighted Sum: Each token’s value vector is multiplied by its respective attention weight, creating an output vector with focused attention.
This process is repeated in parallel across multiple heads, each focusing on different relationships within the sequence. The outputs are then concatenated and passed through a linear layer.
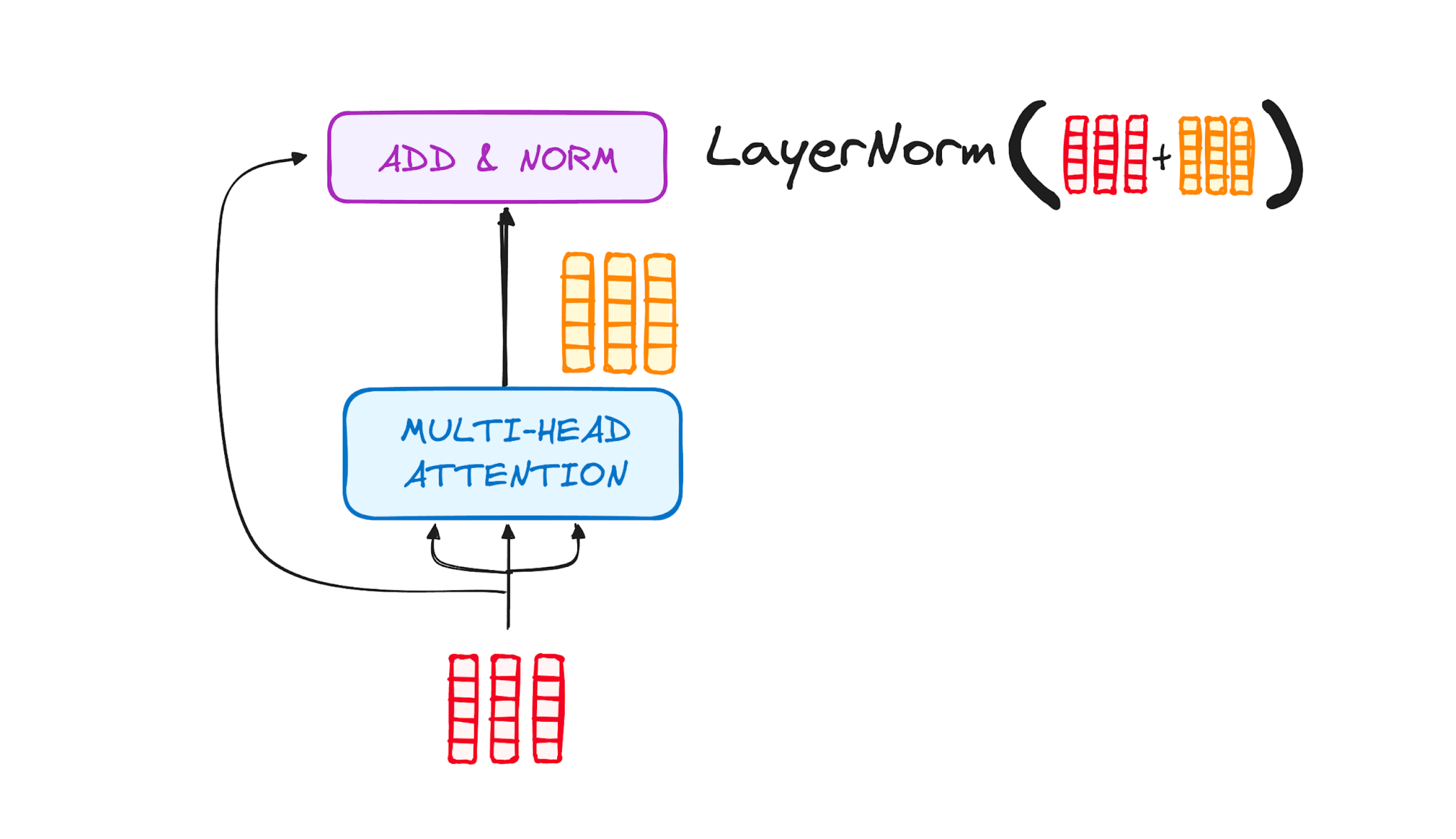
Step 3.2: Normalization and Residual Connections
Residual connections help mitigate the vanishing gradient issue, while layer normalization stabilizes training. This process is repeated after each sub-layer.
