Issues using Debezium with Kafka Connect for Change Data Capture (CDC)
 Priyansh Khodiyar
Priyansh KhodiyarTable of contents
- 1. Complex Setup and Maintenance
- 2. High Operational Overhead
- 3. Slow Snapshot
- 4. Challenges with Complex Schema Evolutions
- 5. Limited Exactly-Once Delivery Guarantees & Hot Standby of cluster failovers
- 6. Ingestion into Target Systems Requires Custom Development
- 7. Kafka Dependency and Resource Consumption
- 8. Limited Transformation Capabilities
- 9. Handling Data Loss scenarios:
- 10. Scalability Challenges with Debezium Connectors
- 11. Handling Source Data types
- 12. Handling TOAST values of Postgres
- 13. Miscellaneous Debezium Drawbacks
- RedHat Debezium Issue Tracker Highlights:
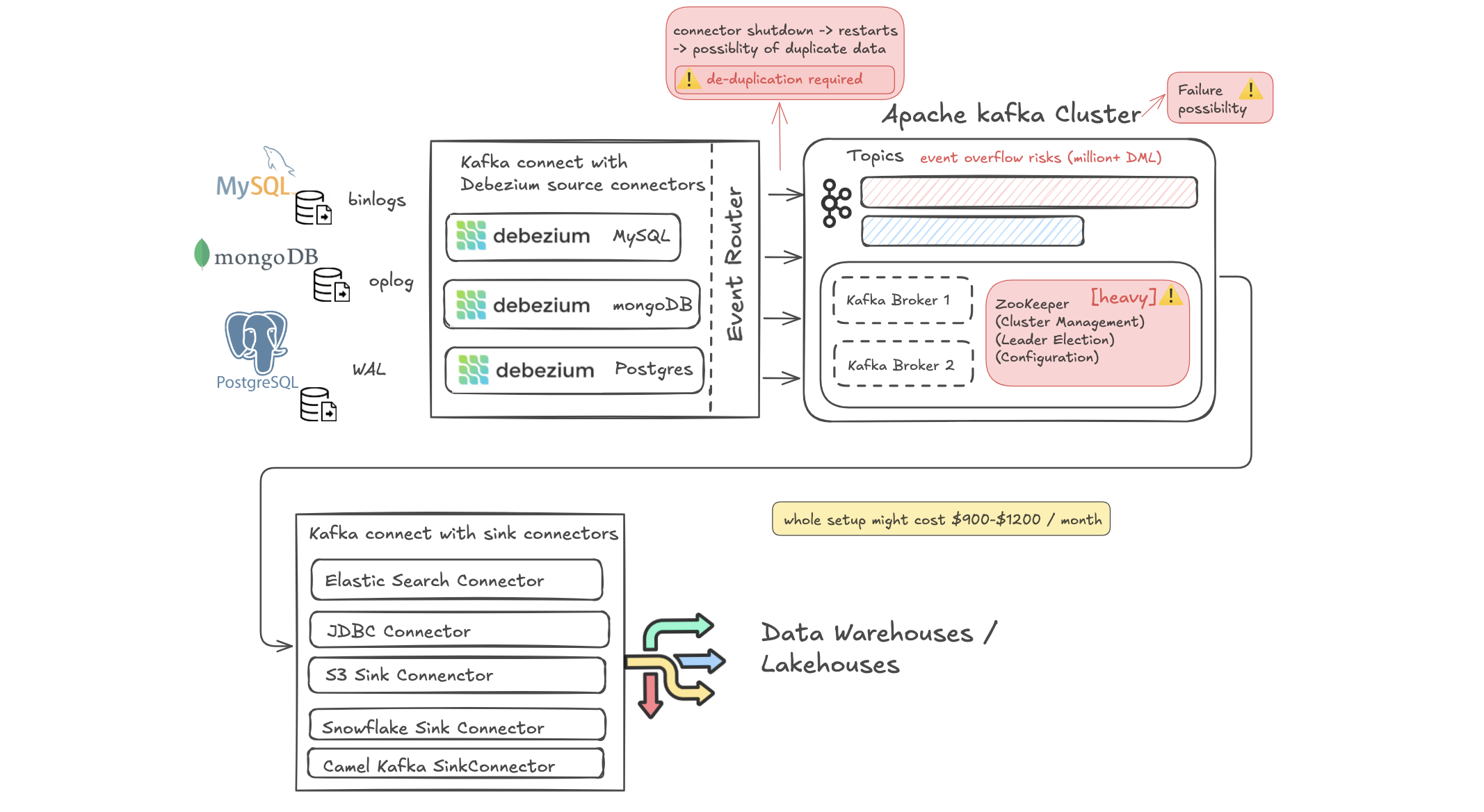
Change Data Capture (CDC) is essential for modern data architectures that require real-time data replication and synchronization across systems. Debezium (a Java utility based on the Qurkus framework), coupled with Apache Kafka, has become a popular open-source solution for implementing CDC.
