Reaching Design Consensus on CKB Script Execution Model
 Cryptape
Cryptape
This post was originally a talk delivered at Common Knowledge Conference (CKCON) 2024 in Chiang Mai, Thailand. Xuejie Xiao is a blockchain engineer at Cryptape working on CKB. He's the lead developer of CKB Virtual Machine.
Morning! Consensus is an extremely popular term in our industry; sometimes I feel like we have abused this word. Today, I'm going to talk about design consensus, which is slightly different from blockchain consensus. While machines talk to reach blockchain consensus, design consensus is reached among people.
Back in the early days, we designed and implemented CKB-VM and the whole CKB Script execution model. While CKB-VM strictly follows the RISC-V spec, CKB's Script execution model is a more subjective topic. It is designed with our own likes and preferences—mostly my personal likes and preferences. We all have preferences, and lately, I've found that some CKB features are not really used in the way they were designed in the first place. I'm not saying those CKB features are used in the wrong way. It really is a worthwhile time to tell the differences and raise discussions.
Hash_Type: The Ignored Key to Identifying RISC-V Code
The first thing to discuss is the hash_type field in the Script data structure.
As you might already know, each CKB Cell has a mandatory Lock Script and an optional Type Script. When a CKB transaction is committed on-chain, both the Lock Script and Type Script from each input Cell will be executed via CKB-VM. In addition, the Type Script from each output Cell will also be executed. The transaction is only valid when all those Scripts terminate with 0, or the success return code.
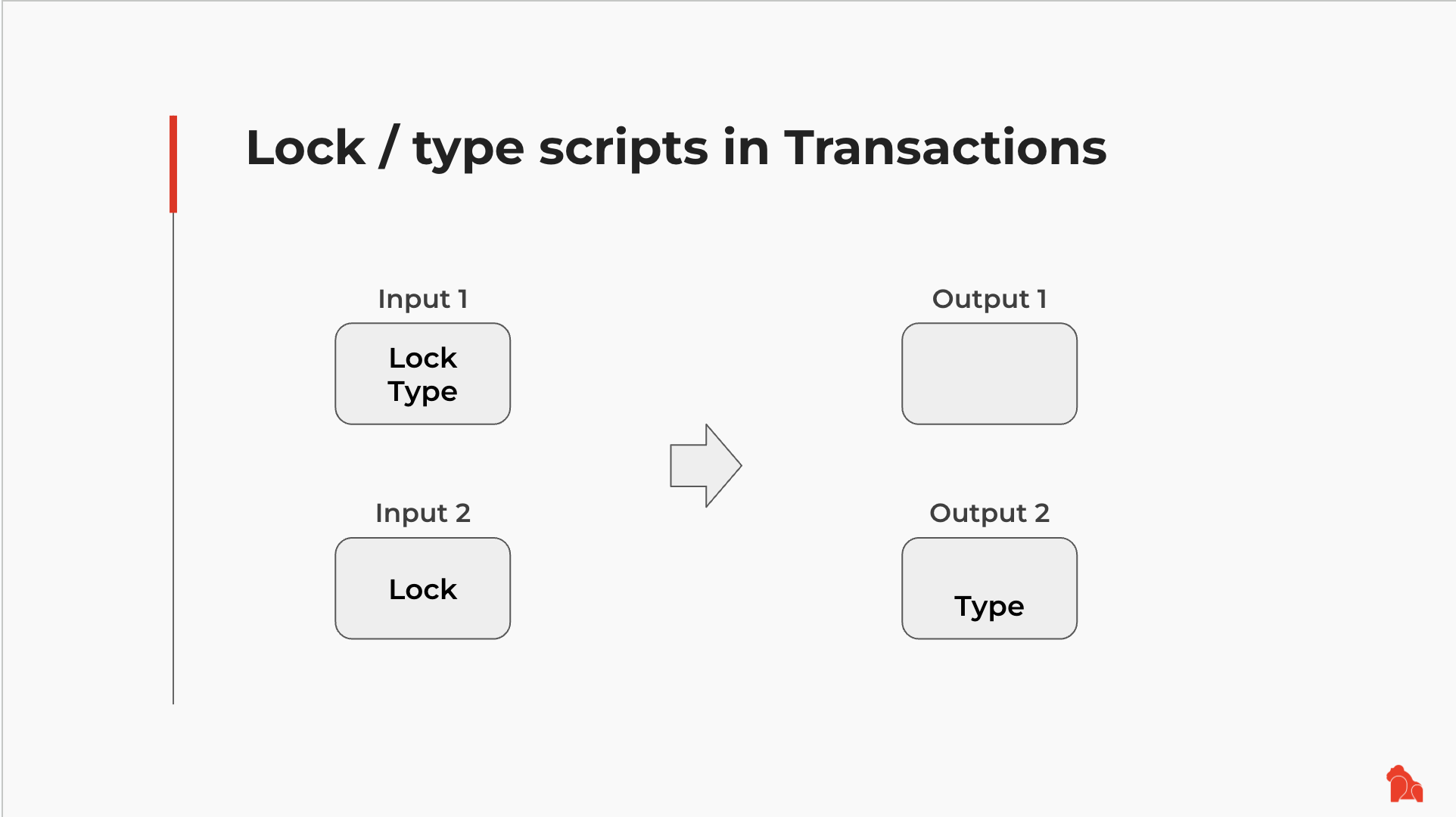
Both lock and Type Script have exactly three fields: code_hash, hash_type, and args, as shown below:
table Script {
`code_hash`: Byte32,
`hash_type`: byte,
args: Bytes,
}
The args field is not our focus today. I want to talk about code_hash and hash_type, specifically the hash_type field.