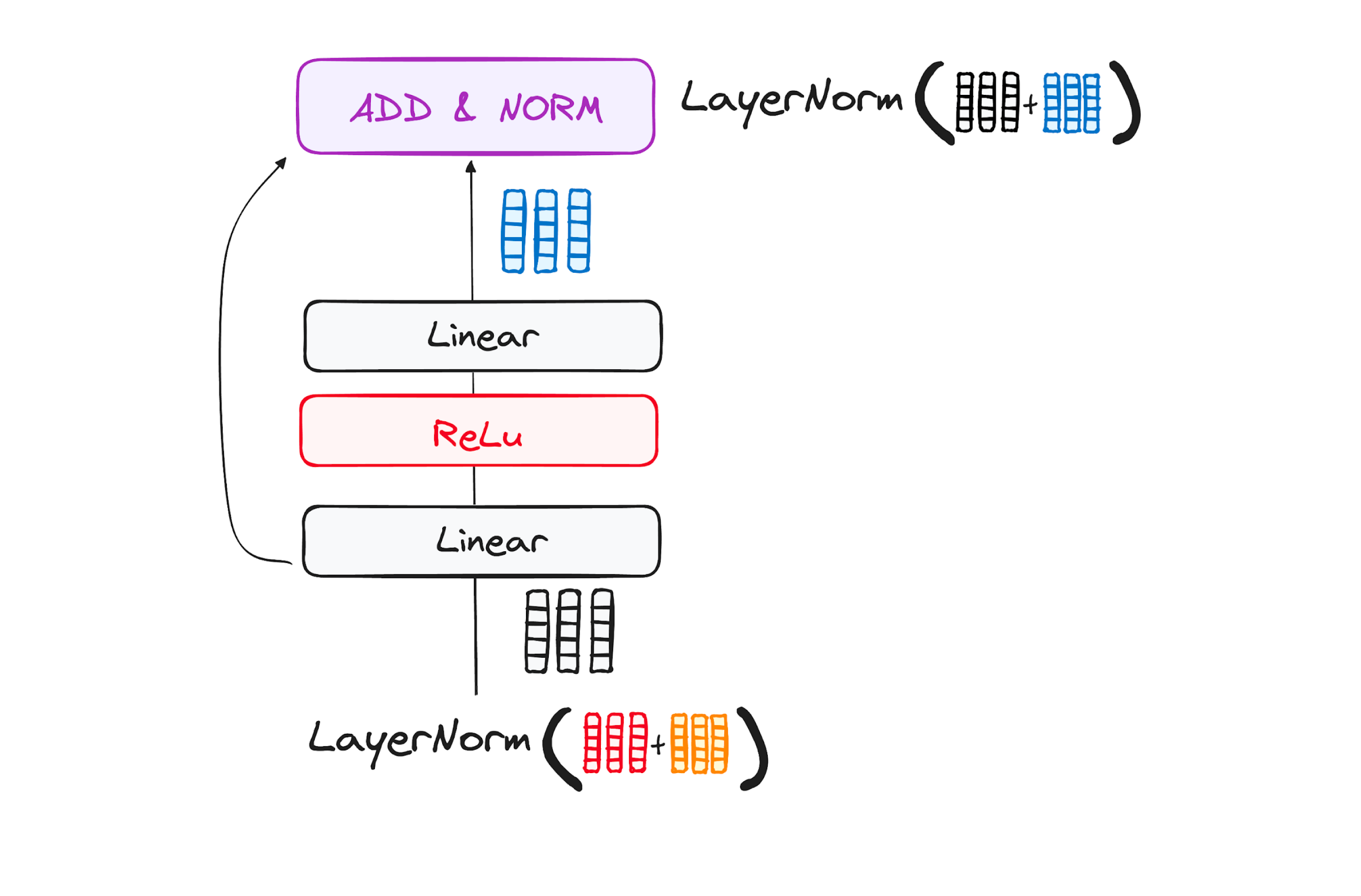
Step 3.3: Feed-Forward Neural Network
The output from the self-attention layer passes through a two-layer feed-forward network, with a ReLU activation in between. This layer further refines the token representation before passing it to the next encoder layer.