However, while this combination offers powerful capabilities, it also comes with significant drawbacks that can impact your organization's efficiency and resources.
In this article, we'll delve into the technical challenges of using Debezium and Kafka for CDC, provide concrete examples, and explore why companies adopt this approach despite its limitations.
1. Complex Setup and Maintenance
Technical Challenge
Setting up Debezium with Kafka is not a plug-and-play process. It requires:
Installation and Configuration of Multiple Components: You need to set up Kafka brokers, Kafka Connect, Zookeeper (fairly heavy), and Debezium connectors.
Expertise in Distributed Systems: Understanding the intricacies of Kafka's partitioning, replication, and retention policies is essential to make it highly available.
Managing Compatibility: Making sure that all components (written in Java) are compatible in terms of versions (version incompatibility is a nightmare) and configurations.
Understanding concepts like partitioning, replication, leader election, and fault tolerance. Knowing how databases handle transaction logs or binlogs, which Debezium relies on.
Custom Transformations: Implementing Single Message Transforms (SMTs) may require writing custom Java classes and deploying them to the Kafka Connect cluster. Transforms in Debezium only apply to individual messages as they are sent to the topic.
For more advanced transformations, such as streaming joins, splitting messages, or processing the entire dataset, an additional system like Flink is required.
Example
Imagine you want to capture changes from a MongoDB database and stream them into Kafka:
Set Up Kafka Cluster: Install and configure a Kafka cluster with at least three brokers for fault tolerance.
Configure Zookeeper: Kafka relies on Zookeeper for cluster coordination, requiring its own setup and maintenance.
Deploy Kafka Connect: Install Kafka Connect to run Debezium connectors.
Configure Debezium Connector: Setting up Debezium to capture changes from MongoDB requires you to write a detailed JSON configuration file. You need to specify connector classes, database connection details, and Kafka topics. If you’re dealing with multiple databases, each requires its own configuration file and specific topic configurations.
Sink Connector for Data Lake: Moving data from Kafka into a data lake involves setting up a sink connector.
You need to manually configure the sink connector to read from the Kafka topics and define where data will be stored in the lake (e.g., S3, HDFS, or Azure Blob Storage).
Additionally, you must specify the data format (like Avro or Parquet) and tune batch and flush settings to control data flow.
Debezium Connector Configuration Example:
{
"name": "mongodb-connector",
"config": {
"connector.class": "io.debezium.connector.mongodb.MongoDbConnector",
"mongodb.hosts": "rs0/localhost:27017",
"mongodb.user": "debezium",
"mongodb.password": "dbz",
"mongodb.name": "dbserver1",
"database.include.list": "mydb",
"collection.include.list": "mydb.my_collection"
}
}
This process requires a deep understanding of each component and how they interact, making the setup time-consuming and error-prone.
Or, let’s say if you want to set up a CDC pipeline from PostgreSQL to a system like Elasticsearch, you’ll need to connect and configure a lot of different tools.
You will need a connector (Debezium PostgreSQL Connector), Instaclustr’s Managed Kafka Connect (or use the unmanaged one), and OpenDistro Elasticsearch service. While it’s definitely possible, it’s not simple—it takes time and effort to get everything working together. So, if you’re planning something similar, be ready for the complexity involved in setting up and managing all these connections.
2. High Operational Overhead
Running and maintaining a Kafka cluster demands continuous monitoring and tuning:
Resource Allocation: Kafka brokers require significant CPU, memory, and disk I/O resources.