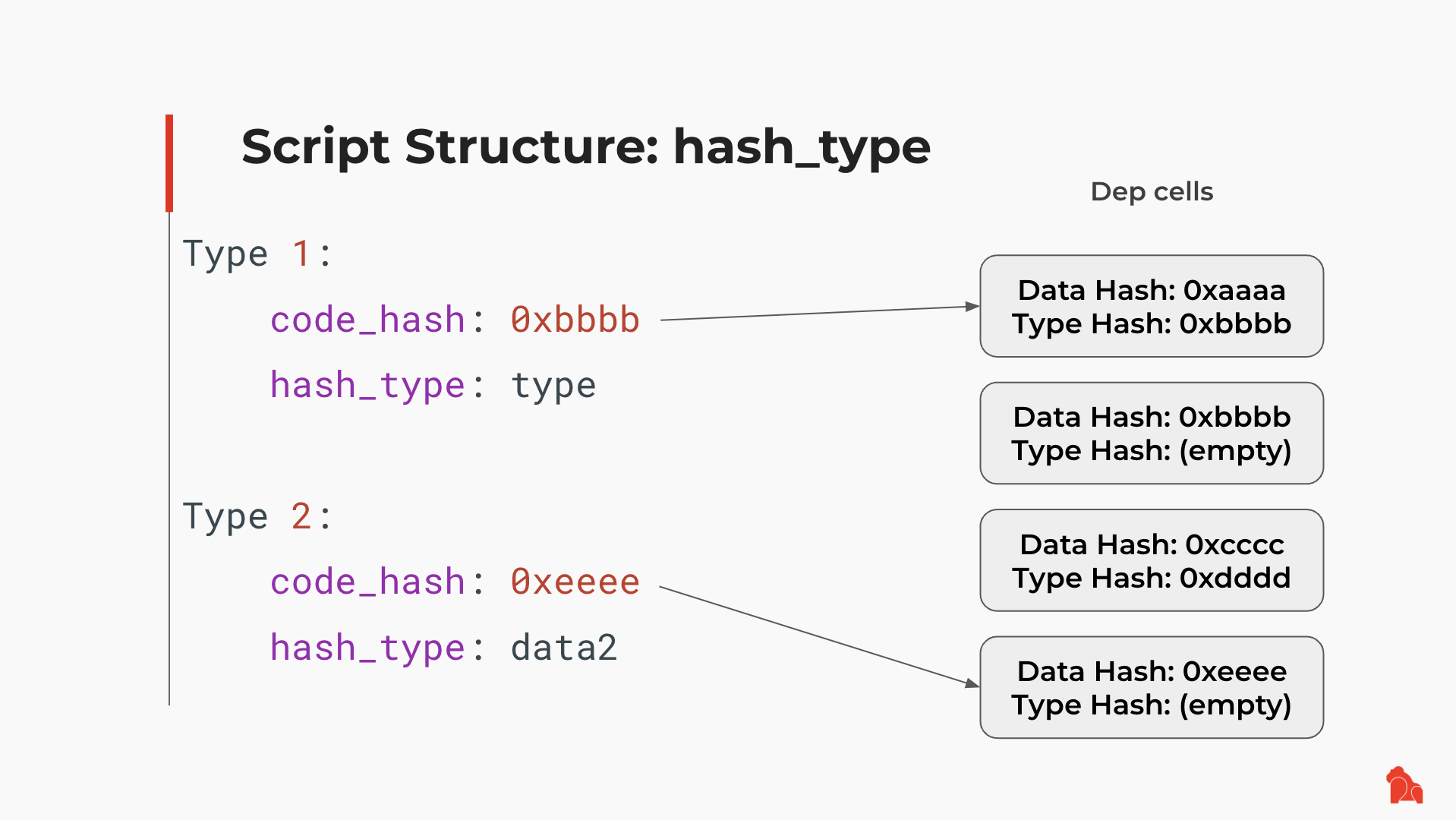
The Script structure itself does not contain the actual RISC-V code. Instead, code_hash and hash_type, when used together, act as a pointer to the real RISC-V code in a Cell from the current transaction. code_hash always contains a hash of something, while hash_type specifies what that something is. When hash_type is "type", code_hash contains the hash of the Type Script structure from the particular dep Cell containing the RISC-V code. When hash_type has a prefix of "data", code_hash contains the hash of the Cell data—the actual RISC-V code itself.
In some cases, there are two Type Script structures: the Type Script to execute and the Type Script from the Dep Cell. The hash of the second Type Script structure must match the code_hash field from the first Type Script, as shown below:
This mechanism looks simple, but it enables us to build a Cell with a unique Type Script across all CKB live Cells while continuing to allow changes to this Cell.