The Decoder Workflow
The decoder generates the output sequence, step-by-step, based on both its own input sequence (previously generated tokens) and the encoder’s output.
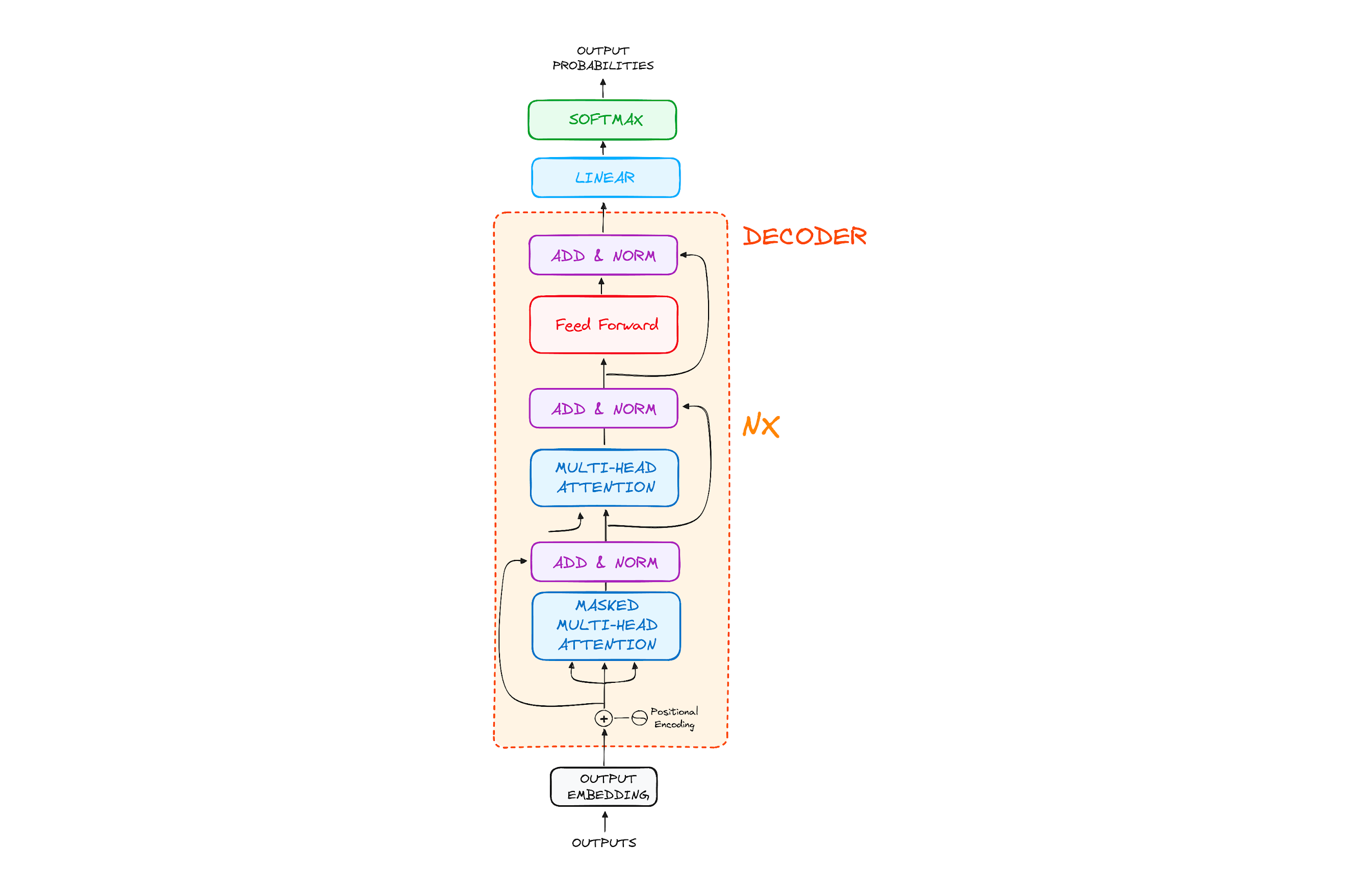
Step 1: Output Embeddings
The decoder also begins with embedding the input sequence, where it transforms tokens into vectors.