Scaling Infrastructure: As data volume grows, you might need to add more brokers (Downtime involved) and manage data distribution. Also need to scale consumers.
Monitoring and Alerts: Implementing monitoring tools (like Prometheus, Loki and Grafana) to track cluster health and performance + snapshot metrics and streaming metrics, schema history metrics that Debezium emits. Running these tools is again resource intensive + engineering effort of setting them up.
Handling Failures: You need to manually develop strategies for broker failures, network issues, and data loss prevention.
Quantifying Resource Consumption
Memory Usage: Each Kafka broker can consume between 4 GB to 32 GB of RAM, depending on workload.
Disk Throughput: High disk I/O is needed; SSDs are recommended for low latency.
CPU Usage: High throughput scenarios can consume significant CPU resources per broker.
3. Slow Snapshot
One challenge with using Debezium is that its initial snapshot can be quite slow, especially with large datasets. This is because Debezium processes the snapshot sequentially without parallelism.
To speed things up, a common approach is to use a faster tool like an EMR cluster with Apache Spark to create a snapshot of the data and store it in a separate backfill table.
While this approach temporarily results in data existing in two locations with some overlap, you explicitly need to merge them into a single table or view to unify the data and ensure consistency.
4. Challenges with Complex Schema Evolutions
Debezium doesn't seamlessly handle complex schema changes such as:
Altering Primary Keys
Changing Column Data Types
Renaming Tables or Columns
DROP table
Primary key updates (add, remove, rename) can cause brief periods of desynchronization between the actual database primary key and the metadata Debezium uses. During these moments, data change events might have an inconsistent structure, which can result in data integrity issues.
To prevent this, you need to make primary key changes when the system is in read-only mode, process all events, stop Debezium, make the changes, then restart Debezium.
These changes can cause Debezium to fail or require manual intervention.
If any DDL (Data Definition Language) changes, like table structure updates, adding a new column, are made in MySQL (like ON DELETE CASCADE ) or Postgres, Debezium won’t notify downstream consumers, so they won’t be aware of these changes automatically. You can read more about it here
Azure Mysql you will sometimes see DDL statements such as : "FLUSH FIREWALL_RULES" which are unparseable by Debezium. Source
Added a new column to source db
Let’s say you added a new column in your source db and backfilled it with some default values, that's a DDL event, this change won't be reflected in your destination DB.
No Event for Existing Rows:
When you add a column with a default value in PostgreSQL (say), the database does not generate change events for existing rows in the Write-Ahead Log (
WAL). This means Debezium, which relies on WAL for capturing change data, does not pick up the addition of the default values for pre-existing rows.Only new inserts or updates to the table generate events that include the new column, as these actions trigger WAL entries for the rows involved.
.
Schema Evolution is Event-Driven:
- Debezium captures schema changes and propagates them to Kafka when data change events (insert, update, or delete) occur. Without any such event for pre-existing rows, the schema change doesn’t get propagated to the sink connector.
How Will the New Column Be Reflected in the Destination?
The new column will appear in the destination database when:
A new row is inserted into the source table.
An existing row is updated or deleted in the source table.
These actions will generate WAL entries that Debezium captures, including the new schema metadata.
This will be done by Debezium automatically, you might face issues with the sink connectors.
If you use a schema registry, ensure it is updated with the new schema version to avoid conflicts during serialization/deserialization.
As long as the sink system (destination database) supports schema evolution and can accommodate the new column, no errors should occur.
It’s working looking at debezium’s maintainers comment on this thread
“For Postgres, we don't support schema history and so all that gets captured are your typical data change events, i.e. insert / update / delete.”
Moreover, Debezium expects to have Primary Key of Source to NOT be of STRING type as they need to be stably ordered for incremental snapshot to happen. Why?
Configuration Considerations:
Debezium provides a snapshot.mode configuration for schema, but options like initial, schema_only, or never may not address complex schema changes without manual steps.
If there’s a possibility of schema changes during the snapshot, you cannot use snapshot.locking.mode. This setting controls how the connector locks tables (to read the schema) while taking a schema snapshot.
Debezium's PostgreSQL connector poses challenges for consumers during schema evolution, as event structures can change over time. This requires consumers to frequently update their schema interpretations, increasing overhead.