As shown below, Script A locates Cell B via B's Type Script. Later, Cell B is upgraded to Cell C. The content of C might be different from B, but C uses the same Type Script as B, so Script A can continue to locate Cell C. It is also guaranteed that no other live Cells can use C's Type Script, so Script A always locates the same Cell without ambiguity.
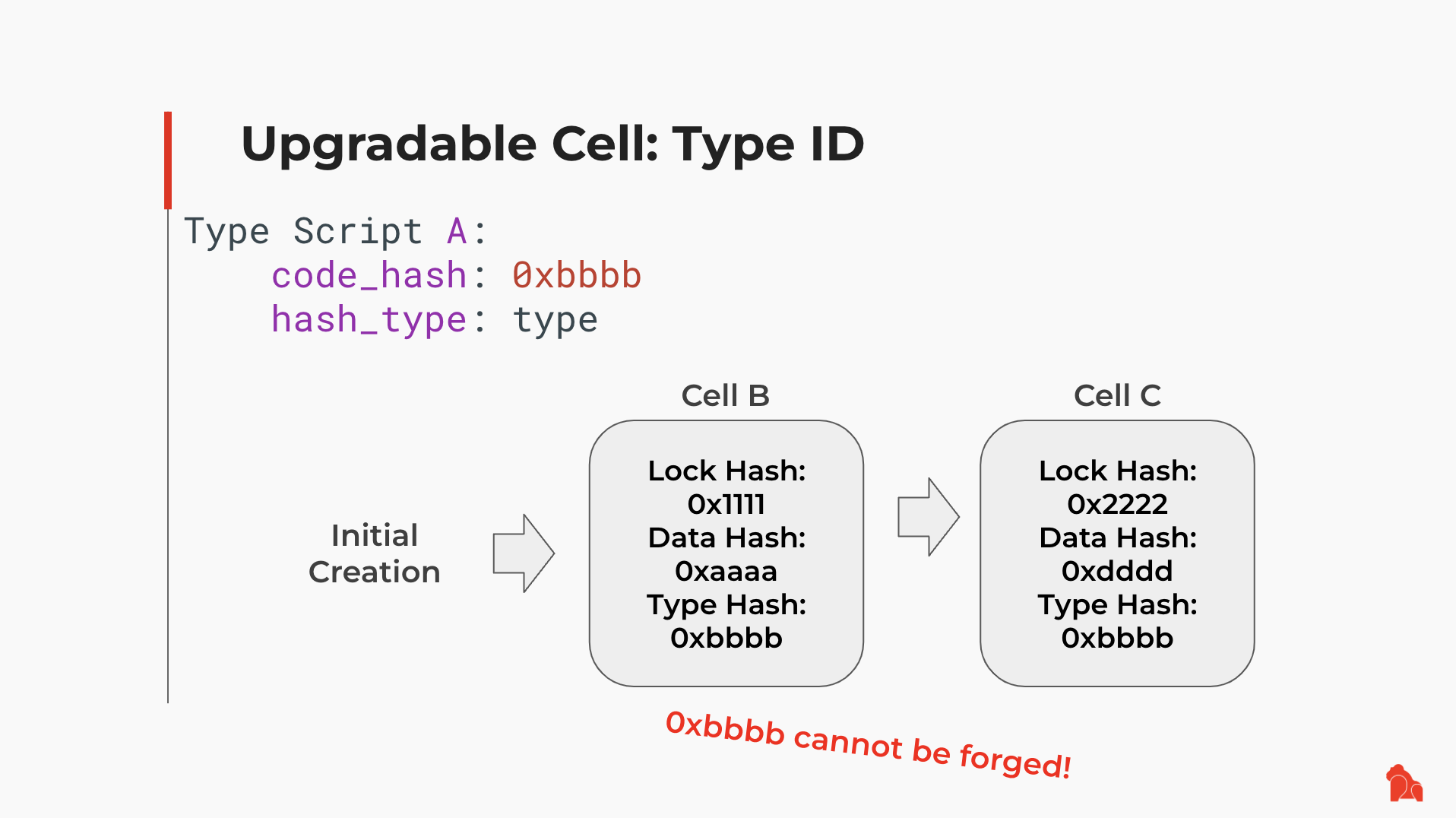
Now we have an optional solution in CKB supporting upgradable code.
Throughout the years, it really seems that this feature is not used as I hoped. For starters, some libraries such as ckb-std have APIs that only require code_hash to locate a particular piece of code. It just assumes a particular value of hash_type, as the screenshot below shows:
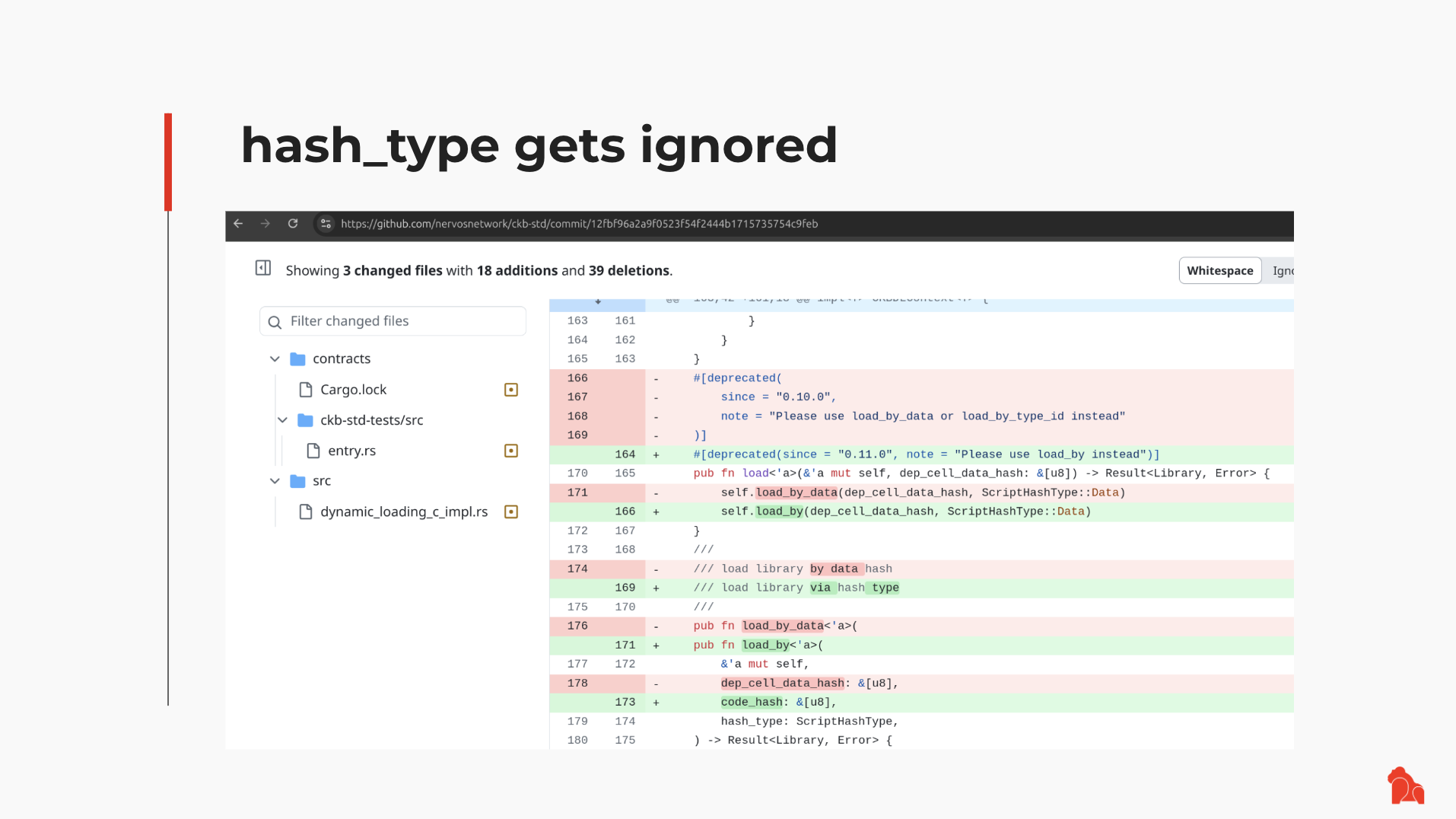
So here comes my first suggestion: don't ignore hash_type. Only the combination of code_hash and hash_type could identify a particular piece of RISC-V code within a transaction, without any ambiguity. Please do not use code_hash alone. Looking back, it is totally my responsibility that this point was not made crystal clear. In the future, please always use the combination of code_hash and hash_type to identify a Script, whether it's in off-chain code or on-chain RISC-V code.