Step 2: Positional Encoding
Just like the encoder, positional encoding is applied to provide sequence information.
Step 3: Stack of Decoder Layers
Each decoder layer contains three main sub-modules:
Masked Multi-Head Self-Attention
Encoder-Decoder Attention (Cross-Attention)
Feed-Forward Neural Network
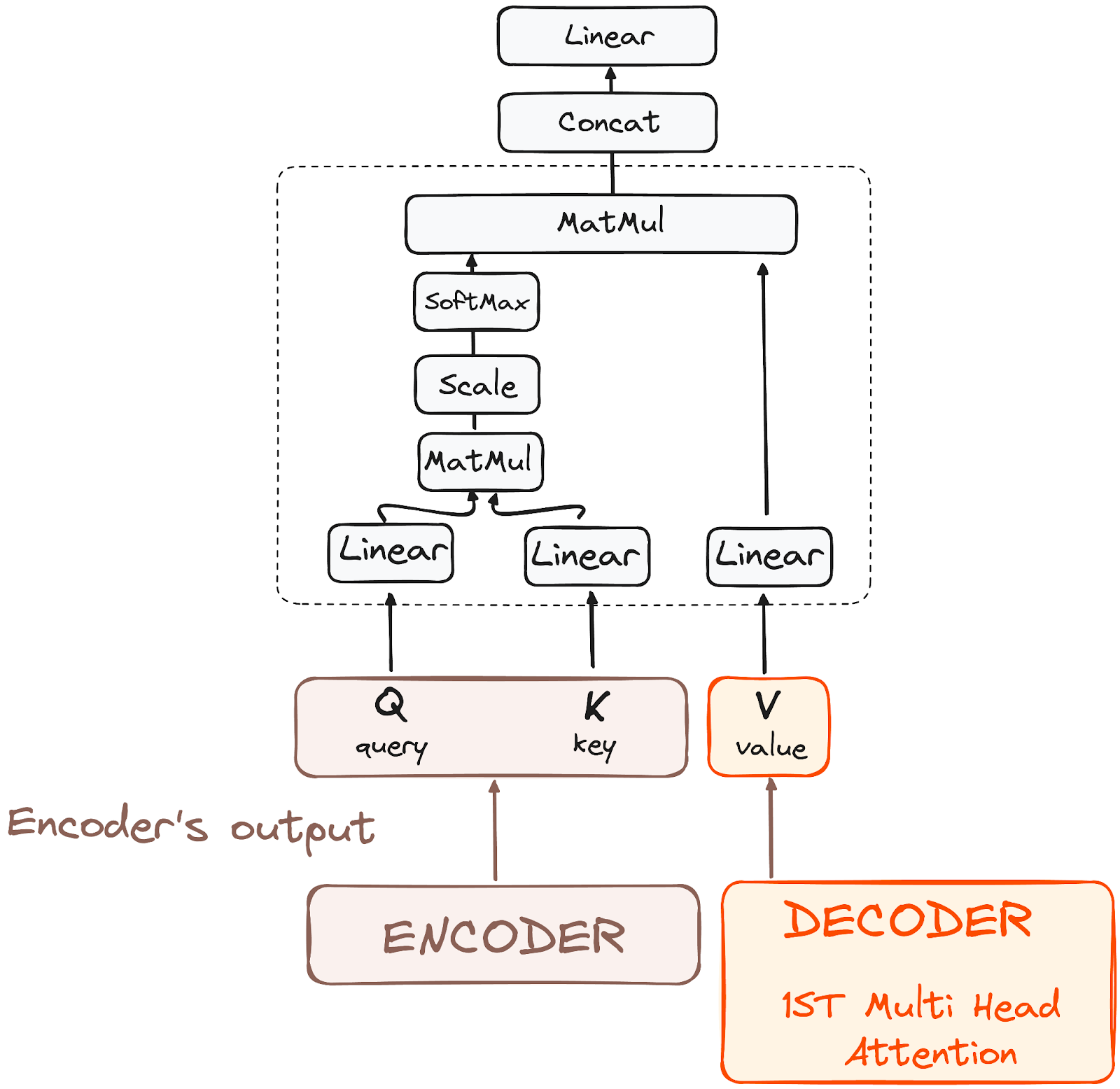
Step 3.1: Masked Multi-Head Self-Attention
Masked self-attention prevents the decoder from “peeking” at future tokens, allowing it to focus only on tokens generated so far.