To solve this, Debezium includes schema information or references a schema ID in each event, keeping events self-contained and simplifying interpretation.
In scenarios where JSON messages with schemas are enabled, larger Kafka records are produced, particularly when schema changes are rare. To address this, some configurations disable message schemas by setting key.converter.schemas.enabled and value.converter.schemas.enabled to false.
This approach reduces payload size, saving on network bandwidth and serialization/deserialization costs. However, it introduces the need to manage and maintain schemas externally in a schema registry (such as Confluent's), adding complexity.
Incremental Snapshot Limitations:
The kafka connector doesn’t support schema changes during an incremental snapshot. If a schema change occurs between signaling and starting the snapshot, it could disrupt the snapshot process, leading to partial or inaccurate data capture.
One of the ways of Mitigation is by using database.autosave set to “conservative” helps manage this risk by handling schema changes carefully, again, requiring manual intervention.
Info: The default chunk size for incremental snapshots is 1024 rows according to Debezium and user on reddit mentioned they did some testing and found incremental snapshots pretty slow.
5. Limited Exactly-Once Delivery Guarantees & Hot Standby of cluster failovers
Debezium claims to provide at-least-once delivery, meaning duplicates can occur (and they do de-duplication steps in a snapshot window frame to resolve collisions between events that have the same primary key.).
However, in case of failures, connector restarts or DB connection drops, the same event can be delivered more than once.
Ensuring exactly-once processing requires additional work:
Implementing Idempotent Consumers: Design consumers that can handle duplicate messages gracefully.
Using Transactional Messaging: Kafka supports transactions, but configuring this with Debezium adds complexity.
Example
If a network glitch causes a message to be resent OR streaming update and incremental snapshot change or read the data at the same time / near same time, a possible collisions between late-arriving READ events and streamed events that modify the same collection row:
Duplicate Event: The consumer receives the same change event twice.
Data Integrity Issue: Without handling duplicates, this could result in incorrect data states in the target system.
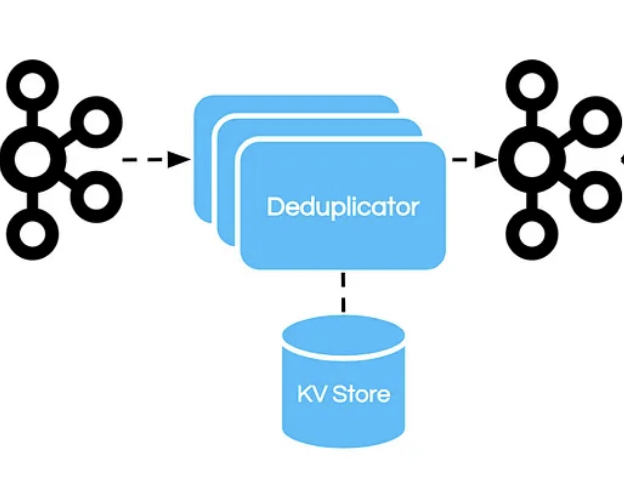
Possible solution: Implement deduplication logic based on unique identifiers, increasing development effort.
Talking about PostgreSQL, replication slots are only available on primary servers. If the primary server fails, Debezium must be reconfigured to work with the new primary, and the replication slot must be carefully managed to avoid data loss.
Moreover, if either Debezium or the MySQL (let’s say) replica (used as the CDC source) goes down, the CDC stream halts entirely.
Another way to handle duplicate events is requiring additional logic to handle idempotency (a function or operation that produces the same result when performed multiple times) at the consumer side or something like a deduplicator service (again, a lot of manual engineering team effort + code + testing it out + $$ ) between the stream that takes care of NOT sending any duplicate data to destination.
Read more about it here.
Although Debezium relies on the Kafka Connect framework for high availability, it does not support hot standby instances—a backup instance that can immediately take over without interruptions.
When a connector shuts down, it takes time for a new instance to start, which may be acceptable for some use cases but can be problematic for scenarios requiring uninterrupted data capture.
You can mitigate this to some extent by using managed services like AWS RDS and GCP CloudSQL, as they handle replication slots during failovers, minimizing the setup complexity. However, verification of the replication slot and data consistency after failover remains essential.