While the above rule should be made crystal clear without any confusion, the actual usage flow for Type ID Cells now does not really align with the original design. I do want to take this time to talk about it, raising some discussions.
The key observation is that Lock Scripts can be changed in a Type ID Cell. You really don’t have to always use the same Lock Script. When upgrading a Type ID Cell, you can change the lock to really anything. My originally designed workflow relies heavily on this fact:
First, when a piece of code is deployed, no one really knows if it is free of bugs. More features might also be requested as people start to use the Script. At this stage, it might be better if the code is deployed using Type ID, so it is upgradable. A multi-sig lock can be used here.
And as development goes, the deployed code could be upgraded a few times using the “Type ID” deisgn, shipping bug fixes and new features.
Sooner or later, we might reach a state where we want the code to be frozen. There could be many reasons for this: we might know enough about the quirks in the deployed code and have more confidence in it; another reason could be that too many assets have been controlled by the code, and the risk is significant if the code is changeable. Now one can do a final upgrade on the Cell, simply altering the Lock Script to an unlockable one. This way, even though the Type ID setup is still present, the Cell will be frozen forever. Put differently, "Type ID" alone does not necessarily mean that the stored code is mutable. The Lock Script of the Cell also plays a role here.
In addition to that, I want to distinguish between two different issues: a Script developer can choose to deploy a piece of code in an upgradable Cell using the "Type ID" Script. However, it is entirely up to the actual app developer to decide if they want to reference the deployed code using the "Type ID" way. These two are completely independent choices.
For example, assuming someone deployed UDT code with Type ID setup on-chain, one issued token A might choose a UDT Type Script using "type" as the hash_type, while another issued token B might choose a different UDT Type Script, using "data2"—a data variant—as the hash_type value. If the UDT developer chooses to upgrade the UDT code from Version 1 to Version 2, token A will immediately pick up the new Version 2 of the UDT code, while token B can continue to use the old Version 1 of the code, ignoring the fact that the UDT developer ships a new version of the code.
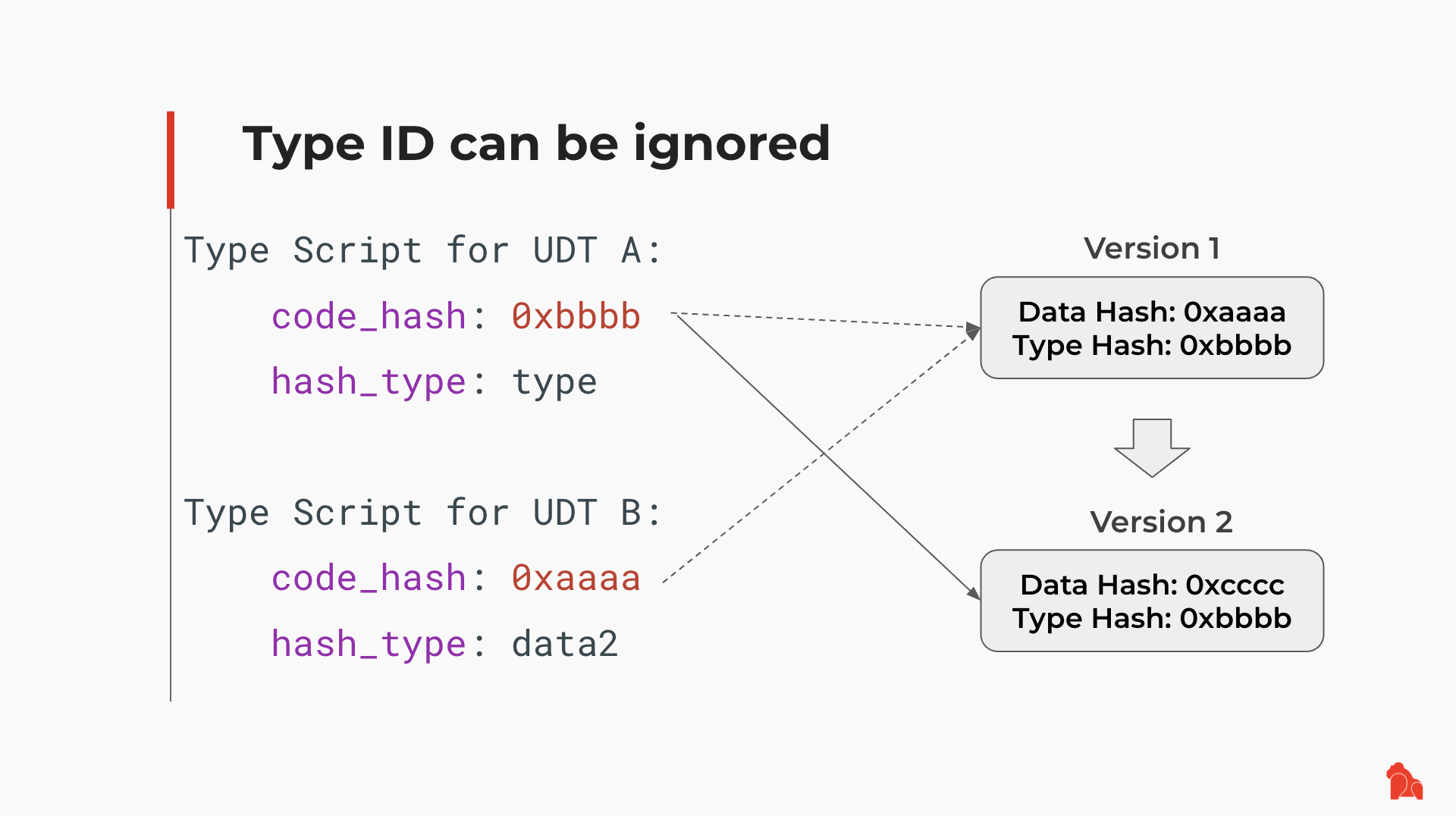
Of course, one might say that Version 1 is not present in a live Cell now. But that does not mean Version 1 of the UDT code is unusable. There are several options here: one can find the original Version 1 of the UDT code by tracking CKB chain history, then redeploy the Version 1 code in a new Cell, and use it in later operations.