Step 3.2: Encoder-Decoder Cross-Attention
This layer enables the decoder to focus on relevant parts of the encoder’s output, aligning the source language with the target language. Here, the queries come from the previous decoder layer, while keys and values come from the encoder’s output.
Step 3.3: Feed-Forward Neural Network
Each decoder layer has its own feed-forward network, applied identically to all positions.
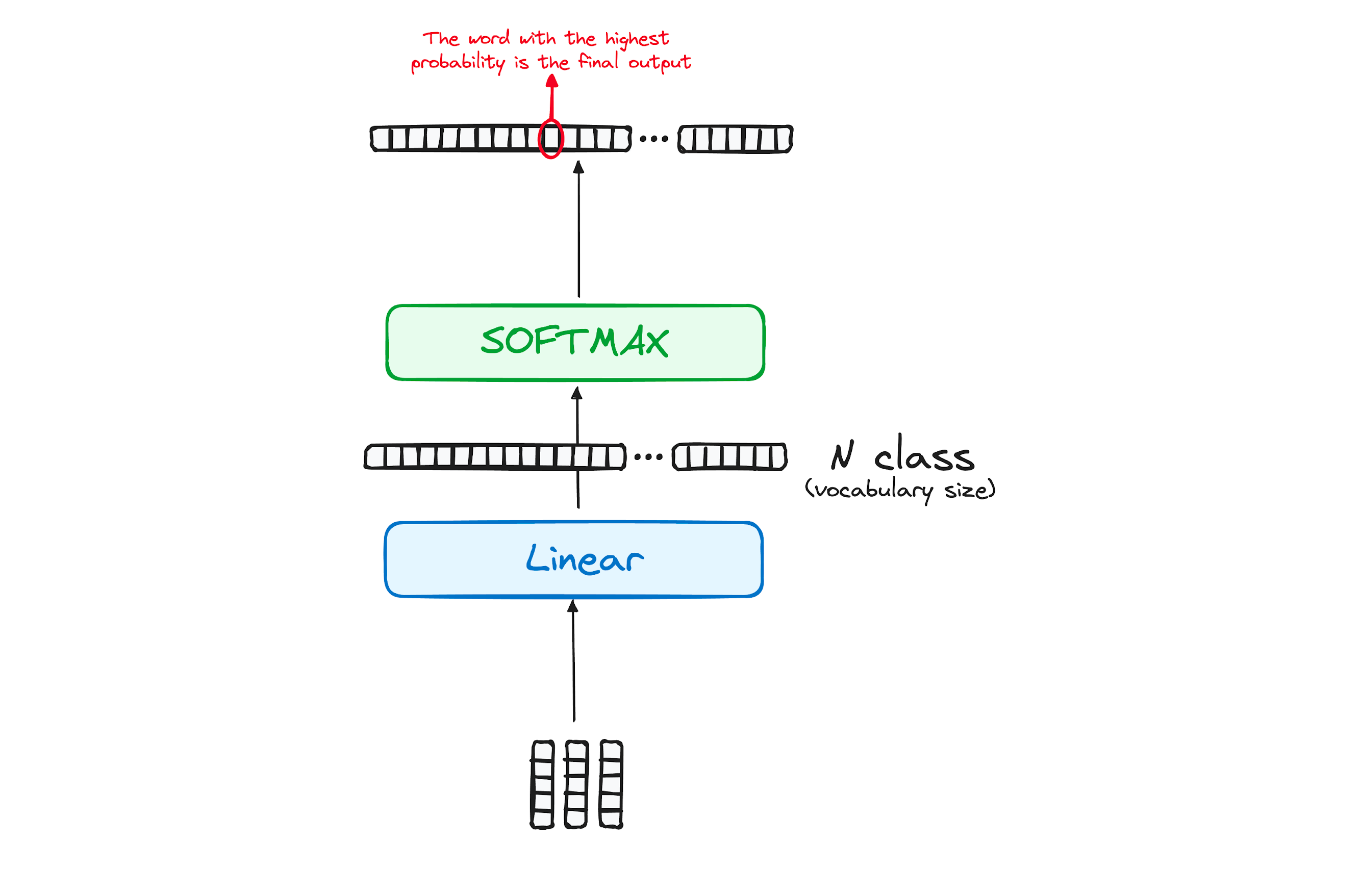
Final Layer: Linear and Softmax
A final linear layer transforms the decoder output into logits, and a softmax layer converts these logits to probabilities, allowing the model to predict the next word in the sequence.