6. Ingestion into Target Systems Requires Custom Development
Debezium streams data into Kafka topics, but moving that data into target systems (like data warehouses or data lakes) out of scope of the Debezium project. You need to utilize Sink Connectors provided by Kafka Connect or third-party vendors.
Custom Consumers Needed: You need to configure Kafka consumers that can read from topics and write to target systems.
Schema Management: Mapping database schemas to target schemas requires additional development on your part.
Examples:
Snowflake Connector for Kafka: Provided by Snowflake, this connector streams data from Kafka topics directly into Snowflake tables.
Redshift Connector: Available through Confluent or third-party vendors, this connector allows data to flow from Kafka into Amazon Redshift.
Apache Iceberg: While there isn't a native Debezium connector for Iceberg, you can use existing Kafka Connect Sink frameworks or develop custom connectors to write data into Iceberg tables.
Example Scenario: In order to write Debezium data into an Apache Iceberg lakehouse, you need to:
Develop a Kafka Consumer: Write an application that reads from Kafka topics and writes data to Iceberg tables.
Handle Schema Evolution: Implement logic to map Debezium's change event structure to Iceberg's schema (or other lakehouse format), including handling schema changes.
Maintain the Pipeline: Monitor and update the consumer application as schemas evolve and data volumes grow. A tool like Olake is needed in such scenarios.
7. Kafka Dependency and Resource Consumption
Relying on Kafka introduces several challenges:
Infrastructure Complexity: Managing Kafka clusters and Zookeeper ensembles is complex.
High Resource Consumption: Kafka and Zookeeper require significant resources to operate efficiently.
Cost Implications: Infrastructure costs can be substantial.
Quantifying Resource Needs
Kafka Brokers:
Memory: 6-12 GB RAM per broker.
CPU: Multi-core processors for handling high throughput.
Disk Space: Depends on data retention policies; could be terabytes of storage.
Zookeeper Nodes:
Memory: 4 GB RAM per node.
CPU: Less intensive but still requires reliable hardware.
Cluster Size: Minimum of 3 nodes for high availability.
Cost Example on AWS:
Kafka Cluster (3 brokers):
Instance Type:
m5.2xlarge(8 vCPU, 32 GB RAM).Cost: Approximately $350 per month per instance.
Total: $1,050 per month. Estimate.
Zookeeper Ensemble (3 nodes): (if not using Debezium v3)
Instance Type:
m5.large(2 vCPU, 8 GB RAM).Cost: Approximately $88 per month per instance.
Total: $264 per month.
Total Infrastructure Cost: Around $1,314 per month (estimate, depends on use), not including storage costs and data transfer fees.
8. Limited Transformation Capabilities
Debezium's transformation abilities are limited to simple, stateless transformations:
Single Message Transforms (SMTs): Applied to individual messages; cannot perform operations that require state or context.
Complex Transformations Require Additional Tools: For aggregations, joins, or stateful computations, you need to integrate Kafka Streams, Apache Flink, or Apache Spark separately.
Example
Use Case: You want to
JOINchange events from two tables to create a denormalized dataset.Limitation: Debezium cannot perform this join out-of-the-box, not something Debezium does but you might require from a single solution.
Solution: Develop a Kafka Streams application, which adds complexity and requires additional resources.
9. Handling Data Loss scenarios:
Another challenge with Debezium is ensuring zero data loss, particularly when dealing with large tables. When using Debezium CDC, performance, availability, and potential data loss become major concerns.
If any component in the system—such as Kafka brokers, connectors, or databases—fails, achieving absolute data integrity and zero data loss is not guaranteed. This is especially true when there are high write volumes or complex database structures.
For instance, if Kafka experiences an outage or there are network issues, some change events might be lost, leading to inconsistencies in the data.
The burden of ensuring that data loss doesn’t happen falls entirely on the development team. This means setting up robust monitoring, retry mechanisms, and possibly custom recovery processes to handle failures.
You also need to tune the system to balance performance and reliability, which involves careful configuration of Debezium, Kafka, and the underlying database to handle failures gracefully.
The bottom line is that maintaining data integrity with Debezium requires a lot of effort from developers. Ensuring zero data loss involves complex configurations, ongoing monitoring, and a solid understanding of the entire data pipeline—making it a challenging task when working with large datasets or critical systems.