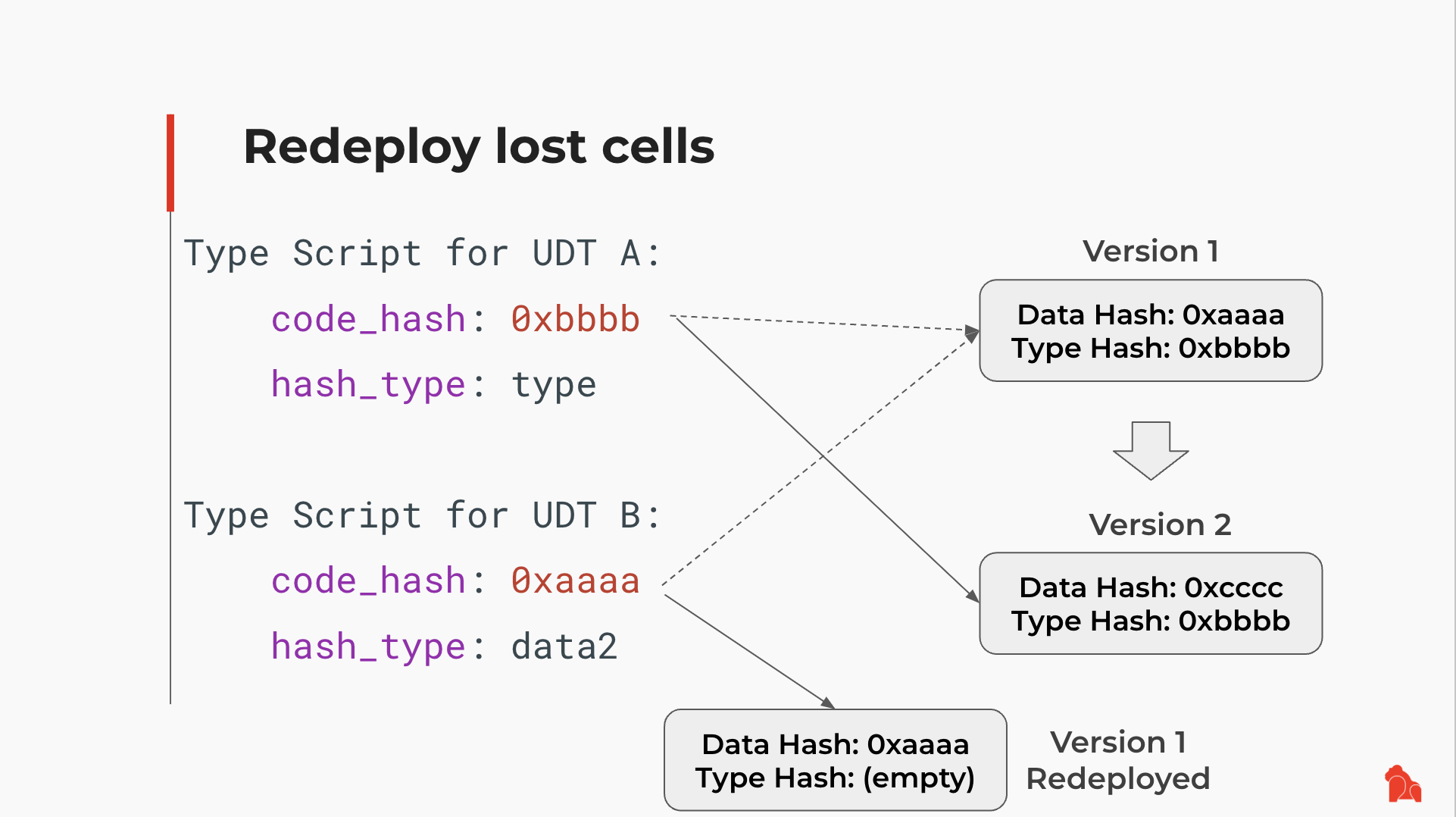
A fully developed ecosystem might also have a lending system aiding these requirements. And there is another interesting possibility: while right now a Script can only locate code within a dep Cell, historically there has been discussion that a CKB transaction should be able to keep temporary code in one of the witness structures. If there's enough interest, we might be able to bring this feature back.
So those are really what I had in mind when "Type ID" was first introduced. As I mentioned earlier, somehow they got lost in history. I believe it makes sense to explain all those facts in more detail here. I will leave it to you to decide if they still fit today.
Syscalls: Exec and Spawn
Next, I want to discuss two syscalls: exec and Spawn.
Syscall is a concept we borrowed from operating systems; it grants a CPU access to external entities. For example, in modern OSes, syscalls allow us to read a file on a disk, execute a new program, or access the network. In CKB, syscalls help CKB-VM read contents of the current CKB transaction or perform certain duties. Exec and spawn are such a pair of syscalls that let one Script call another Script on demand.