💡Why Transformers Revolutionized NLP
The self-attention mechanism allows Transformers to capture dependencies across sequences in a single step, bypassing the limitations of sequential models like RNNs. By enabling parallel processing, Transformers significantly reduce training times and scale efficiently, making them the go-to architecture for modern NLP tasks.
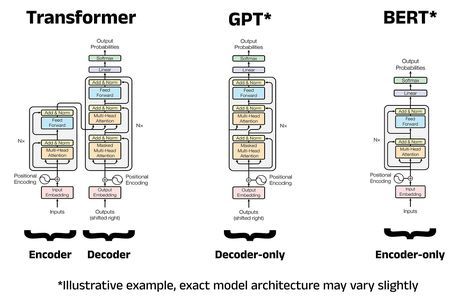
✨BERT and GPT: Revolutionizing NLP Tasks with Pre-trained Models
The Transformer architecture paved the way for models like BERT (Bidirectional Encoder Representations from Transformers) and GPT (Generative Pre-trained Transformer), which set new standards for NLP performance. Here’s how each of these models works:
BERT: Learning Context from All Directions BERT, developed by Google in 2018, processes language bidirectionally, meaning it considers both the left and right context of each word. This feature allows BERT to understand meaning with a higher level of accuracy.
Masked Language Modeling (MLM): BERT hides random words in a sentence and learns to predict them based on context, training the model to understand relationships between words.
Next Sentence Prediction (NSP): This task helps BERT understand the connection between sentences, which is especially useful for tasks like question answering.
GPT: Generating Language with a Left-to-Right Approach The GPT models of OpenAI are interested in generating coherent text. They process the language in a one-way, left-to-right manner. Even though GPT does not understand the language in the way that BERT understands, it was designed with such efficiency in text generation tasks.
🛡️The Impact of Transformer Models on NLP Applications
Transformer-based models like BERT and GPT have had a profound impact on a range of NLP tasks:
Question Answering: By learning bidirectional context, BERT has set new benchmarks for accurately answering questions based on given passages.
Text Generation: GPT-3, with 175 billion parameters, can generate human-like text, write articles, and even assist in creative writing.
Summarization and Translation: Both BERT and GPT have improved the accuracy and fluidity of machine-generated summaries and translations.
❓What’s Next? The Future of NLP with Transformers
As Transformer-based models continue to evolve, researchers are focusing on several key areas:
Efficiency: Large Transformer models are resource-intensive. Innovations like DistilBERT and TinyBERT aim to make NLP models smaller and more efficient without sacrificing too much accuracy.
Multimodal Models: There is increasing interest in combining text with other types of data, such as images and audio, to create richer, multimodal models that can understand context across different media.
🎯Conclusion: A Bright Future for NLP
The transition from RNNs to Transformers has changed NLP from its roots. Transformer models opened capabilities that were once too fantastic, allowing everything from very realistic chatbots to AI translation of languages.
As NLP research continues to advance, Transformer-based models will only grow more powerful, versatile, and accessible, bringing smarter, more intuitive applications ever closer to seamless human-AI interaction.
Subscribe to my newsletter
Read articles from Tahmid Choudhury directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by