10. Scalability Challenges with Debezium Connectors
Debezium has many connectors for different databases, but they can sometimes struggle to handle large amounts of data. For example, when using PostgreSQL with the wal2json plugin to turn database logs into JSON, you might run into an OutOfMemoryError when committing large transactions that require more memory for their serialized form than the available Java heap space.
Also, taking a snapshot of large tables while new data is coming in can make the tables unavailable for a long time. This is especially a problem with big datasets
11. Handling Source Data types
While Debezium covers a range of PostgreSQL types, the handling is often simplified. Complex, custom, and structured data types are generally reduced to basic types like STRING or BYTES.
This approach may limit data fidelity and the ability to perform direct operations on these data types without additional transformation or processing.
Handling of Custom and Complex Types:
Custom Types: We referred to the Debezium docs to see how they map postgres data types. The table does not show direct support for custom types created by users in PostgreSQL (such as user-defined types or custom structures).
Structured Data: Only a few structured types like POINT are supported natively as
STRUCT, while most range types and complex structures default to a simpleSTRINGrepresentation. This limits fine-grained handling and direct manipulation of complex types, as they must first be parsed or processed outside Debezium.
Range and Enum Types:
- Debezium represents PostgreSQL’s range types (like
INT4RANGE,INT8RANGE,NUMRANGE) as strings, which means that the connector doesn’t directly support operations on ranges. Similarly,ENUMvalues are also treated asSTRING, limiting type specificity.
- Debezium represents PostgreSQL’s range types (like
Temporal and Interval Handling:
- Limited Options: Although
INTERVALcan be mapped to an integer (microseconds) or a formatted string, this handling lacks granularity. PostgreSQL’s rich interval functions are not fully leveraged, as Debezium simply provides a raw numeric or string format.
- Limited Options: Although
12. Handling TOAST values of Postgres
*[fixed in v2.5], might be good time to upgrade if you face this issue.
TOAST (The Oversized-Attribute Storage Technique) in PostgreSQL stores large column values outside the main table row. Normally, it's transparent to users, but when using Debezium, unchanged TOAST column values (e.g., large TEXT fields) are not sent in change events unless part of the table's replica identity.
Instead, Debezium uses a placeholder, like __debezium_unavailable_value
Example
Given a table with name and email as CHAR and biography as TEXT type, which can exceed page size (of 8kb) and we update the email of a user, this is what streamed to the kafka event:
{ "before": null, "after": { "id": 1004, "first_name": "Dana", "last_name": "Kretchmar", "email": "annek@noanswer.org", "biography": "__debezium_unavailable_value" } }
One way to handle this is to set the Postgres table's replica identity to FULL. This includes all column values (even unchanged ones) in change events, so there will be redundancies or add some custom TRIGGERS. Both of which will make you sit for hours to write, test and configure.
13. Miscellaneous Debezium Drawbacks
- Connector Task Limitation:
Each Debezium connector instance is limited to a single task (tasks.max: 1). While it’s possible to run multiple connectors, this restriction prevents parallelism within a single connector, slowing down data processing. This limitation is particularly noticeable in high-volume environments, where data ingestion could be slower than the rate of change, resulting in a backlog of change events.
- Lack of Active Directory Authentication Support:
Currently, Debezium does not support Active Directory (AD) authentication. Many enterprise environments use AD for managing access and permissions. Without support for AD, administrators may need to configure separate access management, which complicates setup and reduces integration with other enterprise systems.
- Event Overflow Risks:
Rapid creation of millions of data modification (DML) events can overwhelm Debezium’s event-processing pipeline (postgres connector is 7k/events per second max). When this happens, events can accumulate faster than they are processed, leading to potential data loss or delayed data sync.
While backlogging can be addressed using partitioning, this requires setting up multiple connectors for the same table and then reassembling the data later. If the load is uneven between tables, smaller tables might experience delays, as they have to wait for larger operations to complete processing first.
This scenario often occurs when high-volume operations like bulk inserts, updates, or deletes are performed, and the connector cannot keep up, creating an overflow situation in Kafka or other destinations.