Let's consider a real scenario:
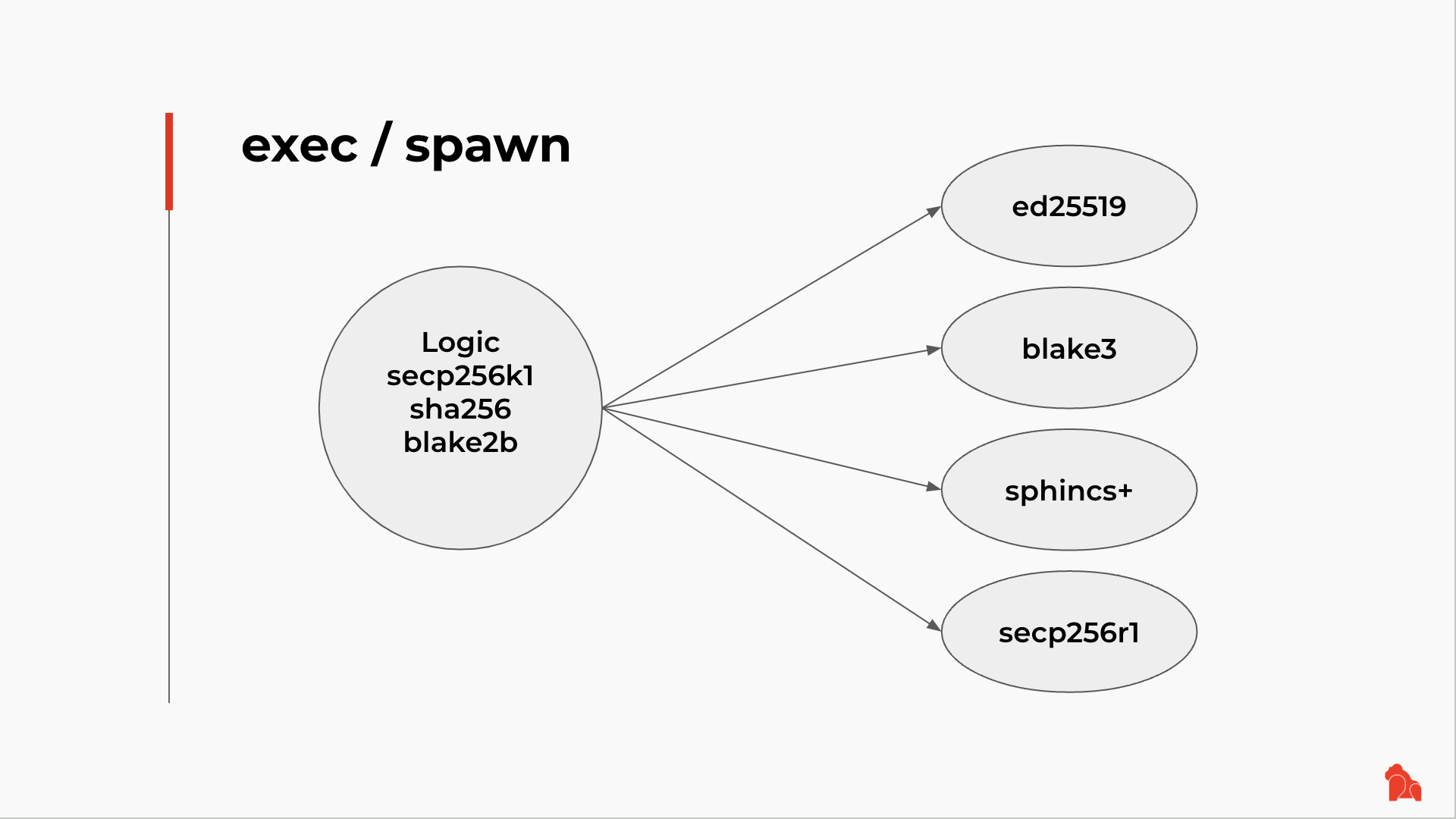
Assuming we are building a new Script. Actually, I'm going to use Script and code interchangeably, since a Script simply references a piece of code. The Script verifies some signatures or calculates some hashes. Right now, we know and use secp256k1, sha256, blake2b, etc. We can, of course, include the implementation for those algorithms directly in our Script. However, new algorithms come out every day. What if we want to add ed25519 or blake3 to our solution?

We can build upgradable code as mentioned before and upgrade our Script directly. But having more dependencies means a larger focus and also a potentially larger binary size. Some Scripts might not be upgradable at all. Is there a better solution?
Exec and Spawn syscalls are designed exactly for this. They allow your main Script to call a different Script, so the different Script provides more functionality. Take the above example: we can build a piece of code doing ed25519 verification or blake3 hash calculation. This way, there is no need to bake the same logic into our main Script. We can simply have our main Script call the ed25519 code or blake3 code via exec or Spawn syscall. Similarly, when newer algorithms come out in the future, we can have our main Script defer to other Scripts for those tasks.
The difference between exec and Spawn is that exec requires the main Script, or the caller Script, to transfer execution completely to the callee code. This means that after the main Script calls into the ed25519 code using the exec syscall, the execution control will NOT return to the main Script; the return code of the ed25519 code will be the final return code of the main Script. On the other hand, when the main Script calls into some other Script or code using the Spawn syscall, both Scripts will have their own CKB-VM instances, and CKB will execute as if both Scripts are running. Pipes can also be set up between the main Script and the callee Script so they can exchange data. When the callee Script terminates, the main Script obtains the exit code, then continues to execute until it finally terminates.
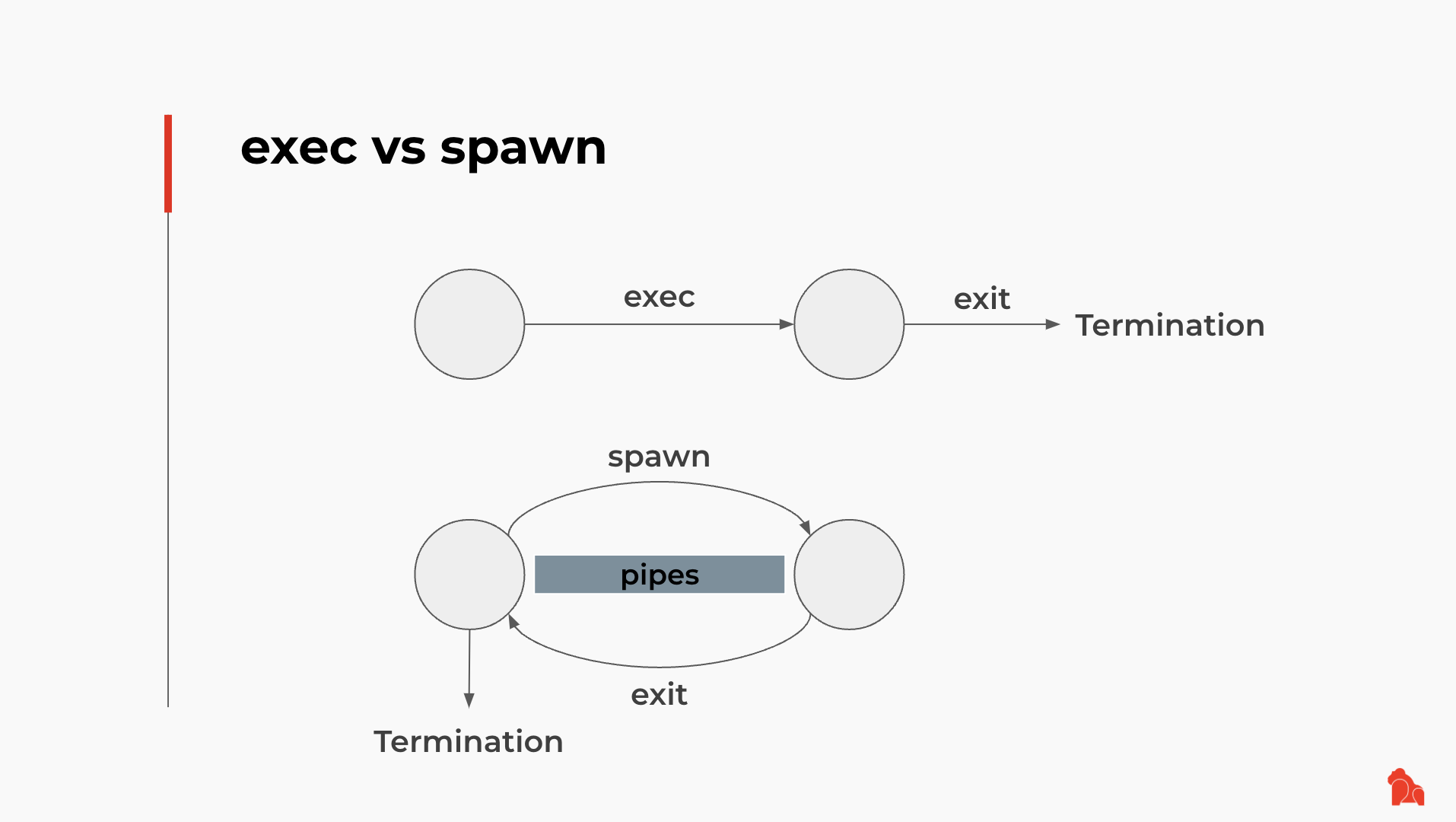
Spawn is actually the combination of two primitives: fork and exec. Assuming we type "ls" in a bash shell, the bash process actually first clones itself using the fork syscall, then the cloned bash process executes the exec syscall, replacing itself with the ls program. Finally, the ls program starts to work. By merging fork and exec into a single Spawn syscall, modern OSes can skip the cloning part, achieving better performance.
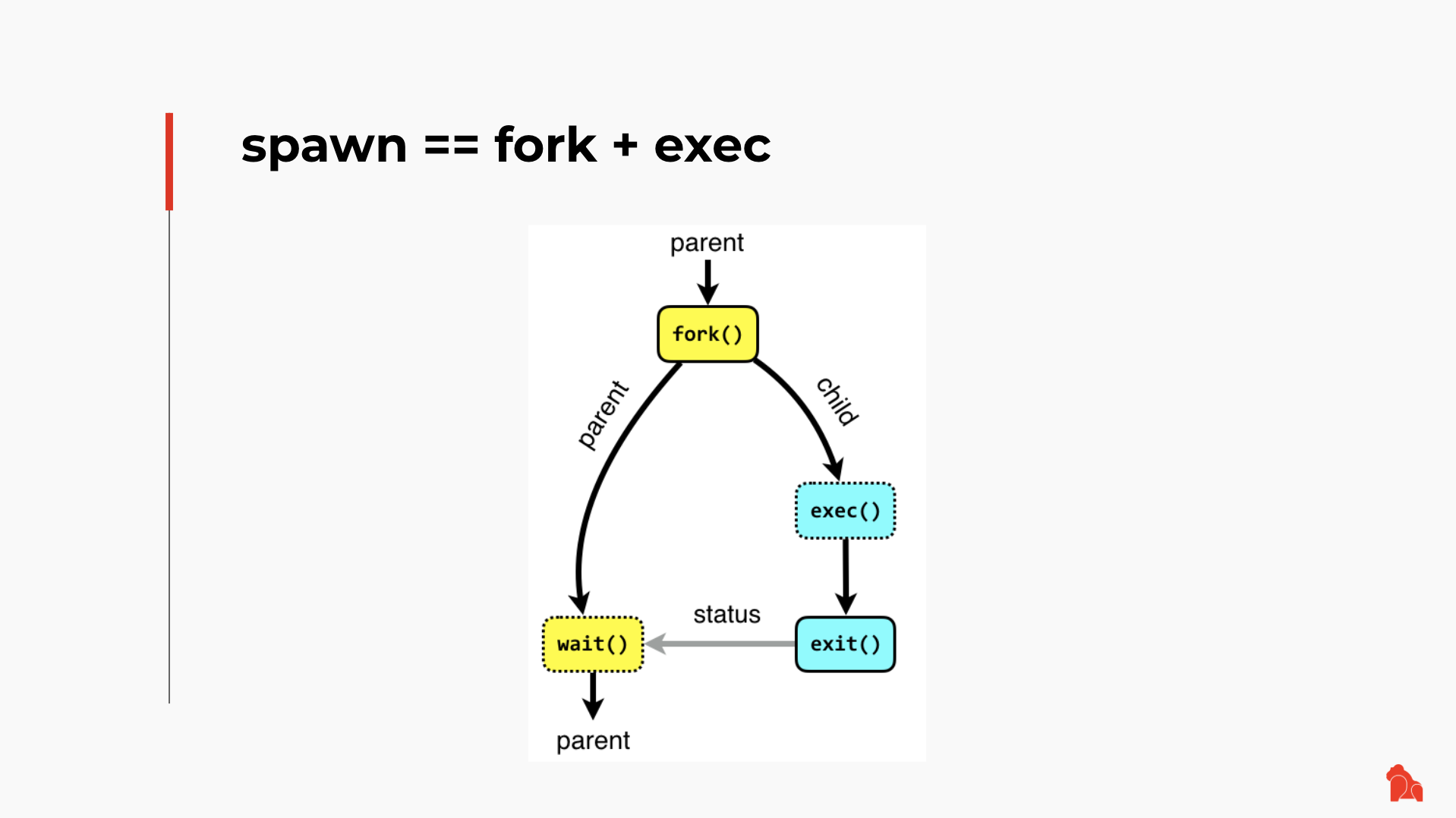
I designed and pushed the exec syscall to be shipped in the last hard fork in 2022. When I designed the exec syscall, I actually had both fork and exec in mind. I did understand that having exec alone would raise some questions, but I decided to introduce it anyway, due to two reasons:
For starters, we didn't have a clear picture of cycle consumption by different Scripts. It was really an early time when only a few Scripts were deployed and used on-chain. We simply didn't know how many cycles we should charge for a fork syscall, mainly because fork does not simply consume CPU time—it also puts pressure on memory requirements.