4. Table name restrictions:
If your database name is TEST and the name of the table is in format for “ABC.TABLE2”, you must escape the table name in double quotes like "TEST.\"ABC.TABLE2\"".
5. Delay Processing in extreme cases:
Debezium exhibits an odd behavior when monitoring multiple tables with unbalanced loads. If one table receives a batch of changes before the others, the connector processes all changes from that table before moving on to others, potentially causing delays (e.g., up to 10 minutes in one observed case). While this may not affect well-balanced workloads, it could impact timely processing for spiky or batch-heavy loads on specific tables. Source:
Here’s what a reddit user had to say:
RedHat Debezium Issue Tracker Highlights:
DBZ-7857: Challenges with Debezium not capturing columns created by unique keys using the HASH function in MariaDB schemas.DBZ-5761: Difficulties in whitelisting additional MySQL tables in schema_only mode.DBZ-7560: Problems related to Debezium's handling of certain data types or schema changes.DBZ-5169: Issues concerning Debezium's performance under specific configurations.DBZ-3829: Complications arising from Debezium's integration with other data processing tools.DBZ-2208: Errors encountered during Debezium's snapshot process.DBZ-3046: Challenges with Debezium's handling of large transactions.DBZ-560: Problems related to Debezium's connector configurations.DBZ-5189: Issues with Debezium's handling of specific database events.
You can read more about them here. Being such a vast and complex project, you cannot be sure how long would it take if you had your production setup moved to Debezium just to later find a bug with the project or it does not handle specific use cases.
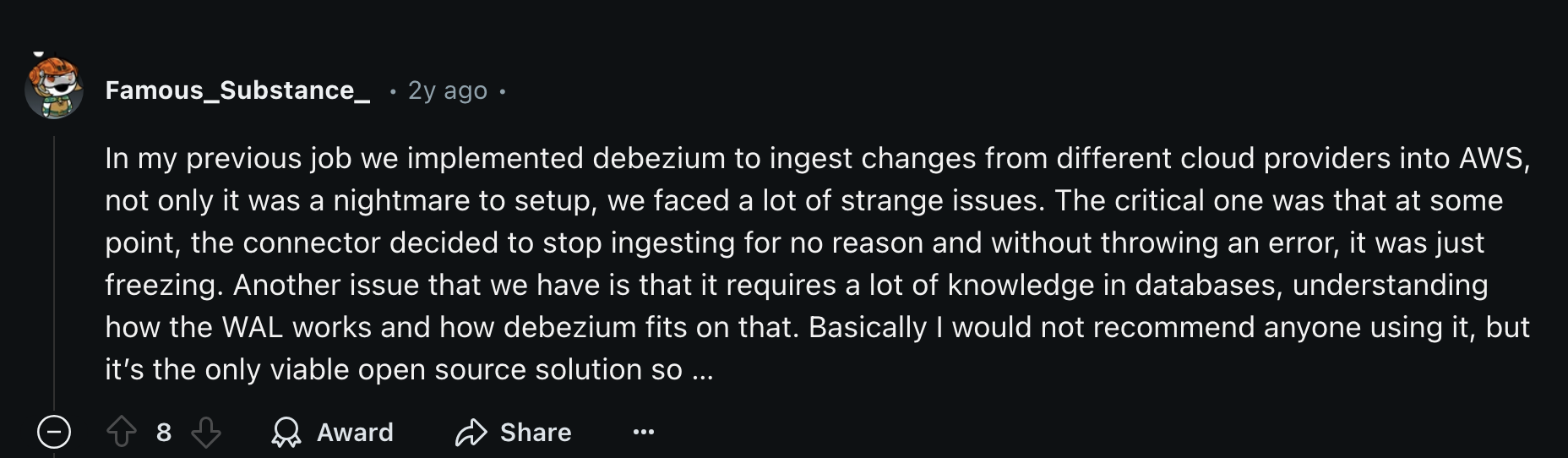
Some users on the internet mentioned issues with Debezium (or due to its complexity, they were unable to set it up the correct way):

Another user on reddit said “When a large number of updates occur, Debezium is unable to keep up with the throughput, resulting in untimely downstream data.” Source
Subscribe to my newsletter
Read articles from Priyansh Khodiyar directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by