The second reason will be more controversial: I do believe a majority of the CKB Scripts can be rearchitected in a way so that they do transaction-level structure validation first, then pass control to a different Script for some final validation, such as signature verification. When architected this way, the exec syscall suits the workflow perfectly. Without forks, the requirement per executed CKB Script stays constant. It really seemed to me that this would work out at the time.
But unfortunately, the exec syscall never really gets enough usage as I hoped. In hindsight, I wish I'd done more introduction and built more examples around the exec syscall. Fast forward to 2024, we now have the Spawn syscall, which solves the re-architect problem of exec, but I still wonder if exec should get the attention it deserves.
Omnilock: General Lock Script with Extensible Verification
Related to exec and Spawn syscalls, I also designed Omnilock roughly at the same time. It was designed to capture enough features so it could be the general Lock Script. This would include:
Anyone-can-pay mode, time lock, and other features
The signature verification algorithm used by CKB, Ethereum, Bitcoin, and a limited set of other chains
If we look at it today, Omnilock was an immature earlier attempt, but it presents two unique interesting points:
It demonstrates the necessity of a general, widely-used Lock Script to replace the secp256k1 Lock Script shipped in the genesis block. At the time, people tried to call the secp256k1 Lock Script from the genesis block the "default lock." I fought hard against this naming, as the Lock Scripts from the genesis block were never really designed to be widely used. They could be defective, containing bugs that limit their use to particular ways. They are really there to serve as a fail-safe solution. So I once used the term "fallback lock" to refer to them. But unfortunately, many still used the secp256k1 lock from genesis and called it the default lock. Looking back, maybe it would have been better if Omnilock could have been shipped earlier than expected, ideally soon after mainnet launch. That would also have hinted from the early days that CKB was designed to have multiple different Lock Scripts, so apps could adapt to this design. Luckily, we have outgrown this phase, and people have moved away from the fallback lock.

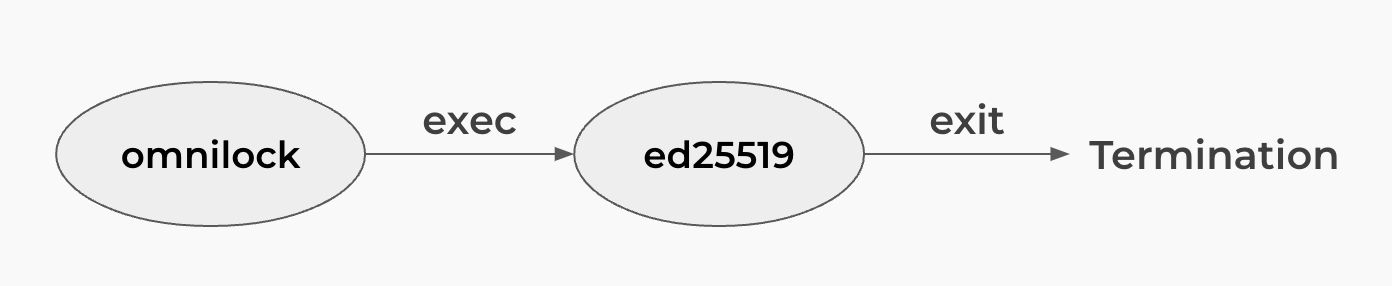
Despite the fact that Omnilock ships with some signature verification solutions, they are by no means an exhaustive list. Omnilock can call other Scripts via exec syscalls for signature verification tasks. This also aligns with the previously mentioned workflow for exec syscalls: Omnilock shall first perform transaction validations, then potentially call independent code for signature verification work. It is only when an algorithm has grown so popular that we consider adding it directly to Omnilock. However, for some reason, we have been adding new algorithms to Omnilock lately. I wish we could've provided better explanations.
(The Lack of) Precompiles
Finally, let’s talk briefly about precompiles—actually the lack of precompiles.
Precompiles are widely used in different blockchains to provide shortcuts for complicated tasks, so VMs can have easier jobs. For example, the code snippet below shows Ethereum’s ecrecover precompile, which performs secp256k1 verification in a single opcode.
function recoverSignerFromSignature(uint8 v, bytes32 r, bytes32 s, bytes32 hash) external {
address signer = ecrecover(hash, v, r, s);
require(signer != address(0), "ECDSA: invalid signature");
}
If we dig through Ethereum’s RFCs, there are all sorts of debates about adding different algorithms to Ethereum, blake2b has been added in EIP-152 as a precompile after years of debate, and yet there are still more like this.
Last I checked, a precompile for secp256r1 (EIP-7212) is still in the discussion phase.
Another example is Dfinity, which took the precompile idea to a whole new level: for each relevant algorithm, they provide an algorithm ID, which is sort of an opcode for it (Check out the code).
CKB took a different approach: instead of adding algorithms as precompiles, we compile implementations directly to RISC-V code and run them in CKB-VM, as part of CKB Script code. Of course, this path is harder and took a lot more effort, but I believe the efforts have paid off. Joy ID, .bit, and RGB++ are all prime examples of our solution.
But this path is not always smooth. I remember earlier, before the testnet launch, Jan and I had an ongoing debate about whether we should introduce precompiles. In fact, the fallback lock mentioned above was once implemented as a precompile! It is such a relief to me that we finally agreed to replace it using RISC-V code. If the fallback lock had been hardcoded, maybe CKB would have ended up with a different story.
Looking around the industry, we are still alone in this journey: even though RISC-V has become a thing for blockchain lately, almost all of them are shipped with precompiles to support complex algorithms, such as Succinct, zkVM, and RISC Zero. CKB is still the only one that works without any precompiles.

Just like proof of work, I personally consider the lack of precompiles a true property of a permissionless public blockchain.The ability to deploy a cryptographic algorithm implementation, without any blessing from anyone, is the true essence of being permissionless. Anyone should be able to deploy new algorithms to CKB as they see fit. They don't need to change CKB's code in any way to do this. Personally, I'm on the practical side—I do assume that one day, the market might force us to introduce precompiles for certain particular features. But as long as I'm working on Nervos CKB, I will fight to keep CKB-VM free from any precompiles. Jan once said Nervos is a group of people who are willing to stand for certain values; for me, this is the value I stand for: a RISC-V based VM without precompiles is the only right choice for a permissionless, public blockchain.

More About the Speaker
Xuejie’s previous articles include:
Explore more of his work on his personal site: Less is More.
Subscribe to my newsletter
Read articles from Cryptape directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by